

完全掌握mysql的索引技巧(總結分享)

本篇文章為大家帶來了關於mysql索引的相關知識,其中包括mysql的邏輯架構和sql執行語句,希望對大家有幫助。

一、MySQL三層邏輯架構
MySQL的儲存引擎架構將查詢處理與資料的儲存/提取分開。以下是MySQL的邏輯架構圖:

1、第一層負責連線管理、授權認證、安全性等等。
每個客戶端的連線都對應著伺服器上的一個執行緒。伺服器上維護了一個執行緒池,避免為每個連線建立銷毀一個執行緒。當客戶端連接到MySQL伺服器時,伺服器對其進行認證。可以透過使用者名稱和密碼的方式進行認證,也可以透過SSL憑證進行認證。登入認證通過後,伺服器也會驗證該客戶端是否有執行某個查詢的權限。
2、第二層負責解析查詢
編譯SQL,並對其進行最佳化(如調整表的讀取順序,選擇適當的索引等)。對於SELECT語句,在解析查詢前,伺服器會先檢查查詢緩存,如果能在其中找到對應的查詢結果,則無需再進行查詢解析、最佳化等過程,直接傳回查詢結果。預存程序、觸發器、視圖等都在這一層實現。
3、第三層是儲存引擎
儲存引擎負責在MySQL中儲存資料、擷取資料、開啟一個交易等等。儲存引擎透過API與上層進行通信,這些API屏蔽了不同儲存引擎之間的差異,使得這些差異對上層查詢流程透明化。儲存引擎不會去解析SQL。
二、比較InnoDB與MyISAM
1、 儲存結構
MyISAM:每個MyISAM在磁碟上儲存成三個檔案。分別為:表定義檔、資料檔、索引檔。第一個檔案的名字以表格的名字開始,副檔名指出檔案類型。 .frm檔案儲存表定義。資料檔案的副檔名為.MYD (MYData)。索引檔的副檔名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一個資料檔案中(也可能是多個文件,或是獨立的表空間檔案),InnoDB表的大小只受限於作業系統檔案的大小,一般為2GB。
2、 儲存空間
MyISAM: MyISAM支援支援三種不同的儲存格式:靜態表(默認,但是注意資料結尾不能有空格,會被去掉)、動態表、壓縮表。當表在建立之後並匯入資料之後,不會再進行修改操作,可以使用壓縮表,極大的減少磁碟的空間佔用。
InnoDB: 需要更多的記憶體和存儲,它會在主記憶體中建立其專用的緩衝池用於高速緩衝資料和索引。
3、 可攜性、備份及恢復
MyISAM:資料是以檔案的形式存儲,所以在跨平台的資料轉移中會很方便。在備份和還原時可單獨針對某個表進行操作。
InnoDB:免費的方案可以是拷貝資料檔案、備份 binlog,或是用 mysqldump,在資料量達到幾十G的時候就相對痛苦了。
4、 事務支援
MyISAM:強調的是效能,每次查詢具有原子性,其執行數度比InnoDB類型更快,但不提供事務支持。
InnoDB:提供事務支援事務,外部鍵等高階資料庫功能。具有事務(commit)、回滾(rollback)和崩潰修復能力(crash recovery capabilities)的事務安全(transaction-safe (ACID compliant))型表。
5、 AUTO_INCREMENT
MyISAM:可以和其他欄位一起建立聯合索引。引擎的自動增長列必須是索引,如果是組合索引,自動增長可以不是第一列,他可以根據前面幾列進行排序後遞增。
InnoDB:InnoDB中必須包含只有該欄位的索引。引擎的自動增長列必須是索引,如果是組合索引也必須是組合索引的第一列。
6、 表鎖差異
MyISAM: 只支援表級鎖定,使用者在操作myisam表時,select,update,delete,insert語句都會給表自動加鎖,如果加鎖以後的表滿足insert並發的情況下,可以在表的尾部插入新的資料。
InnoDB: 支援交易和行級鎖定,是innodb的最大特色。行鎖大幅提高了多用戶並發操作的新能。但是InnoDB的行鎖,只是在WHERE的主鍵是有效的,非主鍵的WHERE都會鎖全表的。
7、全文索引
MyISAM:支援FULLTEXT類型的全文索引
InnoDB:不支援FULLTEXT類型的全文索引,但是innodb可以使用sphinx外掛程式支援全文索引,並且效果更好。
8、表主鍵
MyISAM:允許沒有任何索引和主鍵的表存在,索引都是保存行的位址。
InnoDB:如果沒有設定主鍵或非空唯一索引,就會自動產生一個6位元組的主鍵(使用者不可見),資料是主索引的一部分,附加索引保存的是主索引的值。
9、表格的具體行數
MyISAM: 儲存有表格的總行數,如果select count() from table;會直接取出出該值。
InnoDB: 沒有保存表格的總行數,如果使用select count(*) from table;就會遍歷整個表,消耗相當大,但是在加了wehre條件後,myisam和innodb處理的方式都一樣。
10、CRUD操作
MyISAM:如果執行大量的SELECT,MyISAM是更好的選擇。
InnoDB:如果你的資料執行大量的INSERT或UPDATE,出於效能方面的考慮,應該使用InnoDB表。
11、 外鍵
MyISAM:不支援
InnoDB:支援
三、sql最佳化簡介
#1、什麼情況下進行sql最佳化
效能低、執行時間太長、等待時間太長、連線查詢、索引失效。
2、sql語句執行過程
(1)寫程式
select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
(2)解析過程
from ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
3.sql優化就是優化索引
索引相當於書的目錄。
索引的資料結構是B 樹。
四、索引
1、索引的優點
#(1)提高查詢效率(降低IO使用率)
# (2)降低CPU使用率
例如查詢order by age desc,因為B 索引樹本身就是排好序的,所以再查詢如果觸發索引,就不用再重新查詢了。
2、索引的弊端
(1)索引本身很大,可以存放在記憶體或硬碟上,通常儲存在硬碟上。
(2)索引不是所有情況都使用,例如①少量資料②頻繁變化的欄位③很少使用的欄位
(3)索引會降低增刪改的效率
3、索引的分類
(1)單一值索引
(2)唯一索引
(3)聯合索引
(4)主鍵索引
備註:唯一索引和主鍵索引唯一的差異:主鍵索引不能為null
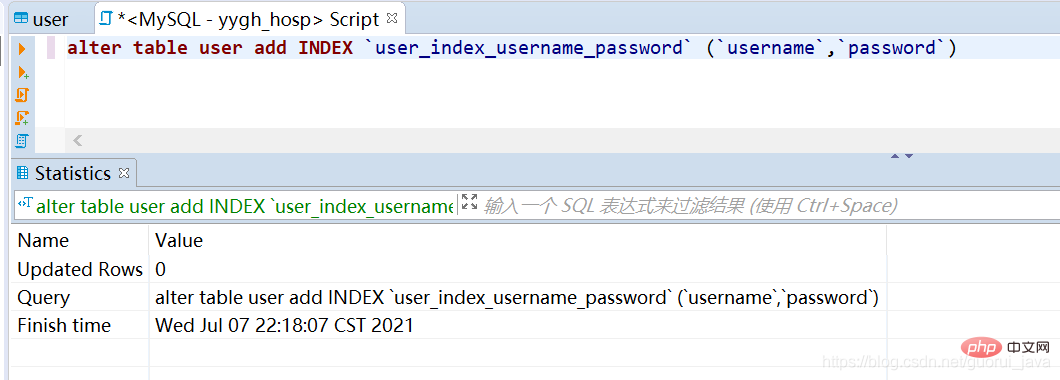
4、建立索引
alter table user add INDEX `user_index_username_password` (`username`,`password`)
5、MySQL索引原理-> B 樹
MySQL索引的底層資料結構是B 樹
B Tree是在B- Tree基礎上的最佳化,使其更適合實現外部儲存索引結構,InnoDB儲存引擎就是用B Tree實現其索引結構。
B-Tree結構圖中每個節點中不僅包含資料的key值,還有data值。而每一個頁的儲存空間是有限的,如果data資料較大時將會導致每個節點(即一個頁)能儲存的key的數量很小,當儲存的資料量很大時同樣會導致B- Tree的深度較大,增加查詢時的磁碟I/O次數,進而影響查詢效率。在B Tree中,所有資料記錄節點都是按照鍵值大小順序存放在同一層的葉子節點上,而非葉子節點上只存儲key值信息,這樣可以大大加大每個節點存儲的key值數量,降低B Tree的高度。
B Tree相對於B-Tree有幾點不同:
非葉子節點只儲存鍵值資訊。
所有葉子節點之間都有一個鏈指標。
資料記錄都存放在葉子節點中。
將上一節中的B-Tree優化,由於B Tree的非葉子節點只儲存鍵值訊息,假設每個磁碟區塊能儲存4個鍵值及指標訊息,則變成B Tree後其結構如下圖所示:
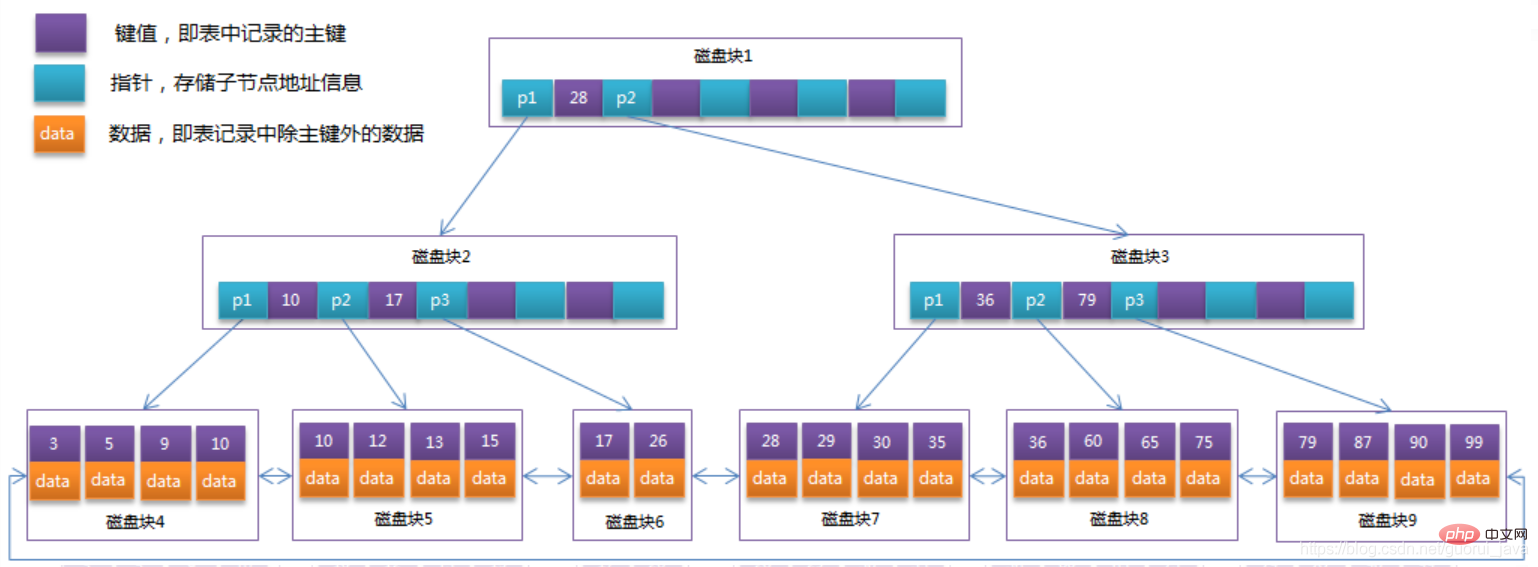
通常在B Tree上有兩個頭指針,一個指向根節點,另一個指向關鍵字最小的葉子節點,而且所有葉子節點(即資料節點)之間是一種鍊式環結構。因此可以對B Tree進行兩種查找運算:一種是對於主鍵的範圍查找和分頁查找,另一種是從根節點開始,進行隨機查找。
可能上面例子中只有22筆資料記錄,看不出B Tree的優點,下面做一個推算:
InnoDB儲存引擎中頁的大小為16KB,一般表的主鍵類型為INT(佔用4個位元組)或BIGINT(佔用8個位元組),指標型別也一般為4或8個位元組,也就是說一個頁(B Tree中的一個節點)中大概儲存16KB/( 8B 8B)=1K個鍵值(因為是估值,為方便計算,這裡的K取值為〖10〗^3)。也就是說一個深度為3的B Tree索引可以維護10^3 * 10^3 * 10^3 = 10億 筆記錄。
實際情況中每個節點可能無法填滿,因此在資料庫中,B Tree的高度一般都在2~4層。 MySQL的InnoDB儲存引擎在設計時是將根節點常駐記憶體的,也就是說尋找某一鍵值的行記錄時最多只需要1~3次磁碟I/O操作。
資料庫中的B Tree索引可以分為聚集索引(clustered index)和輔助索引(secondary index)。上面的B Tree範例圖在資料庫中的實作即為聚集索引,聚集索引的B Tree中的葉子節點存放的是整張表的行記錄資料。輔助索引與聚集索引的區別在於輔助索引的葉子節點並不包含行記錄的全部數據,而是儲存相應行數據的聚集索引鍵,即主鍵。當透過輔助索引來查詢資料時,InnoDB儲存引擎會遍歷輔助索引找到主鍵,然後再透過主鍵在聚集索引中找到完整的行記錄資料。
五、如何觸發聯合索引
1、對user表建立聯合索引username、password
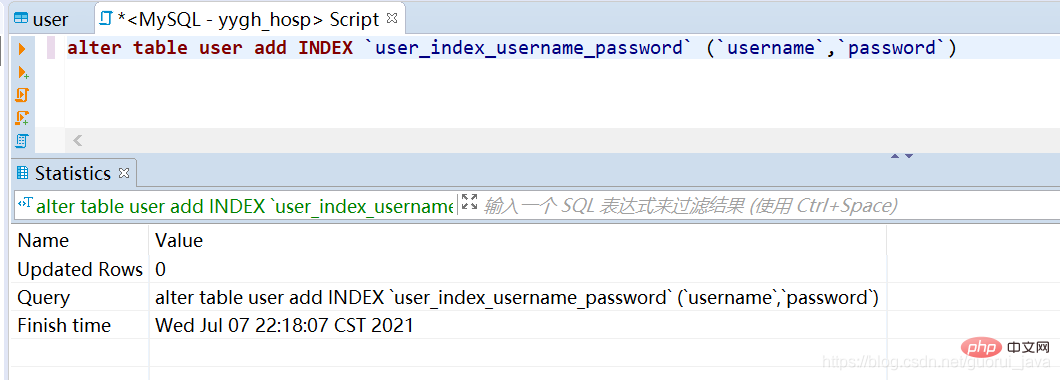
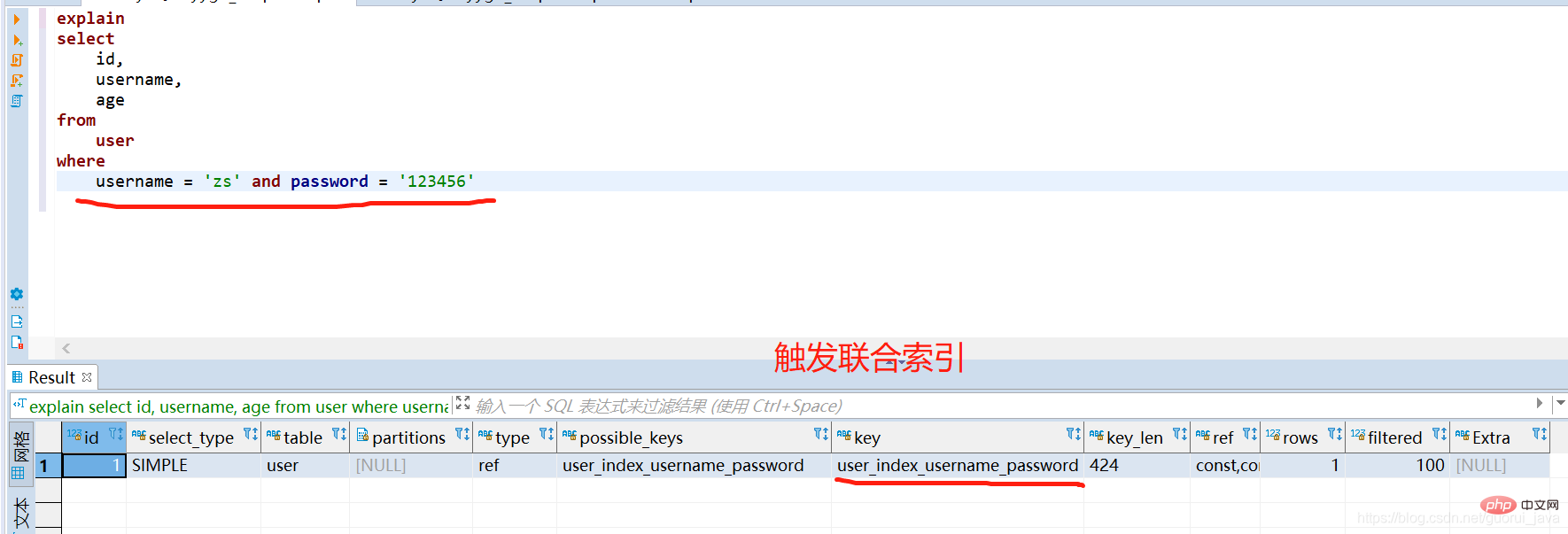
2、觸發聯合索引
(1)使用聯合索引的完整索引鍵可觸發聯合索引
#(2)使用聯合索引的全部索引鍵,但用or連接的,不可觸發聯合索引
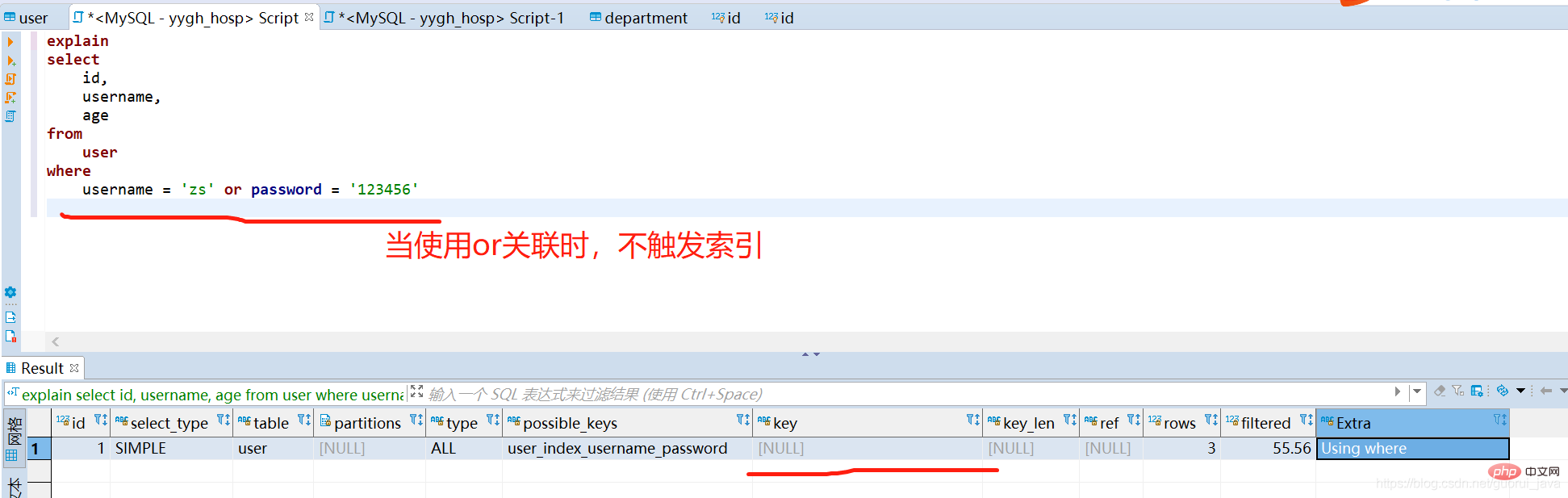
(3)單獨使用聯合索引的左邊第一個欄位時,可觸發聯合索引

(4)單獨使用聯合索引的其它欄位時,不可觸發聯合索引

#六、分析sql的執行計劃---explain
#explain可以模擬sql最佳化執行sql語句。
1、explan使用簡介
(1)使用者表

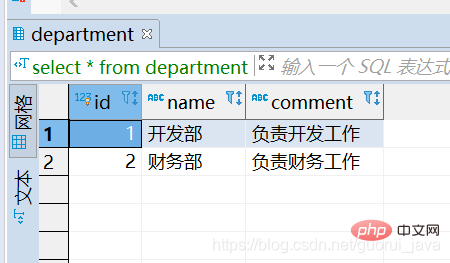
#(2)部門表
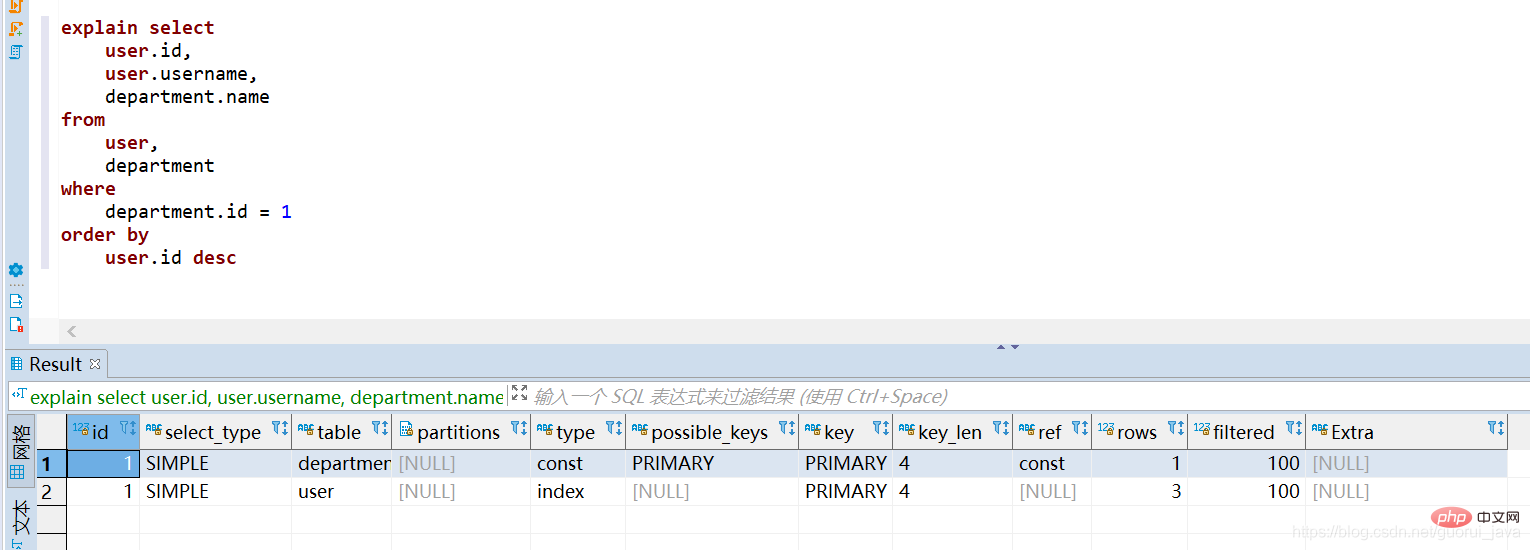
#(3)未觸發索引
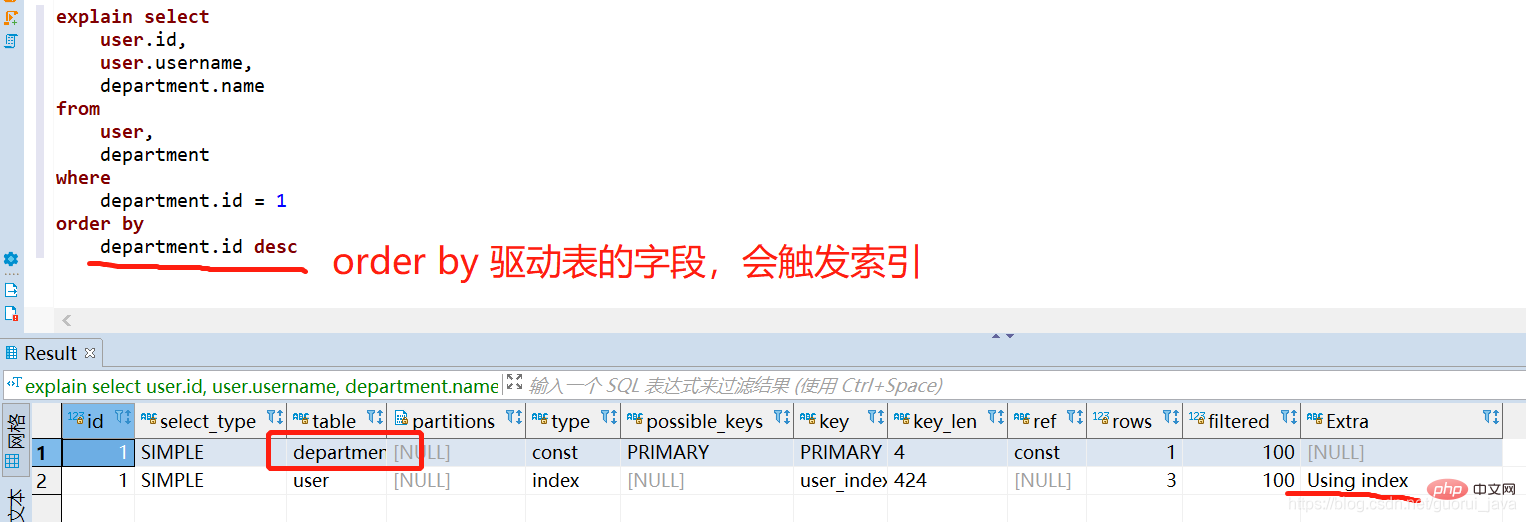
(4)觸發索引
(5 )結果分析
explain中第一行出現的表格是驅動表。
- 指定了聯結條件時,滿足查詢條件的記錄行數少的表為[驅動表]
- #未指定聯結條件時,行數少的表為[驅動表]
對驅動程式表直接進行排序就會觸發索引,且對非驅動表進行排序不會觸發索引。
2、explain查詢結果簡介
(1)id:SELECT識別碼。這是SELECT的查詢序號。
(2) select_type:SELECT類型:
#SIMPLE:簡單SELECT(不使用UNION或子查詢)
- ## PRIMARY: 最外面的SELECT
- UNION:UNION中的第二或後面的SELECT語句
- DEPENDENT UNION:UNION中的第二或後面的SELECT語句,取決於外面的查詢
- UNION RESULT:UNION的結果
- DERIVED:匯出表格的SELECT (FROM子句的子查詢)
- (3)table:表名
- (4)type:聯結類型
- system:表格僅有一行(=系統表)。這是const聯接類型的一個特例。
- const:表最多有一個符合行,它將在查詢開始時被讀取。因為僅有一行,在這行的列值可被最佳化器剩餘部分認為是常數。 const用於用常數值比較PRIMARY KEY或UNIQUE索引的所有部分時。 ######eq_ref:對於每個來自前面的表的行組合,從該表中讀取一行。這可能是最好的聯接類型,除了const類型。它用在一個索引的所有部分被聯接使用並且索引是UNIQUE或PRIMARY KEY。 eq_ref可以用來使用= 運算子比較的帶索引的列。比較值可以是常數或一個使用在該表前面所讀取的表的列的表達式。 ############ref:對於每個來自前面的表的行組合,所有有匹配索引值的行將從這張表中讀取。如果聯接只使用鍵的最左邊的前綴,或者如果鍵不是UNIQUE或PRIMARY KEY(換句話說,如果聯接不能基於關鍵字選擇單一行的話),則使用ref。如果使用的鍵僅符合少量行,則該連接類型是不錯的。 ref可以用來使用=或<=>運算子的帶索引的欄位。 ############ref_or_null:這個聯結類型如同ref,但新增了MySQL可以特別搜尋包含NULL值的行。在解決子查詢中經常使用該聯結類型的最佳化。 ###
index_merge:此聯結類型表示使用了索引合併最佳化方法。在這種情況下,key列包含了使用的索引的清單,key_len包含了使用的索引的最長的關鍵元素。
unique_subquery:這個類型取代了下面形式的IN子查詢的ref:value IN (SELECT primary_key FROMsingle_table WHERE some_expr);unique_subquery是一個索引查找函數,可以完全替換子查詢,效率更高。
index_subquery:此聯結類型類似unique_subquery。可以取代IN子查詢,但只適合下列形式的子查詢中的非唯一索引:value IN (SELECT key_column FROM single_table WHERE some_expr)
#range:只檢索給定範圍的行,使用一個索引來選擇行。 key列顯示使用了哪個索引。 key_len包含所使用索引的最長關鍵元素。在該類型中ref列為NULL。使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或IN運算符,用常數比較關鍵字列時,可以使用range
index:此聯結類型與ALL相同,除了只有索引樹被掃描。這通常比ALL快,因為索引檔案通常比資料檔案小。
all:對於每個來自先前的表格的行組合,進行完整的表格掃描。如果表是第一個沒有標記const的表,這通常不好,並且通常在它情況下很差。通常可以增加更多的索引而不要使用ALL,使得行能基於前面的表中的常數值或列值被檢索出。
(5)possible_keys:possible_keys欄位指出MySQL能使用哪個索引在該表中找到行。請注意,此列完全獨立於EXPLAIN輸出所示的表的順序。這意味著在possible_keys中的某些鍵實際上不能按生成的表次序使用。
(6)key:key列顯示MySQL實際決定使用的鍵(索引)。如果沒有選擇索引,鍵是NULL。若要強制MySQL使用或忽略possible_keys欄位中的索引,在查詢中使用FORCE INDEX、USE INDEX或IGNORE INDEX。
(7)key_len:key_len列顯示MySQL決定使用的鍵長度。如果鍵是NULL,則長度為NULL。注意透過key_len值我們可以確定MySQL將實際使用一個多部關鍵字的幾個部分。
(8)ref:ref列顯示使用哪個列或常數與key一起從表中選擇行。
(9)rows:rows列顯示MySQL認為它執行查詢時必須檢查的行數。
(10)Extra:此列包含MySQL解決查詢的詳細資訊。
Distinct:MySQL發現第1個符合行後,停止為目前的行組合搜尋更多的行。
Not exists:MySQL能夠對查詢進行LEFT JOIN優化,發現1個符合LEFT JOIN標準的行後,不再為前面的行組合在該表內檢查更多的行。
range checked for each record (index map: #):MySQL沒有發現好的可以使用的索引,但發現如果來自前面的表的列值已知,可能部分索引可以使用。對前面的表格的每個行組合,MySQL檢查是否可以使用range或index_merge存取方法來索取行。
Using filesort:MySQL需要額外的一次傳遞,以找出如何按排序順序檢索行。透過根據聯接類型瀏覽所有行並為所有符合WHERE子句的行保存排序關鍵字和行的指標來完成排序。然後關鍵字被排序,並按排序順序檢索行。
Using index:從只使用索引樹中的資訊而不需要進一步搜尋讀取實際的行來檢索表中的列資訊。當查詢只使用作為單一索引一部分的欄位時,可以使用該策略。
Using temporary:為了解決查詢,MySQL需要建立一個暫存表來容納結果。典型情況如查詢包含可以依不同情況列出列的GROUP BY和ORDER BY子句時。
Using where:WHERE子句用來限制哪一個行符合下一個資料表或傳送到客戶。除非你專門從表中索取或檢查所有行,如果Extra值不為Using where並且表聯接類型為ALL或index,查詢可能會有一些錯誤。
Using sort_union(...), Using union(...), Using intersect(...):這些函式說明如何為index_merge聯結型別合併索引掃描。
Using index for group-by:類似於存取表的Using index方式,Using index for group-by表示MySQL發現了一個索引,可以用來查詢GROUP BY或DISTINCT查詢的所有列,而不要額外搜尋硬碟存取實際的表。並且,以最有效的方式使用索引,以便對於每個群組,只讀取少量索引條目。
透過相乘EXPLAIN輸出的rows列的所有值,你能得到一個關於一個聯接如何的提示。這應該粗略地告訴你MySQL必須檢查多少行以執行查詢。當你使用max_join_size變數限制查詢時,也用這個乘積來決定要執行哪個多表SELECT語句。
推薦學習:mysql影片教學
以上是完全掌握mysql的索引技巧(總結分享)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 mysql索引失效的幾種情況
Feb 21, 2024 pm 04:23 PM
mysql索引失效的幾種情況
Feb 21, 2024 pm 04:23 PM
常見情況:1、使用函數或運算;2、隱式類型轉換;3、使用不等於(!=或<>);4、使用LIKE操作符,並以通配符開頭;5、OR條件;6、NULL值;7、索引選擇性低;8、複合索引的最左前綴原則;9、優化器決策;10、FORCE INDEX和IGNORE INDEX。
 與MySQL中使用索引相比,全表掃描何時可以更快?
Apr 09, 2025 am 12:05 AM
與MySQL中使用索引相比,全表掃描何時可以更快?
Apr 09, 2025 am 12:05 AM
全表掃描在MySQL中可能比使用索引更快,具體情況包括:1)數據量較小時;2)查詢返回大量數據時;3)索引列不具備高選擇性時;4)複雜查詢時。通過分析查詢計劃、優化索引、避免過度索引和定期維護表,可以在實際應用中做出最優選擇。
 mysql索引什麼情況下會失效
Aug 09, 2023 pm 03:38 PM
mysql索引什麼情況下會失效
Aug 09, 2023 pm 03:38 PM
mysql索引在不使用索引列進行查詢、資料類型不符、前綴索引的使用不當、使用函數或表達式進行查詢、索引列的順序不正確、資料更新頻繁和索引過多或過少情況下會失效。 1、不使用索引列進行查詢,為了避免這種情況,應在查詢中使用適當的索引列;2、資料類型不匹配,在設計表結構時,應確保索引列和查詢的資料類型匹配;3 、前綴索引的使用不當,可使用前綴索引。
 MySQL索引左前綴匹配規則
Feb 24, 2024 am 10:42 AM
MySQL索引左前綴匹配規則
Feb 24, 2024 am 10:42 AM
MySQL索引最左原則原理及程式碼範例在MySQL中,索引是提高查詢效率的重要手段之一。其中,索引最左原則是我們在使用索引來優化查詢的過程中需要遵循的一個重要原則。本文將圍繞MySQL索引最左原則的原理進行介紹,並給出一些具體的程式碼範例。一、索引最左原則的原理索引最左原則是指在一個索引中,如果查詢條件是由多個列組成的,那麼只有按照索引中的最左側列進行查詢,才能充
 說明不同類型的MySQL索引(B樹,哈希,全文,空間)。
Apr 02, 2025 pm 07:05 PM
說明不同類型的MySQL索引(B樹,哈希,全文,空間)。
Apr 02, 2025 pm 07:05 PM
MySQL支持四種索引類型:B-Tree、Hash、Full-text和Spatial。 1.B-Tree索引適用於等值查找、範圍查詢和排序。 2.Hash索引適用於等值查找,但不支持範圍查詢和排序。 3.Full-text索引用於全文搜索,適合處理大量文本數據。 4.Spatial索引用於地理空間數據查詢,適用於GIS應用。
 mysql索引的分類有哪幾種
Apr 22, 2024 pm 07:12 PM
mysql索引的分類有哪幾種
Apr 22, 2024 pm 07:12 PM
MySQL 索引分為以下類型:1. 普通索引:匹配值、範圍或前綴;2. 唯一索引:確保值唯一;3. 主鍵索引:主鍵列的唯一索引;4. 外鍵索引:指向另一表主鍵;5. 全文索引:全文搜尋;6. 雜湊索引:相等配對搜尋;7.空間索引:地理空間搜尋;8. 複合索引:基於多個欄位的搜尋。
 如何合理使用MySQL索引,優化資料庫效能?技術同學須知的設計規約!
Sep 10, 2023 pm 03:16 PM
如何合理使用MySQL索引,優化資料庫效能?技術同學須知的設計規約!
Sep 10, 2023 pm 03:16 PM
如何合理使用MySQL索引,優化資料庫效能?技術同學須知的設計規約!引言:在當今網路時代,資料量不斷成長,資料庫效能最佳化成為了一個非常重要的課題。而MySQL作為最受歡迎的關係型資料庫之一,索引的合理使用對於提升資料庫效能至關重要。本文將介紹如何合理使用MySQL索引,優化資料庫效能,並為技術同學提供一些設計規約。一、為什麼要使用索引?索引是一種資料結構,用
 PHP與MySQL索引的資料更新和索引維護的效能最佳化策略及其對效能的影響
Oct 15, 2023 pm 12:15 PM
PHP與MySQL索引的資料更新和索引維護的效能最佳化策略及其對效能的影響
Oct 15, 2023 pm 12:15 PM
PHP與MySQL索引的資料更新和索引維護的效能最佳化策略及其對效能的影響摘要:在PHP與MySQL的開發中,索引是最佳化資料庫查詢效能的重要工具。本文將介紹索引的基本原理和使用方法,並探討索引對資料更新和維護的效能影響。同時,本文也提供了一些效能優化策略和具體的程式碼範例,幫助開發者更好地理解和應用索引。索引的基本原理和使用方法在MySQL中,索引是一種特殊的數
