在linux中,堆疊是一種串列形式的資料結構;這種資料結構的特徵是後入先出,資料只能在串列的一端進行推入和彈出的操作,linux中的棧可以分為進程棧、執行緒棧、核心棧和中斷棧。

本教學操作環境:linux7.3系統、Dell G3電腦。
堆疊 (stack) 是一種串列形式的 資料結構。這種資料結構的特徵是 後入先出 (LIFO, Last In First Out),資料只能在串列的一端 (稱為:棧頂 top) 進行 推入 (push) 和 彈出 (pop) 操作。
進程堆疊
執行緒堆疊
核心堆疊

中斷堆疊
- 大多數的處理器架構,都有實作硬體堆疊。有專門的堆疊指標暫存器,以及特定的硬體指令來完成 入棧/出棧 的操作。例如在 ARM 架構上,R13 (SP) 指標是堆疊指標暫存器,而 PUSH 是用來壓棧的組譯指令,POP 則是出棧的組譯指令。
【擴充閱讀】ARM 暫存器簡介- 提供了下列暫存器:
ARM 處理器擁有 37 個暫存器。這些暫存器會依部分重疊組方式加以排列。每個處理器模式都有一個不同的暫存器組。編組的暫存器為處理處理器異常和特權操作提供了快速的上下文切換。
- 三十個32 位元通用暫存器:
- ##存在十五個通用暫存器,它們分別是r0-r12、sp、lr
- sp (r13) 是堆疊指標。 C/C 編譯器始終將 sp 用作堆疊指標
- lr (r14) 用於儲存呼叫子程式時的回傳位址。如果返回位址儲存在堆疊上,則可將lr 用作通用暫存器
- 程式計數器(pc):指令暫存器
應用程式狀態暫存器(APSR):存放算術邏輯單元(ALU) 狀態標記的副本
#目前程式狀態暫存器(CPSR):存放APSR 標記,目前處理器模式,中斷停用標記等
已儲存的程式狀態暫存器(SPSR):當發生異常時,使用SPSR 來儲存CPSR
【擴充閱讀】:函數堆疊訊框(Stack Frame)
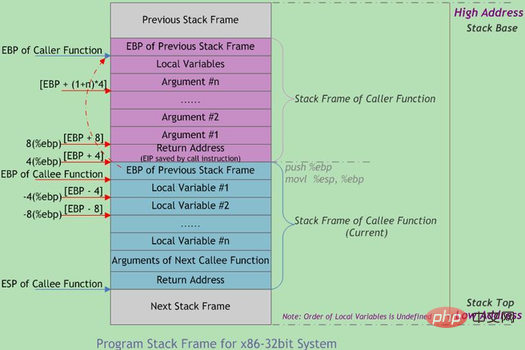
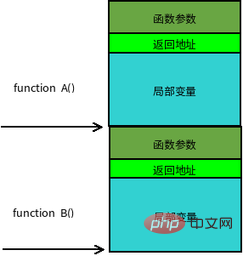
函數呼叫常是巢狀的,在同一時刻,堆疊中會有多個函數的資訊。每個未完成運行的函數佔用一個獨立的連續區域,稱為堆疊幀(Stack Frame)。堆疊幀存放函數參數,局部變數及恢復前一棧幀所需的資料等,函數呼叫時入棧的順序為:
實參N~1 → 主調函數回傳位址→ 主調函數幀基指標EBP → 被調函數局部變數1~N
堆疊幀的邊界由堆疊幀基位址指標EBP 和堆疊指標ESP 界定,EBP 指向目前堆疊幀底部(高位址),在當前棧幀內位置固定;ESP指向目前堆疊幀頂部(低位址),當程式執行時ESP會隨著資料的入棧和出棧而移動。因此函數中對大部分資料的存取都是基於EBP進行。函數呼叫堆疊的典型記憶體佈局如下圖所示:
#然而棧的意義還不只是函數調用,有了它的存在,才能建構出作業系統的多任務模式。我們以 main 函數呼叫為例,main 函數包含一個無限循環體,循環體中先呼叫 A 函數,再呼叫 B 函數。
func B():
return;
func A():
B();
func main():
while (1)
A();試想在單處理器情況下,程式將永遠停留在此 main 函數中。即使有另外一個任務在等待狀態,程式是沒辦法從此 main 函數裡面跳到另一個任務。因為如果是函數呼叫關係,本質上還是屬於 main 函數的任務中,不能算多任務切換。此刻的 main 函數任務本身其實和它的棧綁定在了一起,無論如何巢狀呼叫函數,棧指標都在本棧範圍內移動。
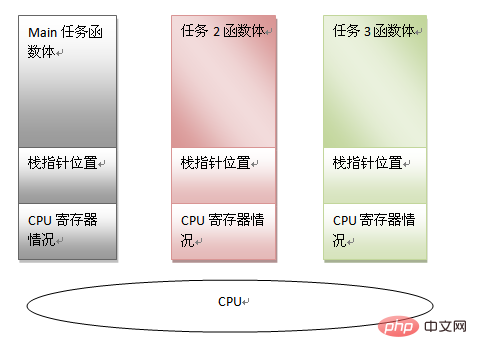
由此可以看出一個任務可以利用以下資訊來表徵:
main 函數體程式碼
main 函數堆疊指標
目前CPU 暫存器資訊
假如我們可以保存以上信息,則完全可以強制讓出CPU 去處理其他任務。只要將來想繼續執行此 main 任務的時候,把上面的資訊恢復回去即可。有了這樣的先決條件,多任務就有了存在的基礎,也可以看出堆疊存在的另一個意義。在多任務模式下,當調度程序認為有必要進行任務切換的話,只需保存任務的資訊(即上面說的三個內容)。恢復另一個任務的狀態,然後跳到上次運行的位置,就可以恢復運作了。
可見每個任務都有自己的堆疊空間,而正是有了獨立的堆疊空間,為了程式碼重用,不同的任務甚至可以混用任務的函數體本身,例如可以一個main函數有兩個任務實例。至此之後的作業系統的框架也形成了,譬如任務在呼叫sleep() 等待的時候,可以主動讓出CPU 給別的任務使用,或者分時操作系統任務在時間片用完是也會被迫的讓出CPU。不論是哪一種方法,只要想辦法切換任務的脈絡空間,切換堆疊即可。
【擴展閱讀】:任務、執行緒、進程三者關係
任務是一個抽象的概念,即指軟體完成的一個活動;而線程則是完成任務所需的動作;進程則指的是完成此動作所需資源的統稱;關於三者的關係,有一個形象的比喻:
任務= 送貨
線程= 開送貨車
系統排程= 決定適合開哪一輛送貨車
進程= 道路加油站外送車修車廠
介紹完棧的工作原理和用途作用後,我們回歸到 Linux 核心上來。核心將堆疊分成四種:
進程堆疊
#執行緒堆疊
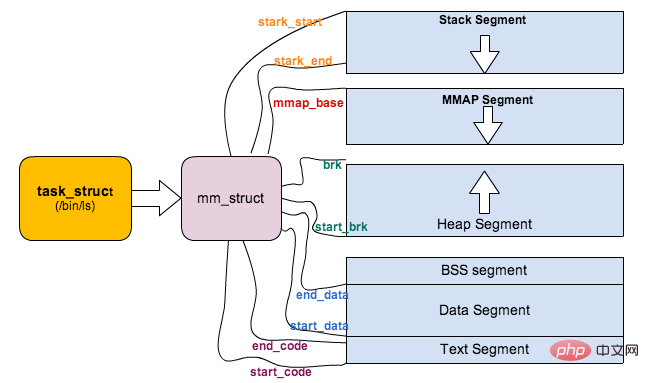
Linux 内核将这 4G 字节的空间分为两部分,将最高的 1G 字节(0xC0000000-0xFFFFFFFF)供内核使用,称为 内核空间。而将较低的3G字节(0x00000000-0xBFFFFFFF)供各个进程使用,称为 用户空间。每个进程可以通过系统调用陷入内核态,因此内核空间是由所有进程共享的。虽然说内核和用户态进程占用了这么大地址空间,但是并不意味它们使用了这么多物理内存,仅表示它可以支配这么大的地址空间。它们是根据需要,将物理内存映射到虚拟地址空间中使用。
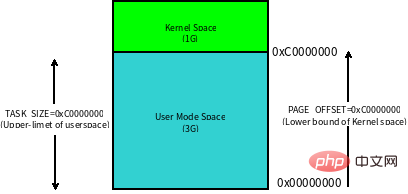
Linux 对进程地址空间有个标准布局,地址空间中由各个不同的内存段组成 (Memory Segment),主要的内存段如下:
程序段 (Text Segment):可执行文件代码的内存映射
数据段 (Data Segment):可执行文件的已初始化全局变量的内存映射
BSS段 (BSS Segment):未初始化的全局变量或者静态变量(用零页初始化)
堆区 (Heap) : 存储动态内存分配,匿名的内存映射
栈区 (Stack) : 进程用户空间栈,由编译器自动分配释放,存放函数的参数值、局部变量的值等
映射段(Memory Mapping Segment):任何内存映射文件

而上面进程虚拟地址空间中的栈区,正指的是我们所说的进程栈。进程栈的初始化大小是由编译器和链接器计算出来的,但是栈的实时大小并不是固定的,Linux 内核会根据入栈情况对栈区进行动态增长(其实也就是添加新的页表)。但是并不是说栈区可以无限增长,它也有最大限制 RLIMIT_STACK (一般为 8M),我们可以通过 ulimit 来查看或更改 RLIMIT_STACK 的值。
【扩展阅读】:如何确认进程栈的大小
我们要知道栈的大小,那必须得知道栈的起始地址和结束地址。栈起始地址 获取很简单,只需要嵌入汇编指令获取栈指针 esp 地址即可。栈结束地址 的获取有点麻烦,我们需要先利用递归函数把栈搞溢出了,然后再 GDB 中把栈溢出的时候把栈指针 esp 打印出来即可。代码如下:
/* file name: stacksize.c */
void *orig_stack_pointer;
void blow_stack() {
blow_stack();
}
int main() {
__asm__("movl %esp, orig_stack_pointer");
blow_stack();
return 0;
}$ g++ -g stacksize.c -o ./stacksize $ gdb ./stacksize (gdb) r Starting program: /home/home/misc-code/setrlimit Program received signal SIGSEGV, Segmentation fault. blow_stack () at setrlimit.c:4 4 blow_stack(); (gdb) print (void *)$esp $1 = (void *) 0xffffffffff7ff000 (gdb) print (void *)orig_stack_pointer $2 = (void *) 0xffffc800 (gdb) print 0xffffc800-0xff7ff000 $3 = 8378368 // Current Process Stack Size is 8M
上面对进程的地址空间有个比较全局的介绍,那我们看下 Linux 内核中是怎么体现上面内存布局的。内核使用内存描述符来表示进程的地址空间,该描述符表示着进程所有地址空间的信息。内存描述符由 mm_struct 结构体表示,下面给出内存描述符结构中各个域的描述,请大家结合前面的 进程内存段布局 图一起看:
struct mm_struct {
struct vm_area_struct *mmap; /* 内存区域链表 */
struct rb_root mm_rb; /* VMA 形成的红黑树 */
...
struct list_head mmlist; /* 所有 mm_struct 形成的链表 */
...
unsigned long total_vm; /* 全部页面数目 */
unsigned long locked_vm; /* 上锁的页面数据 */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long shared_vm; /* 共享页面数目 Shared pages (files) */
unsigned long exec_vm; /* 可执行页面数目 VM_EXEC & ~VM_WRITE */
unsigned long stack_vm; /* 栈区页面数目 VM_GROWSUP/DOWN */
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data; /* 代码段、数据段 起始地址和结束地址 */
unsigned long start_brk, brk, start_stack; /* 栈区 的起始地址,堆区 起始地址和结束地址 */
unsigned long arg_start, arg_end, env_start, env_end; /* 命令行参数 和 环境变量的 起始地址和结束地址 */
...
/* Architecture-specific MM context */
mm_context_t context; /* 体系结构特殊数据 */
/* Must use atomic bitops to access the bits */
unsigned long flags; /* 状态标志位 */
...
/* Coredumping and NUMA and HugePage 相关结构体 */
};
【扩展阅读】:进程栈的动态增长实现
进程在运行的过程中,通过不断向栈区压入数据,当超出栈区容量时,就会耗尽栈所对应的内存区域,这将触发一个 缺页异常 (page fault)。通过异常陷入内核态后,异常会被内核的 expand_stack() 函数处理,进而调用 acct_stack_growth() 来检查是否还有合适的地方用于栈的增长。
如果栈的大小低于 RLIMIT_STACK(通常为8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情,这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会发生 栈溢出(stack overflow),进程将会收到内核发出的 段错误(segmentation fault) 信号。
动态栈增长是唯一一种访问未映射内存区域而被允许的情形,其他任何对未映射内存区域的访问都会触发页错误,从而导致段错误。一些被映射的区域是只读的,因此企图写这些区域也会导致段错误。
从 Linux 内核的角度来说,其实它并没有线程的概念。Linux 把所有线程都当做进程来实现,它将线程和进程不加区分的统一到了 task_struct 中。线程仅仅被视为一个与其他进程共享某些资源的进程,而是否共享地址空间几乎是进程和 Linux 中所谓线程的唯一区别。线程创建的时候,加上了 CLONE_VM 标记,这样 线程的内存描述符 将直接指向 父进程的内存描述符。
if (clone_flags & CLONE_VM) {
/*
* current 是父进程而 tsk 在 fork() 执行期间是共享子进程
*/
atomic_inc(¤t->mm->mm_users);
tsk->mm = current->mm;
}虽然线程的地址空间和进程一样,但是对待其地址空间的 stack 还是有些区别的。对于 Linux 进程或者说主线程,其 stack 是在 fork 的时候生成的,实际上就是复制了父亲的 stack 空间地址,然后写时拷贝 (cow) 以及动态增长。然而对于主线程生成的子线程而言,其 stack 将不再是这样的了,而是事先固定下来的,使用 mmap 系统调用,它不带有 VM_STACK_FLAGS 标记。这个可以从 glibc 的 nptl/allocatestack.c 中的 allocate_stack() 函数中看到:
mem = mmap (NULL, size, prot, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0);
由于线程的 mm->start_stack 栈地址和所属进程相同,所以线程栈的起始地址并没有存放在 task_struct 中,应该是使用 pthread_attr_t 中的 stackaddr 来初始化 task_struct->thread->sp(sp 指向 struct pt_regs 对象,该结构体用于保存用户进程或者线程的寄存器现场)。这些都不重要,重要的是,线程栈不能动态增长,一旦用尽就没了,这是和生成进程的 fork 不同的地方。由于线程栈是从进程的地址空间中 map 出来的一块内存区域,原则上是线程私有的。但是同一个进程的所有线程生成的时候浅拷贝生成者的 task_struct 的很多字段,其中包括所有的 vma,如果愿意,其它线程也还是可以访问到的,于是一定要注意。
在每一个进程的生命周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先进程用户空间中的栈,而是一个单独内核空间的栈,这个称作进程内核栈。进程内核栈在进程创建的时候,通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};thread_union 进程内核栈 和 task_struct 进程描述符有着紧密的联系。由于内核经常要访问 task_struct,高效获取当前进程的描述符是一件非常重要的事情。因此内核将进程内核栈的头部一段空间,用于存放 thread_info 结构体,而此结构体中则记录了对应进程的描述符,两者关系如下图(对应内核函数为 dup_task_struct()):
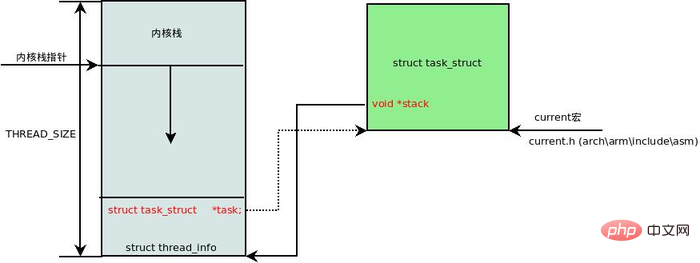
有了上述关联结构后,内核可以先获取到栈顶指针 esp,然后通过 esp 来获取 thread_info。这里有一个小技巧,直接将 esp 的地址与上 ~(THREAD_SIZE - 1) 后即可直接获得 thread_info 的地址。由于 thread_union 结构体是从 thread_info_cache 的 Slab 缓存池中申请出来的,而 thread_info_cache 在 kmem_cache_create 创建的时候,保证了地址是 THREAD_SIZE 对齐的。因此只需要对栈指针进行 THREAD_SIZE 对齐,即可获得 thread_union 的地址,也就获得了 thread_union 的地址。成功获取到 thread_info 后,直接取出它的 task 成员就成功得到了 task_struct。其实上面这段描述,也就是 current 宏的实现方法:
register unsigned long current_stack_pointer asm ("sp");
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
}
#define get_current() (current_thread_info()->task)
#define current get_current()进程陷入内核态的时候,需要内核栈来支持内核函数调用。中断也是如此,当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。由于系统中断的时候,系统当然是处于内核态的,所以中断栈是可以和内核栈共享的。但是具体是否共享,这和具体处理架构密切相关。
X86 上中断栈就是独立于内核栈的;独立的中断栈所在内存空间的分配发生在 arch/x86/kernel/irq_32.c 的 irq_ctx_init() 函数中 (如果是多处理器系统,那么每个处理器都会有一个独立的中断栈),函数使用 __alloc_pages 在低端内存区分配 2个物理页面,也就是8KB大小的空间。有趣的是,这个函数还会为 softirq 分配一个同样大小的独立堆栈。如此说来,softirq 将不会在 hardirq 的中断栈上执行,而是在自己的上下文中执行。

而 ARM 上中断栈和内核栈则是共享的;中断栈和内核栈共享有一个负面因素,如果中断发生嵌套,可能会造成栈溢出,从而可能会破坏到内核栈的一些重要数据,所以栈空间有时候难免会捉襟见肘。
推薦學習:Linux影片教學
以上是linux棧是什麼的詳細內容。更多資訊請關注PHP中文網其他相關文章!