本篇文章為大家帶來了關於mysql的相關知識,其中主要介紹了mysql高級篇的一些問題,包括了索引是什麼、索引底層實現等等問題,下面一起來看一下,希望對大家有幫助。

推薦學習:mysql影片教學
#MySQL,熟悉又陌生的名詞,早在學習Javaweb的時候,我們就用到了MySQL資料庫,在那個階段,MySQL對我們來說似乎只是一個儲存資料的好東西,儲存時一股腦往裡邊塞,查詢時也是盲目的全表查詢(不帶一點點最佳化).
我們總是自欺欺人的覺得,我們透過其他方面來優化就好了阿,遲遲不願面對MySQL高級,轉而學習一些看似更為"高級"的東西,學Redis,來分擔MySQL的壓力,學MyCat等中間件,實現主從複製,讀寫分離,分庫分錶等等。 (說的就是melo沒錯了)
到了準備面試的時候,發現面試題裡邊的MySQL一問三不知~
而自己學到的前沿中間件,問得幾乎很少! !自己也只是會用,寫履歷時只能弱寫上"了解"xxx中間件…
#當然了,學習MySQL高級篇,不單單只是為了面試,實際的專案中,這一塊的優化是十分重要的,體驗過伺服器宕機後,只能默默........
從現在開始吧,此時上岸還來得及! ! !趁著金三銀四,補充補充MySQL高級篇的知識點,從下幾方面開啟MySQL高級篇之旅
建議透過側邊欄目錄檢索對您有幫助的部分,其中有emoji表情前綴屬於重點部分,覺得對您有幫助的話,小編還會持續更進完善本篇文章和MySQL專欄。
索引定義
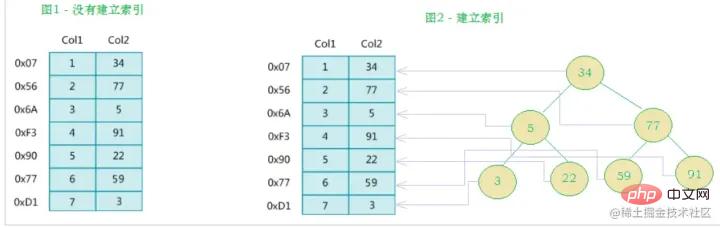
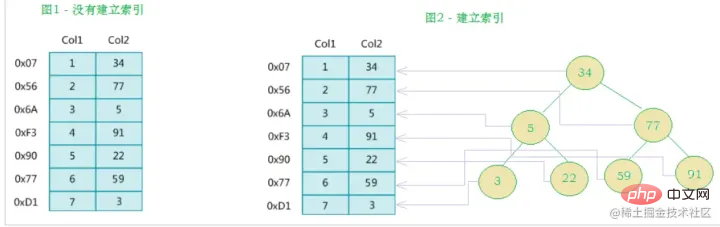
MySQL官方對索引的定義為:索引(index)是幫助MySQL有效率地取得資料的資料結構(有序)。索引是在資料庫表的欄位上新增的,是為了提高查詢效率存在的一種機制。除了數據之外,資料庫系統還維護著滿足特定查找演算法的數據結構,這些數據結構以某種方式引用(指向)數據, 這樣就可以在這些數據結構上實現高級查找演算法,這種數據結構就是索引。如下面的示意圖所示:
其實簡單來說,索引就是一個排好序的資料結構
#左邊是資料表,一共有兩列七筆記錄,最左邊的是資料記錄的實體位址(注意邏輯上相鄰的記錄在磁碟上也並不是一定物理相鄰的)。為了加快Col2的查找,可以維護一個右邊所示的二元查找樹,每個節點分別包含
索引鍵值和一個指向對應資料記錄物理位址的指標,這樣就可以運用二元查找快速取得到對應資料。
索引優勢
加快- 找出和排序的速率,降低資料庫的IO成本以及CPU的消耗
透過建立唯一性索引,可以保證資料庫表中每一行資料的唯一性。 -
索引劣勢
索引實際上也是- 一張表,保存了主鍵和索引字段,並指向實體類別的記錄,本身需要佔用空間
雖然增加了查詢效率,但對於增刪改,每次改動表,還需要更新索引新增:自然需要在索引樹中新增節點刪除:索引樹中指向的記錄可能會失效,意味著這棵索引樹很多節點,都是失效的改動:索引樹中節點的- 指向可能需要改變
但實際上呢,我們MySQL中並不是用二元找樹來存儲,為何呢?
要知道,二元查找樹,這裡一個節點只能儲存一條數據,而一個節點呢,在MySQL裡邊又對應一個磁碟區塊,這樣我們每次讀取一個磁碟區塊,只能取得一條數據,效率特別的低,所以我們會想到採用
B樹這種結構來儲存。
索引結構
索引是在MySQL的儲存引擎層中實現的,而不是在伺服器層實現的。所以每種儲存引擎的索引不一定完全相同,而且也不是所有的引擎都支援所有的索引類型。
-
BTREE 索引 : 最常見的索引類型,大部分索引都支援 B 樹索引。
-
HASH 索引:只有Memory引擎支援 , 使用場景簡單 。
-
R-tree 索引(空間索引):空間索引是MyISAM引擎的一個特殊索引類型,主要用於地理空間資料類型,通常使用較少,不做特別介紹。
-
Full-text (全文索引) :全文索引也是MyISAM的一個特殊索引類型,主要用於全文索引,InnoDB從Mysql5.6版本開始支援全文索引。
MyISAM、InnoDB、Memory三種儲存引擎對各種索引類型的支援
| ##索引
|
INNODB引擎
|
MYISAM引擎
|
MEMORY引擎
|
| BTREE索引
|
#支持
|
支持
|
支援
|
| HASH 索引
|
#不支援
|
不支援
|
支援
|
| R-tree 索引
|
不支援
|
支援
|
不支援
|
| Full-text
|
5.6版本之後支援
|
支援
|
不支援
|
########################## ####
我們平常所說的索引,如果沒有特別指明,都是指B 樹(多路搜尋樹,不一定是二元的)結構組織的索引。其中聚集索引、複合索引、前綴索引、唯一索引預設都是使用 B tree 索引,統稱為 索引。
BTREE
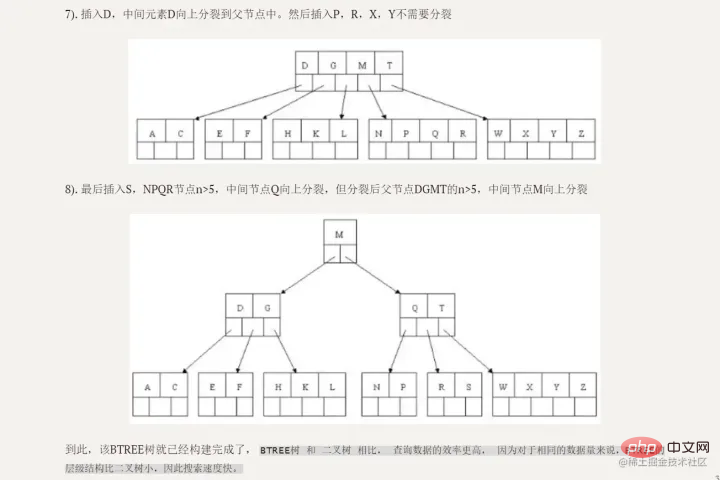
多路平衡搜尋樹,一棵m階(m叉)BTREE滿足:
- 每個節點最多m個孩子孩子數: ceil(m/2) 到m 關鍵字個數:ceil(m/2)-1 到m-1
ceil表示向上取整,ceil(2.3)=3
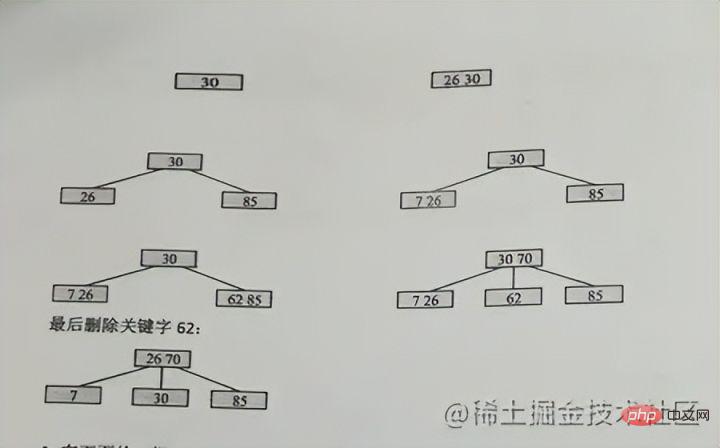
插入關鍵字案例
保證不破壞m階B樹的性質
#由於3階,最多只能2個節點,所以一開始26和30在一起,之後再來個85就要開始分裂了,30作為中間上位,26保持,85去到右邊
即:中間位置上位,然後左邊留在舊節點,右邊去到新結點
如圖中的70再插入的時候,70剛好是中間位置上位,然後62保持,85又去分一個新節點出來
上位後又需要分裂
#繼續往上分裂即可,同理的
比較優勢
比起二元搜尋樹,高度/深度更低,自然查詢效率更高。
B TREE
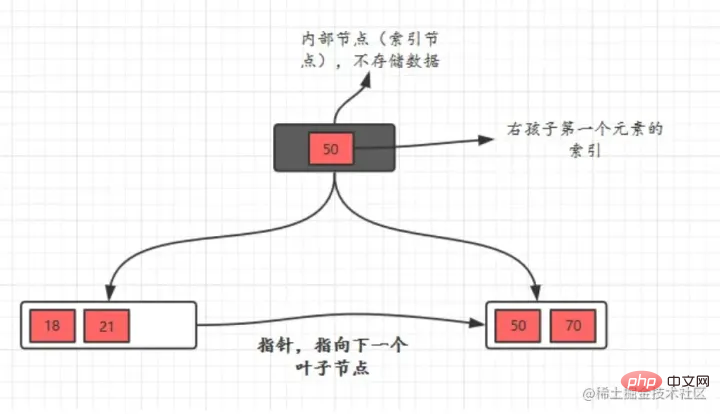
- B 樹有兩種類型的節點:內部結點(也稱為索引結點)和葉子結點。內部節點就是非葉節點,內部節點不儲存數據,只儲存索引,資料都儲存在葉子節點。
- 內部結點中的key都按照從小到大的順序排列,對於內部結點中的一個key,左樹中的所有key都小於它,右子樹中的key都大於等於它。葉子結點中的記錄也依照key的大小排列。
- 每個葉子結點都存有相鄰葉子結點的指針,葉子結點本身依關鍵字的大小自小而大順序連接。
- 父節點存有右孩子的第一個元素的索引。
比起優勢
- B Tree的查詢效率更穩定。由於B Tree只有葉子節點保存key訊息,查詢任何key都要從root走到葉子,所以更穩定。
- 只要遍歷葉子節點,就可以實現整棵樹的遍歷。
MySQL中的B Tree
MySql索引資料結構對經典的B Tree進行了最佳化。在原B Tree的基礎上,增加一個指向相鄰葉子節點的鍊錶指標(整體類似一個雙向鍊錶的結構),就形成了帶有順序指標的B Tree,提高區間存取的效能。
細心的同學可以看出,這張圖跟我們的二元查找樹簡圖的一個最大差別是什麼?
- 從二元查找樹過渡到B樹,有一個顯著的變化就是,一個節點可以儲存多個資料了,相當於一個磁碟區塊裡邊可以儲存多筆數據,大大減少了我們的IO次數! !
MySQL中的B Tree 索引結構示意圖:
二元尋找樹簡圖:
索引原理
BTree索引:
初始化介紹
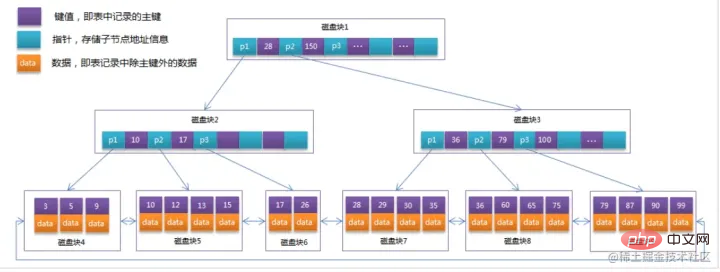
淺藍色的稱為一個磁碟區塊,可以看到每個磁碟區塊包含幾個資料項(深藍色所示)和指標(黃色所示)
如磁碟區塊1包含資料項17和35,包含指標P1、P2、P3,
P1表示小於17的磁碟區塊,P2表示在17和35之間的磁碟區塊,P3表示大於35的磁碟區塊。
-
真實的資料存在於葉子節點即3、5、9、10、13、15、28、29、36、60、75、79、90、99。 `
- 非葉子節點不儲存真實的數據,只儲存指引搜尋方向的數據項,如17、35並不真實存在於數據表中。 `
查找過程
如果要查找資料項29,那麼首先會把磁碟區塊1由磁碟載入到內存,此時發生一次IO。在記憶體中用二分查找確定29在17和35之間,鎖定磁碟區塊1的P2指針,記憶體時間因為非常短(相比磁碟的IO)可以忽略不計,透過磁碟區塊1的P2指針的磁碟位址把磁碟區塊3由磁碟載入到內存,發生第二次IO,29在26和30之間,鎖定磁碟區塊3的P2指針,透過指標載入磁碟區塊8到內存,發生第三次IO,同時記憶體中通過二分查找搜尋到29,結束查詢,總計三次IO。
真實的情況是,3層的B 樹可以表示上百萬的數據,如果上百萬的數據查找只需要三次IO,性能提高將是巨大的,如果沒有索引,每個數據項都要發生一次IO,那麼總共需要百萬次的IO,顯然成本非常非常高。
索引分類
在InnoDB中,表都是根據主鍵順序以索引的形式存放的,這種儲存方式的表稱為索引組織表。又因為前面我們提到的,InnoDB使用了B 樹索引模型,所以資料都是儲存在B 樹中的。
每一個索引在InnoDB裡面對應一棵B 樹。
假設,我們有一個主鍵列為ID的表,表中有欄位k,並且在k上有索引。
這個表格的建表語句是:
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
复制代码
登入後複製
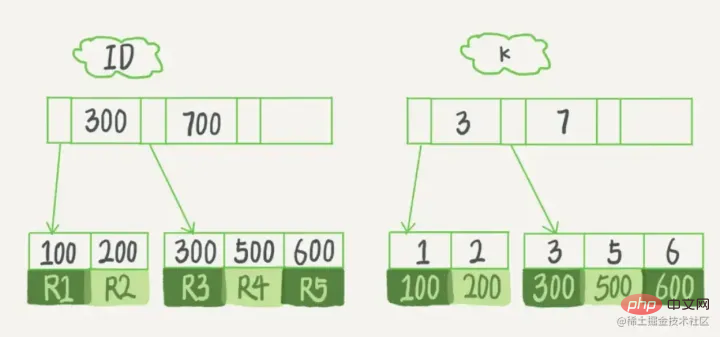
表中R1~R5的(ID,k)值分別為(100,1)、(200,2)、(300,3)、 (500,5)和(600,6),兩棵樹的範例示意圖如下:
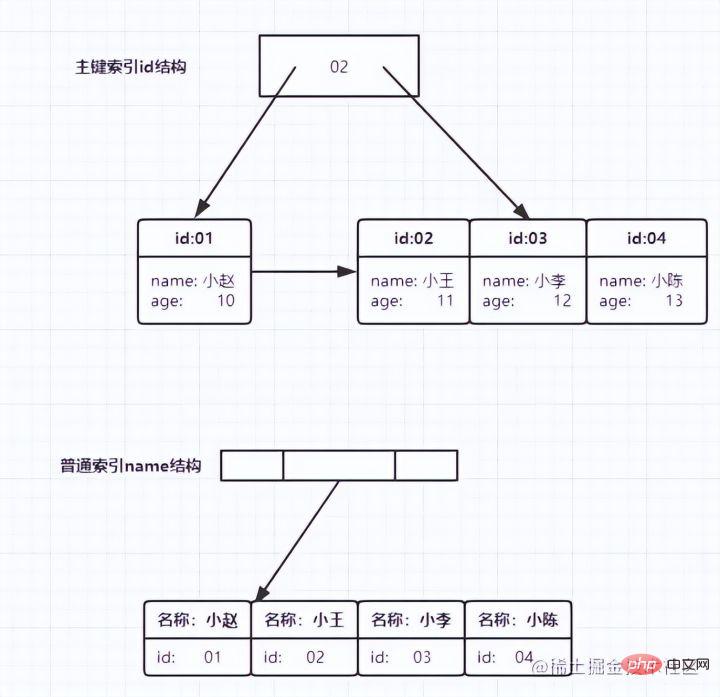
# 從圖中不難看出,根據葉子節點的內容,索引類型分為主鍵索引和非主鍵索引。
主鍵索引
資料表的主鍵列使用的就是主鍵索引,且會預設創建,這也是為什麼,我們還沒學索引的時候,老師常跟我們說根據主鍵查會快一點,原來主鍵本身就建好了索引。
主鍵索引的葉子節點存的是整行資料。在InnoDB裡,主鍵索引也被稱為叢集索引(clustered index)。
輔助索引
輔助索引的葉子節點內容是主鍵的值。在InnoDB裡,輔助索引也被稱為二級索引(secondary index)。
如下圖:
- 主鍵索引存放了整行資料
- 輔助索引只存放了自己本身,以及id主鍵用於回表查詢
根據上面的索引結構,我們來討論一個問題:基於主鍵索引和輔助索引的查詢有什麼區別?
- 如果語句是select * from T where ID=500,即主鍵查詢方式,則只需要搜尋ID這棵B 樹;
- 如果語句是select * from T where k=5,即普通索引查詢方式,則需要先搜尋k索引樹,得到ID的值為500,再到ID索引樹搜尋一次。這個過程稱為回表。
也就是說,基於輔助索引的查詢需要多掃描一棵索引樹。因此,我們在應用程式上應盡量使用主鍵查詢。
除非說,我們所要查詢的數據,剛好就是我們索引樹上存在的,此時我們稱之為覆蓋索引--即索引列中包含了我們要查詢的所有資料。
同時,二級索引又分為如下幾種(先簡單略過即可,後續我們再慢慢了解):
-
唯一索引(Unique Key) :唯一索引也是一種限制。 唯一索引的屬性列不能出現重複的數據,但是允許資料為 NULL,一張表允許建立多個唯一索引。 建立唯一索引的目的大部分時候都是為了該屬性列的資料的唯一性,而不是為了查詢效率。
-
普通索引(Index) :普通索引的唯一作用就是為了快速查詢數據,一張表允許創建多個普通索引,並允許資料重複和 NULL。
-
前綴索引(Prefix) :前綴索引只適用於字串類型的資料。前綴索引是對文字的前幾個字元建立索引,相比普通索引建立的資料更小, 因為只取前幾個字元。
-
全文索引(Full Text) :全文索引主要是為了檢索大文本資料中的關鍵字的信息,是目前搜尋引擎資料庫使用的一種技術。 Mysql5.6 之前只有MYISAM 引擎支援全文索引,5.6 之後InnoDB 也支援了全文索引
擴充--索引下推
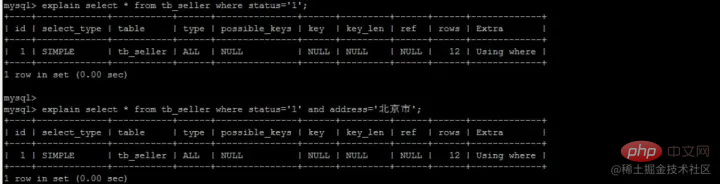
所謂下推,顧名思義,其實是延後我們的回表操作,MySQL不會輕易讓我們去回表,因為很浪費。什麼意思呢?來看下邊這個例子。
我們建立了一個複合索引(name,status,address),索引中也是按這個欄位來儲存的,類似圖中這樣:
複合索引樹(只儲存索引列和主鍵用於回表)
name |
#status |
address |
id(主鍵) |
#小米1 |
##0
|
1
|
1
|
| 小米2
|
1
|
1
|
#2
|
我们执行这样一条语句:
SELECT name FROM tb_seller WHERE name like '小米%' and status ='1' ;
复制代码
登入後複製
- 首先我们在复合索引树上,找到了第一个以小米开头的name -- 小米1
- 此时我们不着急回表(回到主键索引树搜索的过程,我们称为回表),而是先在复合索引树判断status是否=1,此时status=0,我们直接就不回表了,直接继续找下一个以小米开头的name
- 找到第二个-- 小米2,判断status=1,则根据id=2去主键索引树上找,得到所有的数据
这种先在自身索引树上判断是否满足其他的where条件,不满足则直接pass掉,不进行回表的操作,就叫做索引下推。
最左前缀原则
所谓最左前缀,可以想象成一个爬楼梯的过程,假设我们有一个复合索引:name,status,address,那这个楼梯由低到高依次顺序是:name,status,address,最左前缀,要求我们不能出现跳跃楼梯的情况,否则会导致我们的索引失效:
- 按楼梯从低到高,无出现跳跃的情况--此时符合最左前缀原则,索引不会失效
- 出现跳跃的情况
- 直接第一层name都不走,当然都失效
- 走了第一层,但是后续直接第三层,只有出现跳跃情况前的不会失效(此处就只有name成功)
- 同时,这个顺序并不是由我们where中的排列顺序决定,比如: where name='小米科技' and status='1' and address='北京市' where status='1' and name='小米科技' and address='北京市'
这两个尽管where中字段的顺序不一样,第二个看起来越级了,但实际上效果是一样的
其实是因为我们MySQL有一个Optimizer(查询优化器),查询优化器会将SQL进行优化,选择最优的查询计划来执行。
- 关于这个查询优化器,后续文章我们也会谈谈MySQL的逻辑架构与存储引擎
索引设计原则
针对表
- 查询频次高,且数据量多的表
针对字段
- 最好从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合。
其他原则
- 最好用唯一索引,区分度越高,使用索引的效率越高
- 不是越多越好,维护也需要时间和空间代价,建议单张表索引不超过 5 个
因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
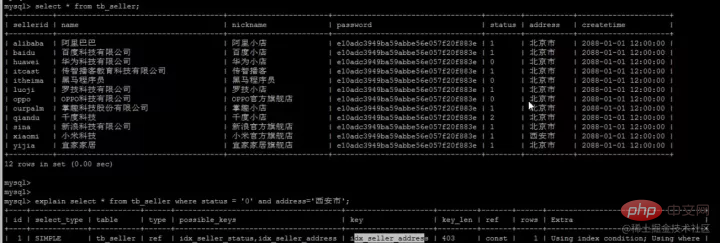
比如:
我们创建了三个单列索引,name,status,address
当我们where中根据status和address两个字段来查询时,数据库只会选择最优的一个索引,不会所有单列索引都使用。
最优的索引:具体是指所查询表中,辨识度最高(所占比例最少)的索引列,比如此处address中有一个辨识度很高的 '西安市'数据;
- 使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升MySQL访问索引的I/O效率。
- 利用最左前缀,比如有N个字段,我们不一定需要创建N个索引,可以用复合索引
也就是说,我们尽量创建复合索引,而不是单列索引
创建复合索引:
CREATE INDEX idx_name_email_status ON tb_seller(name,email,status);
就相当于
对name 创建索引 ;
对name , email 创建了索引 ;
对name , email, status 创建了索引 ;
复制代码
登入後複製
举个栗子
假设我们有这么一个表,id为主键,没有创建索引:
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
) ENGINE=InnoDB
复制代码
登入後複製
如果要在此处建立复合索引,我们要遵循什么原则呢?
通过调整顺序,可以少维护一个索引
- 比如我们的业务需求里边,有如下两种查询方式: 根据name查询 根据name和age查询
如果我们建立索引(age,name),由于最左前缀原则,我们这个索引能实现的是根据age,根据age和name查询,并不能单纯根据name查询(因为跳跃了),为了实现我们的需求,我们还得再建立一个name索引;
而如果我们通过调整顺序,改成(name,age),就能实现我们的需求了,无需再维护一个name索引,这就是通过调整顺序,可以少维护一个索引。
考虑空间->短索引
- 比如我们的业务需求里边,有以下两种查询方式: 根据name查询 根据age查询 根据name和age查询
我们有两种方案:
- 建立联合索引(name,age),建立单列索引:age索引。
- 建立联合索引(age,name),建立单列索引:name索引。
这两种方案都能实现我们的需求,这个时候我们就要考虑空间了,name字段是比age字段大的,显然方案1所耗费的空间是更小的,所以我们更倾向于方案1。
何时建立索引
- where中的查询字段
- 查询中与其他表关联的字段,比如外键
- 排序的字段
- 统计或分组的字段
何时达咩索引
- 表中数据量很少
- 经常改动的表
- 频繁更新的字段
-
数据重复且分布均匀的表字段(比如包含了很多重复数据,那此时多叉树的二分查找,其实用处不大,可以理解为O(logn)退化了)
索引相关语法
创建索引
默认会为主键创建索引--primary
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
复制代码
登入後複製
查找索引
结尾加上\G,可以变成竖屏显示
select index from tbl_name\G;
复制代码
登入後複製
删除索引
drop INDEX index_name on tbl_name ;
复制代码
登入後複製
变更索引
1). alter table tb_name add primary key(column_list);
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
2). alter table tb_name add unique index_name(column_list);
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
3). alter table tb_name add index index_name(column_list);
添加普通索引, 索引值可以出现多次。
4). alter table tb_name add fulltext index_name(column_list);
该语句指定了索引为FULLTEXT, 用于全文索引
复制代码
登入後複製
查看索引使用情况
show status like 'Handler_read%'; -- 查看当前会话索引使用情况
show global status like 'Handler_read%'; -- 查看全局索引使用情况
复制代码
登入後複製
Handler_read_first:索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(这个值越低越好)。
Handler_read_key:如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的性能改善不高,因为索引不经常使用(这个值越高越好)。
Handler_read_next :按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。
Handler_read_prev:按照键顺序读前一行的请求数。该读方法主要用于优化ORDER BY ... DESC。
Handler_read_rnd :根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。你可能使用了大量需要MySQL扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应该建立索引来补救。
Handler_read_rnd_next:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。
总结
- 索引简单来说就是一个排好序的数据结构,可以方便我们检索数据,而不需要盲目的进行全表扫描。
- 索引底层有很多种实现结构,这篇主要只是讲解了BTREE索引,如果对树这一数据结构还不太熟悉的小伙伴,可以关注我后续数据结构专栏,会整理关于普通树,二叉树,二叉排序树的文章。
- 索引分类:
- 主键索引
- 辅助索引
这里我们还扩展了索引下推,是一个十分重要的知识点,需要仔细回味。
- 索引的相关设计原则,索引虽好,但也不可贪杯,不能为了用索引而建索引。
- 索引的相关语法,很容易上手的。
- 查看索引的使用情况。
推荐学习:mysql视频教程
以上是帶你把MySQL索引吃透了的詳細內容。更多資訊請關注PHP中文網其他相關文章!