
這篇文章為大家帶來了關於Redis的相關知識,其中主要介紹了一致性hash和hash槽的相關問題,如果發生擴容或節點丟失你就會遇到大量的資料遷移問題,一致性hash和hash槽就可以避免這種問題,希望對大家有幫助。

推薦學習:Redis學習教程
假如我們現在有x台快取設備,我們在決定把資料放到哪個快取設備上的時候可以key%x,但是如果發生擴容或節點遺失你就需要key%(x±y)這樣就會遇到大量的資料遷移問題,一致性hash和hash槽就可以避免這種問題。
普通的hash是對伺服器的數量取餘,一致性hash是對特定的數字取餘(2^32)不會因為伺服器的數量變化,首先我們對伺服器的ip或其他唯一識別取餘得到一個值這個值就是伺服器在hash環上的位置,然後對要放入伺服器的物件進行hash得到一個值,在hash換上找對應的伺服器如果值所在的位置沒有伺服器就看下一個位置是否伺服器知道找到可儲存的伺服器。
依照常用的hash演算法將對應的key哈希到一個具有2的32 次方個節點的空間中,即0 ~ (2的32)-1的數位空間中。我們可以把這個東西想像成一個咬住尾巴的,形成了一個閉環。 
#環有了我們現在需要把伺服器放到環上,可以依照伺服器的IP位址取得編號等唯一標識取hash後放到環上。 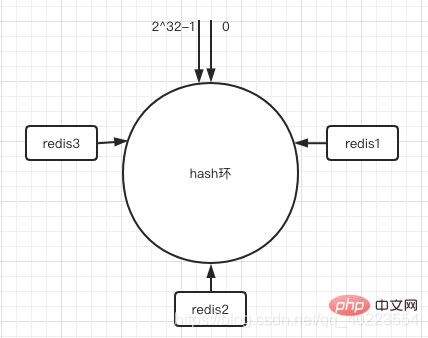
當我們需要把一個資料放到伺服器上的時候我們首先需要計算資料的hash值然後取餘,如果取餘後的值在環上有對應的伺服器那直接放進去如果沒有則向後查找。 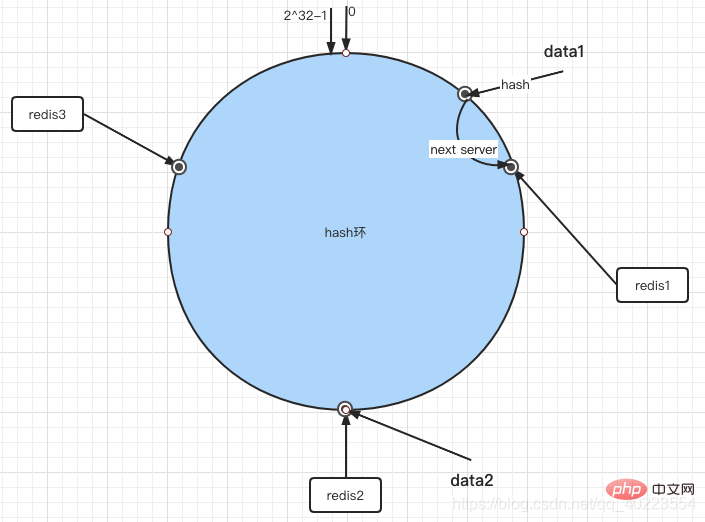
所以最後data1在redis1裡面,data2在redis2裡面。當我們取得資料的時候也是執行相同的過程,計算key的hash值,然後根據相同的規則取得儲存的伺服器。
如果現在某個redis節點掛掉了,那麼其他節點裡面的資料是還在的,原來節點裡面的資料會被重新分配到下一個節點裡面。
如果在環境中新增一台伺服器RedisNeo,透過hash演算法將RedisNeo映射到環中,透過以順時針遷移的規則,那麼以前hash值在Redis2和RedisNeo之間的資料遷移到RedisNeo裡面(下圖中RedisNeo挨著Redis2),其它物件仍保持這原有的儲存位置。透過對節點的添加和刪除的分析,一致性哈希演算法在保持了單調性的同時,還是資料的遷移達到了最小,這樣的演算法對分散式叢集來說是非常合適的,避免了大量資料遷移,減小了伺服器的的壓力。 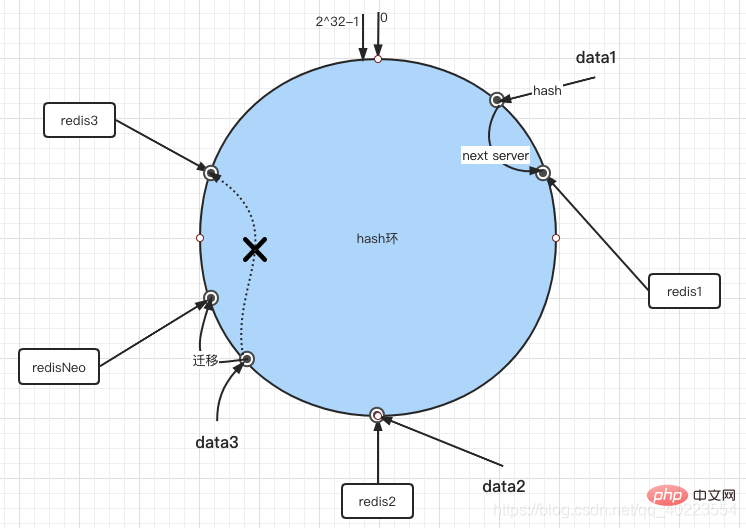
所以redisNeo加入後data3就到redisNeo裡面去了。
到目前為止一致性hash也可以算做完成了,但是有一個問題還需要解決,那就是平衡性。從下圖我們可以看出,當伺服器節點比較少的時候,會出現一個問題,就是此時必然造成大量資料集中到一個節點上面,例如你只有兩個節點一個在1另一個在10,那麼顯然1節點的壓力是無限大的,因為只有hash值在[2,10]之間的才會到10節點,其他的全到1節點上去了,為了解決這個資料傾斜問題,一致性哈希演算法引入了虛擬節點機制,即對每一個服務節點計算多個哈希,每個計算結果位置都放置一個此服務節點,稱為虛擬節點。具體做法可以先確定每個實體節點關聯的虛擬節點數量,然後在ip或主機名稱後面增加編號,同時資料定位演算法不變,只是多了一步虛擬節點到實際節點的對應。
哈希槽是在redis cluster集群方案中採用的,redis cluster集群並沒有採用一致性哈希方案,而是採用資料分片中的哈希槽來進行資料儲存與讀取的。 redis cluster採用資料分片的雜湊槽來進行資料儲存和資料的讀取。 redis cluster一共有2^14(16384)個槽,所有的master節點都會有一個槽區例如0~1000,槽數是可以遷移的。 master節點的slave節點不分配槽,只擁有讀取權限。但注意在程式碼中redis cluster執行讀寫操作的都是master節點,並不是你想 的讀是從節點,寫是主節點。第一次新建redis cluster時,16384個插槽是被master節點均勻分佈的。 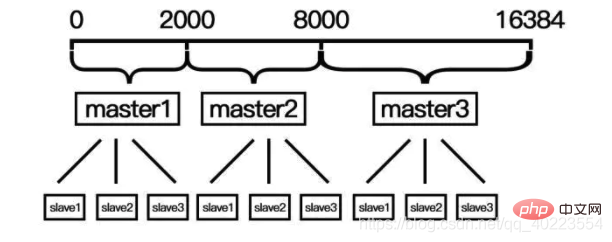
和一致性雜湊相比在擴容和縮容的時候需要手動手動分配hash槽,並且在刪除master節點的時候要把他的從節點和hash槽交給其他master節點;hash槽的是根據CRC-16(key) 384的值來判斷屬於哪個槽區。
推薦學習:Redis教學
以上是redis快取學習之一致性hash和hash槽的詳細內容。更多資訊請關注PHP中文網其他相關文章!
























