

Python詳細解析之多執行緒爬蟲與常見搜尋演算法

這篇文章為大家帶來了關於python的相關知識,其中主要介紹了關於多線程爬蟲開發以及常見搜尋演算法的相關問題,下面一起來看一下,希望對大家有幫助。

推薦學習:python影片教學
#多執行緒爬蟲
多執行緒的優點
在掌握了requests與正規表示式以後,就可以開始實戰爬取一些簡單的網址了。
但是,此時的爬蟲只有一個行程、一個線程,因此稱為單線程爬蟲。單線程爬蟲每次只訪問一個頁面,不能充分利用電腦的網路頻寬。一個頁面最多也就幾百KB,所以爬蟲在爬取一個頁面的時候,多出來的網速和從發起請求到得到原始碼中間的時間都被浪費了。 如果可以讓爬蟲同時造訪10個頁面,就等於爬取速度提高了10倍。為了達到這個目的,就需要使用多執行緒技術了。
Python這門語言,有一個全域解釋器鎖定(Global Interpreter Lock, GIL)。這導致Python的多線程都是偽多線程,即本質上還是一個線程,但是這個線程每個事情只做幾毫秒,幾毫秒以後就保存現場,換做其他事情,幾毫秒後再做其他事情,一輪之後回到第一件事上,恢復現場再做幾毫秒,繼續換……微觀上的單線程,在宏觀上就像同時在做幾件事。這種機制在I/O(Input/Output,輸入/輸出)密集型的操作上影響不大,但是在CPU計算密集型的操作上面,由於只能使用CPU的一個核,就會對性能產生非常大的影響。所以涉及計算密集型的程序,就需要使用多進程,Python的多進程不受GIL的影響。爬蟲屬於I/O密集型的程序,所以使用多執行緒可以大幅提高爬取效率。
多重進程庫:multiprocessing
multiprocessing本身就是Python的多進程庫,用來處理與多進程相關的操作。但是由於進程與進程之間不能直接共享記憶體和堆疊資源,而且啟動新的進程開銷也比線程大得多,因此使用多執行緒來爬取比使用多進程有更多的優勢。
multiprocessing下面有一個dummy模組,它可以讓Python的執行緒使用multiprocessing的各種方法。
dummy下面有一個Pool類,它用來實作執行緒池。
這個執行緒池有一個map()方法,可以讓執行緒池裡面的所有執行緒都「同時」執行一個函數。
例如:
在學習了for迴圈後
for i in range(10): print(i*i)
這種寫法當然可以得到結果,但是程式碼是一個數一個數地計算,效率並不高。而如果使用多執行緒的技術,讓程式碼同時計算很多數的平方,就需要使用multiprocessing.dummy來實作:
多執行緒的使用範例:
from multiprocessing.dummy import Pooldef cal_pow(num):
return num*num
pool=Pool(3)num=[x for x in range(10)]result=pool.map(cal_pow,num)print('{}'.format(result))在上面的程式碼中,先定義了一個函數用來計算平方,然後初始化了一個有3個執行緒的執行緒池。這3個執行緒負責計算10個數字的平方,誰先計算完手上的這個數,誰就先取下一個數繼續計算,直到把所有的數字都計算完成為止。
在這個範例中,執行緒池的map()方法接收兩個參數,第1個參數是函數名,第2個參數是一個列表。注意:第1個參數只是函數的名字,是不能帶括號的。第2個參數是一個可迭代的對象,這個可迭代對象裡面的每一個元素都會被函數clac_power2()接收作為參數。除了列表以外,元組、集合或字典都可以作為map()的第2個參數。
多執行緒爬蟲開發
由於爬蟲是I/O密集型的操作,特別是在請求網頁原始碼的時候,如果使用單執行緒來開發,會浪費大量的時間來等待網頁返回,所以把多執行緒技術應用到爬蟲中,可以大幅提升爬蟲的運作效率。舉一個例子。洗衣機洗完衣服要50min,水壺燒水要15min,背單字要1h。如果先等洗衣機洗衣服,衣服洗完了再燒水,水燒開了再背單詞,總共需要125min。
但是如果換一種方式,從整體上看,3件事情是可以同時運行的,假設你突然分身出另外兩個人,其中一個人負責把衣服放進洗衣機並等待洗衣機洗完,另一個人負責燒水並等待水燒開,而你自己只需要背單字就可以了。等到水燒開,負責燒水的分身先消失。等到洗衣機洗完衣服,負責洗衣服的分身再消失。最後你自己本體背完單字。只需要60min就可以同時完成3件事。
當然,大家一定會發現上面的例子並不是生活中的實際情況。現實中沒有人會分身。真實生活中的情況是,人背單字的時候就專心背單字;水燒開後,水壺會發出響聲提醒;衣服洗完了,洗衣機會發出「滴滴」的聲音。所以到提醒的時候再去做相應的動作就好,沒有必要每分鐘都去檢查。上面的兩種差異,其實就是多執行緒和事件驅動的非同步模型的差異。本小節講到的是多執行緒操作,後面會講到使用非同步操作的爬蟲框架。現在只需要記住,在需要操作的動作數量不大的時候,這兩種方式的性能沒有什麼區別,但是一旦動作的數量大量增長,多線程的效率提升就會下降,甚至比單線程還差。而到那個時候,只有非同步操作才是解決問題的方法。
下面透過兩段程式碼來比較單執行緒爬蟲和多執行緒爬蟲爬取bd首頁的效能差異: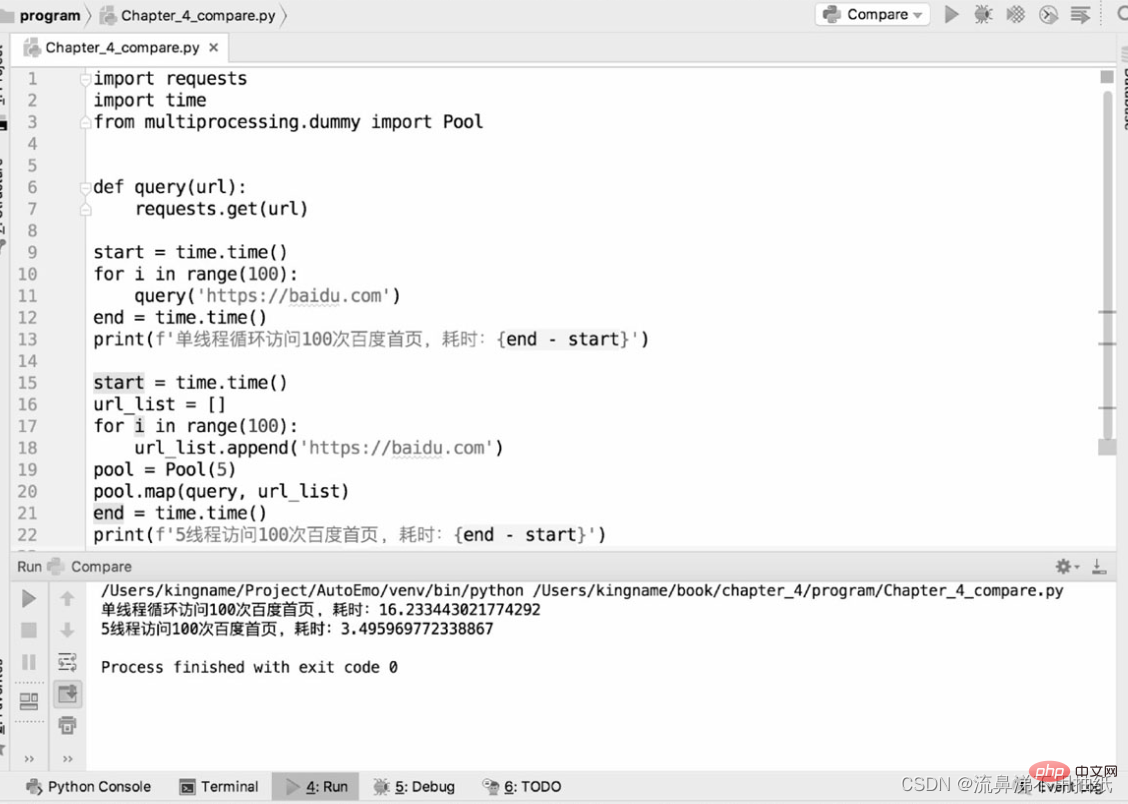
從運行結果可以看到,一個執行緒用時約16.2s,5個線程用時約3.5s,時間是單線程的五分之一左右。從時間上也可以看到5個執行緒「同時運行」的效果。但並不是說線程池設定得越大越好。從上面的結果也可以看到,5個執行緒運行的時間其實比一個執行緒運行時間的五分之一多一點。這多出來的一點其實就是線程切換的時間。這也從側面反映了Python的多線程在微觀上還是串行的。因此,如果執行緒池設定得過大,執行緒切換導致的開銷可能會抵消多執行緒帶來的效能提升。線程池的大小需要根據實際情況來確定,並沒有確切的資料。讀者可以在具體的應用場景下設定不同的大小進行測試對比,找到一個最合適的數據。
爬蟲的常見搜尋演算法
深度優先搜尋
某線上教育網站的課程分類,需要爬取上面的課程資訊。從首頁開始,課程有幾個大的分類,例如根據語言分為Python、Node.js和Golang。每個大分類下面又有很多的課程,像是Python下面有爬蟲、Django和機器學習。每個課程又分為很多的課程。
在深度優先搜尋的情況下,爬取路線如圖所示(序號從小到大)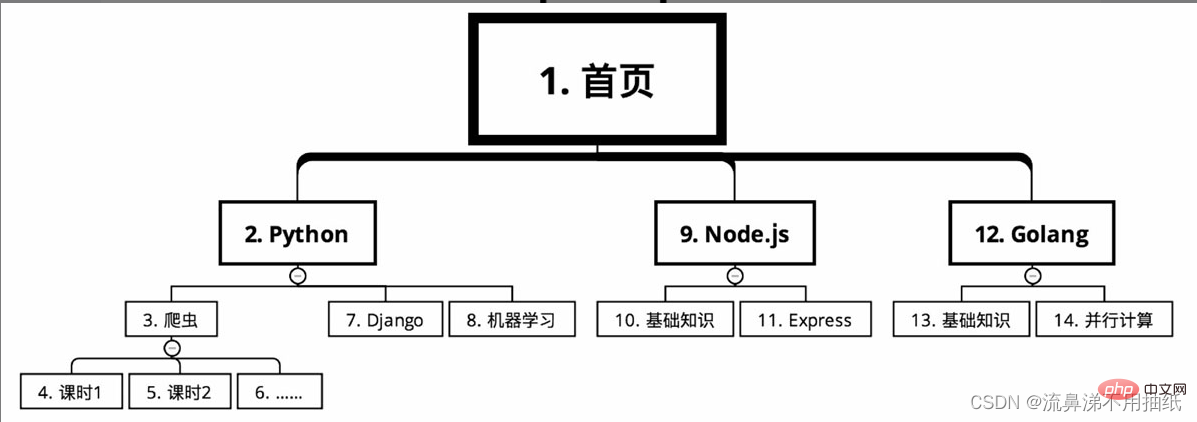
廣度優先搜尋
#先後順序如下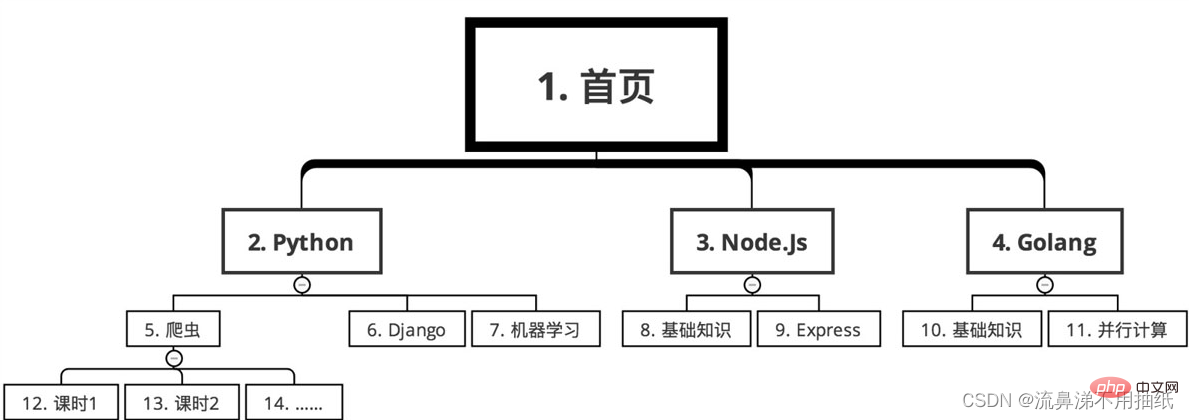
演算法選擇
例如要爬取某網站全國所有的餐廳資訊和每個餐廳的訂單資訊。假設使用深度優先演算法,那麼先從某個連結爬到了餐廳A,再立刻去爬餐廳A的訂單資訊。由於全國有十幾萬家餐館,全部爬完可能需要12小時。這樣導致的問題就是,餐廳A的訂單量可能是早上8點爬到的,而餐廳B是晚上8點爬到的。它們的訂單量差了12小時。而對於熱門餐廳來說,12小時就有可能帶來數百萬的收入差距。這樣在做數據分析時,12小時的時間差就會導致難以比較A和B兩家餐廳的銷售表現。相對於訂單量來說,餐廳的數量變化要小得多。所以如果採用廣度優先搜索,先在半夜0點到第二天中午12點把所有的餐館都爬取一遍,第二天下午14點到20點再集中爬取每個餐館的訂單量。這樣做,只花了6個小時就完成了訂單爬取任務,縮小了由時間差異致的訂單量差異。同時由於店家隔幾天抓一次影響也不大,所以請求量也減少了,讓爬蟲更難被網站發現。
又例如,要分析即時輿情,需要爬百度貼。一個熱門的貼吧可能有幾萬頁的帖子,假設最早的帖子可追溯到2010年。如果採用廣度優先搜索,則先把這個貼吧所有帖子的標題和網址都獲取下來,然後根據這些網址進入每個帖子裡面以獲取每一層樓的信息。可是,既然是即時輿情,那麼7年前的貼文對現在的分析意義不大,更重要的應該是新的貼文才對,所以應該優先抓取新的內容。相對於過往的內容,即時的內容才最為重要。因此,對於貼吧內容的爬取,應該採用深度優先搜尋。看到一個帖子就趕緊進去,爬取它的每個樓層信息,一個帖子爬完了再爬下一個帖子。當然,這兩種搜尋演算法並非非此即彼,需要根據實際情況靈活選擇,很多時候也能夠同時使用。
推薦學習:python影片教學
#以上是Python詳細解析之多執行緒爬蟲與常見搜尋演算法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
