
本篇文章為大家帶來了關於java的相關知識,其中主要介紹了java並發的相關問題,總結了一些問題,大家來看一下會多少,希望對大家有幫助。

推薦學習:《java教學》
從作業系統的角度來看,執行緒是CPU分配的最小單位。
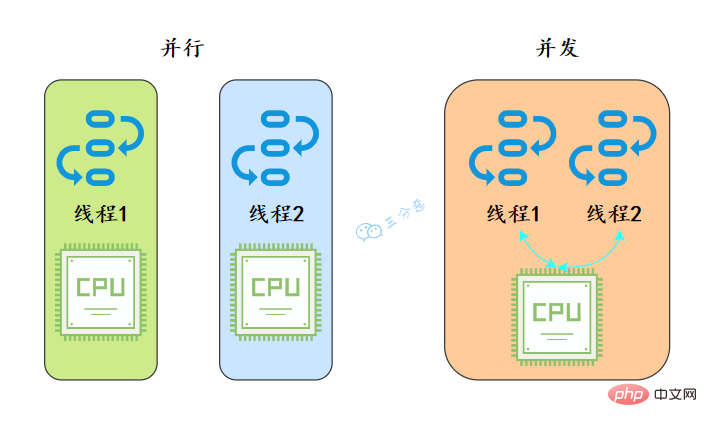
就好像我們去食堂打飯,並行就是我們在多個窗口排隊,幾個阿姨同時打菜;並發就是我們擠在一個窗口,阿姨給這個打一匙,又手忙腳亂地給那個打一匙。

要說線程,必須先說說進程。
作業系統在分配資源時是把資源分配給進程的, 但是CPU 資源比較特殊,它是被分配到線程的,因為真正要佔用CPU運行的是線程,所以也說線程是CPU分配的基本單位。
例如在Java中,當我們啟動 main 函數其實就啟動了一個JVM進程,而 main 函數在的線程就是這個進程中的一個線程,也稱為主線程。
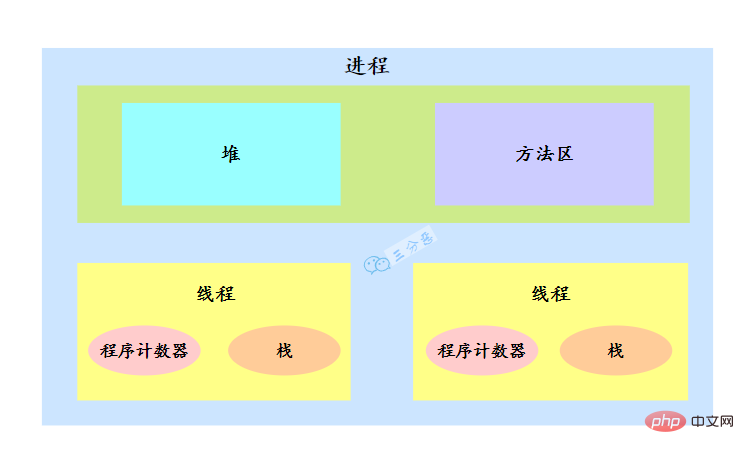
一個行程中有多個線程,多個執行緒共用行程的堆疊和方法區資源,但是每個執行緒有自己的程式計數器和堆疊。
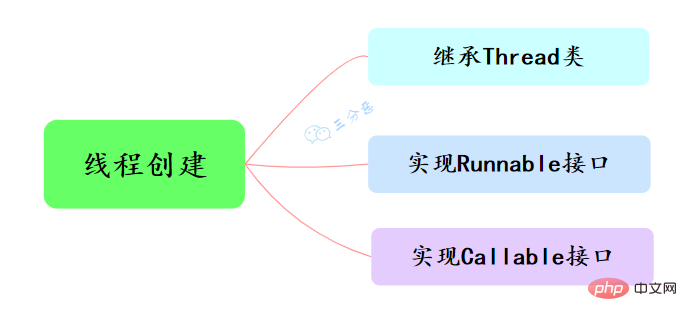
Java中建立執行緒主要有三種方式,分別為繼承Thread類別、實作Runnable介面、實作Callable介面。
public class ThreadTest {
/**
* 继承Thread类
*/
public static class MyThread extends Thread {
@Override
public void run() {
System.out.println("This is child thread");
}
}
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}}public class RunnableTask implements Runnable {
public void run() {
System.out.println("Runnable!");
}
public static void main(String[] args) {
RunnableTask task = new RunnableTask();
new Thread(task).start();
}}上面兩個都是沒有回傳值的,但是如果我們需要取得執行緒的執行結果,該怎麼辦呢?
public class CallerTask implements Callable<string> {
public String call() throws Exception {
return "Hello,i am running!";
}
public static void main(String[] args) {
//创建异步任务
FutureTask<string> task=new FutureTask<string>(new CallerTask());
//启动线程
new Thread(task).start();
try {
//等待执行完成,并获取返回结果
String result=task.get();
System.out.println(result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}}</string></string></string>JVM執行歸納整理Java並發知識點,會先建立一條線程,由創建出來的新線程去執行thread的run方法,這才起到多線程的效果。
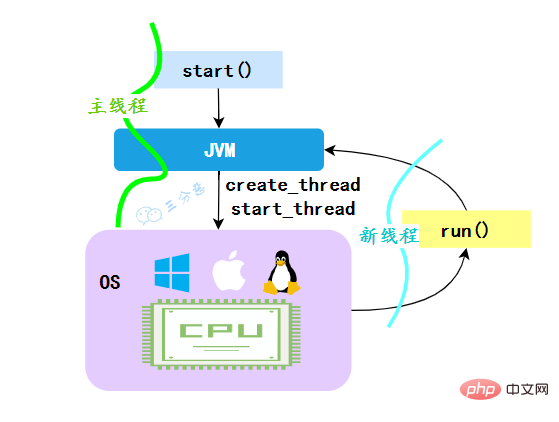
**為什麼我們不能直接呼叫run()方法? **也很清楚, 如果直接呼叫Thread的run()方法,那麼run方法還是運行在主執行緒中,相當於順序執行,就起不到多執行緒的效果。
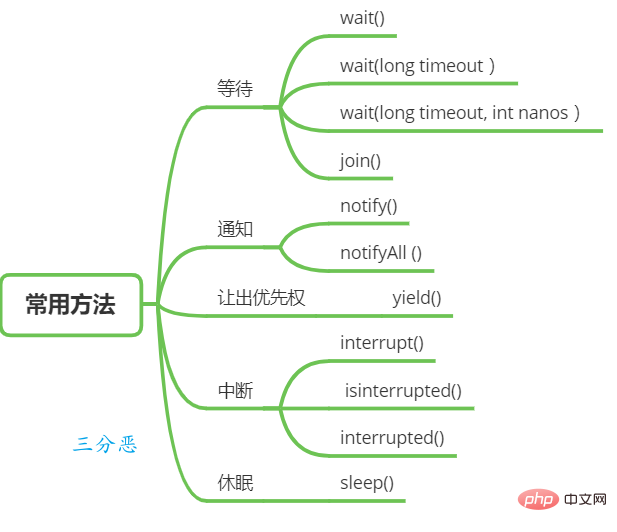
執行緒等待與通知
在Object類別中有一些函數可以用於執行緒的等待與通知。
wait():當一個執行緒A呼叫一個共享變數的wait()方法時, 執行緒A會被阻塞掛起, 發生下面幾種情況才會回傳:
(1) 線程A呼叫了共享物件notify()或notifyAll()方法;
(2)其他線程呼叫了線程A的interrupt() 方法,執行緒A拋出InterruptedException異常回傳。
wait(long timeout) :這個方法相比wait() 方法多了一個超時參數,它的不同之處在於,如果線程A呼叫共享物件的wait(long timeout)方法後,沒有在指定的timeout ms時間內被其它執行緒喚醒,那麼這個方法還是會因為逾時而回傳。
wait(long timeout, int nanos),其內部呼叫的是 wait(long timout)函數。
上面是執行緒等待的方法,而喚醒執行緒主要是下面兩個方法:
Thread類別也提供了一個方法用於等待的方法:
#join():如果一個執行緒A執行了thread.join()語句,其意義是:當前執行緒A等待thread執行緒終止之後才
從thread.join()返回。
線程休眠
讓出優先權
執行緒中斷
Java 中的執行緒中斷是一種執行緒間的協作模式,透過設定執行緒的中斷標誌並不能直接終止該執行緒的執行,而是被中斷的執行緒根據中斷狀態自行處理。
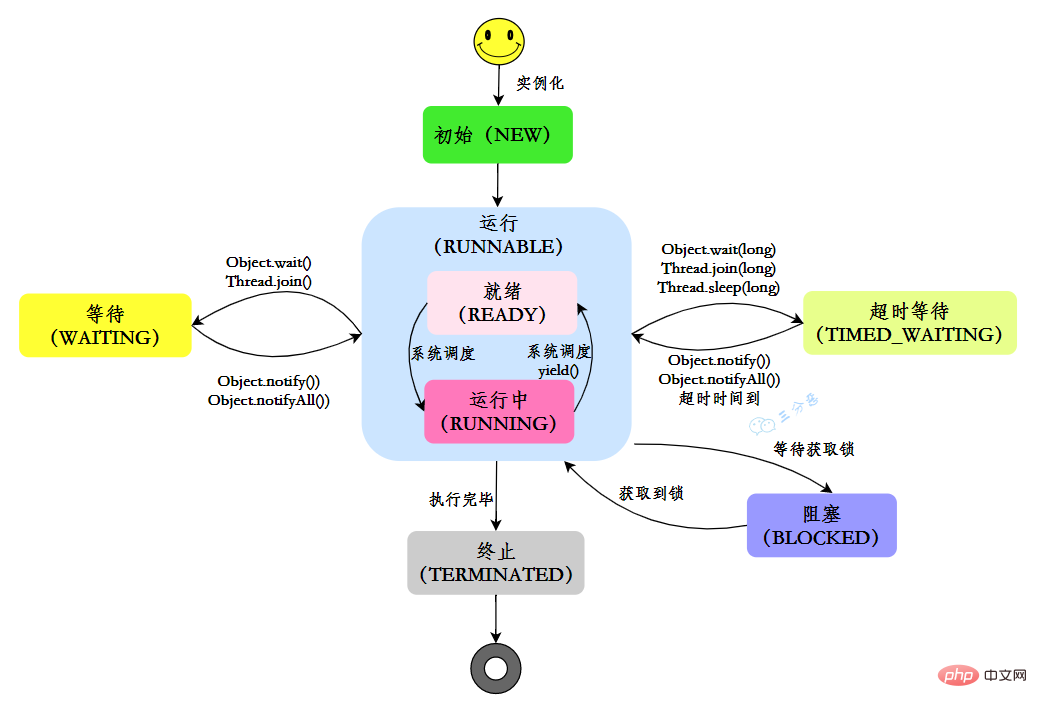
在Java中,執行緒共有六種狀態:
| #說明 | |
|---|---|
| NEW | |
| RUNNABLE | |
| #BLOCKED | |
| WAITING |
執行緒在自身的生命週期中, 並不是固定地處於某個狀態,而是隨著程式碼的執行在不同的狀態之間進行切換,Java執行緒狀態變化如圖示:
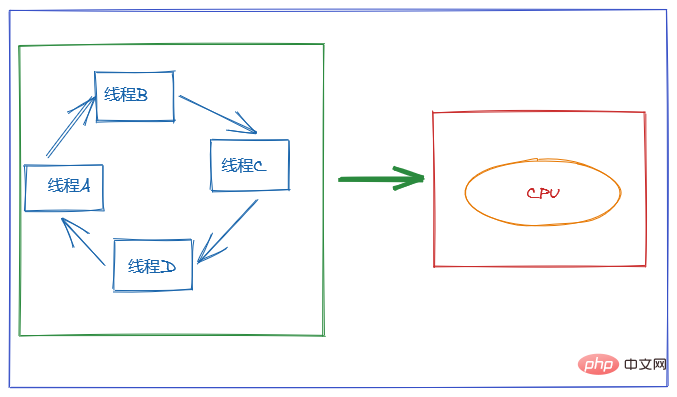
使用多執行緒的目的是為了充分利用CPU,但我們知道,並發其實是一個CPU來應付多個執行緒。
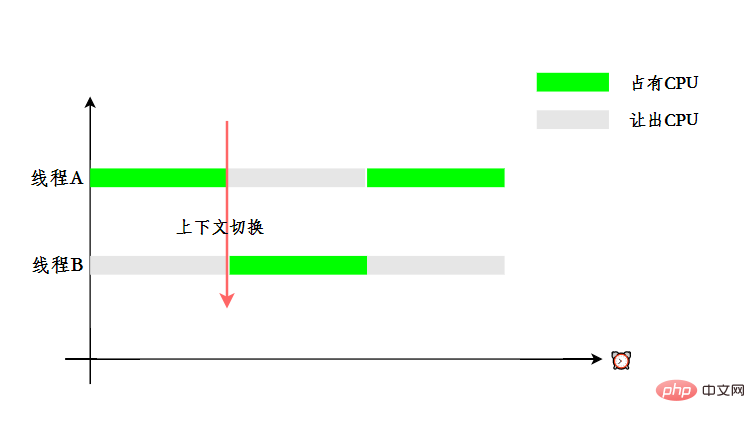
為了讓使用者感覺多個執行緒是在同時執行的, CPU 資源的分配採用了時間片輪轉也就是給每個執行緒分配一個時間片,執行緒在時間片內佔用CPU 執行任務。當執行緒使用完時間片後,就會處於就緒狀態並讓出 CPU 讓其他執行緒佔用,這就是上下文切換。
Java中的執行緒分為兩類,分別為 daemon 執行緒(守護執行緒)和 user 執行緒(使用者執行緒)。
在JVM 啟動時會呼叫 main 函數,main函數所在的錢程就是一個使用者執行緒。其實在 JVM 內部同時也啟動了許多守護線程,像是垃圾回收線程。
那麼守護線程和使用者線程有什麼差別呢?其中一個差異是當最後一個非守護線程束時, JVM會正常退出,而不管當前是否存在守護線程,也就是說守護線程是否結束並不會影響 JVM退出。換而言之,只要有一個使用者執行緒還沒結束,正常情況下JVM就不會退出。
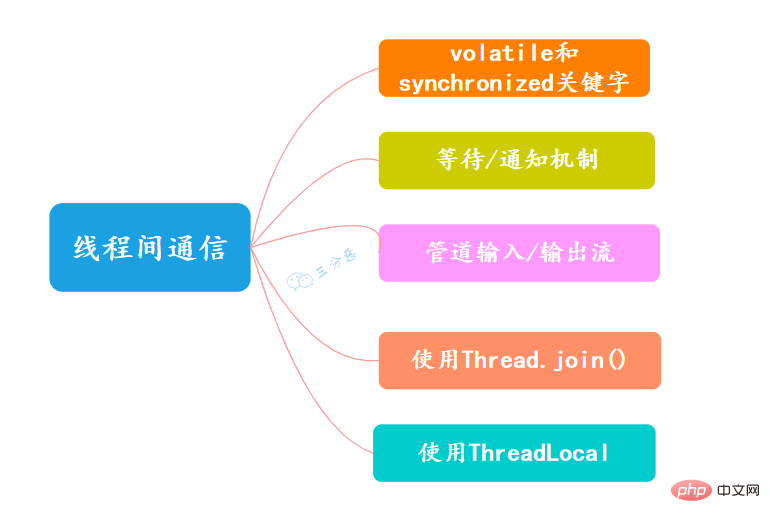
關鍵字volatile可以用來修飾欄位(成員變數) ,就是告知程式任何對該變數的存取均需要從共享記憶體中獲取,而對它的改變必須同步刷新回共享內存,它能保證所有執行緒對變數存取的可見性。
關鍵字synchronized可以修飾方法或以同步區塊的形式來進行使用,它主要確保多個執行緒在同一個時刻,只能有一個執行緒處於方法或同步區塊中,它保證了執行緒對變數存取的可見性和排他性。
可以透過Java內建的等待/通知機制(wait()/notify())實作一個執行緒修改一個物件的值,而另一個執行緒感知到了變化,然後進行相應的操作。
管道輸入/輸出流和普通的檔案輸入/輸出流或網路輸入/輸出流不同之處在於,它主要用於線程之間的資料傳輸,而傳輸的媒介為記憶體。
管道輸入/輸出流主要包括如下4種具體實作:PipedOutputStream、PipedInputStream、 PipedReader和PipedWriter,前兩種面向字節,而後兩種面向字元。
#如果一個執行緒A執行了thread.join()語句,其意義是:目前執行緒A等待thread執行緒終止之後才從thread.join()返回。 。執行緒Thread除了提供join()方法之外,還提供了join(long millis)和join(long millis,int nanos)兩個具備超時特性的方法。
ThreadLocal,即執行緒變數,是一個以ThreadLocal物件為鍵、任意物件為值的儲存結構。這個結構被附帶在線程上,也就是說一個線程可以根據一個ThreadLocal物件查詢到綁定在這個線程上的一個值。
可以透過set(T)方法來設定一個值,在目前執行緒下再透過get()方法取得到原先設定的值。
關於多線程,其實很大機率還會出一些筆試題,例如交替列印、銀行轉帳、生產消費模型等等,後面老三會單獨出一期來盤點一下常見的多執行緒筆試題。
ThreadLocal其實應用場景不是很多,但卻是被炸了千百遍的面試老油條,涉及到多線程、資料結構、JVM,可問的點比較多,一定要拿下。
ThreadLocal,也就是執行緒本地變數。如果你創建了一個ThreadLocal變量,那麼訪問這個變量的每個線程都會有這個變量的一個本地拷貝,多個線程操作這個變量的時候,實際上是操作自己本地內存裡面的變量,從而起到線程隔離的作用,避免了線程安全問題。
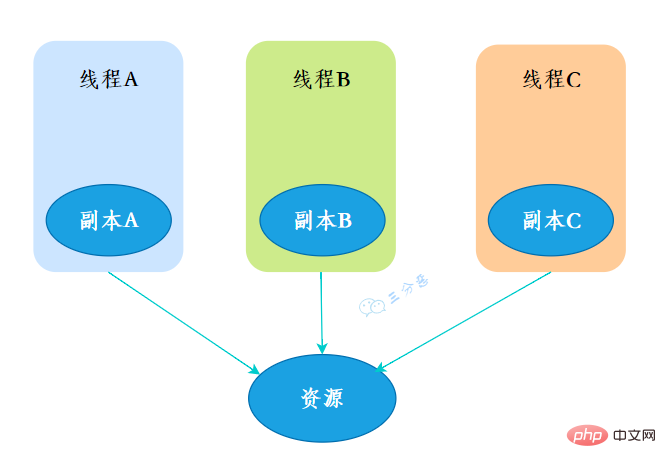
创建了一个ThreadLoca变量localVariable,任何一个线程都能并发访问localVariable。
//创建一个ThreadLocal变量public static ThreadLocal<string> localVariable = new ThreadLocal();</string>
线程可以在任何地方使用localVariable,写入变量。
localVariable.set("鄙人三某”);线程在任何地方读取的都是它写入的变量。
localVariable.get();
有用到过的,用来做用户信息上下文的存储。
我们的系统应用是一个典型的MVC架构,登录后的用户每次访问接口,都会在请求头中携带一个token,在控制层可以根据这个token,解析出用户的基本信息。那么问题来了,假如在服务层和持久层都要用到用户信息,比如rpc调用、更新用户获取等等,那应该怎么办呢?
一种办法是显式定义用户相关的参数,比如账号、用户名……这样一来,我们可能需要大面积地修改代码,多少有点瓜皮,那该怎么办呢?
这时候我们就可以用到ThreadLocal,在控制层拦截请求把用户信息存入ThreadLocal,这样我们在任何一个地方,都可以取出ThreadLocal中存的用户数据。
很多其它场景的cookie、session等等数据隔离也都可以通过ThreadLocal去实现。
我们常用的数据库连接池也用到了ThreadLocal:
我们看一下ThreadLocal的set(T)方法,发现先获取到当前线程,再获取ThreadLocalMap,然后把元素存到这个map中。
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//获取ThreadLocalMap
ThreadLocalMap map = getMap(t);
//讲当前元素存入map
if (map != null)
map.set(this, value);
else
createMap(t, value);
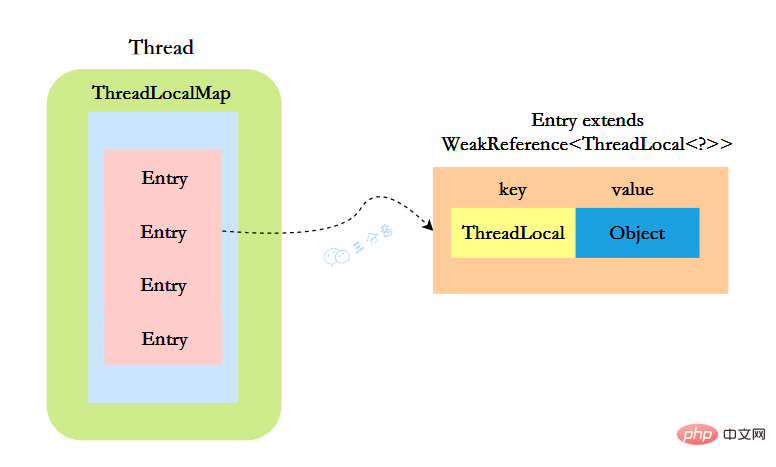
}ThreadLocal实现的秘密都在这个ThreadLocalMap了,可以Thread类中定义了一个类型为ThreadLocal.ThreadLocalMap的成员变量threadLocals。
public class Thread implements Runnable {
//ThreadLocal.ThreadLocalMap是Thread的属性
ThreadLocal.ThreadLocalMap threadLocals = null;}ThreadLocalMap既然被称为Map,那么毫无疑问它是
static class Entry extends WeakReference<threadlocal>> {
/** The value associated with this ThreadLocal. */
Object value;
//节点类
Entry(ThreadLocal> k, Object v) {
//key赋值
super(k);
//value赋值
value = v;
}
}</threadlocal>这里的节点,key可以简单低视作ThreadLocal,value为代码中放入的值,当然实际上key并不是ThreadLocal本身,而是它的一个弱引用,可以看到Entry的key继承了 WeakReference(弱引用),再来看一下key怎么赋值的:
public WeakReference(T referent) {
super(referent);
}key的赋值,使用的是WeakReference的赋值。
所以,怎么回答ThreadLocal原理?要答出这几个点:
我们先来分析一下使用ThreadLocal时的内存,我们都知道,在JVM中,栈内存线程私有,存储了对象的引用,堆内存线程共享,存储了对象实例。
所以呢,栈中存储了ThreadLocal、Thread的引用,堆中存储了它们的具体实例。
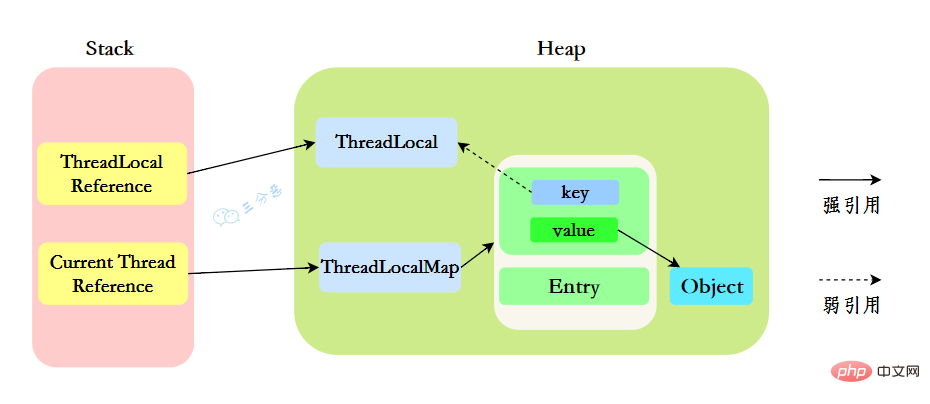
ThreadLocalMap中使用的 key 为 ThreadLocal 的弱引用。
“弱引用:只要垃圾回收机制一运行,不管JVM的内存空间是否充足,都会回收该对象占用的内存。”
那么现在问题就来了,弱引用很容易被回收,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是ThreadLocalMap生命周期和Thread是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap的key没了,value还在,这就会造成了内存泄漏问题。
那怎么解决内存泄漏问题呢?
很简单,使用完ThreadLocal后,及时调用remove()方法释放内存空间。
ThreadLocallocalVariable = new ThreadLocal();try { localVariable.set("鄙人三某”); ……} finally { localVariable.remove();}
那为什么key还要设计成弱引用?
key设计成弱引用同样是为了防止内存泄漏。
假如key被设计成强引用,如果ThreadLocal Reference被销毁,此时它指向ThreadLoca的强引用就没有了,但是此时key还强引用指向ThreadLoca,就会导致ThreadLocal不能被回收,这时候就发生了内存泄漏的问题。
ThreadLocalMap虽然被叫做Map,其实它是没有实现Map接口的,但是结构还是和HashMap比较类似的,主要关注的是两个要素:元素数组和散列方法。
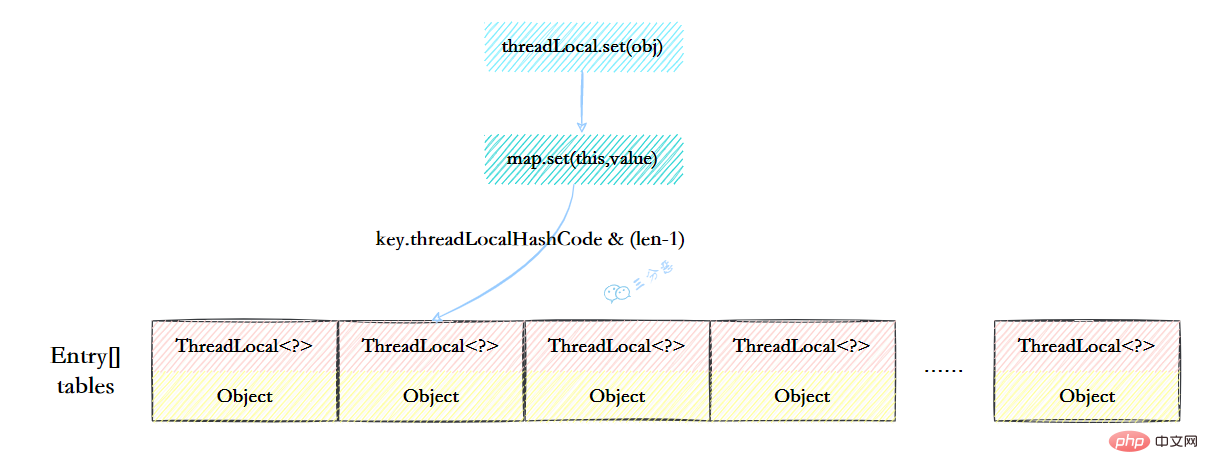
元素数组
一个table数组,存储Entry类型的元素,Entry是ThreaLocal弱引用作为key,Object作为value的结构。
private Entry[] table;
散列方法
散列方法就是怎么把对应的key映射到table数组的相应下标,ThreadLocalMap用的是哈希取余法,取出key的threadLocalHashCode,然后和table数组长度减一&运算(相当于取余)。
int i = key.threadLocalHashCode & (table.length - 1);
这里的threadLocalHashCode计算有点东西,每创建一个ThreadLocal对象,它就会新增0x61c88647,这个值很特殊,它是斐波那契数 也叫 黄金分割数。hash增量为 这个数字,带来的好处就是 hash 分布非常均匀。
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}我们可能都知道HashMap使用了链表来解决冲突,也就是所谓的链地址法。
ThreadLocalMap没有使用链表,自然也不是用链地址法来解决冲突了,它用的是另外一种方式——开放定址法。开放定址法是什么意思呢?简单来说,就是这个坑被人占了,那就接着去找空着的坑。
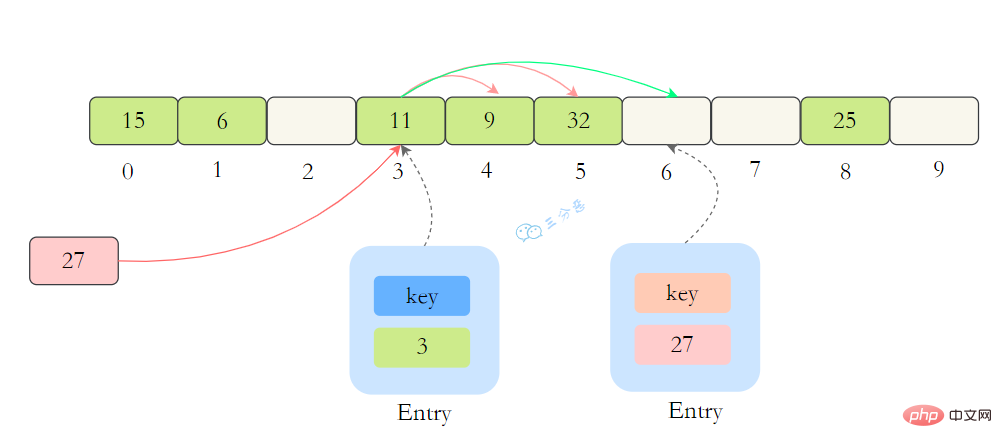
如上图所示,如果我们插入一个value=27的数据,通过 hash计算后应该落入第 4 个槽位中,而槽位 4 已经有了 Entry数据,而且Entry数据的key和当前不相等。此时就会线性向后查找,一直找到 Entry为 null的槽位才会停止查找,把元素放到空的槽中。
在get的时候,也会根据ThreadLocal对象的hash值,定位到table中的位置,然后判断该槽位Entry对象中的key是否和get的key一致,如果不一致,就判断下一个位置。
在ThreadLocalMap.set()方法的最后,如果执行完启发式清理工作后,未清理到任何数据,且当前散列数组中Entry的数量已经达到了列表的扩容阈值(len*2/3),就开始执行rehash()逻辑:
if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();
再着看rehash()具体实现:这里会先去清理过期的Entry,然后还要根据条件判断size >= threshold - threshold / 4 也就是size >= threshold* 3/4来决定是否需要扩容。
private void rehash() {
//清理过期Entry
expungeStaleEntries();
//扩容
if (size >= threshold - threshold / 4)
resize();}//清理过期Entryprivate void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j <p>接着看看具体的<code>resize()</code>方法,扩容后的<code>newTab</code>的大小为老数组的两倍,然后遍历老的table数组,散列方法重新计算位置,开放地址解决冲突,然后放到新的<code>newTab</code>,遍历完成之后,<code>oldTab</code>中所有的<code>entry</code>数据都已经放入到<code>newTab</code>中了,然后table引用指向<code>newTab</code></p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/6137d48077cbb320beee2007e8763d69-16.png" class="lazy" alt="歸納整理Java並發知識點"></p><p>具体代码:</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/85310a4f8d2bb86283cd76fb2542424d-17.png" class="lazy" alt="ThreadLocalMap resize"></p><h2>17.父子线程怎么共享数据?</h2><p>父线程能用ThreadLocal来给子线程传值吗?毫无疑问,不能。那该怎么办?</p><p>这时候可以用到另外一个类——<code>InheritableThreadLocal</code>。</p><p>使用起来很简单,在主线程的InheritableThreadLocal实例设置值,在子线程中就可以拿到了。</p><pre class="brush:php;toolbar:false">public class InheritableThreadLocalTest {
public static void main(String[] args) {
final ThreadLocal threadLocal = new InheritableThreadLocal();
// 主线程
threadLocal.set("不擅技术");
//子线程
Thread t = new Thread() {
@Override
public void run() {
super.run();
System.out.println("鄙人三某 ," + threadLocal.get());
}
};
t.start();
}}那原理是什么呢?
原理很简单,在Thread类里还有另外一个变量:
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
在Thread.init的时候,如果父线程的inheritableThreadLocals不为空,就把它赋给当前线程(子线程)的inheritableThreadLocals。
if (inheritThreadLocals && parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals)
歸納整理Java並發知識點(Java Memory Model,JMM),是一种抽象的模型,被定义出来屏蔽各种硬件和操作系统的内存访问差异。
JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。
歸納整理Java並發知識點的抽象图:
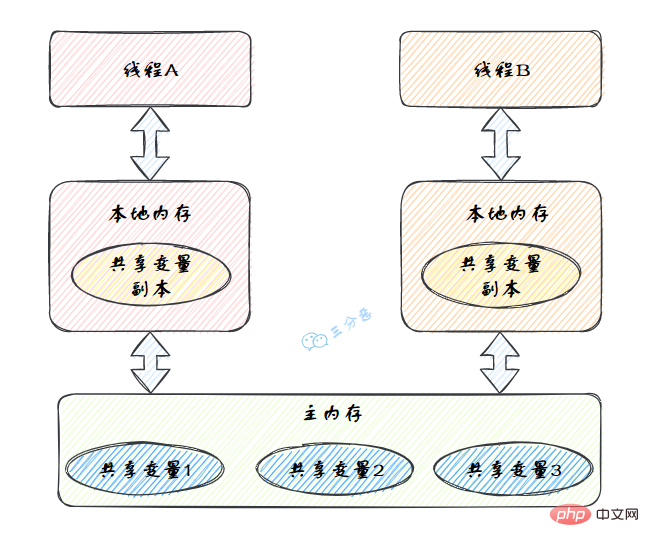
本地内存是JMM的 一个抽象概念,并不真实存在。它其实涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
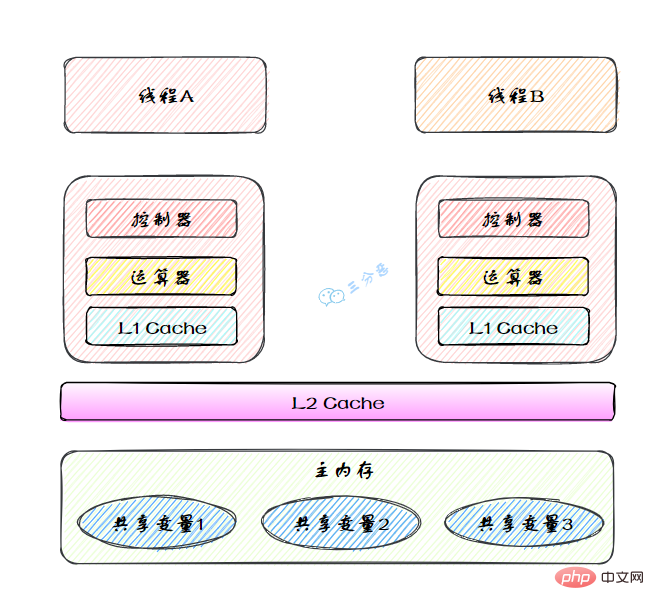
图里面的是一个双核 CPU 系统架构 ,每个核有自己的控制器和运算器,其中控制器包含一组寄存器和操作控制器,运算器执行算术逻辅运算。每个核都有自己的一级缓存,在有些架构里面还有一个所有 CPU 共享的二级缓存。 那么 Java 内存模型里面的工作内存,就对应这里的 Ll 缓存或者 L2 缓存或者 CPU 寄存器。
原子性、有序性、可见性是并发编程中非常重要的基础概念,JMM的很多技术都是围绕着这三大特性展开。
分析下面几行代码的原子性?
int i = 2;int j = i;i++;i = i + 1;
原子性、可见性、有序性都应该怎么保证呢?
synchronized。volatile关键字来保证可见性的,除此之外,final和synchronized也能保证可见性。synchronized或者volatile都可以保证多线程之间操作的有序性。在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序,如图:

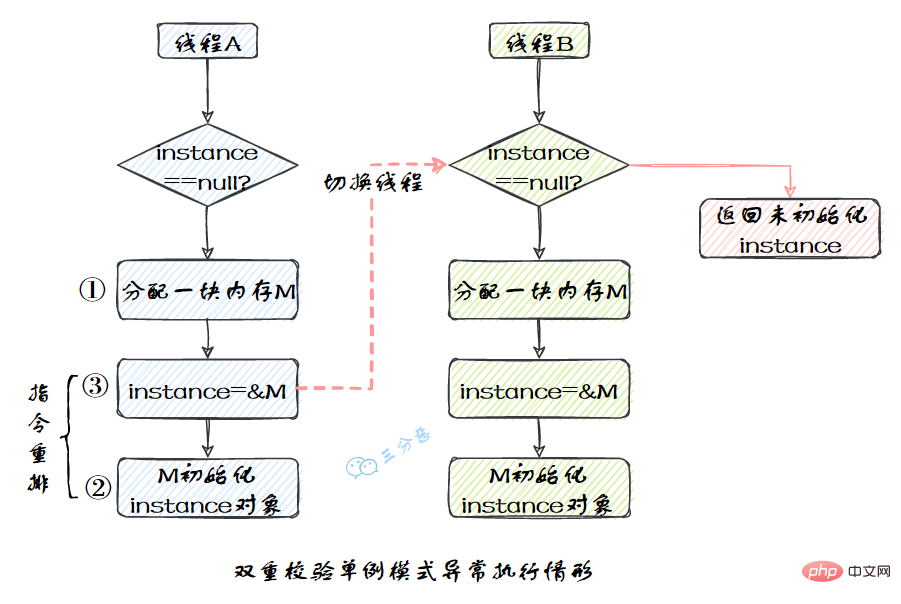
我们比较熟悉的双重校验单例模式就是一个经典的指令重排的例子,Singleton instance=new Singleton();对应的JVM指令分为三步:分配内存空间–>初始化对象—>对象指向分配的内存空间,但是经过了编译器的指令重排序,第二步和第三步就可能会重排序。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
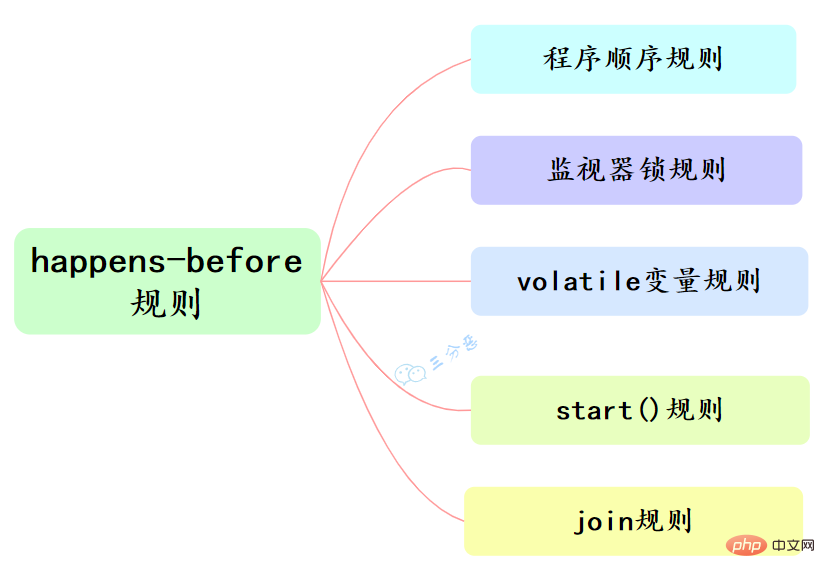
指令重排也是有一些限制的,有两个规则happens-before和as-if-serial来约束。
happens-before的定义:
happens-before和我们息息相关的有六大规则:
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度),单线程程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例。
double pi = 3.14; // Adouble r = 1.0; // B double area = pi * r * r; // C
上面3个操作的数据依赖关系:
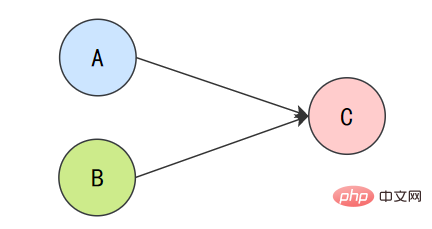
A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
所以最终,程序可能会有两种执行顺序:
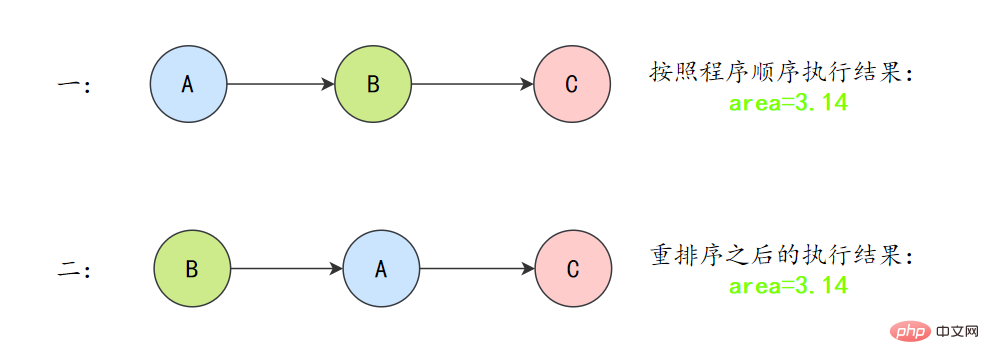
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器、runtime和处理器共同编织了这么一个“楚门的世界”:单线程程序是按程序的“顺序”来执行的。as- if-serial语义使单线程情况下,我们不需要担心重排序的问题,可见性的问题。
volatile有两个作用,保证可见性和有序性。
volatile怎么保证可见性的呢?
相比synchronized的加锁方式来解决共享变量的内存可见性问题,volatile就是更轻量的选择,它没有上下文切换的额外开销成本。
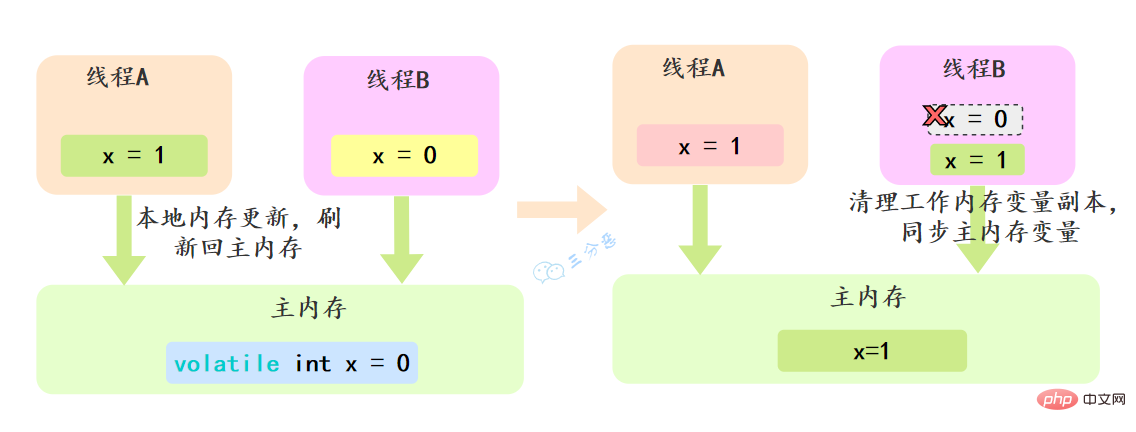
volatile可以确保对某个变量的更新对其他线程马上可见,一个变量被声明为volatile 时,线程在写入变量时不会把值缓存在寄存器或者其他地方,而是会把值刷新回主内存 当其它线程读取该共享变量 ,会从主内存重新获取最新值,而不是使用当前线程的本地内存中的值。
例如,我们声明一个 volatile 变量 volatile int x = 0,线程A修改x=1,修改完之后就会把新的值刷新回主内存,线程B读取x的时候,就会清空本地内存变量,然后再从主内存获取最新值。
volatile怎么保证有序性的呢?
重排序可以分为编译器重排序和处理器重排序,valatile保证有序性,就是通过分别限制这两种类型的重排序。
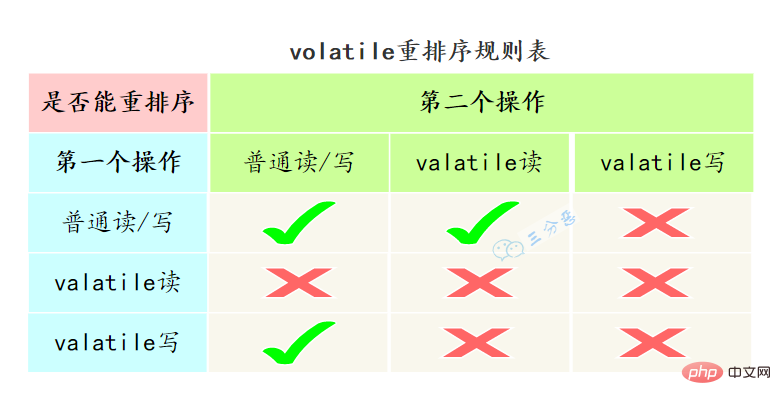
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
StoreStore屏障StoreLoad屏障LoadLoad屏障LoadStore屏障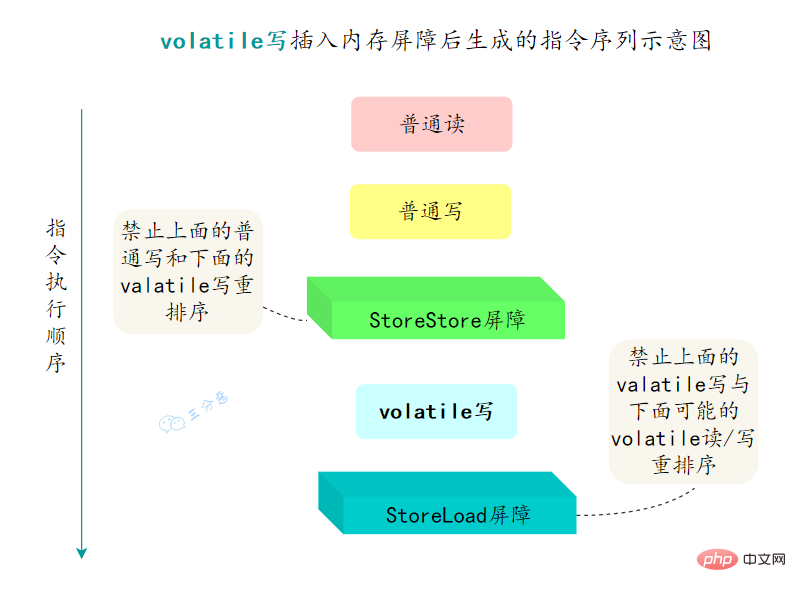
synchronized经常用的,用来保证代码的原子性。
synchronized主要有三种用法:
synchronized void method() {
//业务代码}修饰静态方法:也就是给当前类加锁,会作⽤于类的所有对象实例 ,进⼊同步代码前要获得当前 class 的锁。因为静态成员不属于任何⼀个实例对象,是类成员( static 表明这是该类的⼀个静态资源,不管 new 了多少个对象,只有⼀份)。
如果⼀个线程 A 调⽤⼀个实例对象的⾮静态 synchronized ⽅法,⽽线程 B 需要调⽤这个实例对象所属类的静态 synchronized ⽅法,是允许的,不会发⽣互斥现象,因为访问静态 synchronized ⽅法占⽤的锁是当前类的锁,⽽访问⾮静态 synchronized ⽅法占⽤的锁是当前实例对象锁。
synchronized void staic method() {
//业务代码}synchronized(this) {
//业务代码}synchronized是怎么加锁的呢?
我们使用synchronized的时候,发现不用自己去lock和unlock,是因为JVM帮我们把这个事情做了。
synchronized修饰代码块时,JVM采用monitorenter、monitorexit两个指令来实现同步,monitorenter 指令指向同步代码块的开始位置, monitorexit 指令则指向同步代码块的结束位置。
反编译一段synchronized修饰代码块代码,javap -c -s -v -l SynchronizedDemo.class,可以看到相应的字节码指令。
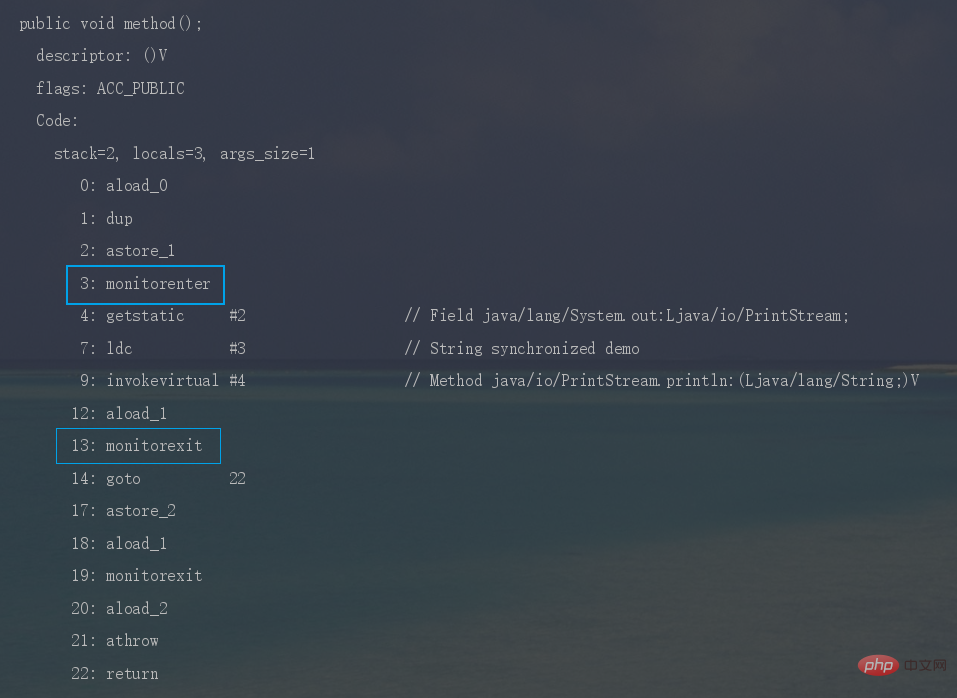
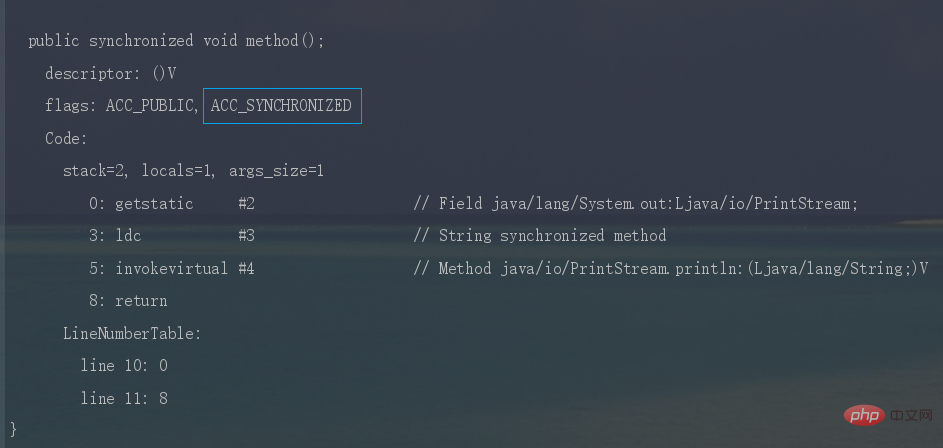
歸納整理Java並發知識點时,JVM采用ACC_SYNCHRONIZED标记符来实现同步,这个标识指明了该方法是一个同步方法。
同样可以写段代码反编译看一下。
synchronized锁住的是什么呢?
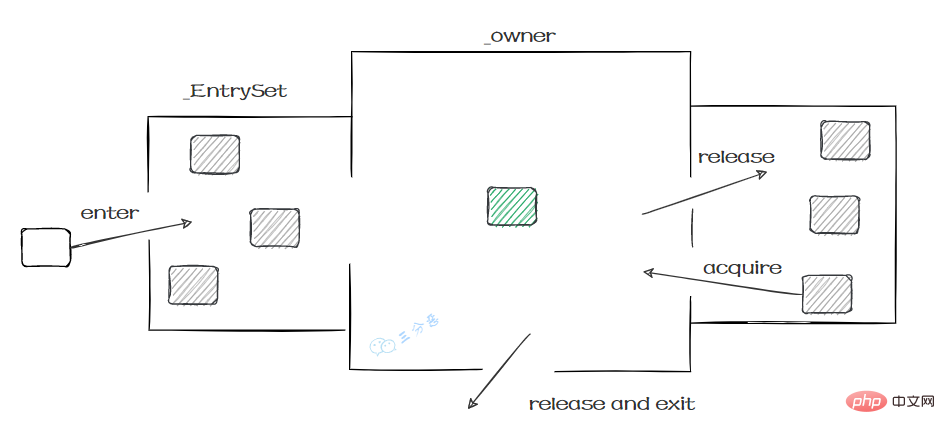
monitorenter、monitorexit或者ACC_SYNCHRONIZED都是基于Monitor实现的。
实例对象结构里有对象头,对象头里面有一块结构叫Mark Word,Mark Word指针指向了monitor。
所谓的Monitor其实是一种同步工具,也可以说是一种同步机制。在Java虚拟机(HotSpot)中,Monitor是由ObjectMonitor实现的,可以叫做内部锁,或者Monitor锁。
ObjectMonitor的工作原理:
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录线程获取锁的次数
_waiters = 0,
_recursions = 0; //锁的重入次数
_object = NULL;
_owner = NULL; // 指向持有ObjectMonitor对象的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}可以类比一个去医院就诊的例子[18]:
首先,患者在门诊大厅前台或自助挂号机进行挂号;
随后,挂号结束后患者找到对应的诊室就诊:
就诊结束后,走出就诊室,候诊室的下一位候诊患者进入就诊室。
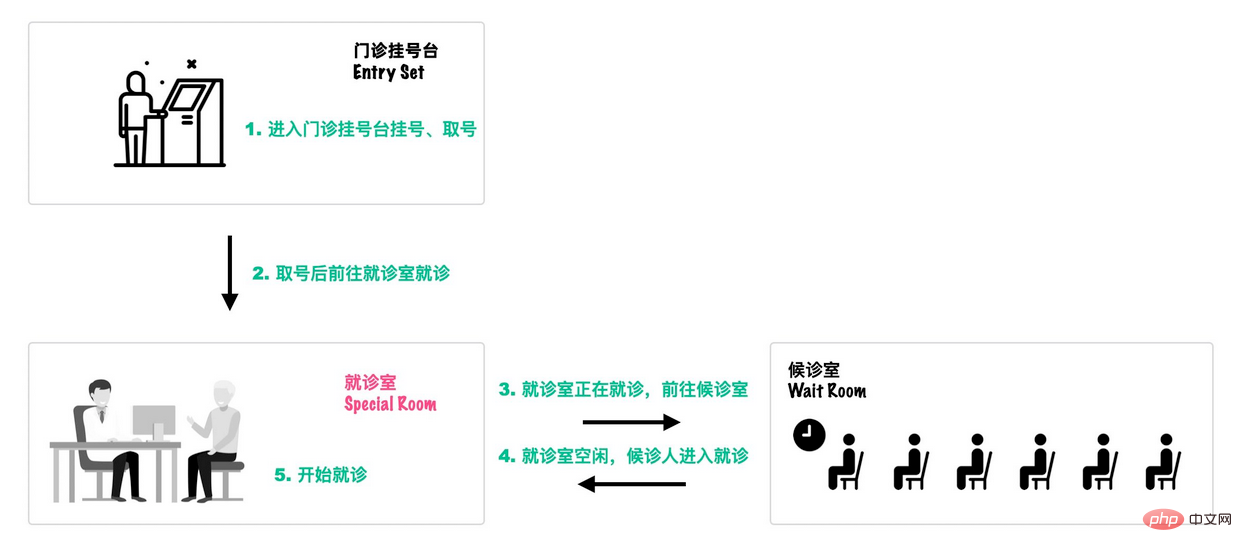
这个过程就和Monitor机制比较相似:
synchronized怎麼保證可見性?
synchronized怎麼保證有序性?synchronized同步的程式碼區塊,具有排他性,一次只能被一個執行緒擁有,所以synchronized保證同一時刻,程式碼是單執行緒執行的。 因為as-if-serial語意的存在,單執行緒的程式能保證最終結果是有順序的,但是不保證不會指令重排。 所以synchronized保證的順序是執行結果的有序性,而不是防止指令重排的有序性。
synchronized怎麼實現可重入的呢?synchronized 是可重入鎖,也就是說,允許一個執行緒二次請求自己持有物件鎖的臨界資源,這種情況稱為可重入鎖定。 synchronized 鎖定物件的時候有個計數器,他會記錄下執行緒取得鎖的次數,在執行完對應的程式碼區塊之後,計數器就會-1,直到計數器清零,就釋放鎖了。 之所以,是可重入的。是因為 synchronized 鎖定物件有計數器,會隨著執行緒取得鎖定後 1 計數,當執行緒執行完畢後 -1,直到清除釋放鎖定。 27.鎖定升級? synchronized優化了解嗎? 了解鎖升級,得先知道,不同鎖的狀態是什麼樣的。這個狀態指的是什麼呢? Java物件頭裡,有一塊結構,叫做
Mark Word#標記字段,這塊結構會隨著鎖的狀態變化而改變。
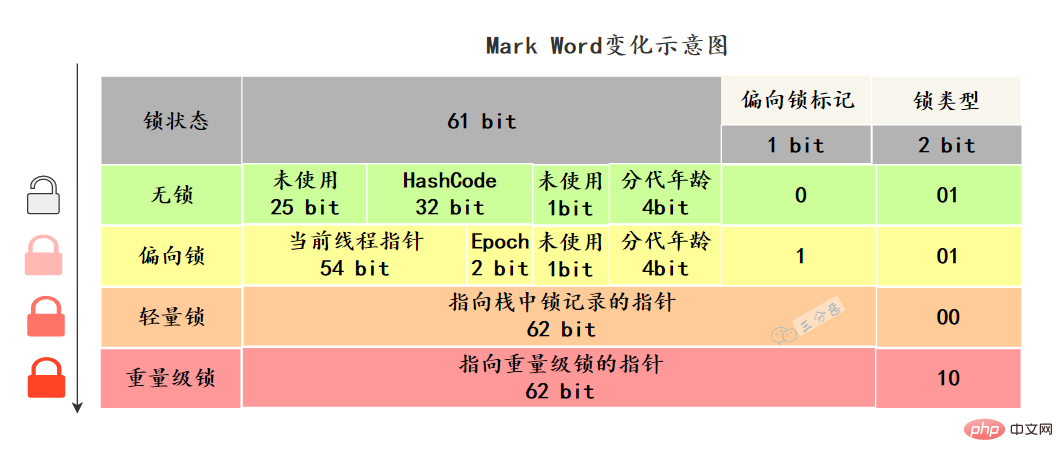
雜湊碼、GC分代年齡、鎖定狀態標誌、偏向時間戳記(Epoch) 等。
synchronized做了哪些最佳化?在JDK1.6之前,synchronized的實作直接呼叫ObjectMonitor的enter和exit,這種鎖被稱為
重量級鎖定。從JDK6開始,HotSpot虛擬機開發團隊對Java中的鎖進行最佳化,例如增加了適應性自旋、鎖定消除、鎖定粗化、輕量級鎖定和偏向鎖等最佳化策略,提升了synchronized的效能。
鎖定升級的過程是什麼樣的?鎖定升級方向:無鎖–>偏向鎖—> 輕量級鎖定---->重量級鎖,這個方向基本上是不可逆的。

######################################## #
偏向鎖定的撤銷:
輕量級鎖定的取得:
大體上省簡的升級過程:
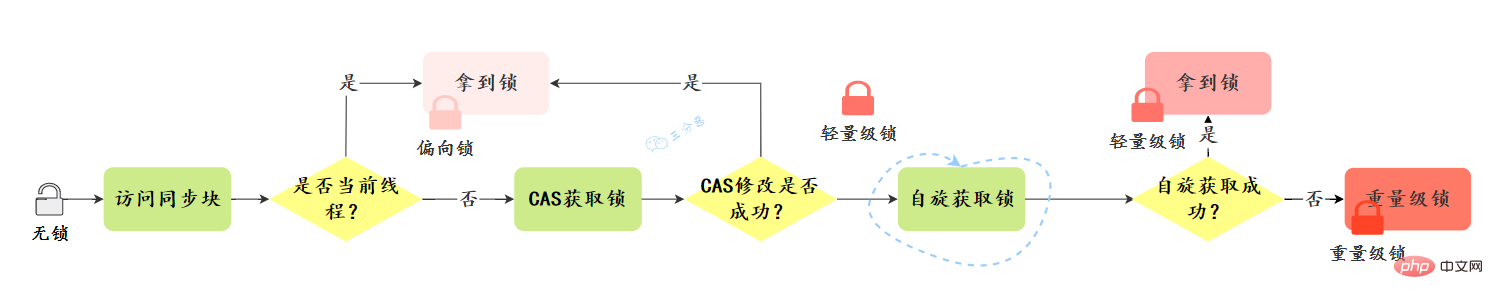
完整的升級過程:
![synchronized 锁升级过程-来源参考[14]](https://img.php.cn/upload/article/000/000/067/2ef068e2d2216314dc9ad545dda17019-36.png)
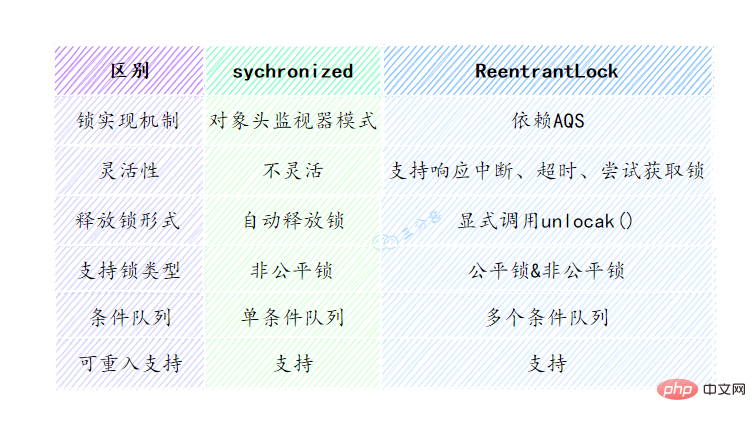
可以從鎖的實作、功能特點、效能等幾個維度去回答這個問題:
下面的表格列出了兩種鎖定之間的差異:
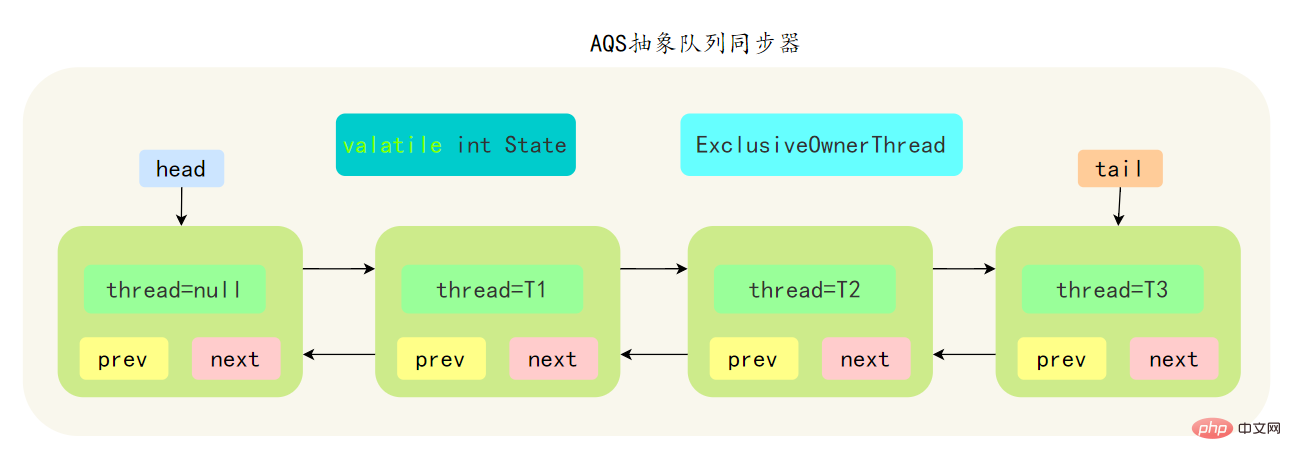
AbstractQueuedSynchronizer 抽象同步佇列,簡稱 AQS ,它是Java並發包的根基,並發包中的鎖就是基於AQS實現的。
 先简单了解一下CLH:Craig、Landin and Hagersten 队列,是 单向链表实现的队列。申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现 前驱节点释放了锁就结束自旋
先简单了解一下CLH:Craig、Landin and Hagersten 队列,是 单向链表实现的队列。申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现 前驱节点释放了锁就结束自旋
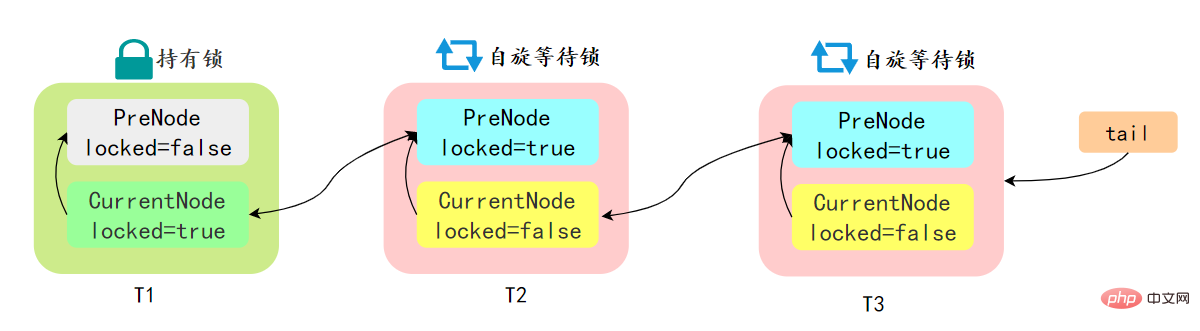
AQS 中的队列是 CLH 变体的虚拟双向队列,通过将每条请求共享资源的线程封装成一个节点来实现锁的分配:
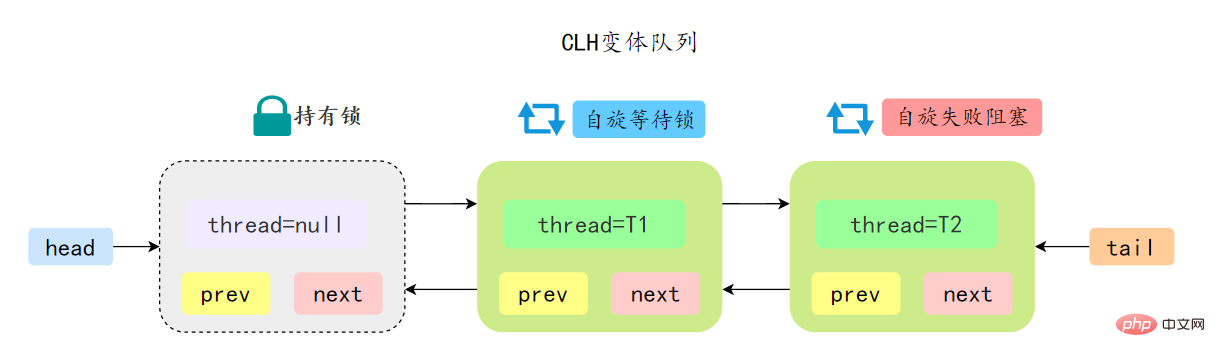
AQS 中的 CLH 变体等待队列拥有以下特性:
ps:AQS源码里面有很多细节可问,建议有时间好好看看AQS源码。
ReentrantLock 是可重入的独占锁,只能有一个线程可以获取该锁,其它获取该锁的线程会被阻塞而被放入该锁的阻塞队列里面。
看看ReentrantLock的加锁操作:
// 创建非公平锁
ReentrantLock lock = new ReentrantLock();
// 获取锁操作
lock.lock();
try {
// 执行代码逻辑
} catch (Exception ex) {
// ...
} finally {
// 解锁操作
lock.unlock();
}new ReentrantLock()构造函数默认创建的是非公平锁 NonfairSync。
公平锁 FairSync
非公平锁 NonfairSync
默认创建的对象lock()的时候:
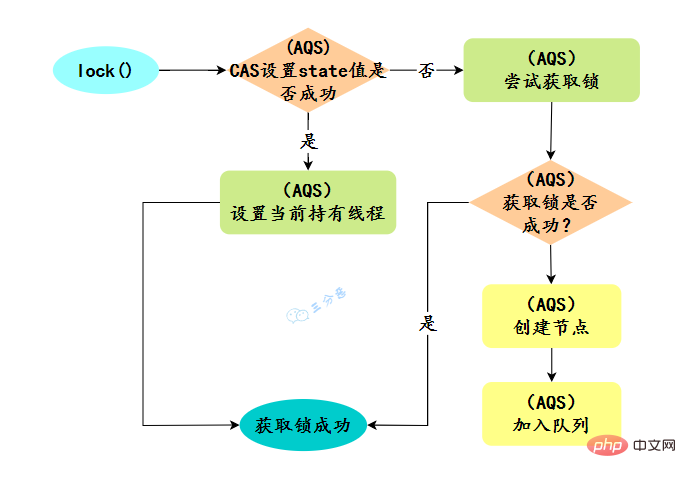
new ReentrantLock()构造函数默认创建的是非公平锁 NonfairSync
public ReentrantLock() {
sync = new NonfairSync();}同时也可以在创建锁构造函数中传入具体参数创建公平锁 FairSync
ReentrantLock lock = new ReentrantLock(true);--- ReentrantLock// true 代表公平锁,false 代表非公平锁public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();}FairSync、NonfairSync 代表公平锁和非公平锁,两者都是 ReentrantLock 静态内部类,只不过实现不同锁语义。
非公平锁和公平锁的两处不同:
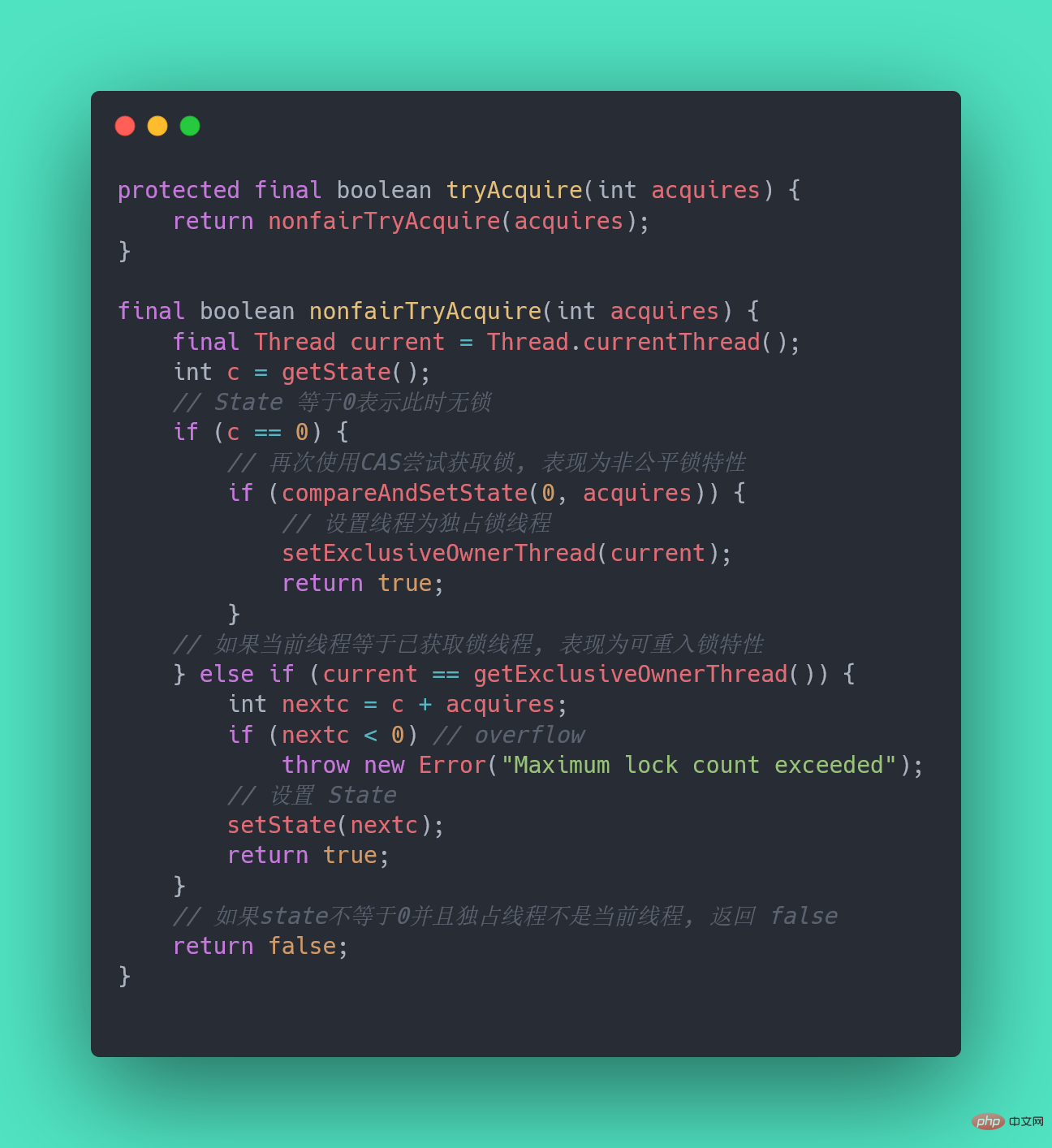
相對來說,非公平鎖定會有更好的效能,因為它的吞吐量比較大。當然,非公平鎖定讓獲取鎖的時間變得更加不確定,可能會導致在阻塞佇列中的執行緒長期處於飢餓狀態。
CAS叫做CompareAndSwap,⽐較並交換,主要是透過處理器的指令來保證操作的原⼦性的。
CAS 指令包含 3 個參數:共享變數的記憶體位址 A、預期的值 B 和共享變數的新值 C。
只有當記憶體中位址 A 處的值等於 B 時,才能將記憶體中位址 A 處的值更新為新值 C。作為一條 CPU 指令,CAS 指令本身是能夠保證原子性的 。
CAS的經典三大問題:
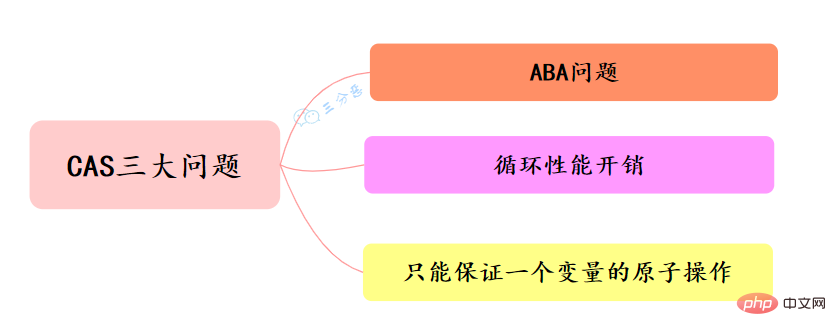
並發環境下,假設初始條件是A,去修改資料時,發現是A就會執行修改。但看到的雖然是A,中間可能發生了A變B,B又變回A的情況。此時A已經非彼A,資料即使成功修改,也可能有問題。
怎麼解決ABA問題?
每次修改變量,都在這個變數的版本號碼上加1,這樣,剛剛A->B-> ;A,雖然A的值沒變,但是它的版本號已經變了,再判斷版本號就會發現此時的A已經被改過了。參考樂觀鎖的版本號,這種做法可以為資料帶上了一種實效性的檢驗。
Java提供了AtomicStampReference類,它的compareAndSet方法首先檢查當前的物件參考值是否等於預期引用,並且當前印戳(Stamp)標誌是否等於預期標誌,如果全部相等,則以原子方式將引用值和印戳標誌的值更新為給定的更新值。
自旋CAS,如果一直循環執行,一直不成功,會為CPU帶來非常大的執行開銷。
怎麼解決循環效能開銷問題?
在Java中,許多使用自旋CAS的地方,會有一個自旋次數的限制,超過一定次數,就停止自旋。
CAS 保證的是對一個變數執行操作的原子性,如果對多個變數操作時,CAS 目前無法直接保證操作的原子性的。
怎麼解決只能保證一個變數的原子操作問題?
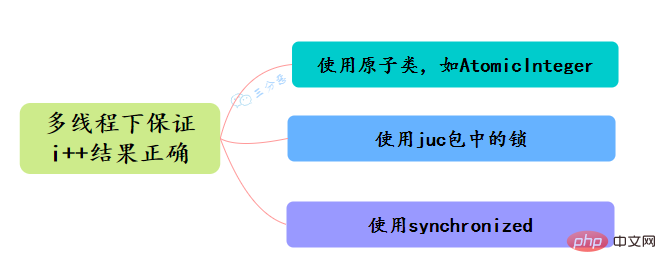
當程式更新一個變數時,如果多執行緒同時更新這個變量,可能得到期望之外的值,例如變數i=1,A執行緒更新i 1,B執行緒也更新i 1,經過兩個執行緒操作之後可能i不等於3,而是等於2。因為A和B執行緒在更新變數i的時候拿到的i都是1,這就是執行緒不安全的更新操作,一般我們會使用synchronized來解決這個問題,synchronized會保證多執行緒不會同時更新變數i。
其實除此之外,還有更輕量級的選擇,Java從JDK 1.5開始提供了java.util.concurrent.atomic包,這個包中的原子操作類別提供了一種用法簡單、效能高效、線程安全地更新一個變數的方式。
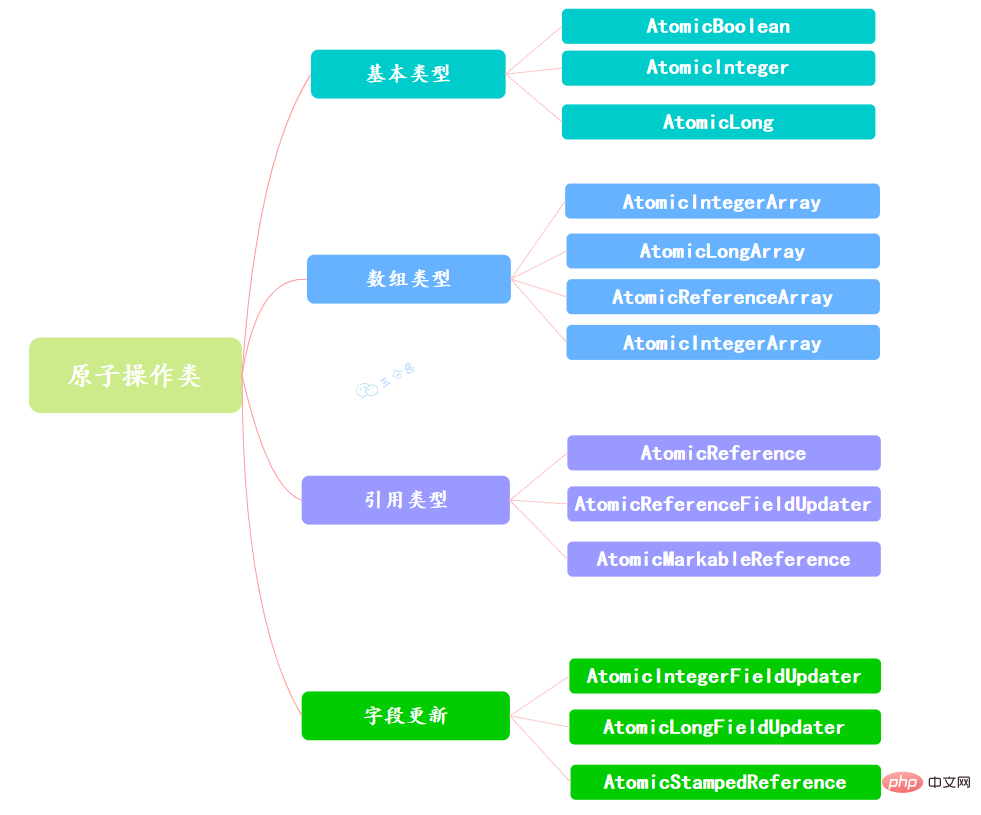
因為變數的型別有很多種,所以在Atomic套件裡一共提供了13個類,屬於4種類型的原子更新方式,分別是原子更新基本型別、原子更新陣列、原子更新引用和原子更新屬性(字段)。
Atomic套件裡的類別基本上都是使用Unsafe實作的包裝類別。
使用原子的方式更新基本类型,Atomic包提供了以下3个类:
AtomicBoolean:原子更新布尔类型。
AtomicInteger:原子更新整型。
AtomicLong:原子更新长整型。
通过原子的方式更新数组里的某个元素,Atomic包提供了以下4个类:
AtomicIntegerArray:原子更新整型数组里的元素。
AtomicLongArray:原子更新长整型数组里的元素。
AtomicReferenceArray:原子更新引用类型数组里的元素。
AtomicIntegerArray类主要是提供原子的方式更新数组里的整型
原子更新基本类型的AtomicInteger,只能更新一个变量,如果要原子更新多个变量,就需要使用这个原子更新引用类型提供的类。Atomic包提供了以下3个类:
AtomicReference:原子更新引用类型。
AtomicReferenceFieldUpdater:原子更新引用类型里的字段。
AtomicMarkableReference:原子更新带有标记位的引用类型。可以原子更新一个布尔类型的标记位和引用类型。构造方法是AtomicMarkableReference(V initialRef,boolean initialMark)。
如果需原子地更新某个类里的某个字段时,就需要使用原子更新字段类,Atomic包提供了以下3个类进行原子字段更新:
一句话概括:使用CAS实现。
以AtomicInteger的添加方法为例:
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}通过Unsafe类的实例来进行添加操作,来看看具体的CAS操作:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}compareAndSwapInt 是一个native方法,基于CAS来操作int类型变量。其它的歸納整理Java並發知識點基本都是大同小异。
死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的互相等待的现象,在无外力作用的情况下,这些线程会一直相互等待而无法继续运行下去。
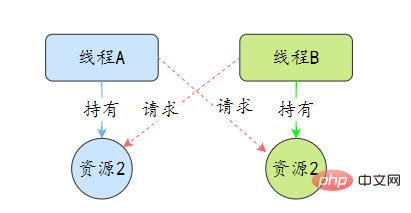
那么为什么会产生死锁呢? 死锁的产生必须具备以下四个条件:
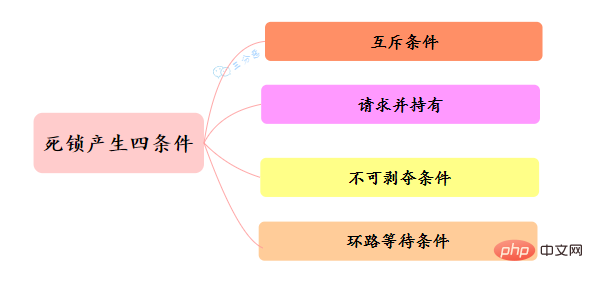
该如何避免死锁呢?答案是至少破坏死锁发生的一个条件。
其中,互斥这个条件我们没有办法破坏,因为用锁为的就是互斥。不过其他三个条件都是有办法破坏掉的,到底如何做呢?
对于“请求并持有”这个条件,可以一次性请求所有的资源。
对于“不可剥夺”这个条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。
对于“环路等待”这个条件,可以靠按序申请资源来预防。所谓按序申请,是指资源是有线性顺序的,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样线性化后就不存在环路了。
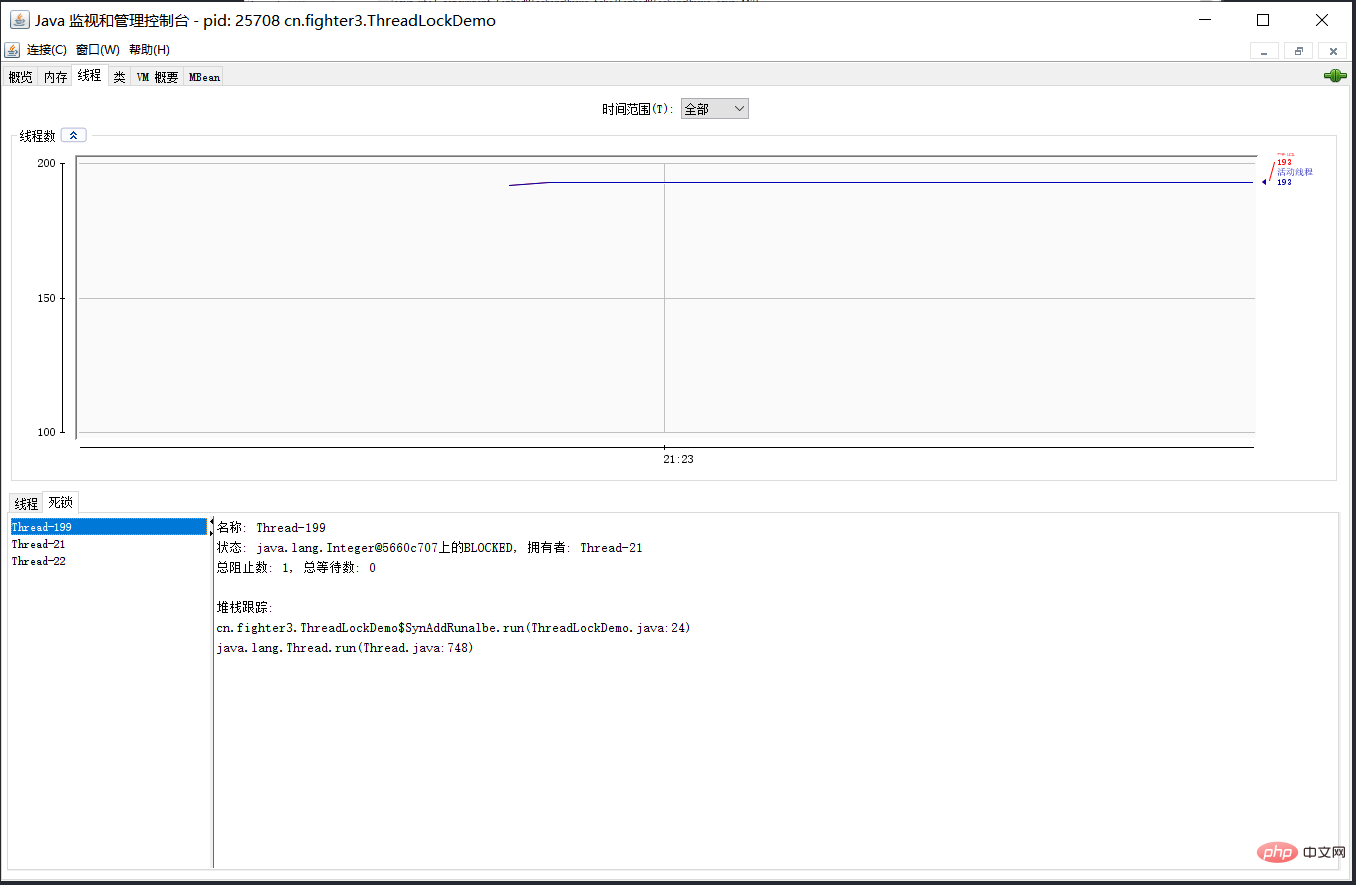
可以使用jdk自带的命令行工具排查:
基本就可以看到死锁的信息。
还可以利用图形化工具,比如JConsole。出现线程死锁以后,点击JConsole线程面板的检测到死锁按钮,将会看到线程的死锁信息。
CountDownLatch,倒计数器,有两个常见的应用场景[18]:
场景1:协调子线程结束动作:等待所有子线程运行结束
CountDownLatch允许一个或多个线程等待其他线程完成操作。
例如,我们很多人喜欢玩的王者荣耀,开黑的时候,得等所有人都上线之后,才能开打。
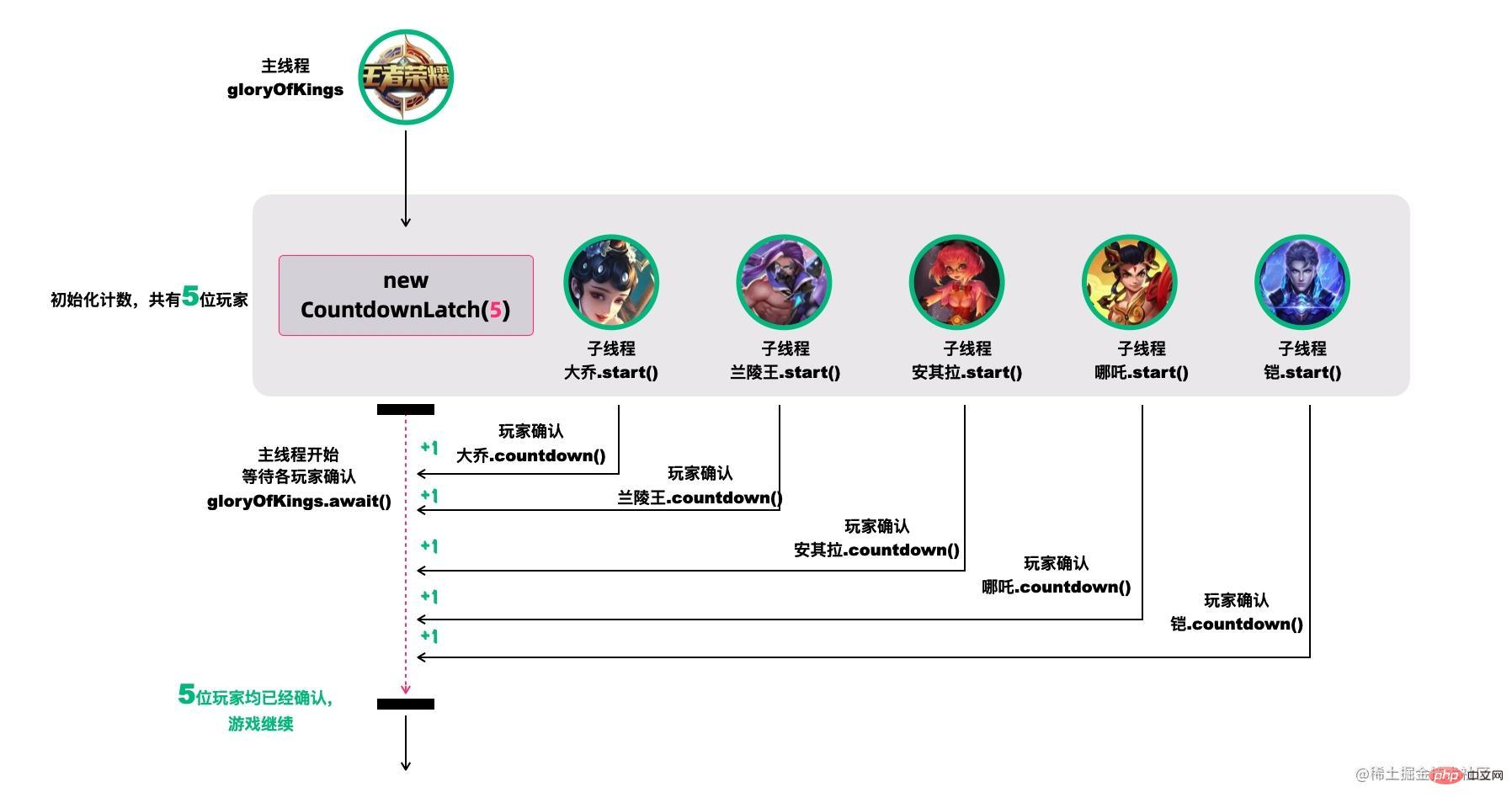
CountDownLatch模仿这个场景(参考[18]):
创建大乔、兰陵王、安其拉、哪吒和铠等五个玩家,主线程必须在他们都完成确认后,才可以继续运行。
在这段代码中,new CountDownLatch(5)用户创建初始的latch数量,各玩家通过countDownLatch.countDown()完成状态确认,主线程通过countDownLatch.await()等待。
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(5);
Thread 大乔 = new Thread(countDownLatch::countDown);
Thread 兰陵王 = new Thread(countDownLatch::countDown);
Thread 安其拉 = new Thread(countDownLatch::countDown);
Thread 哪吒 = new Thread(countDownLatch::countDown);
Thread 铠 = new Thread(() -> {
try {
// 稍等,上个卫生间,马上到...
Thread.sleep(1500);
countDownLatch.countDown();
} catch (InterruptedException ignored) {}
});
大乔.start();
兰陵王.start();
安其拉.start();
哪吒.start();
铠.start();
countDownLatch.await();
System.out.println("所有玩家已经就位!");
}场景2. 协调子线程开始动作:统一各线程动作开始的时机
王者游戏中也有类似的场景,游戏开始时,各玩家的初始状态必须一致。不能有的玩家都出完装了,有的才降生。
所以大家得一块出生,在

在这个场景中,仍然用五个线程代表大乔、兰陵王、安其拉、哪吒和铠等五个玩家。需要注意的是,各玩家虽然都调用了start()线程,但是它们在运行时都在等待countDownLatch的信号,在信号未收到前,它们不会往下执行。
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(1);
Thread 大乔 = new Thread(() -> waitToFight(countDownLatch));
Thread 兰陵王 = new Thread(() -> waitToFight(countDownLatch));
Thread 安其拉 = new Thread(() -> waitToFight(countDownLatch));
Thread 哪吒 = new Thread(() -> waitToFight(countDownLatch));
Thread 铠 = new Thread(() -> waitToFight(countDownLatch));
大乔.start();
兰陵王.start();
安其拉.start();
哪吒.start();
铠.start();
Thread.sleep(1000);
countDownLatch.countDown();
System.out.println("敌方还有5秒达到战场,全军出击!");
}
private static void waitToFight(CountDownLatch countDownLatch) {
try {
countDownLatch.await(); // 在此等待信号再继续
System.out.println("收到,发起进攻!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}CountDownLatch的核心方法也不多:
await():等待latch降为0;boolean await(long timeout, TimeUnit unit):等待latch降为0,但是可以设置超时时间。比如有玩家超时未确认,那就重新匹配,总不能为了某个玩家等到天荒地老。countDown():latch数量减1;getCount():获取当前的latch数量。CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一 组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
它和CountDownLatch类似,都可以协调多线程的结束动作,在它们结束后都可以执行特定动作,但是为什么要有CyclicBarrier,自然是它有和CountDownLatch不同的地方。
不知道你听没听过一个新人UP主小约翰可汗,小约翰生平有两大恨——“歸納整理Java並發知識點”我们来还原一下事情的经过:小约翰在亲政后认识了新垣结衣,于是决定第一次选妃,向结衣表白,等待回应。然而新垣结衣回应嫁给了星野源,小约翰伤心欲绝,发誓生平不娶,突然发现了铃木爱理,于是小约翰决定第二次选妃,求爱理搭理,等待回应。

我们拿代码模拟这一场景,发现CountDownLatch无能为力了,因为CountDownLatch的使用是一次性的,无法重复利用,而这里等待了两次。此时,我们用CyclicBarrier就可以实现,因为它可以重复利用。
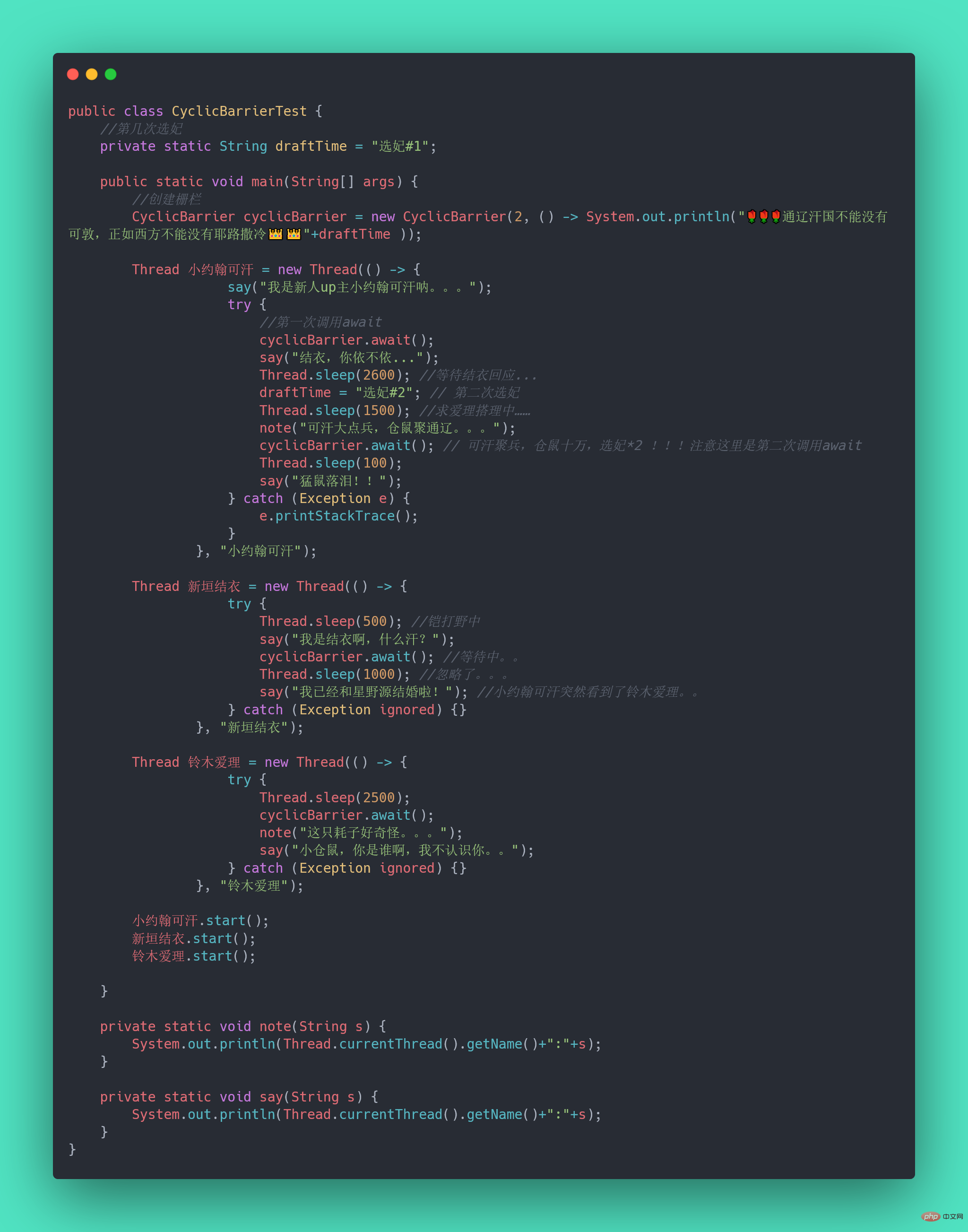
歸納整理Java並發知識點:

CyclicBarrier最最核心的方法,仍然是await():
上面的例子抽象一下,本质上它的流程就是这样就是这样:
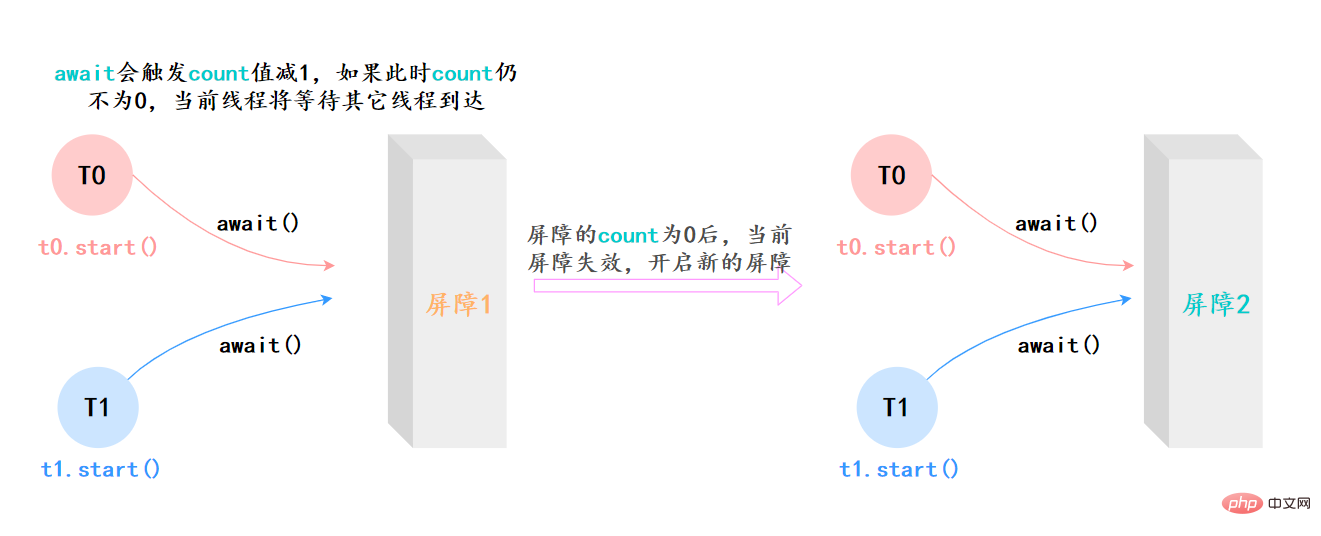
两者最核心的区别[18]:
它們區別用一個表格整理:
| CyclicBarrier | CountDownLatch |
|---|---|
| CyclicBarrier是可重複使用的,其中的執行緒會等待所有的執行緒完成任務。屆時,屏障將被拆除,並可以選擇性地做一些特定的動作。 | CountDownLatch是一次性的,不同的執行緒在同一個計數器上工作,直到計數器為0. |
| CyclicBarrier面向的是執行緒數 | CountDownLatch面向的是任務數 |
| 在使用CyclicBarrier時,你必須在建構中指定參與協作的執行緒數,這些執行緒必須呼叫await()方法 | 使用CountDownLatch時,則必須要指定任務數,至於這些任務由哪些執行緒完成無關緊要 |
| CyclicBarrier可以在所有的執行緒釋放後重新使用 | CountDownLatch在當計數器為0時不能再使用 |
| 在CyclicBarrier中,如果某個執行緒遇到了中斷、逾時等問題時,則處於await的執行緒都會出現問題 | #在CountDownLatch中,如果某個執行緒出現問題,其他執行緒不受影響 |
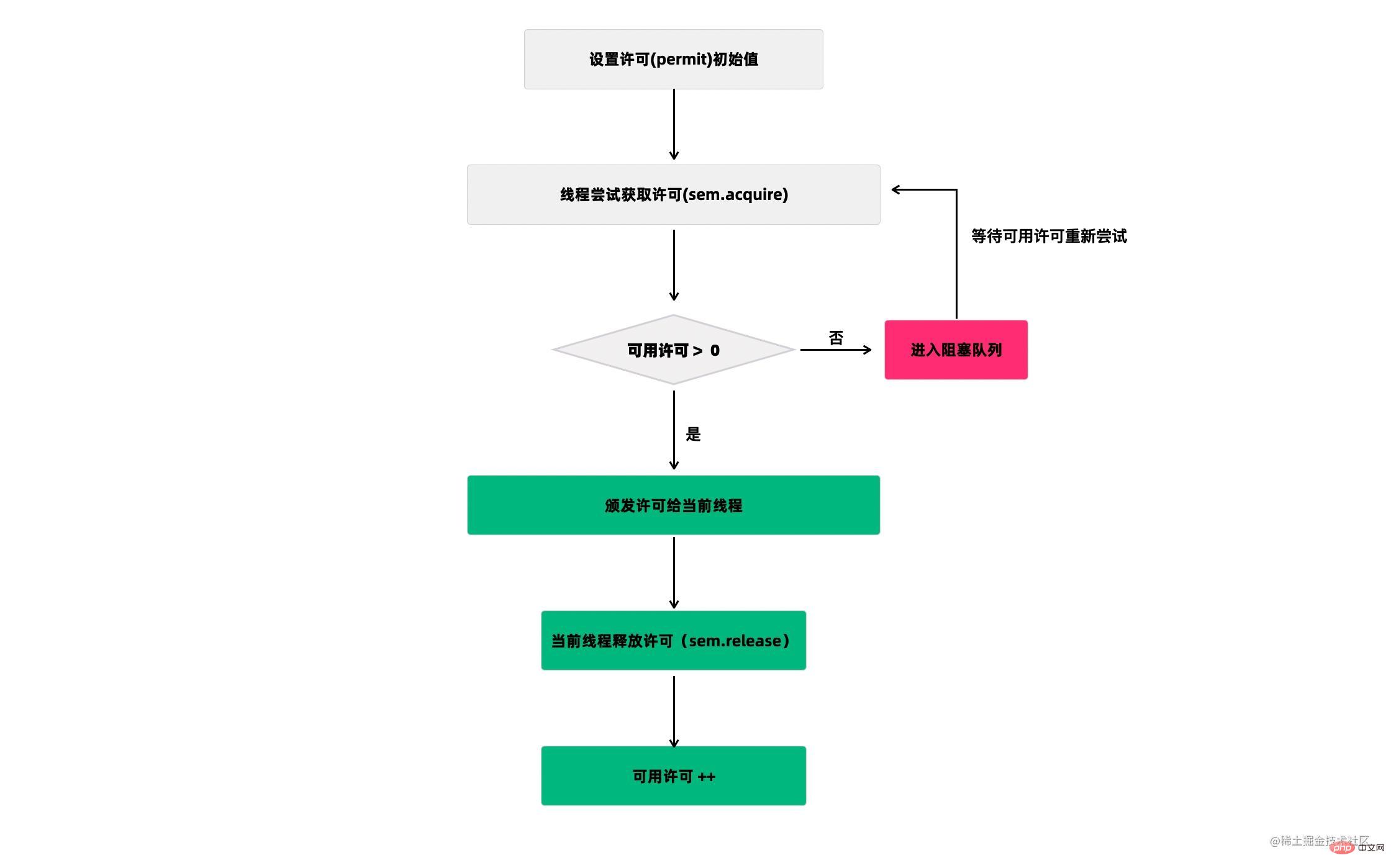
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。
听起来似乎很抽象,现在汽车多了,开车出门在外的一个老大难问题就是停车 。停车场的车位是有限的,只能允许若干车辆停泊,如果停车场还有空位,那么显示牌显示的就是绿灯和剩余的车位,车辆就可以驶入;如果停车场没位了,那么显示牌显示的就是绿灯和数字0,车辆就得等待。如果满了的停车场有车离开,那么显示牌就又变绿,显示空车位数量,等待的车辆就能进停车场。

我们把这个例子类比一下,车辆就是线程,进入停车场就是线程在执行,离开停车场就是线程执行完毕,看见红灯就表示线程被阻塞,不能执行,Semaphore的本质就是协调多个线程对共享资源的获取。
我们再来看一个Semaphore的用途:它可以用于做流量控制,特别是公用资源有限的应用场景,比如数据库连接。
假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发地读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有10个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,就可以使用Semaphore来做流量控制,如下:
public class SemaphoreTest {
private static final int THREAD_COUNT = 30;
private static ExecutorService threadPool = Executors.new歸納整理Java並發知識點(THREAD_COUNT);
private static Semaphore s = new Semaphore(10);
public static void main(String[] args) {
for (int i = 0; i <p>在代码中,虽然有30个线程在执行,但是只允许10个并发执行。Semaphore的构造方法<code>Semaphore(int permits</code>)接受一个整型的数字,表示可用的许可证数量。<code>Semaphore(10)</code>表示允许10个线程获取许可证,也就是最大并发数是10。Semaphore的用法也很简单,首先线程使用 Semaphore的acquire()方法获取一个许可证,使用完之后调用release()方法归还许可证。还可以用tryAcquire()方法尝试获取许可证。</p><h2>43.Exchanger 了解吗?</h2><p>Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/a99f1f171b5f8c414e2981e6a7d5189a-57.png" class="lazy" alt="歸納整理Java並發知識點"></p><p>这两个线程通过 exchange方法交换数据,如果第一个线程先执行exchange()方法,它会一直等待第二个线程也执行exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。</p><p>Exchanger可以用于遗传算法,遗传算法里需要选出两个人作为交配对象,这时候会交换两人的数据,并使用交叉规则得出2个交配结果。Exchanger也可以用于校对工作,比如我们需要将纸制银行流水通过人工的方式录入成电子银行流水,为了避免错误,采用AB岗两人进行录入,录入到Excel之后,系统需要加载这两个Excel,并对两个Excel数据进行校对,看看是否录入一致。</p><pre class="brush:php;toolbar:false">public class ExchangerTest {
private static final Exchanger<string> exgr = new Exchanger<string>();
private static ExecutorService threadPool = Executors.new歸納整理Java並發知識點(2);
public static void main(String[] args) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String A = "银行流水A"; // A录入银行流水数据
exgr.exchange(A);
} catch (InterruptedException e) {
}
}
});
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String B = "银行流水B"; // B录入银行流水数据
String A = exgr.exchange("B");
System.out.println("A和B数据是否一致:" + A.equals(B) + ",A录入的是:"
+ A + ",B录入是:" + B);
} catch (InterruptedException e) {
}
}
});
threadPool.shutdown();
}}</string></string>假如两个线程有一个没有执行exchange()方法,则会一直等待,如果担心有特殊情况发生,避免一直等待,可以使用exchange(V x, long timeOut, TimeUnit unit)设置最大等待时长
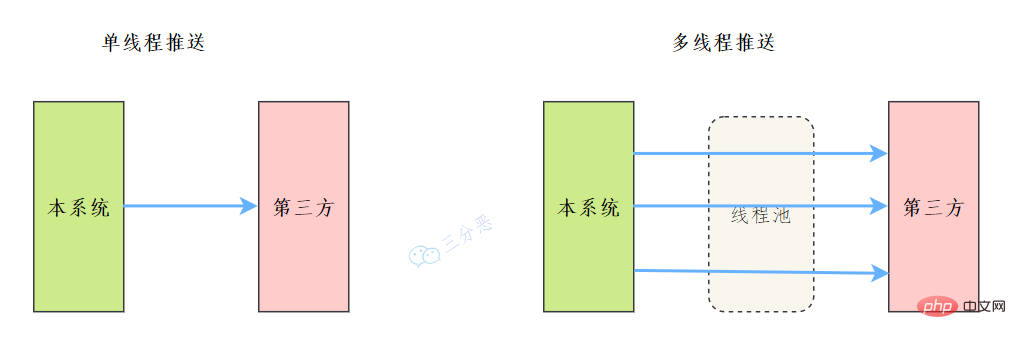
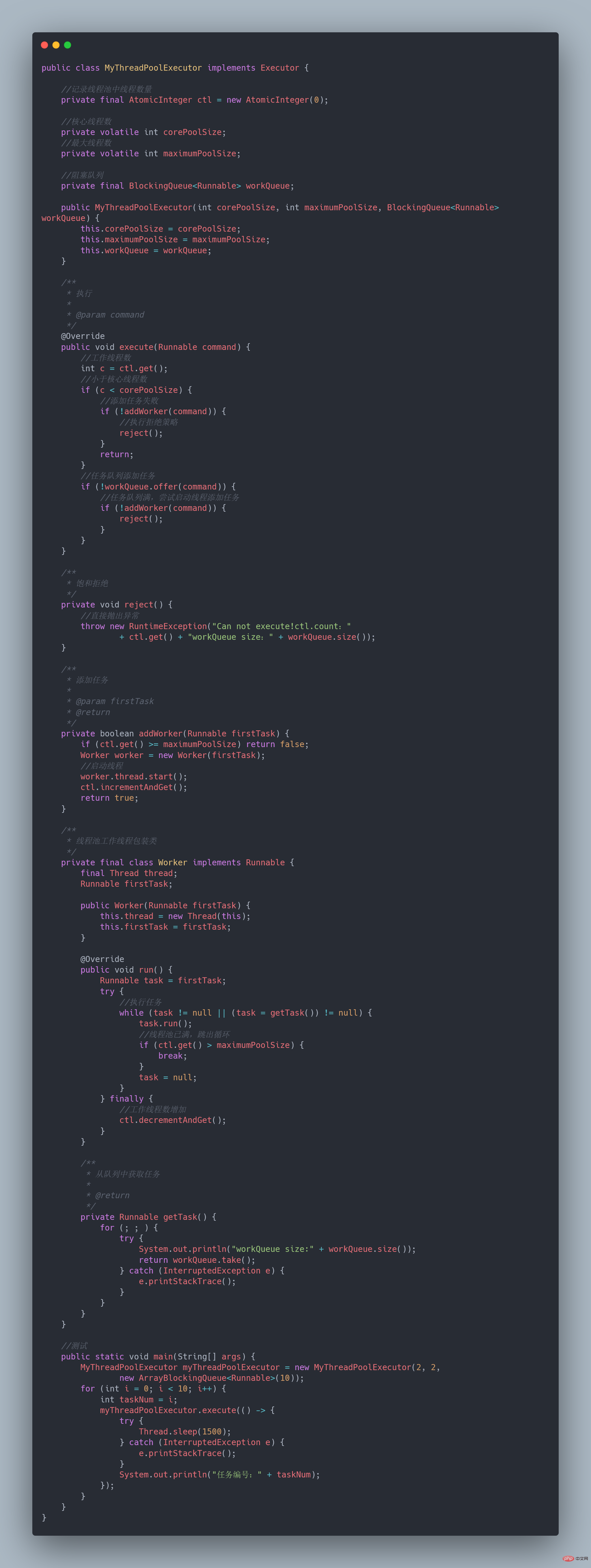
线程池: 简单理解,它就是一个歸納整理Java並發知識點。
之前我们有一个和第三方对接的需求,需要向第三方推送数据,引入了多线程来提升数据推送的效率,其中用到了线程池来管理线程。
歸納整理Java並發知識點如下:
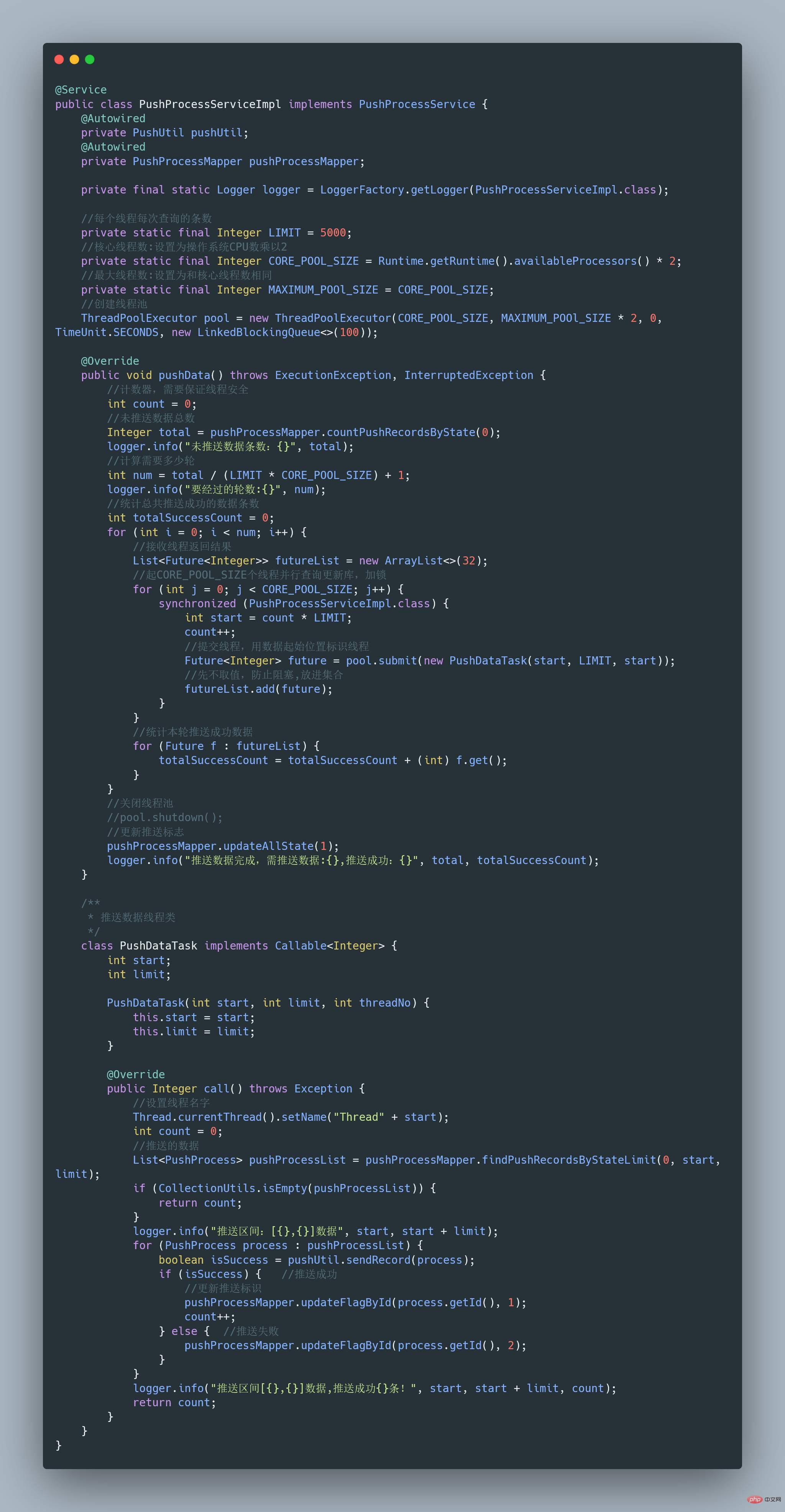
完整可运行代码地址:https://gitee.com/fighter3/thread-demo.git
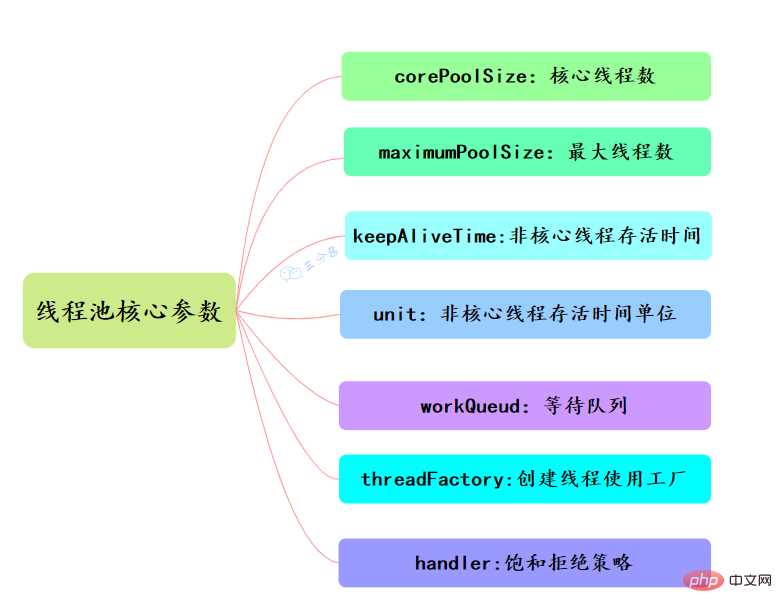
线程池的参数如下:
corePoolSize:线程核心参数选择了CPU数×2
maximumPoolSize:最大线程数选择了和核心线程数相同
keepAliveTime:非核心闲置线程存活时间直接置为0
unit:非核心线程保持存活的时间选择了 TimeUnit.SECONDS 秒
workQueue:线程池等待队列,使用 LinkedBlockingQueue阻塞队列
同时还用了synchronized 来加锁,保证数据不会被重复推送:
synchronized (PushProcessServiceImpl.class) {}ps:这个例子只是简单地进行了数据推送,实际上还可以结合其他的业务,像什么数据清洗啊、数据统计啊,都可以套用。
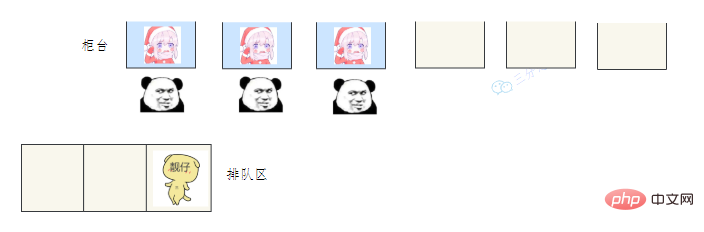
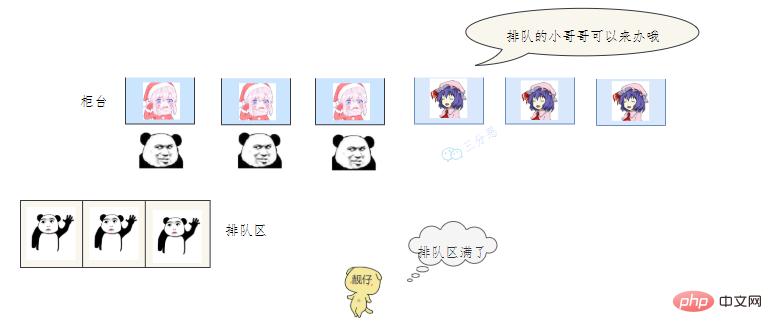
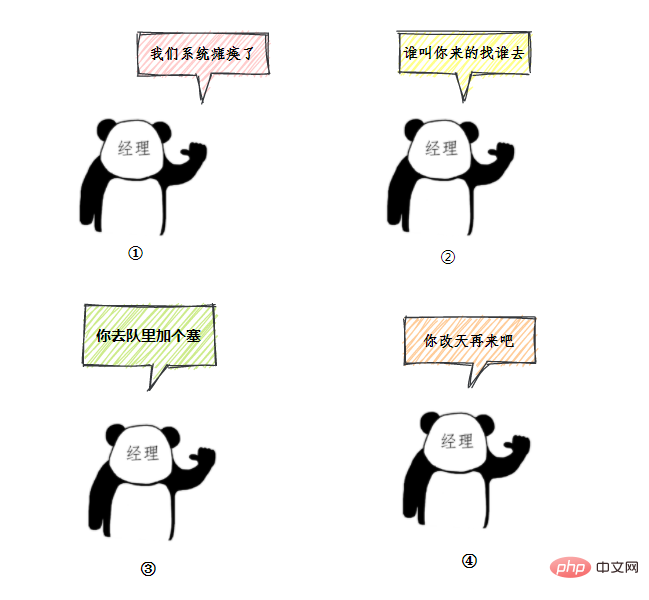
用一个通俗的比喻:
有一个营业厅,总共有六个窗口,现在开放了三个窗口,现在有三个窗口坐着三个营业员小姐姐在营业。
老三去办业务,可能会遇到什么情况呢?

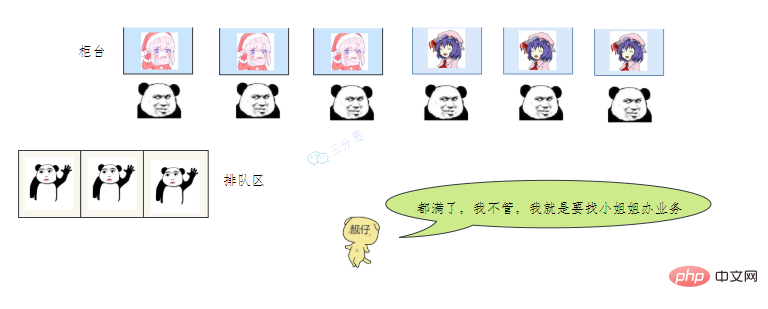
我们银行系统已经瘫痪
谁叫你来办的你找谁去
看你比较急,去队里加个塞
今天没办法,不行你看改一天
上面的这个流程几乎就跟 JDK 线程池的大致流程类似,
- 营业中的 3个窗口对应核心线程池数:corePoolSize
- 总的营业窗口数6对应:maximumPoolSize
- 打开的临时窗口在多少时间内无人办理则关闭对应:unit
- 排队区就是等待队列:workQueue
- 无法办理的时候银行给出的解决方法对应:RejectedExecutionHandler
- threadFactory 该参数在 JDK 中是 线程工厂,用来创建线程对象,一般不会动。
所以我们线程池的工作流程也比较好理解了:
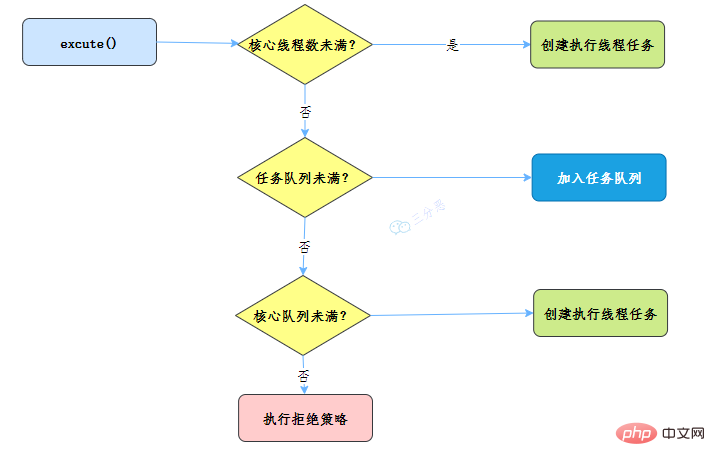
当一个线程完成任务时,它会从队列中取下一个任务来执行。
当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
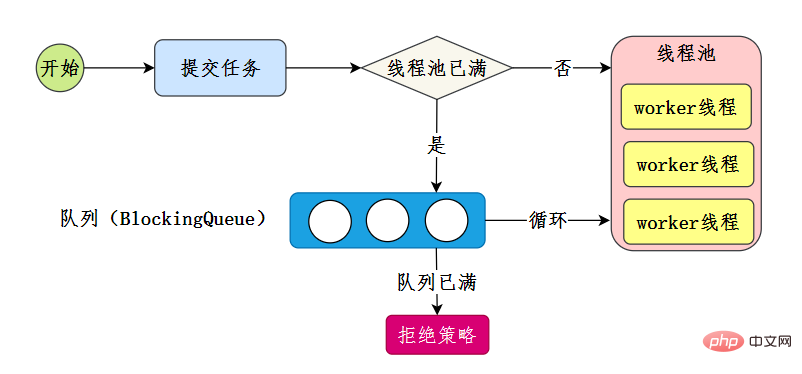
线程池有七大参数,需要重点关注corePoolSize、maximumPoolSize、workQueue、handler这四个。
此值是用来初始化线程池中核心线程数,当线程池中线程池数corePoolSize时,系统默认是添加一个任务才创建一个线程池。当线程数 = corePoolSize时,新任务会追加到workQueue中。
maximumPoolSize表示允许的最大线程数 = (非核心线程数+核心线程数),当BlockingQueue也满了,但线程池中总线程数 maximumPoolSize时候就会再次创建新的线程。
非核心线程 =(maximumPoolSize - corePoolSize ) ,非核心线程闲置下来不干活最多存活时间。
线程池中非核心线程保持存活的时间的单位
线程池等待队列,维护着等待执行的Runnable对象。当运行当线程数= corePoolSize时,新的任务会被添加到workQueue中,如果workQueue也满了则尝试用非核心线程执行任务,等待队列应该尽量用有界的。
创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。
corePoolSize、workQueue、maximumPoolSize都不可用的时候执行的饱和策略。
类比前面的例子,无法办理业务时的处理方式,帮助记忆:
想实现自己的拒绝策略,实现RejectedExecutionHandler接口即可。
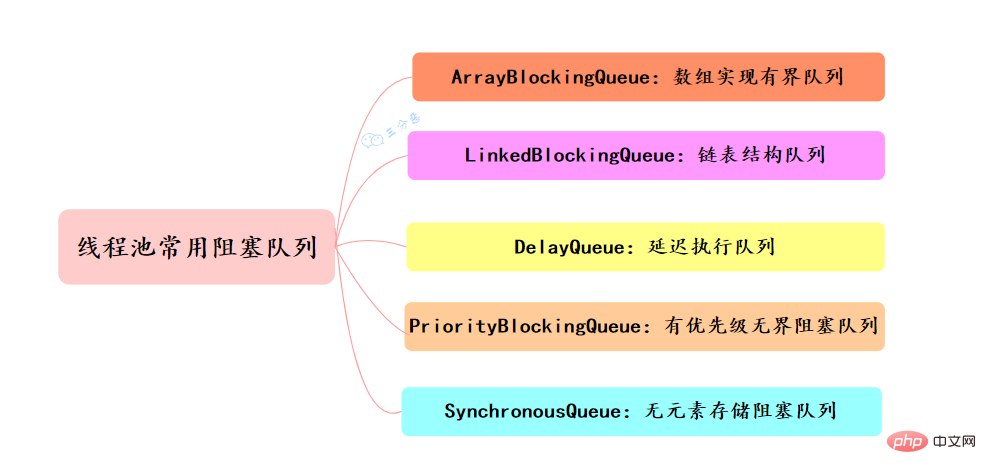
常用的阻塞队列主要有以下几种:
threadsPool.execute(new Runnable() {
@Override public void run() {
// TODO Auto-generated method stub }
});Future<object> future = executor.submit(harReturnValuetask); try { Object s = future.get(); } catch (InterruptedException e) {
// 处理中断异常 } catch (ExecutionException e) {
// 处理无法执行任务异常 } finally {
// 关闭线程池 executor.shutdown();}</object>可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。
shutdown() 将线程池状态置为shutdown,并不会立即停止:
shutdownNow() 将线程池状态置为stop。一般会立即停止,事实上不一定:
shutdown 和shutdownnow简单来说区别如下:
线程在Java中属于稀缺资源,线程池不是越大越好也不是越小越好。任务分为计算密集型、IO密集型、混合型。

一般的经验,不同类型线程池的参数配置:
Runtime.getRuntime().availableProcessors();
当然,实际应用中没有固定的公式,需要结合测试和监控来进行调整。
面试常问,主要有四种,都是通过工具类Excutors创建出来的,需要注意,阿里巴巴《Java开发手册》里禁止使用这种方式来创建线程池。
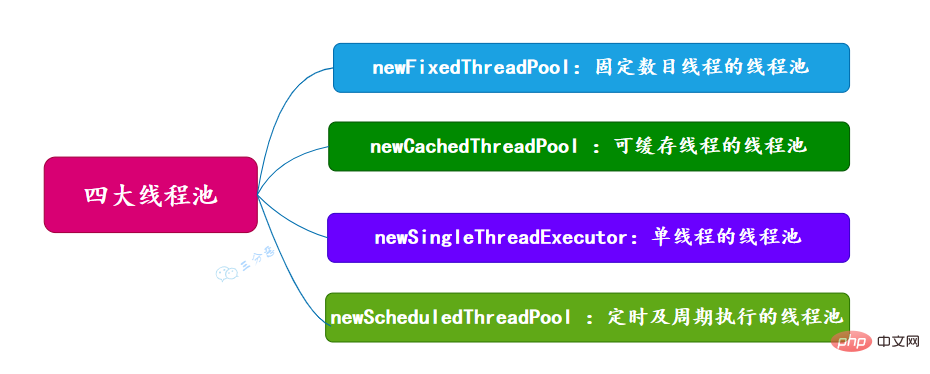
new歸納整理Java並發知識點 (固定数目线程的线程池)
newCachedThreadPool (可缓存线程的线程池)
newSingleThreadExecutor (单线程的线程池)
newScheduledThreadPool (定时及周期执行的线程池)
前三种线程池的构造直接调用ThreadPoolExecutor的构造方法。
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<runnable>(),
threadFactory));
}</runnable>线程池特点
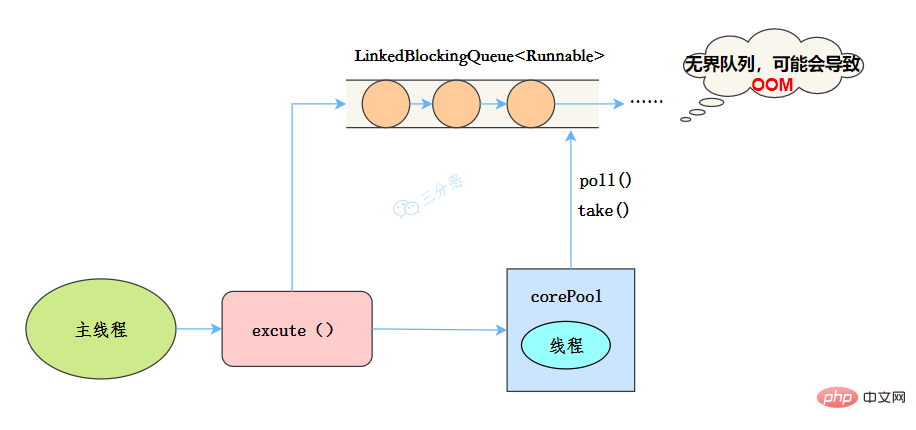
工作流程:
适用场景
适用于串行执行任务的场景,一个任务一个任务地执行。
public static ExecutorService new歸納整理Java並發知識點(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<runnable>(),
threadFactory);
}</runnable>线程池特点:
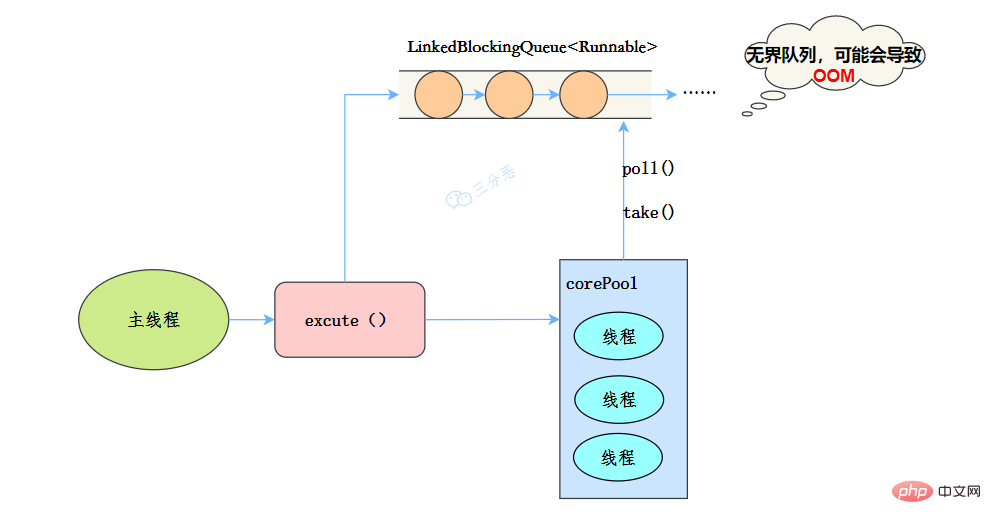
工作流程:
使用场景
歸納整理Java並發知識點 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<runnable>(),
threadFactory);
}</runnable>线程池特点:
当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。
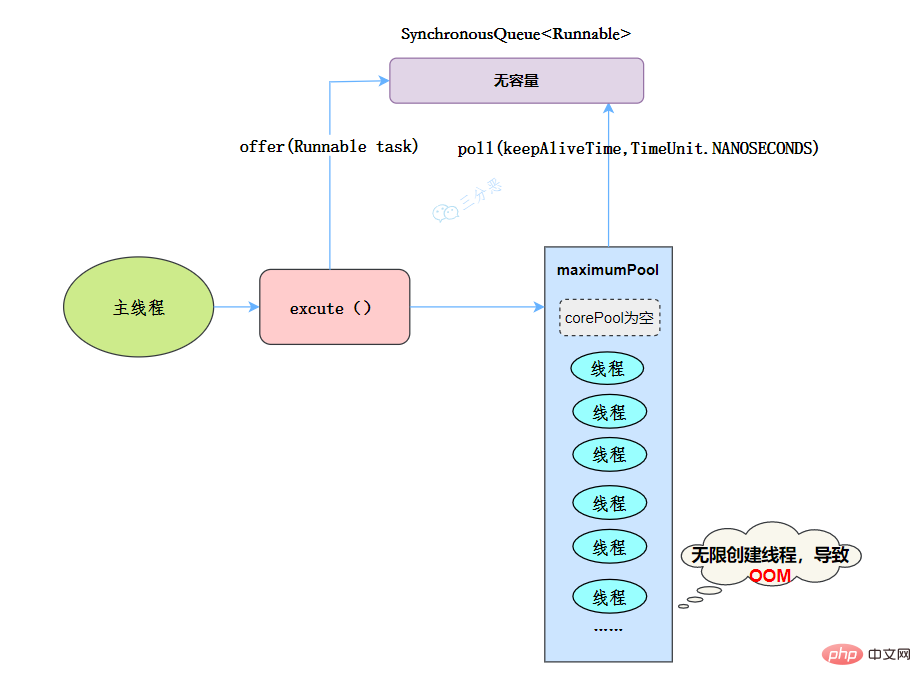
工作流程:
适用场景
用于并发执行大量短期的小任务。
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}线程池特点
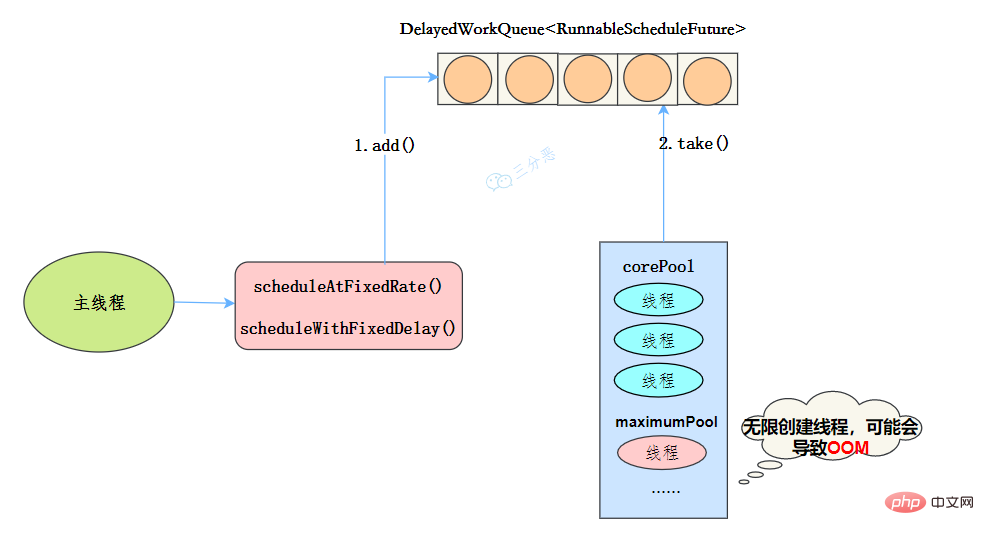
工作机制
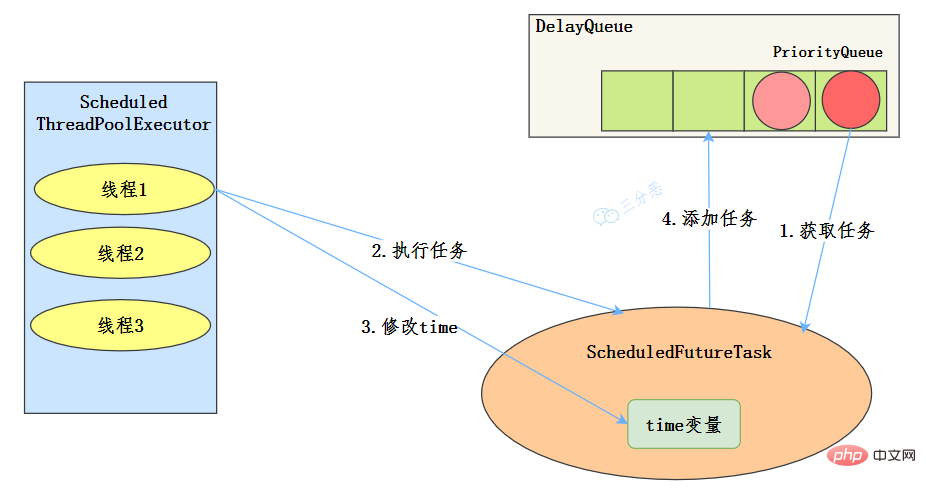
使用场景
周期性执行任务的场景,需要限制线程数量的场景
使用无界队列的线程池会导致什么问题吗?
例如new歸納整理Java並發知識點使用了无界的阻塞队列LinkedBlockingQueue,如果线程获取一个任务后,任务的执行时间比较长,会导致队列的任务越积越多,导致机器内存使用不停飙升,最终导致OOM。
在使用线程池处理任务的时候,任务代码可能抛出RuntimeException,抛出异常后,线程池可能捕获它,也可能创建一个新的线程来代替异常的线程,我们可能无法感知任务出现了异常,因此我们需要考虑线程池异常情况。
常见的异常处理方式:
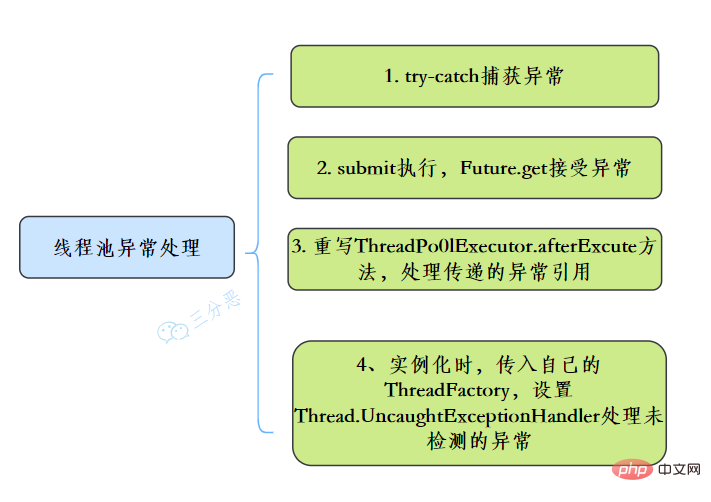
线程池有这几个状态:RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED。
//线程池状态 private static final int RUNNING = -1 <p>线程池各个状态切换图:</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/47690a2c7799a7bd0d10ed5490da3a7b-77.png" class="lazy" alt="歸納整理Java並發知識點"></p><p><strong>RUNNING</strong></p>
SHUTDOWN
STOP
TIDYING
TERMINATED
线程池提供了几个 setter方法来设置线程池的参数。
![JDK 歸納整理Java並發知識點设置接口来源参考[7]](https://img.php.cn/upload/article/000/000/067/6094178ce7a357b1c3eb573fc35e4d09-78.png)
这里主要有两个思路:
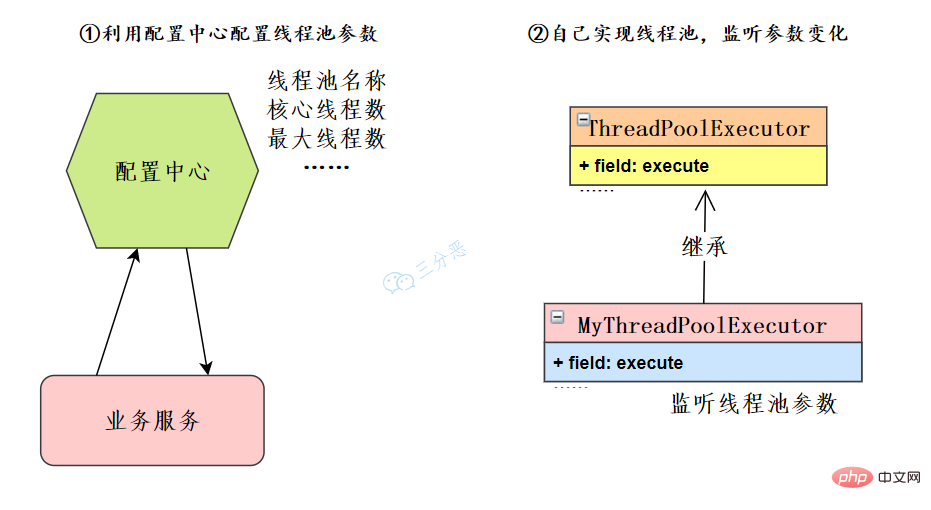
在我們微服務的架構下,可以利用配置中心如Nacos、Apollo等等,也可以自己開發配置中心。業務服務讀取線程池配置,取得對應的線程池實例來修改線程池的參數。
如果限制了配置中心的使用,也可以自己去擴展ThreadPoolExecutor,重寫方法,監聽線程池參數變化,來動態修改線程池參數。
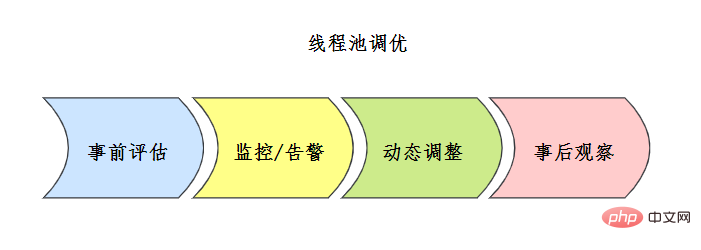
執行緒池配置沒有固定的公式,通常事前會對執行緒池進行一定評估,常見的評估方案如下:
![线程池评估方案 来源参考[7]](https://img.php.cn/upload/article/000/000/067/b8171ba02ccd61fc1cad003f65eae9c1-80.png)
正在處理的已經執行成功的操作。然後重新執行整個阻塞佇列。
CopyOnWriteList和 ConcurrentHashMap這兩種線程安全容器類別的問答。 。
分而治之和工作竊取演算法。
分而治之
Fork/Join框架的定義,其實體現了分治思想:將一個規模為N的問題分解為K個規模較小的子問題,這些子問題相互獨立且與原問題性質相同。求出子問題的解,就可得到原問題的解。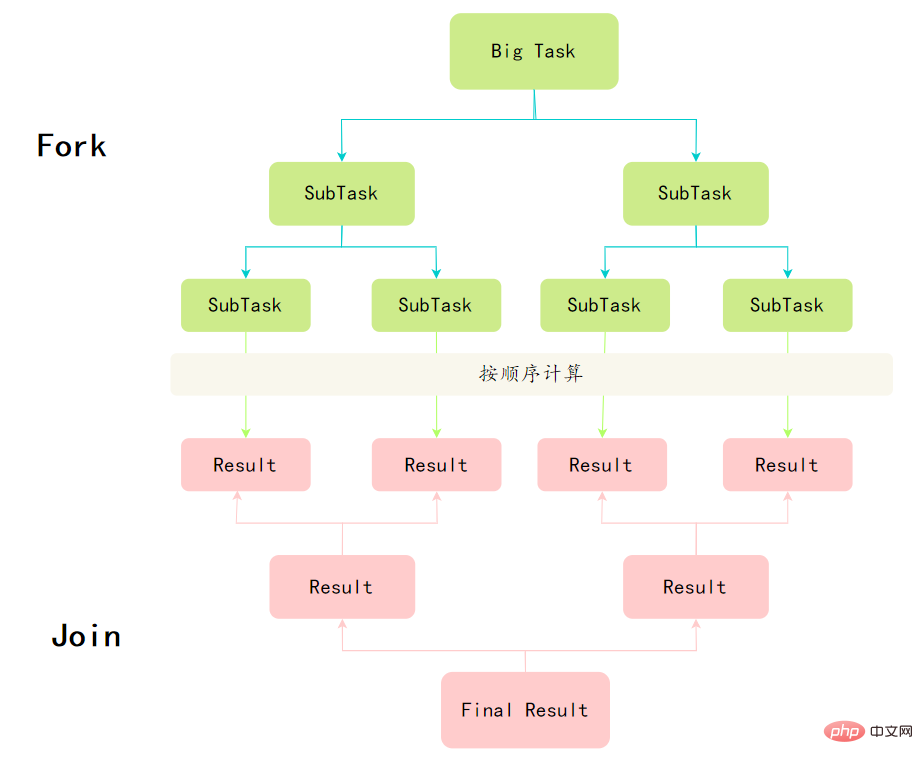
工作竊取演算法
大任務拆成了若干個小任務,把這些小任務放到不同的佇列裡,各自建立單獨執行緒來執行佇列裡的任務。 那麼問題來了,有的線程幹活塊,有的線程幹活慢。幹完活的線程不能讓它空下來,得讓它去幫沒幹完活的線程工作。它去其它線程的佇列裡竊取一個任務來執行,這就是所謂的工作竊取。
工作竊取發生的時候,它們會存取同一個佇列,為了減少竊取任務執行緒和被竊取任務執行緒之間的競爭,通常任務會使用雙端佇列,被竊取任務執行緒永遠從雙端佇列的頭部拿,而竊取任務的執行緒永遠從雙端佇列的尾部拿任務執行。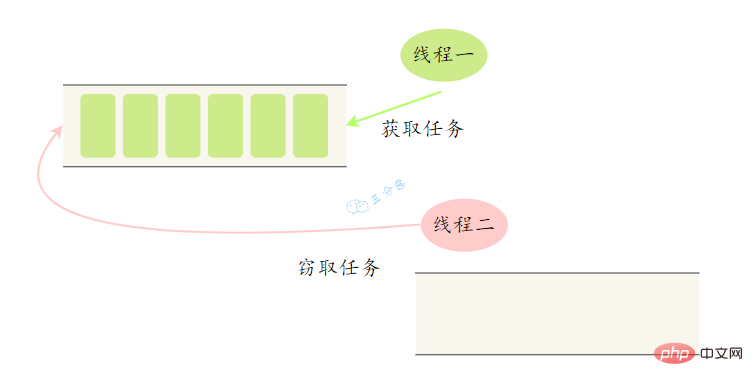
public class CountTask extends RecursiveTask<integer> {
private static final int THRESHOLD = 16; // 阈值
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
// 如果任务足够小就计算任务
boolean canCompute = (end - start) result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
} catch (ExecutionException e) {
}
}
}</integer>ForkJoinTask与一般Task的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果比较大,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进compute方法,看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
推荐学习:《java教程》
以上是歸納整理Java並發知識點的詳細內容。更多資訊請關注PHP中文網其他相關文章!























