
這篇文章為大家帶來了關於mysql的相關知識,其中主要介紹了關於架構原理的相關內容,MySQL Server架構自頂向下大致可以分網絡連接層、服務層、儲存引擎層和系統檔案層,下面一起來看一下,希望對大家有幫助。

推薦學習:mysql影片教學
MySQL Server架構自頂向下大致可以分割網路連接層、服務層、儲存引擎層和系統檔案層。
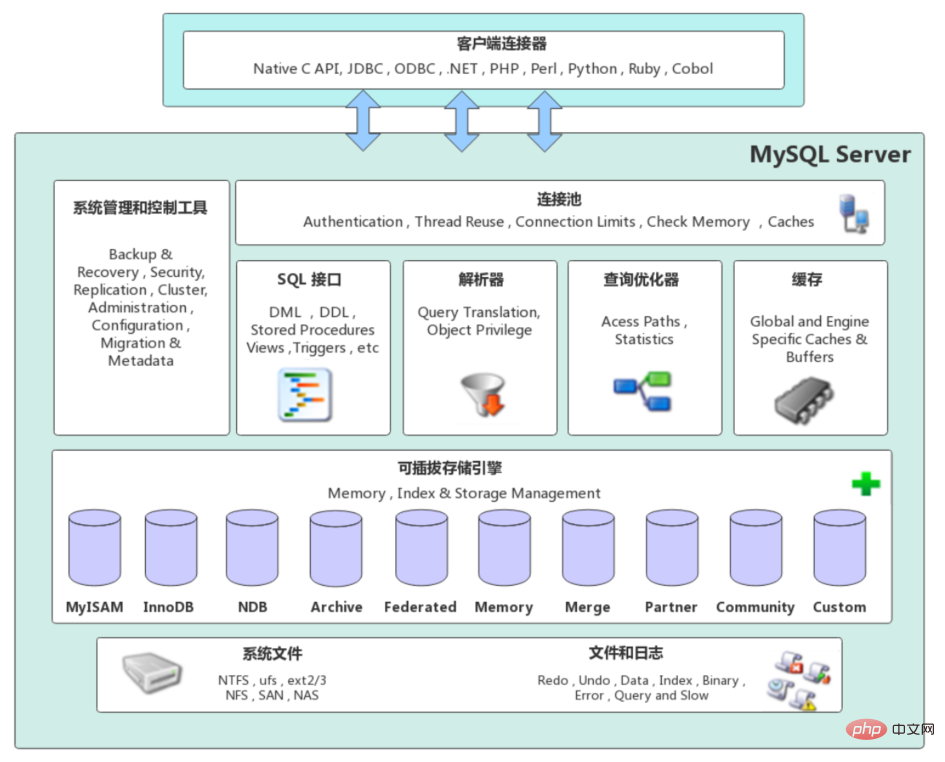
服務層是MySQL Server的核心,主要包含系統管理與控制工具、連線池、SQL介面、解析器、查詢最佳化器和快取六個部分。
連接池(Connection Pool):負責儲存和管理客戶端與資料庫的連接,一個執行緒負責管理一個連接。
系統管理與控制工具(Management Services & Utilities):例如備份還原、安全管理、叢集管理等
SQL介面(SQL Interface):用於接受客戶端發送的各種SQL命令,並且傳回使用者需要查詢的結果。例如DML、DDL、預存程序、視圖、觸發器等。
解析器(Parser):負責將請求的SQL解析產生一個"解析樹"。然後根據一些MySQL規則進一步檢查解析樹是否合法。
查詢優化器(Optimizer):當"解析樹"通過解析器語法檢查後,將交由優化器將其轉換成執行計劃,然後與儲存引擎互動。
select uid, name from user where gender = 1;
選取--》投影--》聯接策略
- select先根據where語句進行選取,並不是查詢出全部資料再過濾;
- select查詢根據uid和name進行屬性投影,並不是取出所有欄位;
- 將前面選取和投影聯接起來最終產生查詢結果;
快取(Cache&Buffer): 快取機制是由一系列小型快取組成的。例如表格緩存,記錄緩存,權限緩存,引擎緩存等。如果查詢快取有命中的查詢結果,查詢語句就可以直接去查詢快取中取資料。
該層負責將資料庫的資料和日誌儲存在檔案系統之上,並完成與儲存引擎的交互,是檔案的物理儲存層。主要包含日誌文件,數據文件,配置文件,pid 文件,socket 文件等。
#
儲存引擎在MySQL的架構中位於第三層,負責MySQL中的資料的儲存和提取,是與文件打交道的子系統,它是根據MySQL提供的文件存取層抽象介面定制的一種文件存取機制,這種機制就叫作儲存引擎。
使用show engines指令,就可以查看目前資料庫支援的引擎資訊。 
在5.5版本前預設採用MyISAM儲存引擎,從5.5開始採用InnoDB儲存引擎。
##從MySQL 5.5版本開始預設使用InnoDB作為引擎,它擅長處理事務,具有自動崩潰復原的特性。下面是官方的InnoDB引擎架構圖,主要分為記憶體結構和磁碟結構兩大部分。
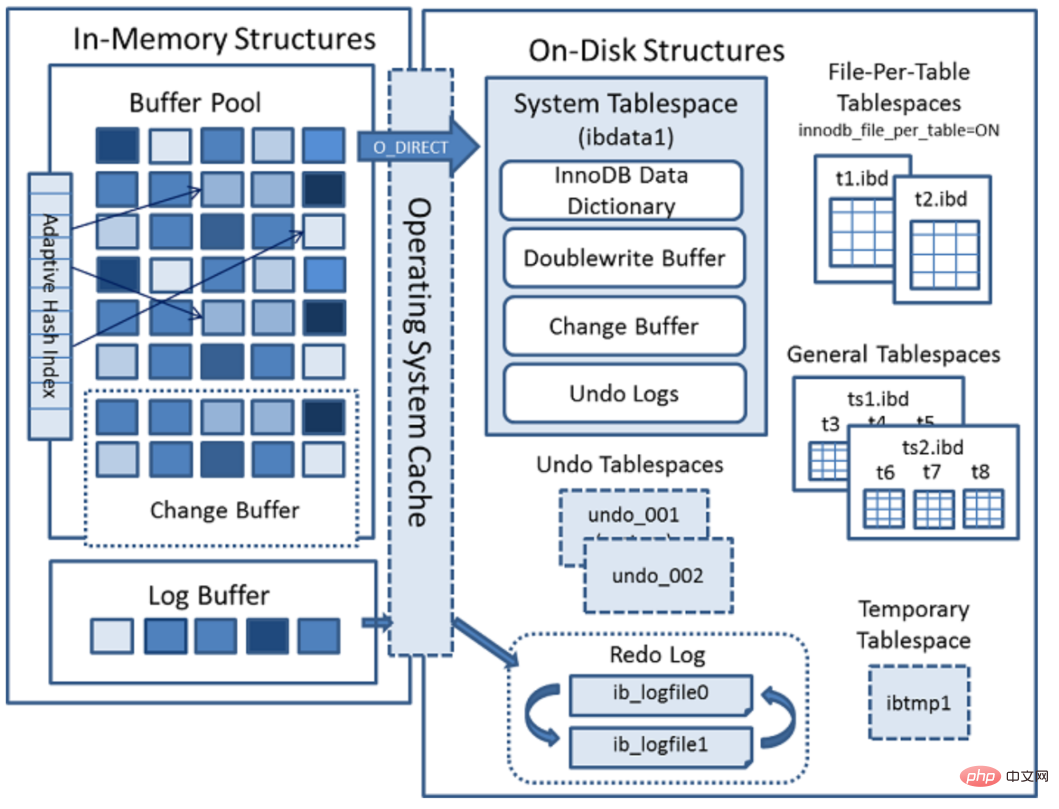
#記憶體結構主要包括Buffer Pool、Change Buffer、Adaptive Hash Index和Log Buffer四大元件。
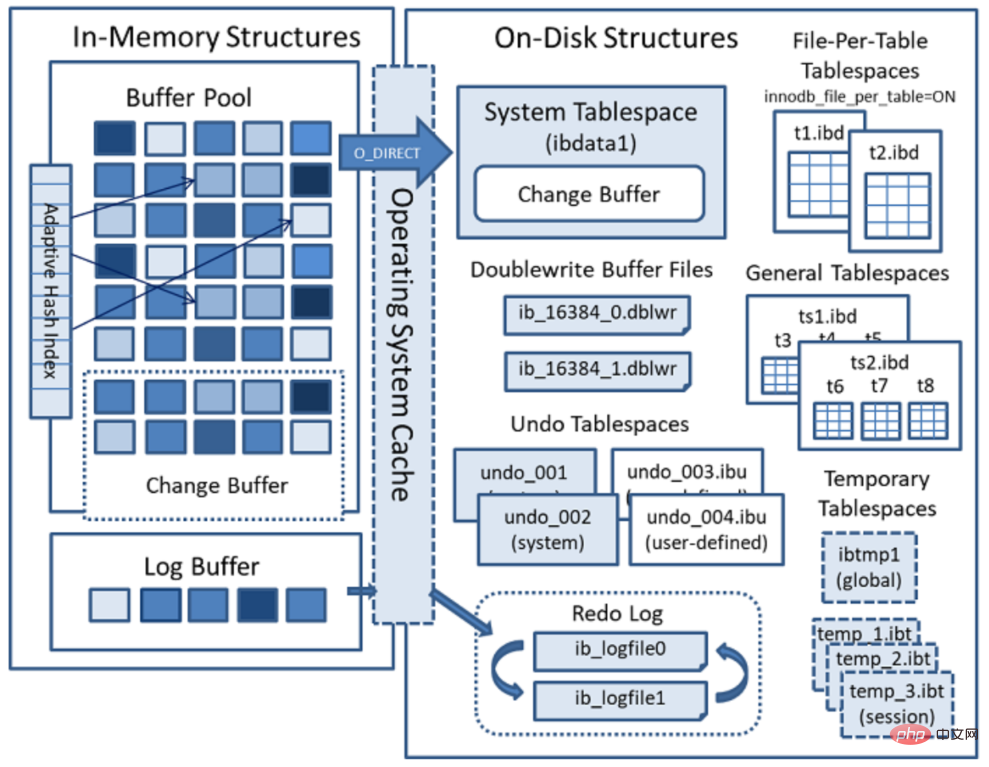
InnoDB磁碟主要包含Tablespaces,InnoDB Data Dictionary,Doublewrite Buffer、Redo Log和Undo Logs。
表空間(Tablespaces):用於儲存表格結構和資料。表空間又分為系統表空間、獨立表空間、通用表空間、暫存表空間、Undo表空間等多種型別;
系統表空間(The System Tablespace)
CREATE TABLESPACE ts1 ADD DATAFILE ts1.ibd Engine=InnoDB; //创建表空 间ts1 CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1; //将表添加到ts1 表空间
獨立表空間(File-Per-Table Tablespaces)
通用表空間(General Tablespaces)
撤銷表空間(Undo Tablespaces)
暫存表空間(Temporary Tablespaces)
資料字典(InnoDB Data Dictionary)
雙寫緩衝區(Doublewrite Buffer)
重做日誌(Redo Log)
撤銷日誌(Undo Logs)
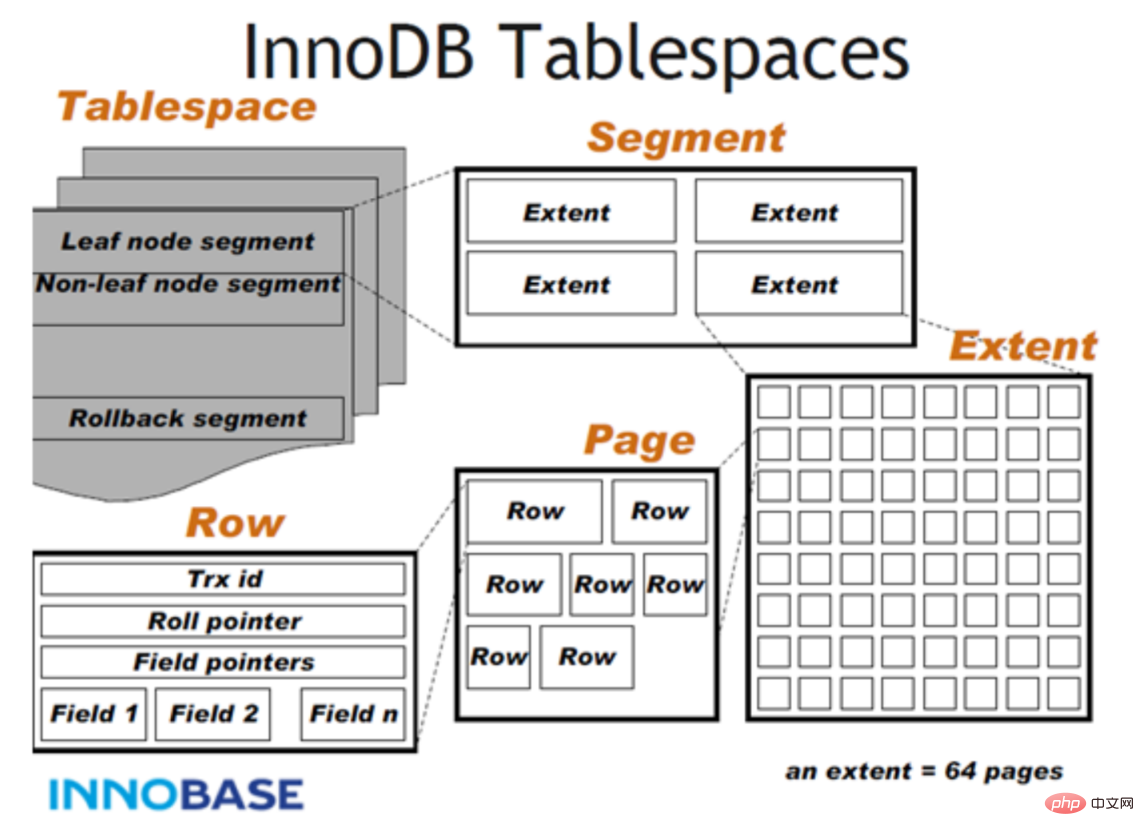
#############InnoDB資料文件儲存結構######
Page是文件最基本的单位,无论何种类型的page,都是由page header,page trailer和page body组成。如下图所示
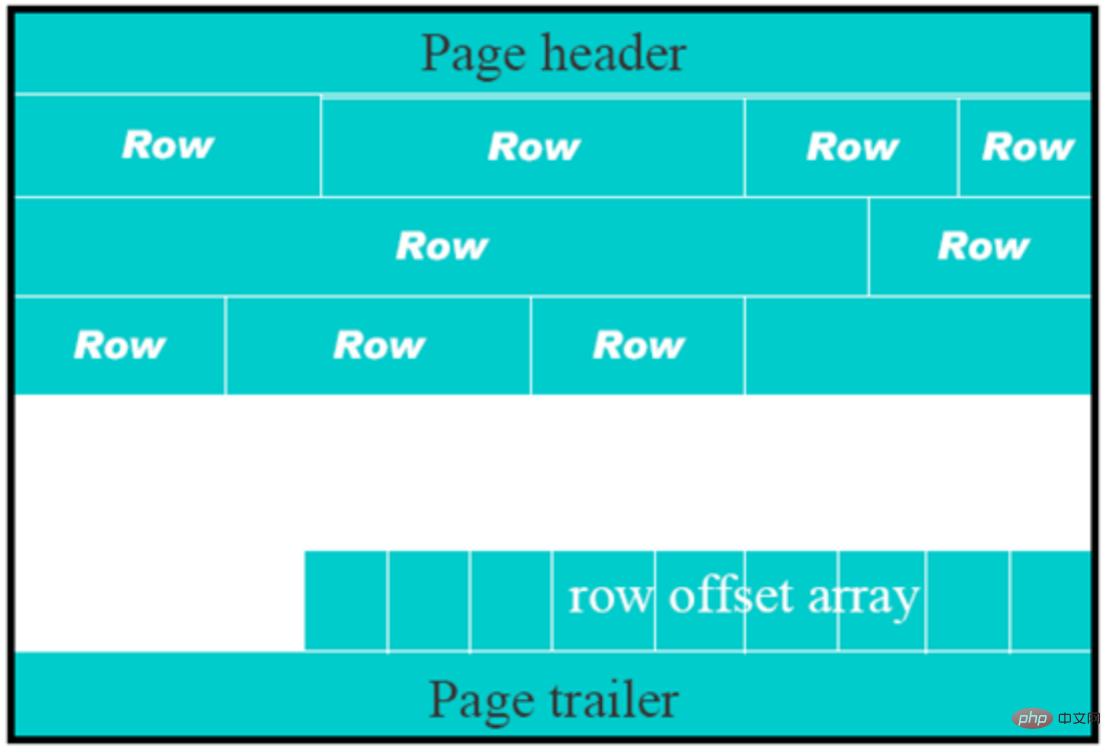
InnoDB文件存储格式
通过 SHOW TABLE STATUS 命令 查看
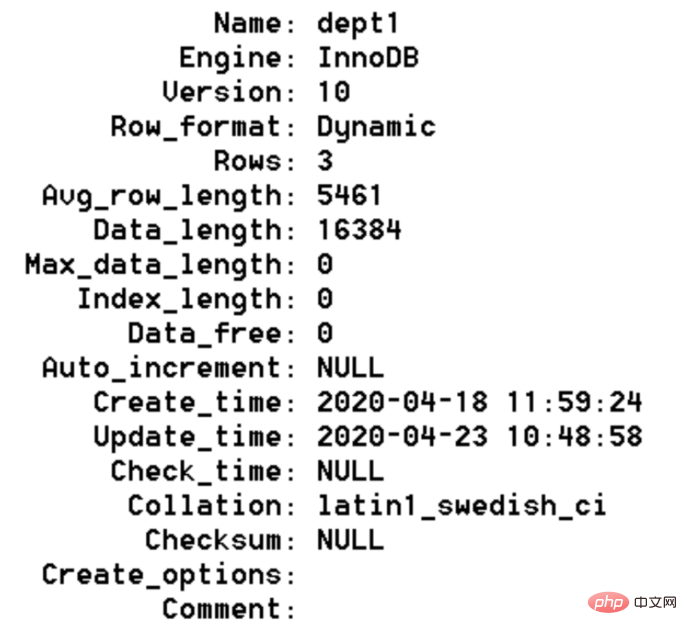
一般情况下,如果row_format为REDUNDANT、COMPACT,文件格式为Antelope;如果row_format为DYNAMIC和COMPRESSED,文件格式为Barracuda。
通过 information_schema 查看指定表的文件格式
select * from information_schema.innodb_sys_tables;
File文件格式(File-Format)
Row行格式(Row_format)
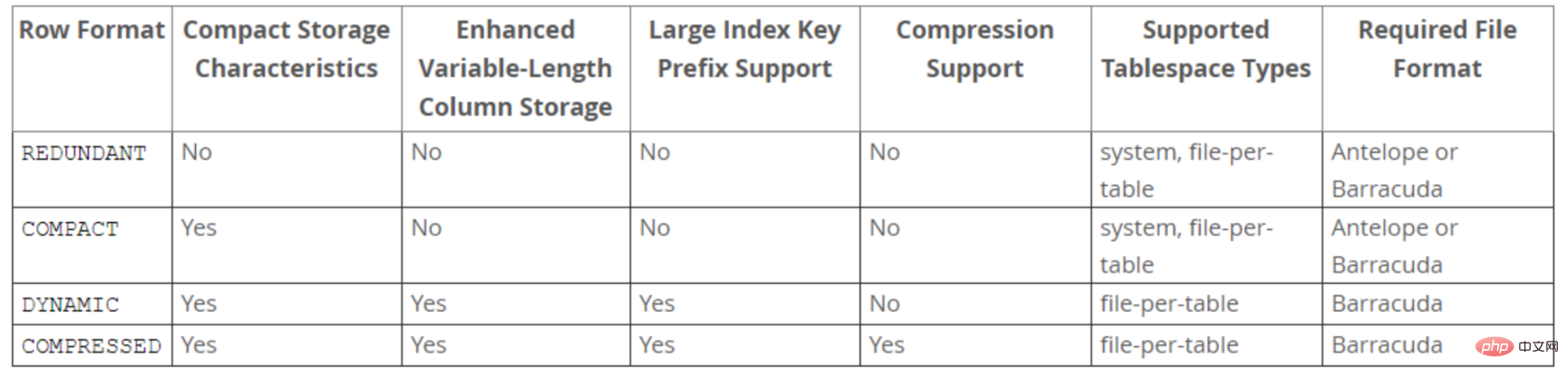
表的行格式决定了它的行是如何物理存储的,这反过来又会影响查询和DML操作的性能。如果在单个page页中容纳更多行,查询和索引查找可以更快地工作,缓冲池中所需的内存更少,写入更新时所需的I/O更少。
InnoDB存储引擎支持四种行格式:REDUNDANT、COMPACT、DYNAMIC和COMPRESSED。
DYNAMIC和COMPRESSED新格式引入的功能有:数据压缩、增强型长列数据的页外存储和大索引前缀。
每个表的数据分成若干页来存储,每个页中采用B树结构存储;
如果某些字段信息过长,无法存储在B树节点中,这时候会被单独分配空间,此时被称为溢出页,该字段被称为页外列。
在创建表和索引时,文件格式都被用于每个InnoDB表数据文件(其名称与*.ibd匹配)。修改文件格式的方法是重新创建表及其索引,最简单方法是对要修改的每个表使用以下命令:
ALTER TABLE 表名 ROW_FORMAT=格式类型;
Undo:意为撤销或取消,以撤销操作为目的,返回指定某个状态的操作。
Undo Log:数据库事务开始之前,会将要修改的记录存放到 Undo 日志里,当事务回滚时或者数据库崩溃时,可以利用 Undo 日志,撤销未提交事务对数据库产生的影响。
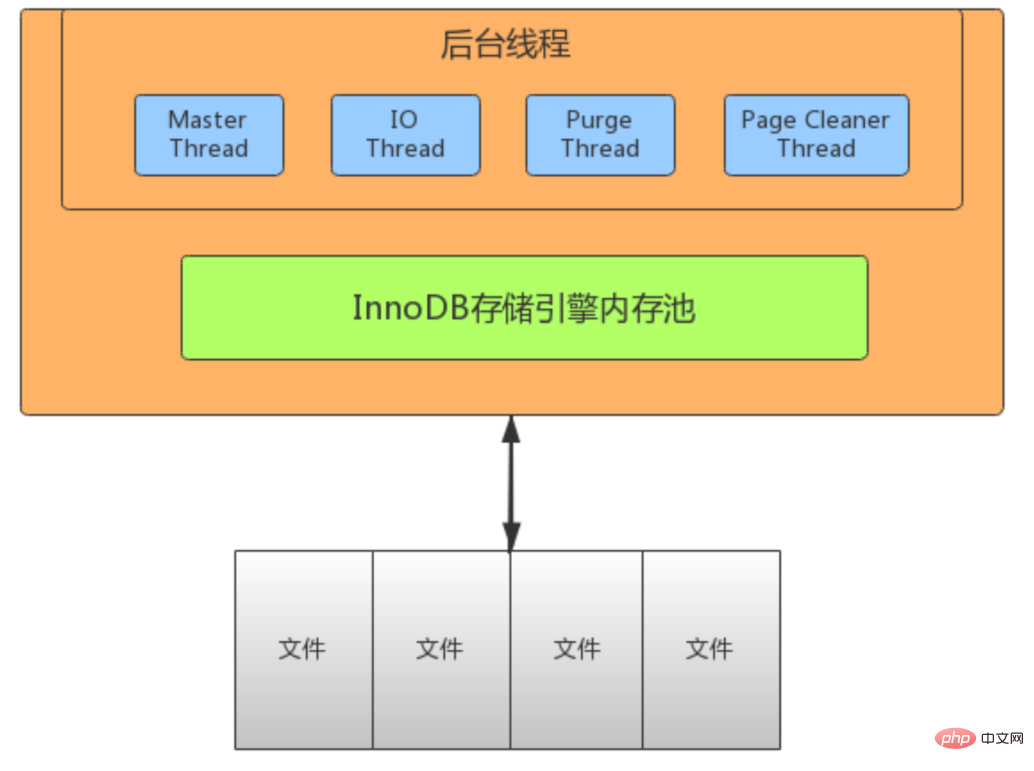
Undo Log产生和销毁:Undo Log在事务开始前产生;事务在提交时,并不会立刻删除undo log,innodb会将该事务对应的undo log放入到删除列表中,后面会通过后台线程purge thread进行回收处理。Undo Log属于逻辑日志,记录一个变化过程。例如执行一个delete,undolog会记录一个insert;执行一个update,undolog会记录一个相反的update。
Undo Log存储:undo log采用段的方式管理和记录。在innodb数据文件中包含一种rollback segment回滚段,内部包含1024个undo log segment。可以通过下面一组参数来控制Undo log存储。
#相关参数命令 show variables like '%innodb_undo%';
实现多版本并发控制(MVCC)
Undo Log 在 MySQL InnoDB 存储引擎中用来实现多版本并发控制。事务未提交之前,Undo Log保存了未提交之前的版本数据,Undo Log 中的数据可作为数据旧版本快照供其他并发事务进行快照读。
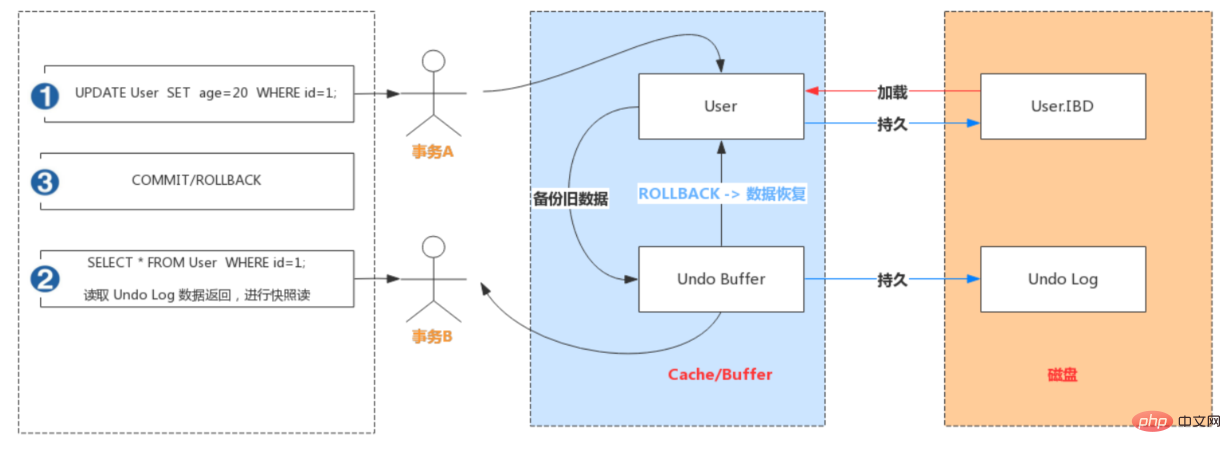
事务B手动开启事务,执行查询操作,会读取 Undo 日志数据返回,进行快照读;
Redo Log 和 Binlog
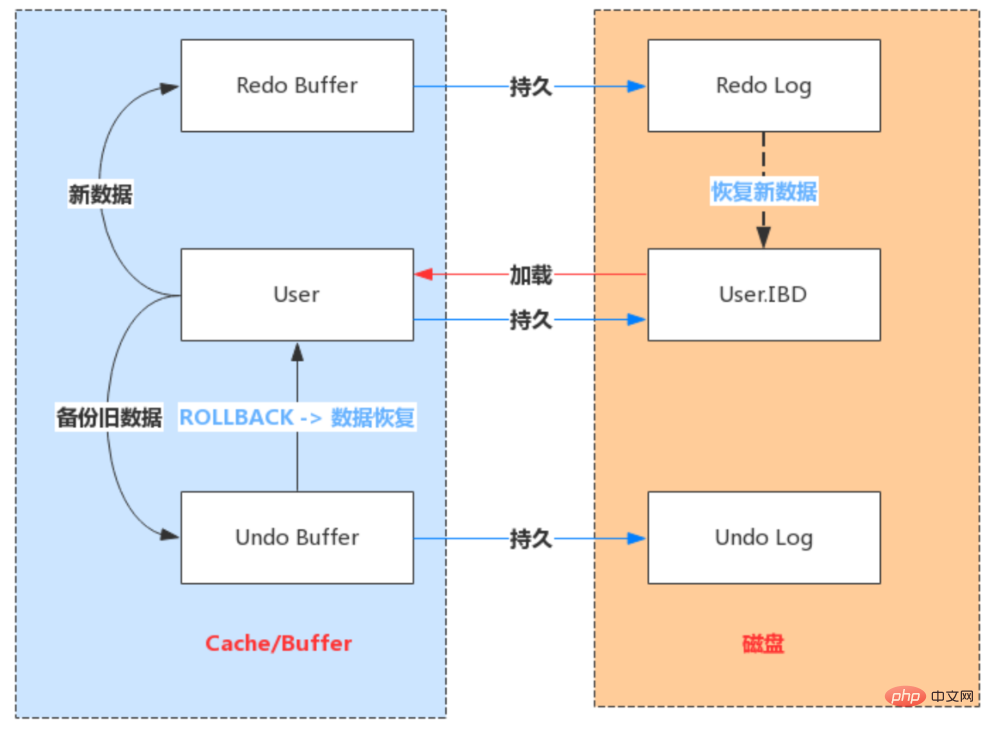
Redo Log 介绍
Redo Log工作原理
Redo Log写入机制
Redo Log 文件内容是以顺序循环的方式写入文件,写满时则回溯到第一个文件,进行覆盖写。
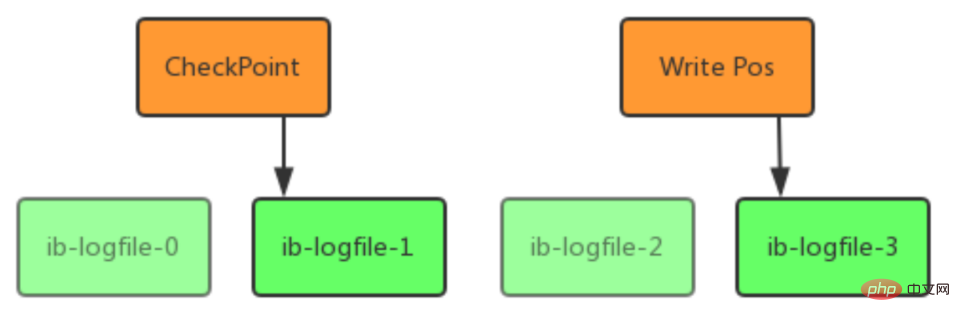
Redo Log相关配置参数
每个InnoDB存储引擎至少有1个重做日志文件组(group),每个文件组至少有2个重做日志文件,默认为ib_logfile0和ib_logfile1。可以通过下面一组参数控制Redo Log存储:
show variables like '%innodb_log%';
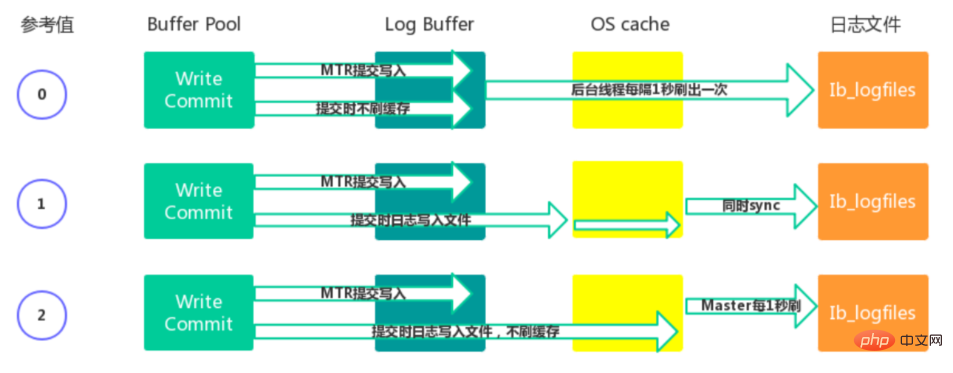
Redo Buffer 持久化到 Redo Log 的策略,可通过 Innodb_flush_log_at_trx_commit 设置:
Binlog 记录模式
Binlog 文件结构
Binlog文件中Log event结构如下图所示:

Binlog写入机制
Binlog文件操作
Binlog文件操作
Binlog状态查看
show variables like 'log_bin';
开启Binlog功能
set global log_bin = mysqllogbin; ERROR 1238 (HY000): Variable 'log_bin' is a read only variable
需要修改my.cnf或my.ini配置文件,在[mysqld]下面增加log_bin=mysql_bin_log,重启MySQL服务。
#log-bin=ON #log-bin-basename=mysqlbinlog binlog-format=ROW log-bin=mysqlbinlog
使用show binlog events命令
show binary logs; //等价于show master logs; show master status; show binlog events; show binlog events in 'mysqlbinlog.000001';
使用 mysqlbinlog 命令
mysqlbinlog "文件名" mysqlbinlog "文件名" > "test.sql"
使用 binlog 恢复数据
//按指定时间恢复 mysqlbinlog --start-datetime="2020-04-25 18:00:00" --stop- datetime="2020-04-26 00:00:00" mysqlbinlog.000002 | mysql -uroot -p1234 //按事件位置号恢复 mysqlbinlog --start-position=154 --stop-position=957 mysqlbinlog.000002 | mysql -uroot -p1234
mysqldump:定期全部备份数据库数据。mysqlbinlog可以做增量备份和恢复操作。
删除Binlog文件
purge binary logs to 'mysqlbinlog.000001'; //删除指定文件 purge binary logs before '2020-04-28 00:00:00'; //删除指定时间之前的文件 reset master; //清除所有文件
可以通过设置expire_logs_days参数来启动自动清理功能。默认值为0表示没启用。设置为1表示超出1天binlog文件会自动删除掉。
Redo Log和 Binlog区别
推荐学习:mysql视频教程
以上是圖文詳解mysql架構原理的詳細內容。更多資訊請關注PHP中文網其他相關文章!




















