

Python實例詳解pdfplumber讀取PDF寫入Excel

本篇文章為大家帶來了關於python的相關知識,其中主要介紹了關於pdfplumber讀取PDF寫入Excel的相關問題,包括了pdfplumber模組的安裝、載入PDF,以及一些實戰操作等等,下面一起來看一下,希望對大家有幫助。

推薦學習:python影片教學
#一、Python操作PDF 13大庫對比
PDF( Portable Document Format)是一種便攜式文件格式,便於跨作業系統傳播文件。 PDF文件遵循標準格式,因此有許多可以操作PDF文件的工具,Python自然也不例外。
Python操作PDF模組比較圖如下:
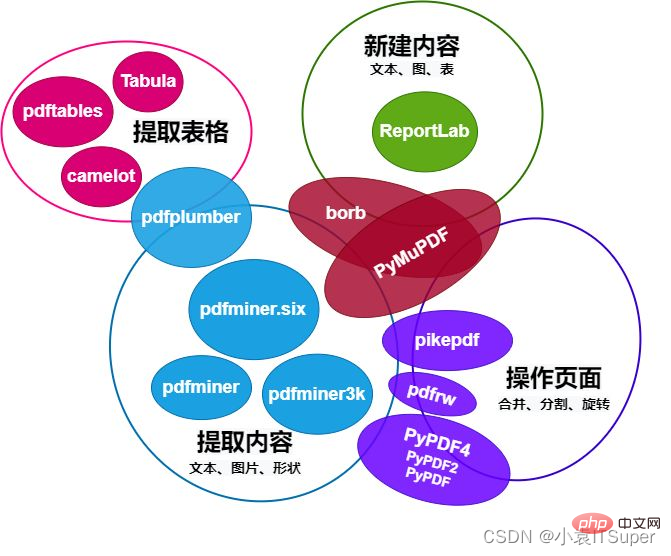
#本文主要介紹pdfplumber專注PDF內容擷取,例如文字(位置、字體及顏色等)和形狀(長方形、直線、曲線),還有解析表格的功能。
二、pdfplumber模組
其他幾個 Python 程式庫可協助使用者從 PDF 中提取資訊。作為一個廣泛的概述,pdfplumber它透過結合以下功能將自己與其他PDF 處理庫區分開來:
- 輕鬆存取有關每個PDF 物件的詳細資訊
- 用於提取文字和表格的更高層級、可自訂的方法
- 緊密整合的可視化偵錯
- 其他有用的實用功能,例如透過裁剪框過濾物件
1. 安裝
cmd控制台輸入:
pip install pdfplumber
導包:
import pdfplumber
案例PDF截圖(兩頁未截取):
#2. 載入PDF
讀取PDF程式碼:pdfplumber.open("路徑/檔案名稱.pdf", password = "test", laparams = { "line_overlap": 0.7 })
參數解讀:
-
#password:要載入受密碼保護的PDF,請傳遞password關鍵字參數 -
laparams:要將佈局分析參數設定為pdfminer.six的佈局引擎,請傳遞laparams關鍵字參數
案例程式碼:
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf)
print(type(pdf))輸出結果:
<pdfplumber.pdf.pdf><class></class></pdfplumber.pdf.pdf>
3. pdfplumber.PDF類別
pdfplumber.PDF類別表示單一PDF,並具有兩個主要屬性:
| 屬性 | 說明 |
|---|---|
#.metadata |
從PDF的Info中取得元資料鍵/值對字典。通常包括“ CreationDate”,“ ModDate”,“ Producer”等。 |
.pages |
傳回一個包含pdfplumber.Page實例的列表,每一個實例代表PDF每一頁的資訊 |
1. 讀取PDF文件資訊(.metadata):
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf.metadata)運行結果:
{'Author': 'wangwangyuqing', 'Comments': '', 'Company': '', 'CreationDate': "D:20220330113508+03'35'", 'Creator': 'WPS 文字', 'Keywords': '', 'ModDate': "D:20220330113508+03'35'", 'Producer': '', 'SourceModified': "D:20220330113508+03'35'", 'Subject': '', 'Title': '', 'Trapped': 'False'}2. 輸出總頁數
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(len(pdf.pages))執行結果:
2
4. pdfplumber.Page類別
pdfplumber.Page類別是pdfplumber整個的核心,大多數操作都圍繞著這個類別進行操作,它有以下幾個屬性:
| 屬性 | 說明 |
|---|---|
.page_number |
#順序頁碼,從1第一頁開始,從第二頁開始2,依此類推。 |
.width |
頁面的寬度。 |
.height |
頁面的高度。 |
.objects/.chars/.lines/.rects/.curves/.figures/.images |
這些屬性中的每一個都是一個列表,每個列表包含一個字典,用於嵌入頁面上的每個此類物件。有關詳細信息,請參閱下面的“對象”。 |
常用方法如下:
| #方法名稱 | 說明 |
|---|---|
.extract_text() |
#用來提頁面中的文本,將頁面的所有字元物件整理為的那個字串 |
.extract_words() |
#回傳的是所有的單字及其相關資訊 |
.extract_tables() |
提取頁面的表格 |
.to_image() |
#用於視覺化偵錯時,傳回PageImage類別的一個實例 |
#.close() |
預設情況下,Page物件快取其佈局和物件訊息,以避免重新處理它。但是,在解析大型 PDF 時,這些快取的屬性可能需要大量記憶體。您可以使用此方法刷新快取並釋放記憶體。 |
1. 读取第一页宽度、高度等信息
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
# 查看页码
print('页码:', first_page.page_number)
# 查看页宽
print('页宽:', first_page.width)
# 查看页高
print('页高:', first_page.height)运行结果:
页码: 1页宽: 595.3页高: 841.9
2. 读取文本第一页
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
text = first_page.extract_text()
print(text)运行结果:
店铺名 价格 销量 地址 小罐茶旗舰店 449 474 安徽 零趣食品旗舰店 6.9 60000 福建 天猫超市 1304 3961 上海 天猫超市 139 25000 上海 天猫超市 930 692 上海 天猫超市 980 495 上海 天猫超市 139 100000 上海 三只松鼠旗舰店 288 25000 安徽 红小厨旗舰店 698 1767 北京 三只松鼠旗舰店 690 15000 安徽 一统领鲜旗舰店 1098 1580 上海 新大猩食品专营9.8 7000 湖南.......舰店 蟹纳旗舰店 498 1905 上海 三只松鼠坚果at茶 188 35000 安徽 嘉禹沪晓旗舰店 598 1517 上海
3. 读取表格第一页
import pdfplumberimport xlwtwith pdfplumber.open("1.pdf") as pdf:
page_one = pdf.pages[0] # PDF第一页
table_1 = page_one.extract_table() # 读取表格数据
# 1. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 2. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 3. 自定义列名
col1 = table_1[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 4. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 5. 将数据写进sheet表单中
for i in range(0, len(table_1[1:])):
data = table_1[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 6. 保存文件分两种格式
workbook.save('test.xls')运行结果: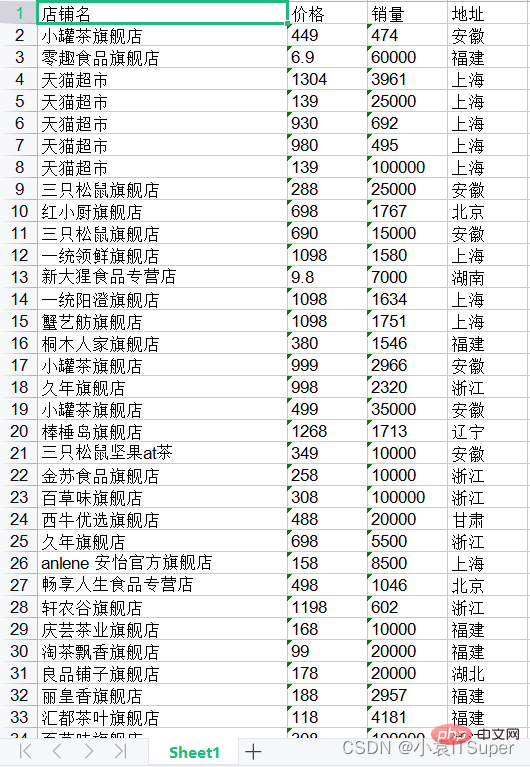
三、实战操作
1. 提取单个PDF全部页数
测试代码:
import pdfplumberimport xlwtwith pdfplumber.open("1.pdf") as pdf:
# 1. 把所有页的数据存在一个临时列表中
item = []
for page in pdf.pages:
text = page.extract_table()
for i in text:
item.append(i)
# 2. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 3. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 4. 自定义列名
col1 = item[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 5. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 6. 将数据写进sheet表单中
for i in range(0, len(item[1:])):
data = item[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 7. 保存文件分两种格式
workbook.save('test.xls')运行结果(上面得没截全):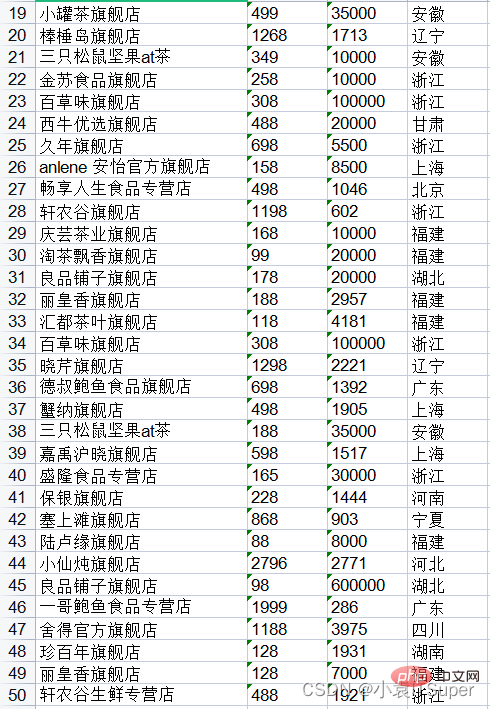
2. 批量提取多个PDF文件
测试代码:
import pdfplumber
import xlwt
import os
# 一、获取文件下所有pdf文件路径
file_dir = r'E:\Python学习\pdf文件'
file_list = []
for files in os.walk(file_dir):
# print(files)
# ('E:\\Python学习\\pdf文件', [],
# ['1.pdf', '1的副本.pdf', '1的副本10.pdf', '1的副本11.pdf', '1的副本2.pdf', '1的副本3.pdf', '1的副本4.pdf', '1的副本5.pdf', '1的副本6.pdf',
# '1的副本7.pdf', '1的副本8.pdf', '1的副本9.pdf'])
for file in files[2]:
# 以. 进行分割如果后缀为PDF或pdf就拼接地址存入file_list
if file.split(".")[1] == 'pdf' or file.split(".")[1] == 'PDF':
file_list.append(file_dir + '\\' + file)
# 二、存入Excel
# 1. 把所有PDF文件的所有页的数据存在一个临时列表中
item = []
for file_path in file_list:
with pdfplumber.open(file_path) as pdf:
for page in pdf.pages:
text = page.extract_table()
for i in text:
item.append(i)
# 2. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 3. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 4. 自定义列名
col1 = item[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 5. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 6. 将数据写进sheet表单中
for i in range(0, len(item[1:])):
data = item[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 7. 保存文件分两种格式
workbook.save('test.xls')运行结果(12个文件,一个文件50行总共600行):
推荐学习:python视频教程
以上是Python實例詳解pdfplumber讀取PDF寫入Excel的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python各有優劣,選擇取決於項目需求和個人偏好。 1.PHP適合快速開發和維護大型Web應用。 2.Python在數據科學和機器學習領域佔據主導地位。
 CentOS上如何進行PyTorch模型訓練
Apr 14, 2025 pm 03:03 PM
CentOS上如何進行PyTorch模型訓練
Apr 14, 2025 pm 03:03 PM
在CentOS系統上高效訓練PyTorch模型,需要分步驟進行,本文將提供詳細指南。一、環境準備:Python及依賴項安裝:CentOS系統通常預裝Python,但版本可能較舊。建議使用yum或dnf安裝Python3併升級pip:sudoyumupdatepython3(或sudodnfupdatepython3),pip3install--upgradepip。 CUDA與cuDNN(GPU加速):如果使用NVIDIAGPU,需安裝CUDATool
 CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
在CentOS系統上啟用PyTorchGPU加速,需要安裝CUDA、cuDNN以及PyTorch的GPU版本。以下步驟將引導您完成這一過程:CUDA和cuDNN安裝確定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA顯卡支持的CUDA版本。例如,您的MX450顯卡可能支持CUDA11.1或更高版本。下載並安裝CUDAToolkit:訪問NVIDIACUDAToolkit官網,根據您顯卡支持的最高CUDA版本下載並安裝相應的版本。安裝cuDNN庫:前
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python和JavaScript在社區、庫和資源方面的對比各有優劣。 1)Python社區友好,適合初學者,但前端開發資源不如JavaScript豐富。 2)Python在數據科學和機器學習庫方面強大,JavaScript則在前端開發庫和框架上更勝一籌。 3)兩者的學習資源都豐富,但Python適合從官方文檔開始,JavaScript則以MDNWebDocs為佳。選擇應基於項目需求和個人興趣。
 CentOS下PyTorch版本怎麼選
Apr 14, 2025 pm 02:51 PM
CentOS下PyTorch版本怎麼選
Apr 14, 2025 pm 02:51 PM
在CentOS下選擇PyTorch版本時,需要考慮以下幾個關鍵因素:1.CUDA版本兼容性GPU支持:如果你有NVIDIAGPU並且希望利用GPU加速,需要選擇支持相應CUDA版本的PyTorch。可以通過運行nvidia-smi命令查看你的顯卡支持的CUDA版本。 CPU版本:如果沒有GPU或不想使用GPU,可以選擇CPU版本的PyTorch。 2.Python版本PyTorch
 minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
MinIO對象存儲:CentOS系統下的高性能部署MinIO是一款基於Go語言開發的高性能、分佈式對象存儲系統,與AmazonS3兼容。它支持多種客戶端語言,包括Java、Python、JavaScript和Go。本文將簡要介紹MinIO在CentOS系統上的安裝和兼容性。 CentOS版本兼容性MinIO已在多個CentOS版本上得到驗證,包括但不限於:CentOS7.9:提供完整的安裝指南,涵蓋集群配置、環境準備、配置文件設置、磁盤分區以及MinI
 CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系統上進行PyTorch分佈式訓練,需要按照以下步驟操作:PyTorch安裝:前提是CentOS系統已安裝Python和pip。根據您的CUDA版本,從PyTorch官網獲取合適的安裝命令。對於僅需CPU的訓練,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,請確保已安裝對應版本的CUDA和cuDNN,並使用相應的PyTorch版本進行安裝。分佈式環境配置:分佈式訓練通常需要多台機器或單機多GPU。所
