

Python隨機森林模型實例詳解

本篇文章為大家帶來了關於Python的相關知識,其中主要整理了隨機森林模型的相關問題,包括了集成模型簡介、隨機森林模型基本原理、使用sklearn實現隨機森林模型等等內容,下面一起來看一下,希望對大家有幫助。

【相關推薦:Python3影片教學 】
1 整合模型簡介
整合學習模型使用一系列弱學習器(也稱為基礎模型或基底模型)進行學習,並將各個弱學習器的結果整合,從而獲得比單一學習器更好的學習效果。
整合學習模型的常見演算法有Bagging演算法和Boosting演算法兩種。
Bagging演算法的典型機器學習模型為隨機森林模型,而Boosting演算法的典型機器學習模型則為AdaBoost、GBDT、XGBoost和LightGBM模型。
1.1 Bagging演算法簡介
Bagging演算法的原理類似投票,每個弱學習器都有一票,最終根據所有弱學習器的投票,按照「少數服從多數」的原則產生最終的預測結果,如下圖所示。
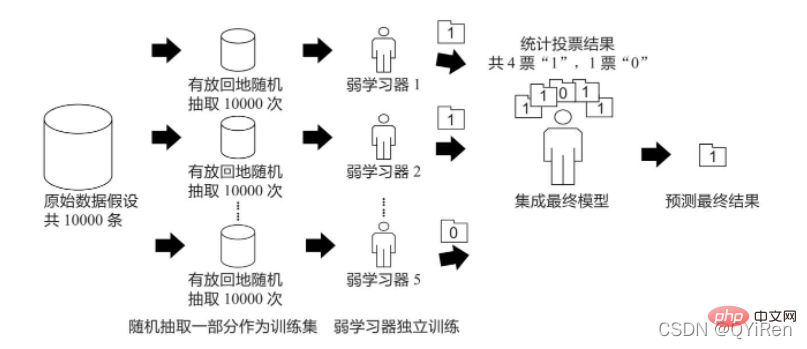
假設原始資料共有10000條,從中隨機有放回地抽取10000次資料構成一個新的訓練集(因為是隨機有放回抽樣,所以可能出現某一條資料多次被抽中,也有可能某一條資料一次也沒有被抽中),每次使用一個訓練集訓練一個弱學習器。這樣有放回地隨機抽取n次後,訓練結束時就能獲得由不同的訓練集訓練出的n個弱學習器,根據這n個弱學習器的預測結果,按照「少數服從多數」的原則,獲得一個更準確、合理的最終預測結果。
具體來說,在分類問題中是用n個弱學習器投票的方式獲取最終結果,在回歸問題中則是取n個弱學習器的平均值作為最終結果。
1.2 Boosting演算法簡介
Boosting演算法的本質是將弱學習器提升為強學習器,它和Bagging演算法的區別在於:Bagging演算法對待所有的弱學習器一視同仁;而Boosting演算法則會對弱學習器“區別對待”,通俗來講就是注重“培養精英”和“重視錯誤”。
「培養菁英」就是每一輪訓練後對預測結果較準確的弱學習器給予較大的權重,對錶現不好的弱學習器則降低其權重。這樣在最終預測時,「優秀模型」的權重是大的,相當於它可以投出多票,而「一般模型」只能投出一票或不能投票。
「重視錯誤」就是在每一輪訓練後改變訓練集的權值或機率分佈,透過提高在前一輪被弱學習器預測錯誤的範例的權值,降低前一輪被弱學習器預測正確的樣例的權值,來提高弱學習器對預測錯誤的數據的重視程度,從而提升模型的整體預測效果。
2 隨機森林模型基本原理
隨機森林(Random Forest)是一種經典的Bagging模型,其弱學習器為決策樹模型。 如下圖所示,隨機森林模型會在原始資料集中隨機抽樣,構成n個不同的樣本資料集,然後根據這些資料集建立n個不同的決策樹模型,最後根據這些決策樹模型的平均值(針對迴歸模型)或投票情況(針對分類模型)來取得最終結果。
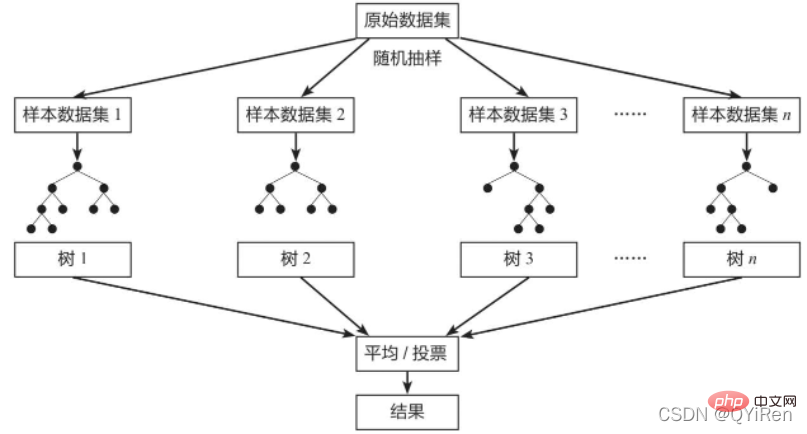
為了保證模型的泛化能力(或通用能力),隨機森林模型在建立每棵樹時,往往會遵循「數據隨機」和「特徵隨機」這兩個基本原則。
資料隨機:從所有資料當中有放回地隨機抽取資料作為其中一個決策樹模型的訓練資料。例如,有1000個原始數據,有放回地抽取1000次,構成一組新的數據,用來訓練某一個決策樹模型。
特徵隨機:如果每個樣本的特徵維度為M,指定一個常數k<M,隨機地從M個特徵中選取k個特徵。
與單獨的決策樹模型相比,隨機森林模型由於整合了多個決策樹,其預測結果會更準確,且不容易造成過擬合現象,泛化能力更強。
3 使用sklearn實現隨機森林模型
隨機森林模型既能進行分類分析,又能進行迴歸分析,對應的模型分別為:
·隨機森林分類模型(RandomForestClassifier)
·隨機森林迴歸模型(RandomForestRegressor)
#隨機森林分類模型的弱學習器是分類決策樹模型,隨機森林迴歸模型的弱學習器則是回歸決策樹模型。
程式碼如下。
from sklearn.ensemble import RandomForestClassifier X = [[1,2],[3,4],[5,6],[7,8],[9,10]] y = [0,0,0,1,1] # 设置弱学习器数量为10 model = RandomForestClassifier(n_estimators=10,random_state=123) model.fit(X,y) model.predict([[5,5]]) # 输出为:array([0])
4 案例:股票漲跌預測模型
4.1 股票衍生變數產生
本節講解如何利用股票的基本數據取得一些衍生變數數據,如股票技術分析常用的均線指標5日均線價格MA5與10日均線價格MA10、相對強弱指標RSI、動量指標MOM、指數移動平均EMA、異同移動平均線MACD等。
4.1.1 取得股票基本資料
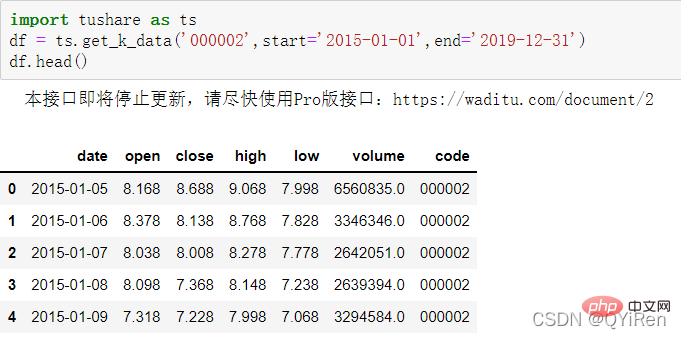
先用get_k_data()函數取得2015-01-01到2019-12-31的股票基本數據,代碼如下。
前5行資料如下圖所示,其中缺少的資料為假日(非交易日)資料。
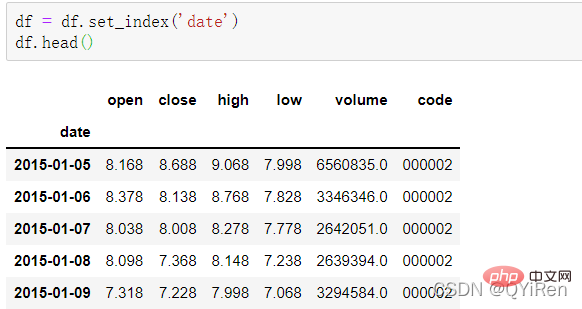
用set_index()函數將date列設定為行索引,程式碼如下。
4.1.2 產生簡單衍生變數
透過以下程式碼可以產生一些簡單的衍生變數資料。
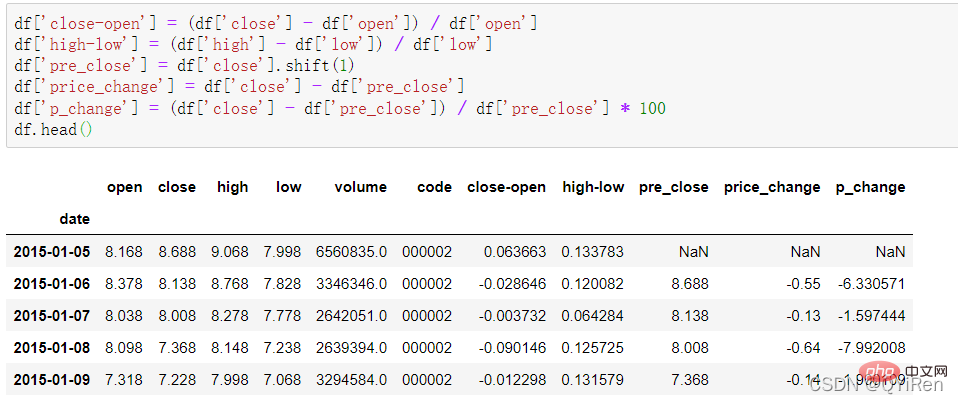
close-open表示(收盤價-開盤價)/開盤價;
high-low表示(最高價-最低價)/最低價;
pre_close表示昨日收盤價,用shift(1)將close列的所有資料向下移動1行並形成新的1列,如果是shift(- 1)則表示向上移動1行;
price_change表示今日收盤價-昨日收盤價,即當天的股價變動;
p_change表示當天股價變動的百分比,也稱為當天股價的漲跌幅。
4.1.3 產生移動平均線指標MA值
透過以下程式碼可以產生股價的5日移動平均值和10日移動平均值。
注意:rolling函數的使用
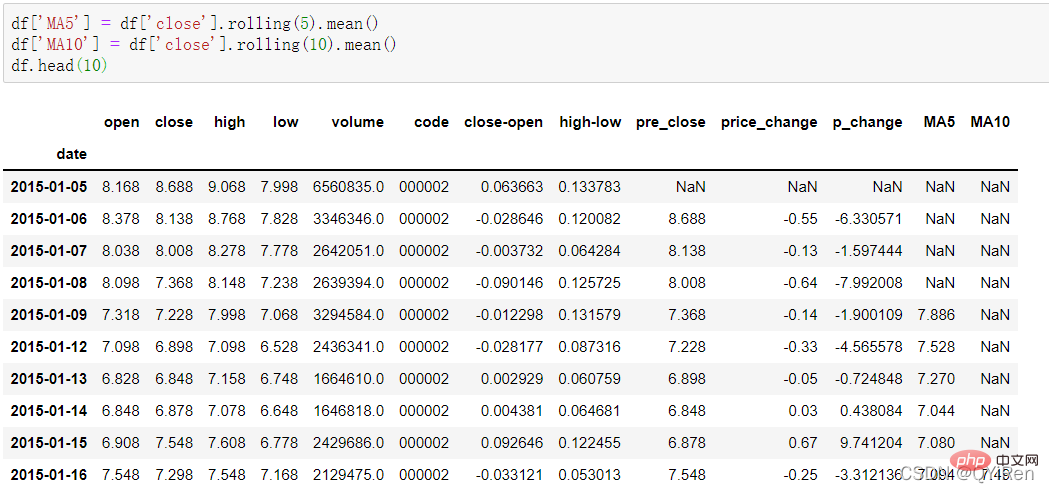
其中,MA是移動平均線的意思,“平均」是指最近n天收盤的算術平均值,「移動」是指在計算中始終採用最近n天的價格資料。
例如:MA5的計算
依據上述數據,5號的MA5值為(1.2+1.4+1.6+1.8+2.0 )/5=1.6,而6號的MA5值則為(1.4+1.6+1.8+2.0+2.2)/5=1.8,依此類推。將一段期間內股價的移動平均值連成曲線,即為移動平均線。同理,MA10為計算當天起前10天的股價平均值。

在計算像MA5這樣的數據時,因為最開始的4天數據量不夠,這4天對應的移動平均值是無法計算出來的,所以會產生空值NaN。通常會用dropna()函數刪除空值,以免後續計算中出現因空值造成的問題,程式碼如下。
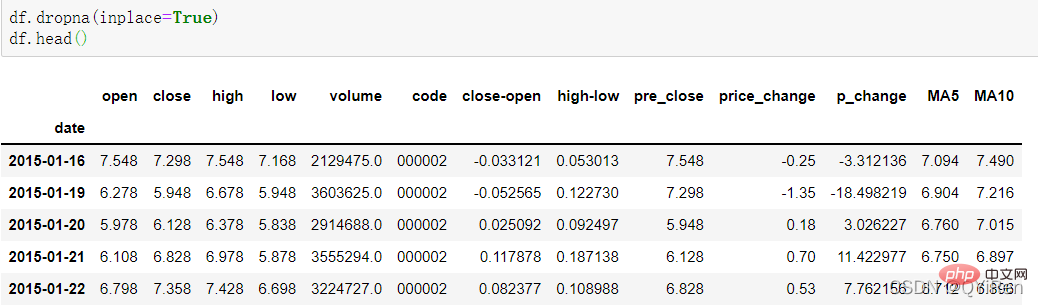
可以看到16號以前的行被刪除。
4.1.4 用TA-Lib函式庫產生相對強弱指標RSI值
透過以下程式碼可以產生相對強弱指標RSI值。
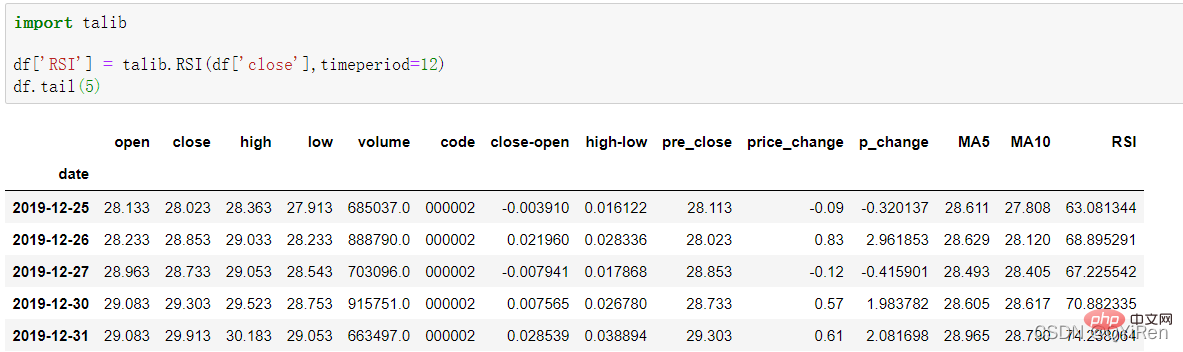
RSI值能反映短期內股價漲勢相對於跌勢的強弱,幫助我們更好地判斷股價的漲跌趨勢。
RSI值越大,漲勢相對於跌勢越強,反之則漲勢相對於跌勢越弱。
RSI值的計算公式如下。

範例:
# 根據上表數據,取N=6 ,可求6日平均上漲價格為(2+2+2)/6=1,6日平均下跌價格為(1+1+1)/6=0.5,所以RSI值為(1/(1+0.5))×100=66.7。
通常情況下,RSI值位於20~80之間,超過80則為超買狀態,低於20則為超賣狀態,等於50則認為買賣雙方力量均等。例如,如果連續6天股價都是上漲,則6日平均下跌價格為0,6日RSI值為100,顯示此時股票買方處於非常強勢的地位,但也提醒投資者要警惕此時可能也是超買狀態,需要預防股價下跌的風險。
4.1.5 用TA-Lib庫產生動量指標MOM值
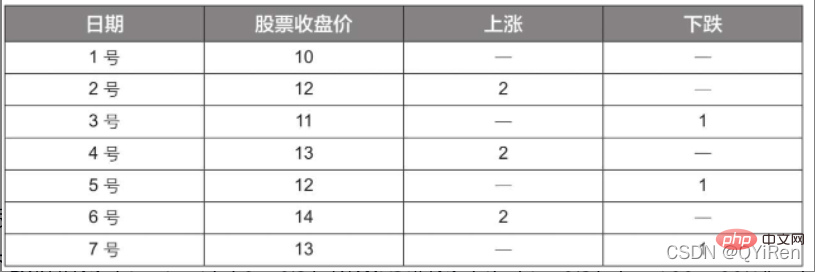
#透過以下程式碼可以產生動量指標MOM值。
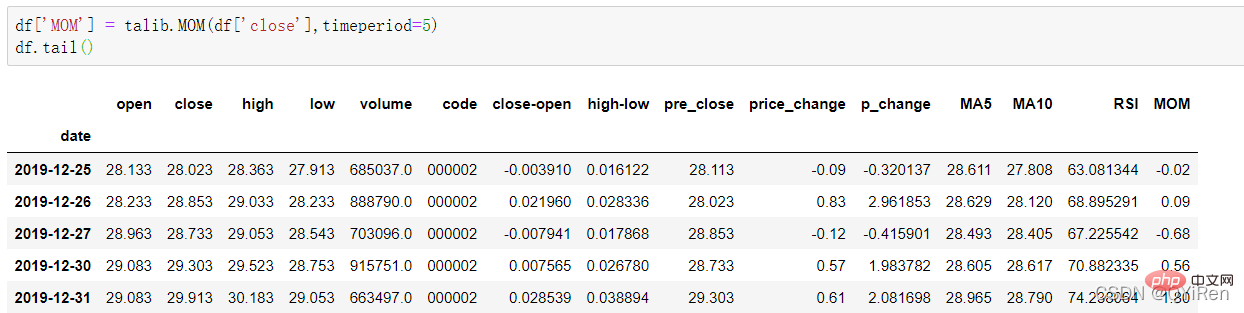
MOM是momentum(動量)的縮寫,它反映了一段時間內股價的漲跌速度,計算公式如下。
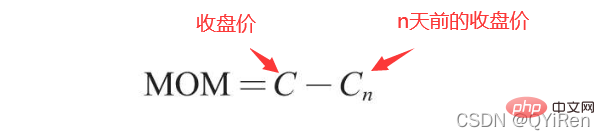
範例:
# 假設要計算6號的MOM值,而前面的程式碼設定參數timeperiod為5,那麼就需要用6號的收盤價減去1號的收盤價,即6號的MOM值為2.2-1.2=1,同理,7號的MOM值為2.4-1.4=1。將連續幾天的MOM值連起來就構成一條反映股價漲跌變動的曲線。

4.1.6 用TA-Lib庫產生指數移動平均值EMA
#透過以下程式碼可以產生指數移動平均值EMA。
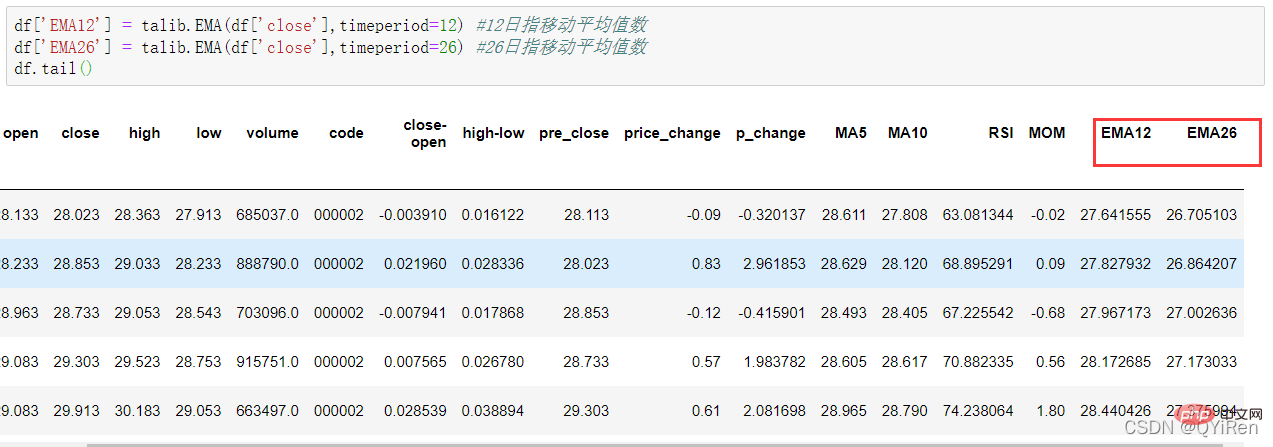
EMA是以指數式遞減加權的移動平均,並根據計算結果進行分析,用於判斷股價未來走勢的變動趨勢。
EMA的計算公式如下。
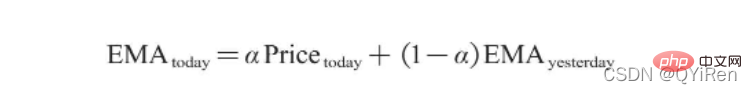
其中,EMAtoday為當天的EMA值;Pricetoday為當天的收盤價;EMAyesterday為昨天的EMA值;α為平滑指數,一般值為2/(N+1),N表示天數,當N為6時,α為2/7,對應的EMA稱為EMA6,即6日指數移動平均值。公式不斷遞歸,直到第1個EMA值出現(第1個EMA值通常為開頭5個數的平均值)。
範例:EMA6
取第1個EMA值為開頭5個數的平均值,故前5天都沒有EMA值; 6號的EMA值就是第1個EMA值,為前5天的平均值,即1;7號的EMA值為第2個EMA值,計算過程如下。

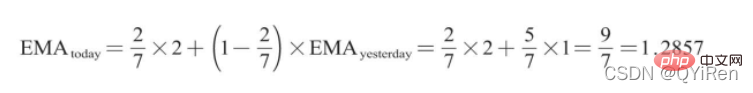
4.1.7 用TA-Lib函式庫產生異同移動平均線MACD值
透過下列程式碼可以產生異同移動平均線MACD值。
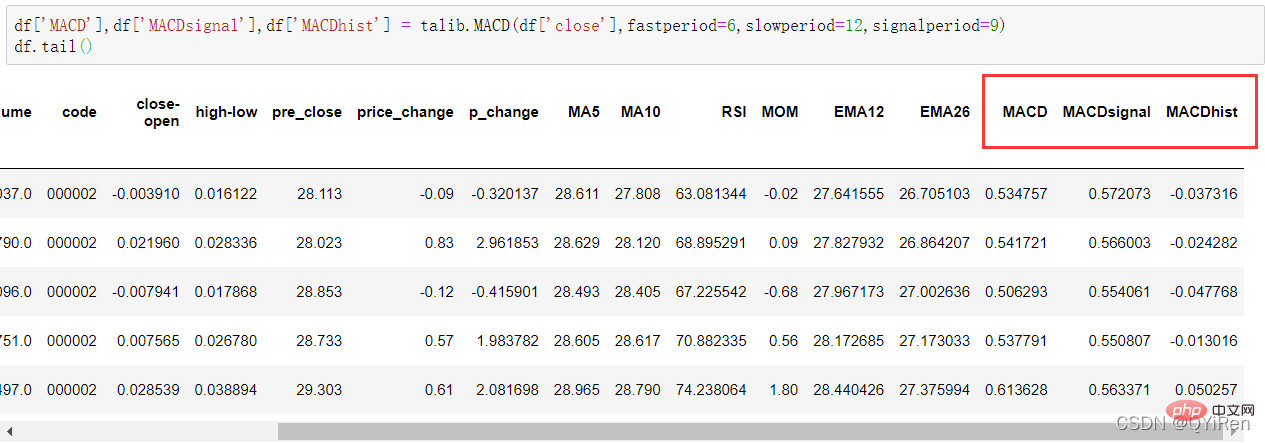
MACD是股票市場上的常用指標,它是基於EMA值的衍生變量,計算方法比較複雜,有興趣的讀者可以自行了解。這裡只需要知道MACD是一種趨勢類別指標,其變化代表著市場趨勢的變化,不同K線等級的MACD代表目前等級週期中的買賣趨勢。
4.2 模型搭建
4.2.1 引入需要搭建的库
# 导入相关库 import tushare as ts import numpy as np import pandas as pd import talib import matplotlib.pyplot as plt from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score
4.2.2 获取数据
# 1.股票基本数据获取
import tushare as ts
df = ts.get_k_data('000002',start='2015-01-01',end='2019-12-31')
df = df.set_index('date')
# 2.简单衍生变量数据构造
df['close-open'] = (df['close'] - df['open']) / df['open']
df['high-low'] = (df['high'] - df['low']) / df['low']
df['pre_close'] = df['close'].shift(1)
df['price_change'] = df['close'] - df['pre_close']
df['p_change'] = (df['close'] - df['pre_close']) / df['pre_close'] * 100
# 3.移动平均线相关数据构造
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()
df.dropna(inplace=True)
# 4.通过TA-Lib库构造衍生变量数据
df['RSI'] = talib.RSI(df['close'],timeperiod=12)
df['MOM'] = talib.MOM(df['close'],timeperiod=5)
df['EMA12'] = talib.EMA(df['close'],timeperiod=12) #12日指移动平均值数
df['EMA26'] = talib.EMA(df['close'],timeperiod=26) #26日指移动平均值数
df['MACD'],df['MACDsignal'],df['MACDhist'] = talib.MACD(df['close'],fastperiod=6,slowperiod=12,signalperiod=9)
df.dropna(inplace=True)4.2.3 提取特征变量和目标变量
X = df[['close','volume','close-open','MA5','MA10','high-low','RSI','MOM','EMA12','MACD','MACDsignal','MACDhist']] y = np.where(df['price_change'].shift(-1) > 0,1,-1)
首先强调最核心的一点:应该是用当天的股价数据预测下一天的股价涨跌情况,所以目标变量y应该是下一天的股价涨跌情况。为什么是用当天的股价数据预测下一天的股价涨跌情况呢?这是因为特征变量中的很多数据只有在当天交易结束后才能确定(例如,收盘价close只有收盘了才有),所以当天正在交易时的股价涨跌情况是无法预测的,而等到收盘时尽管所需数据齐备,但是当天的股价涨跌情况已成定局,也就没有必要预测了,所以是用当天的股价数据预测下一天的股价涨跌情况。
第2行代码中使用了NumPy库中的where()函数,传入的3个参数的含义分别为判断条件、满足条件的赋值、不满足条件的赋值。其中df['price_change'].shift(-1)是利用shift()函数将price_change(股价变化)这一列的所有数据向上移动1行,这样就获得了每一行对应的下一天的股价变化。因此,这里的判断条件就是下一天的股价变化是否大于0,如果大于0,说明下一天股价涨了,则y赋值为1;如果不大于0,说明下一天股价不变或跌了,则y赋值为-1。预测结果就只有1或-1两种分类。
4.2.4 划分训练集和测试集
这里需要注意的是,划分要按照时间序列进行,而不能用train_test_split()函数进行随机划分。这是因为股价的变化趋势具有时间性特征,而随机划分会破坏这种特征,所以需要根据当天的股价数据预测下一天的股价涨跌情况,而不能根据任意一天的股价数据预测下一天的股价涨跌情况。
将前90%的数据作为训练集,后10%的数据作为测试集,代码如下。
X_length = X.shape[0] split = int(X_length * 0.9) X_train,X_test = X[:split],X[split:] y_train,y_test = y[:split],y[split:]
4.2.5 模型搭建
model = RandomForestClassifier(max_depth=3,n_estimators=10,min_samples_leaf=10,random_state=123) model.fit(X_train,y_train)
设置模型参数:决策树的最大深度max_depth设置为3,即每个决策树最多只有3层;弱学习器(即决策树模型)的个数n_estimators设置为10,即该随机森林中共有10个决策树;叶子节点的最小样本数min_samples_leaf设置为10,即如果叶子节点的样本数小于10则停止分裂;随机状态参数random_state的作用是使每次运行结果保持一致,这里设置的数字123没有特殊含义,可以换成其他数字。
4.3 模型评估与使用
4.3.1 预测下一天的股价涨跌情况
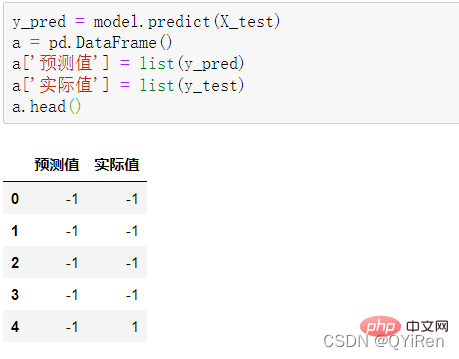
用predict_proba()函数可以预测属于各个分类的概率,代码如下。
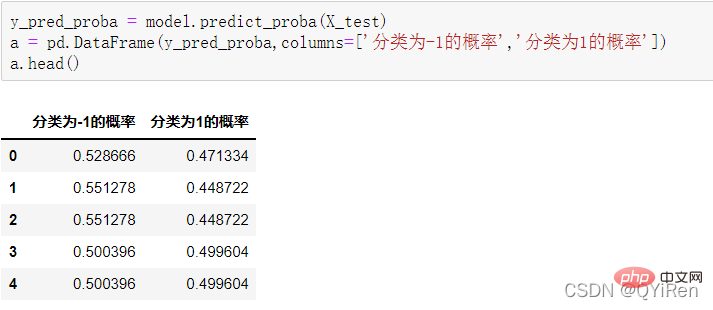
4.3.2 模型准确度评估
通过如下代码可以查看整体的预测准确度。
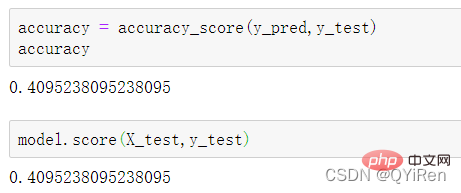
打印输出score为0.40,说明模型对整个测试集中约40%的数据预测正确。这一预测准确度并不算高,也的确符合股票市场千变万化的特点。
4.3.3 分析特征变量的特征重要性
通过如下代码可以分析各个特征变量的特征重要性。
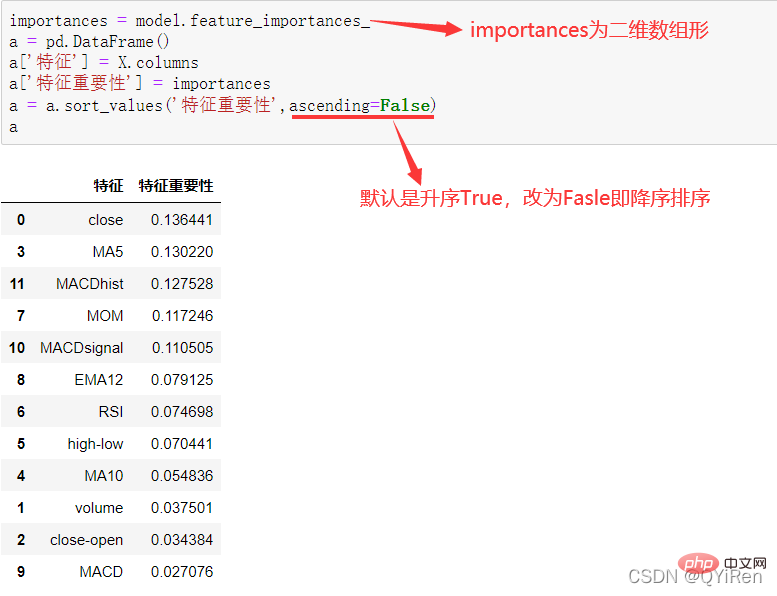
由图可知,当日收盘价close、MA5、MACDhist相关指标等特征变量对下一天股价涨跌结果的预测准确度影响较大。
4.4 参数调优
from sklearn.model_selection import GridSearchCV
parameters={'n_estimators':[5,10,20],'max_depth':[2,3,4,5,6],'min_samples_leaf':[5,10,20,30]}
new_model = RandomForestClassifier(random_state=123)
grid_search = GridSearchCV(new_model,parameters,cv=6,scoring='accuracy')
grid_search.fit(X_train,y_train)
grid_search.best_params_
# 输出
# {'max_depth': 5, 'min_samples_leaf': 20, 'n_estimators': 5}4.5 收益回测曲线绘制
前面已经评估了模型的预测准确度,不过在商业实战中,更关心它的收益回测曲线(又称为净值曲线),也就是看根据搭建的模型获得的结果是否比不利用模型获得的结果更好。
# 在测试数据上添加一列,预测收益 X_test['prediction'] = model.predict(X_test) # 计算每天的股价变化率 X_test['p_change'] = (X_test['close'] - X_test['close'].shift(1)) / X_test['close'].shift(1) # 计算累积收益率 # 例如,初始股价是1,2天内的价格变化率为10% # 那么用cumprod()函数可以求得2天后的股价为1×(1+10%)×(1+10%)=1.21 # 此结果也表明2天的收益率为21%。 X_test['origin'] = (X_test['p_change'] + 1).cumprod() # 计算利用模型预测后的收益率 X_test['strategy'] = (X_test['prediction'].shift(1) * X_test['p_change'] + 1).cumprod() X_test[['strategy','origin']].dropna().plot() # 设置自动倾斜 plt.gcf().autofmt_xdate() plt.show()
可视化结果如下图所示。图中上方的曲线为根据模型得到的收益率曲线,下方的曲线为股票本身的收益率曲线,可以看到,利用模型得到的收益还是不错的。
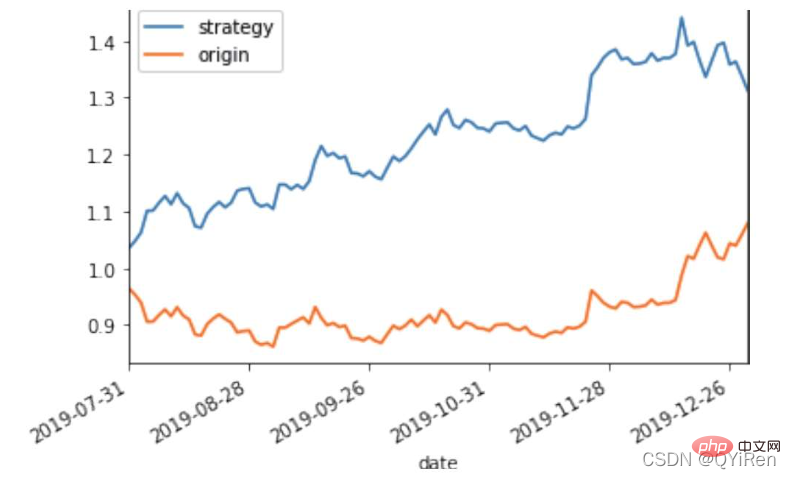
要说明的是,这里讲解的量化金融内容比较浅显,搭建的模型过于理想化,真正的股市是错综复杂的,股票交易也有很多限制,如不能做空、不能T+0交易,还要考虑手续费等因素。
随机森林模型是一种非常重要的集成模型,它集成了决策树模型的众多优点,又规避了决策树模型容易过度拟合等缺点,在实战中应用较为广泛。
【相关推荐:Python3视频教程 】
以上是Python隨機森林模型實例詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
