

linux怎麼安裝hadoop

linux安裝hadoop的方法:1、安裝ssh服務;2、使用ssh進行無密碼驗證登入;3、下載Hadoop安裝包;4、解壓縮Hadoop安裝包;5、設定Hadoop中對應的文件即可。

本文操作環境:ubuntu 16.04系統、Hadoop2.7.1版、Dell G3電腦。
linux怎麼安裝hadoop?
【大數據】Linux下安裝Hadoop(2.7.1)詳解及WordCount運行
一、引言
## 在完成了Storm的環境配置之後,想著鼓搗一下Hadoop的安裝,網上面的教程好多,但是沒有一個特別切合的,所以在安裝的過程中還是遇到了很多的麻煩,並且最後不斷的查閱資料,終於解決了問題,感覺還是很好的,下面廢話不多說,開始進入正題。 本機器的設定環境如下: Hadoop(2.7.1) Ubuntu Linux(64位元系統)Ubuntu Linux(64位元系統)
## 以下分為幾個步驟來詳解配置過程。二、安裝ssh服務
進入shell命令,輸入如下命令,查看是否已經安裝好ssh服務,若沒有,則使用以下命令進行安裝:sudo apt-get install ssh openssh-server
三、使用ssh進行無密碼驗證登入
1.建立ssh-key,這裡我們採用rsa方式,使用以下指令:#ssh-keygen -t rsa -P ""
#cat ~/. ssh/id_rsa.pub >> authorized_keys(好像是可以省略的)
ssh localhost

四、下載Hadoop安裝套件
下載兩種方式 1.直接上官網進行下載,http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz 2.使用shell進行下載,指令如下:wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1. gz
五、解壓縮Hadoop安裝包
使用以下指令解壓縮Hadoop安裝包 tar -zxvf hadoop-2.7.1.tar. gz 解壓縮完成後出現hadoop2.7.1的資料夾六、設定Hadoop中對應的檔案
需要設定的檔案如下, hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml,所有的檔案都位於hadoop2.7.1/etc/hadoop下面,具體需要的設定如下: 1.core-site.xml 配置如下:<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/leesf/program/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/data</value> </property> </configuration>
七、執行Hadoop
在設定完成後,執行hadoop。 1.初始化HDFS系統 在hadop2.7.1目錄下使用如下指令:bin/hdfs namenode -format
## ## 過程需要進行ssh驗證,之前已經登入了,所以初始化過程之間鍵入y即可。
成功的截圖如下:
表示已經初始化完成。
2.開啟 NameNode
NameNode
DataNode
守護程式 使用以下指令開啟: sbin/start-start- dfs.sh,成功的截圖如下:
3.查看進程信息
使用如下命令查看進程信息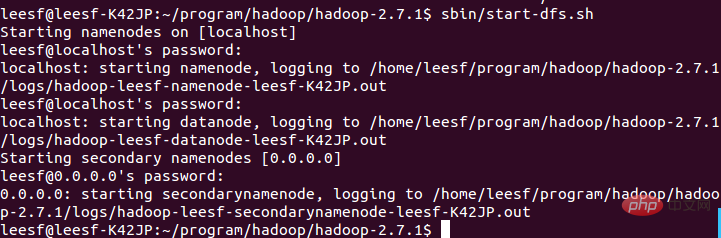
# 表示資料DataNode和NameNode都已經開啟
4.查看Web UI
在瀏覽器中輸入http://localhost:50070,即可查看相關信息,截圖如下:
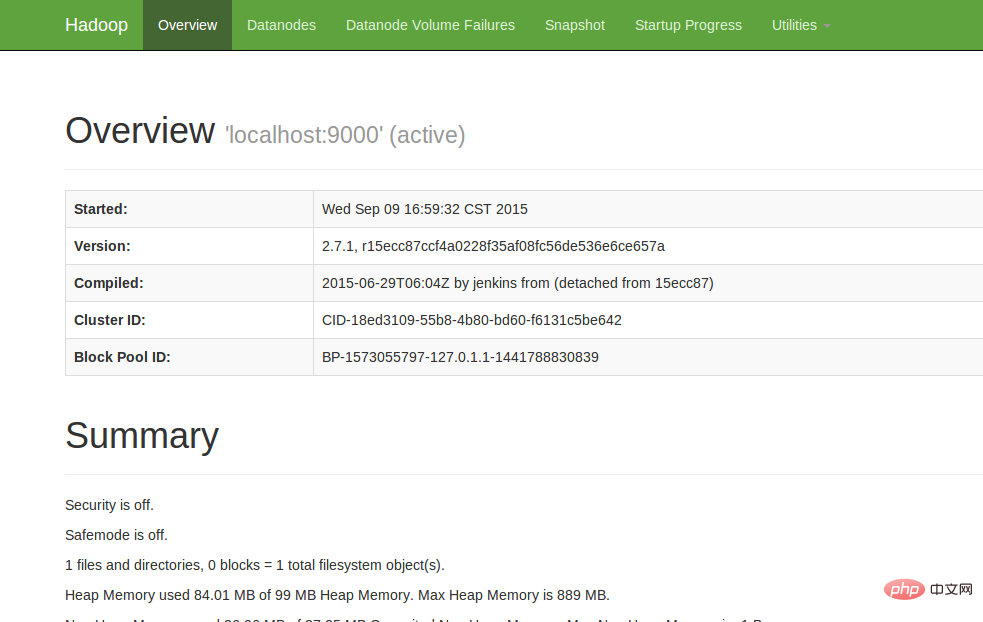
至此,hadoop的環境就已經搭建好了。下面開始使用hadoop來運行一個WordCount範例。
八、運行WordCount Demo
1.在本地新建一個文件,筆者在home/leesf目錄下新建了一個words文檔,裡面的內容可以隨便填寫。
2.在HDFS中新建一個資料夾,用於上傳本地的words文檔,在hadoop2.7.1目錄下輸入如下指令:
bin/hdfs dfs -mkdir /test,表示在hdfs的根目錄下建立了一個test目錄
使用以下指令可以查看HDFS根目錄下的目錄結構
bin/hdfs dfs -ls /
bin/hdfs dfs -ls /
如下:
表示在HDFS的根目錄下已經建立了一個test目錄
3.將本地wordsss.
使用下列指令進行上傳操作: bin/hdfs dfs -put /home/leesf/words /test/ /words /test/ hdfs dfs -ls /test/ 結果截圖如下:
 使用以下指令執行wordcount:
使用以下指令執行wordcount:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-exampjar-2.7 jar share/hadoop/mapreduce/hadoop-mapreduce-exampjar-2.7. /test/words /test/out
截圖如下:
#out 運行完成後,在/test目錄下產生名為的檔案,使用如下指令檢視/test目錄下的檔案
運行完成後,在/test目錄下產生名為的檔案,使用如下指令檢視/test目錄下的檔案
bin/hdfs dfs -ls /test
截圖如下:
test截圖如下:
 下方已經有了一個名為Out的檔案目錄
下方已經有了一個名為Out的檔案目錄
輸入如下指令查看out目錄下的檔案:
bin/hdfs dfs -ls /test/out,結果截圖如下:
表示已經成功運作了,結果保存在part-r-00000中。 5.查看運行結果
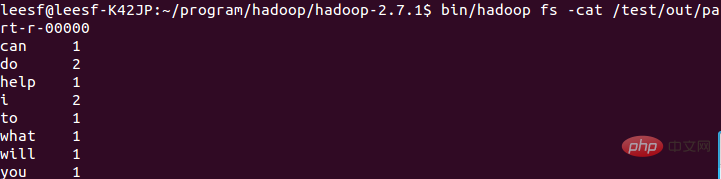 使用以下指令查看運行結果:
使用以下指令查看運行結果:
bin/hadoop fs -cat /test/out/part-r-000000
結果截圖如下:
至此,運行過程就已經完成了。 ###### 在這次的hadoop設定過程遇到了許多問題,hadoop1.x和2.x的指令還是差別很大的,設定過程中還是一一的解決了問題,配置成功了,收穫也很多,特此把這次配置的經驗分享出來,也方便想要配置hadoop環境的各位園友,在配置的過程中有任何問題都歡迎討論,謝謝各位園友的觀看~###### 推薦學習:《###linux影片教學###》###以上是linux怎麼安裝hadoop的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 centos和ubuntu的區別
Apr 14, 2025 pm 09:09 PM
centos和ubuntu的區別
Apr 14, 2025 pm 09:09 PM
CentOS 和 Ubuntu 的關鍵差異在於:起源(CentOS 源自 Red Hat,面向企業;Ubuntu 源自 Debian,面向個人)、包管理(CentOS 使用 yum,注重穩定;Ubuntu 使用 apt,更新頻率高)、支持週期(CentOS 提供 10 年支持,Ubuntu 提供 5 年 LTS 支持)、社區支持(CentOS 側重穩定,Ubuntu 提供廣泛教程和文檔)、用途(CentOS 偏向服務器,Ubuntu 適用於服務器和桌面),其他差異包括安裝精簡度(CentOS 精
 centos如何安裝
Apr 14, 2025 pm 09:03 PM
centos如何安裝
Apr 14, 2025 pm 09:03 PM
CentOS 安裝步驟:下載 ISO 映像並刻錄可引導媒體;啟動並選擇安裝源;選擇語言和鍵盤佈局;配置網絡;分區硬盤;設置系統時鐘;創建 root 用戶;選擇軟件包;開始安裝;安裝完成後重啟並從硬盤啟動。
 Centos停止維護2024
Apr 14, 2025 pm 08:39 PM
Centos停止維護2024
Apr 14, 2025 pm 08:39 PM
CentOS將於2024年停止維護,原因是其上游發行版RHEL 8已停止維護。該停更將影響CentOS 8系統,使其無法繼續接收更新。用戶應規劃遷移,建議選項包括CentOS Stream、AlmaLinux和Rocky Linux,以保持系統安全和穩定。
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 Centos停止維護後的選擇
Apr 14, 2025 pm 08:51 PM
Centos停止維護後的選擇
Apr 14, 2025 pm 08:51 PM
CentOS 已停止維護,替代選擇包括:1. Rocky Linux(兼容性最佳);2. AlmaLinux(與 CentOS 兼容);3. Ubuntu Server(需要配置);4. Red Hat Enterprise Linux(商業版,付費許可);5. Oracle Linux(與 CentOS 和 RHEL 兼容)。在遷移時,考慮因素有:兼容性、可用性、支持、成本和社區支持。
 centos停止維護後怎麼辦
Apr 14, 2025 pm 08:48 PM
centos停止維護後怎麼辦
Apr 14, 2025 pm 08:48 PM
CentOS 停止維護後,用戶可以採取以下措施應對:選擇兼容髮行版:如 AlmaLinux、Rocky Linux、CentOS Stream。遷移到商業發行版:如 Red Hat Enterprise Linux、Oracle Linux。升級到 CentOS 9 Stream:滾動發行版,提供最新技術。選擇其他 Linux 發行版:如 Ubuntu、Debian。評估容器、虛擬機或云平台等其他選項。
 docker desktop怎麼用
Apr 15, 2025 am 11:45 AM
docker desktop怎麼用
Apr 15, 2025 am 11:45 AM
如何使用 Docker Desktop? Docker Desktop 是一款工具,用於在本地機器上運行 Docker 容器。其使用步驟包括:1. 安裝 Docker Desktop;2. 啟動 Docker Desktop;3. 創建 Docker 鏡像(使用 Dockerfile);4. 構建 Docker 鏡像(使用 docker build);5. 運行 Docker 容器(使用 docker run)。
 vscode需要什麼電腦配置
Apr 15, 2025 pm 09:48 PM
vscode需要什麼電腦配置
Apr 15, 2025 pm 09:48 PM
VS Code 系統要求:操作系統:Windows 10 及以上、macOS 10.12 及以上、Linux 發行版處理器:最低 1.6 GHz,推薦 2.0 GHz 及以上內存:最低 512 MB,推薦 4 GB 及以上存儲空間:最低 250 MB,推薦 1 GB 及以上其他要求:穩定網絡連接,Xorg/Wayland(Linux)
