
這篇文章為大家帶來了關於Redis的相關知識,其中主要整理了叢集與擴充的相關問題,實現高可用通常的做法是將資料庫複製多個副本以部署在不同的伺服器上,其中一台掛了也可以繼續提供服務,實現高可用有三種部署模式:主從模式,哨兵模式,集群模式,下面一起來看一下,希望對大家有幫助。

推薦學習:Redis影片教學
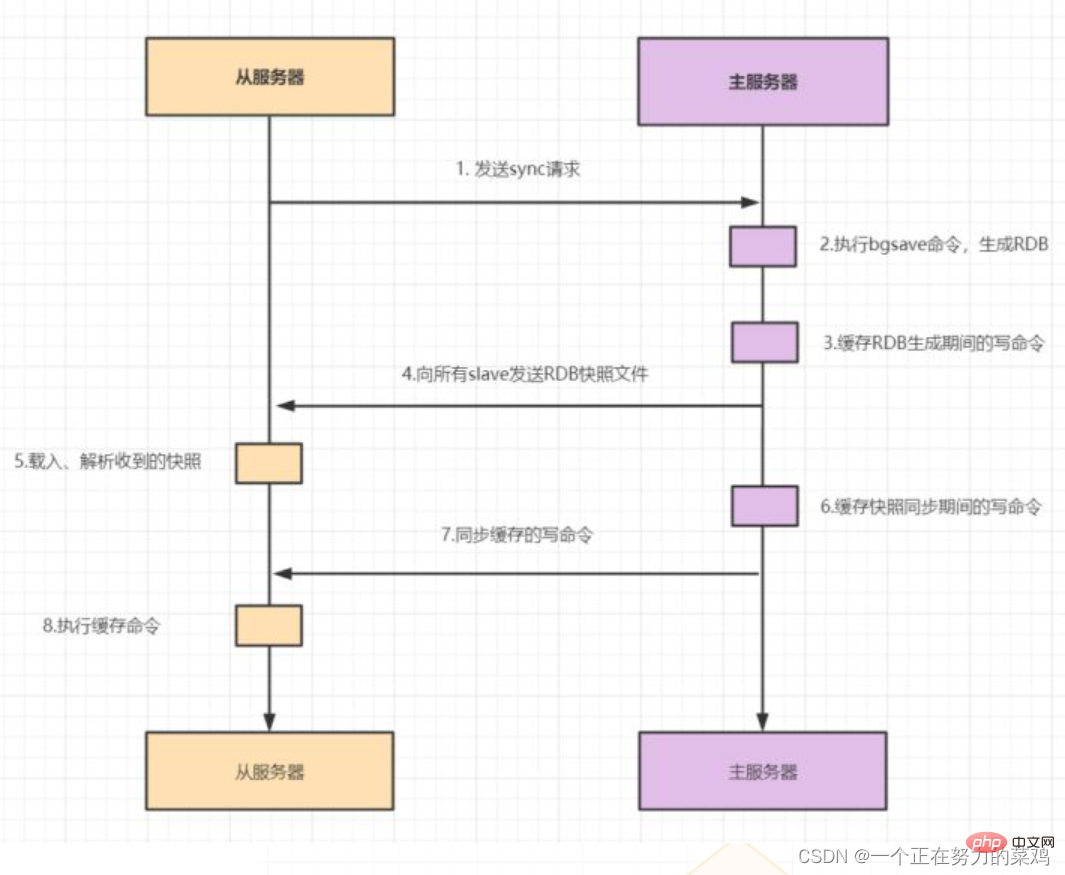
#
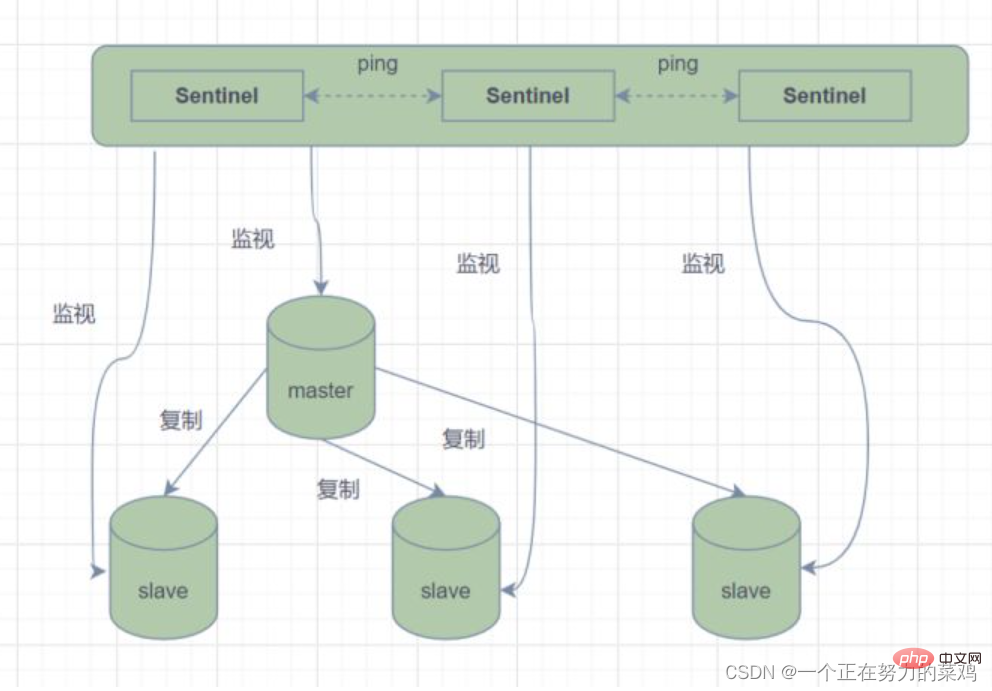
1.发送命令,等待Redis服务器(包括主服务器和从服务器)返回监控其运行状态 2.哨兵监测到主节点宕机会自动将从节点切换成主节点,然后通过发布订阅模式通知其他的从节点修改配置文件,让它们切换主机 3.哨兵之间还会相互监控,从而达到高可用
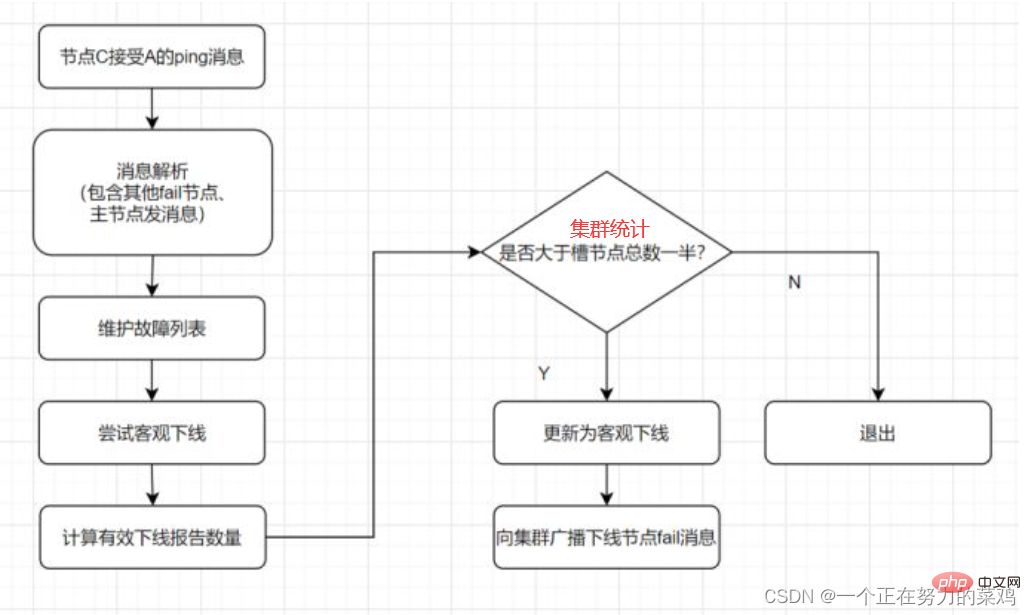
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线 当后面的哨兵也检测到主服务器不可用并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作 切换成功后通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线 这样对于客户端而言,一切都是透明的
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他Sentinel实例发送一个PING命令 如果实例距离最后一次有效回复PING命令的时间超过down-after-milliseconds选项所指定的值,则这个实例会被Sentinel标记为主观下线 如果一个Master被标记为主观下线,则正在监视这个Master的所有Sentinel要以每秒一次的频率确认Master的确进入了主观下线状态 当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态,则Master会被标记为客观下线 一般情况下,每个Sentinel会以每10秒一次的频率向它已知的所有Master,Slave发送INFO命令 当Master被Sentinel标记为客观下线时,Sentinel向下线的Master的所有Slave发送INFO命令的频率会从10秒一次改为每秒一次 若没有足够数量的Sentinel同意Master已经下线,Master的客观下线状态就会被移除;若Master重新向Sentinel的PING命令返回有效回复,Master 的主观下线状态就会被移除
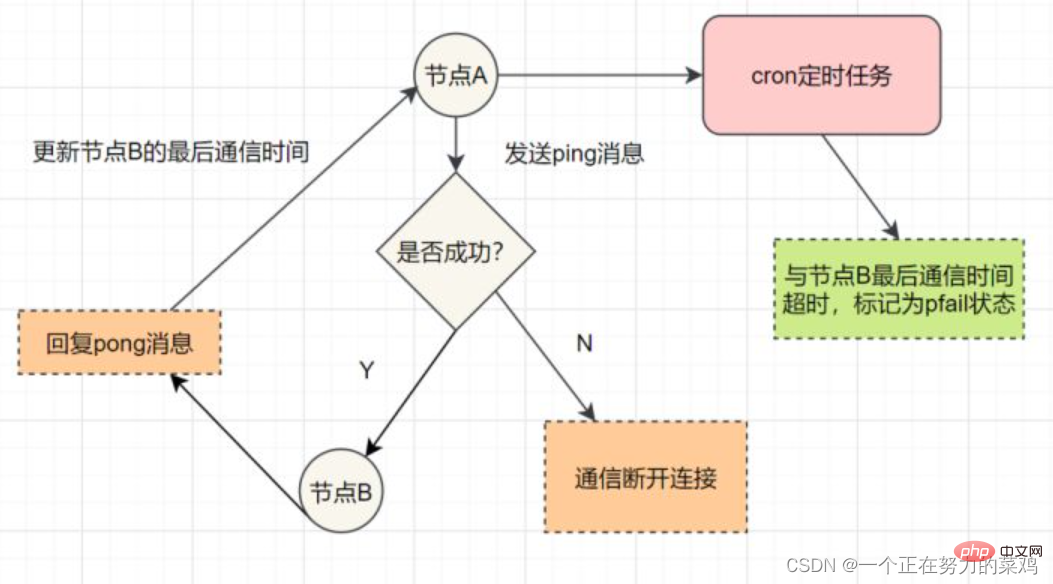
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息 meet消息:通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换 pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信;pong消息内部封装了自身状态数据,节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新 fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态
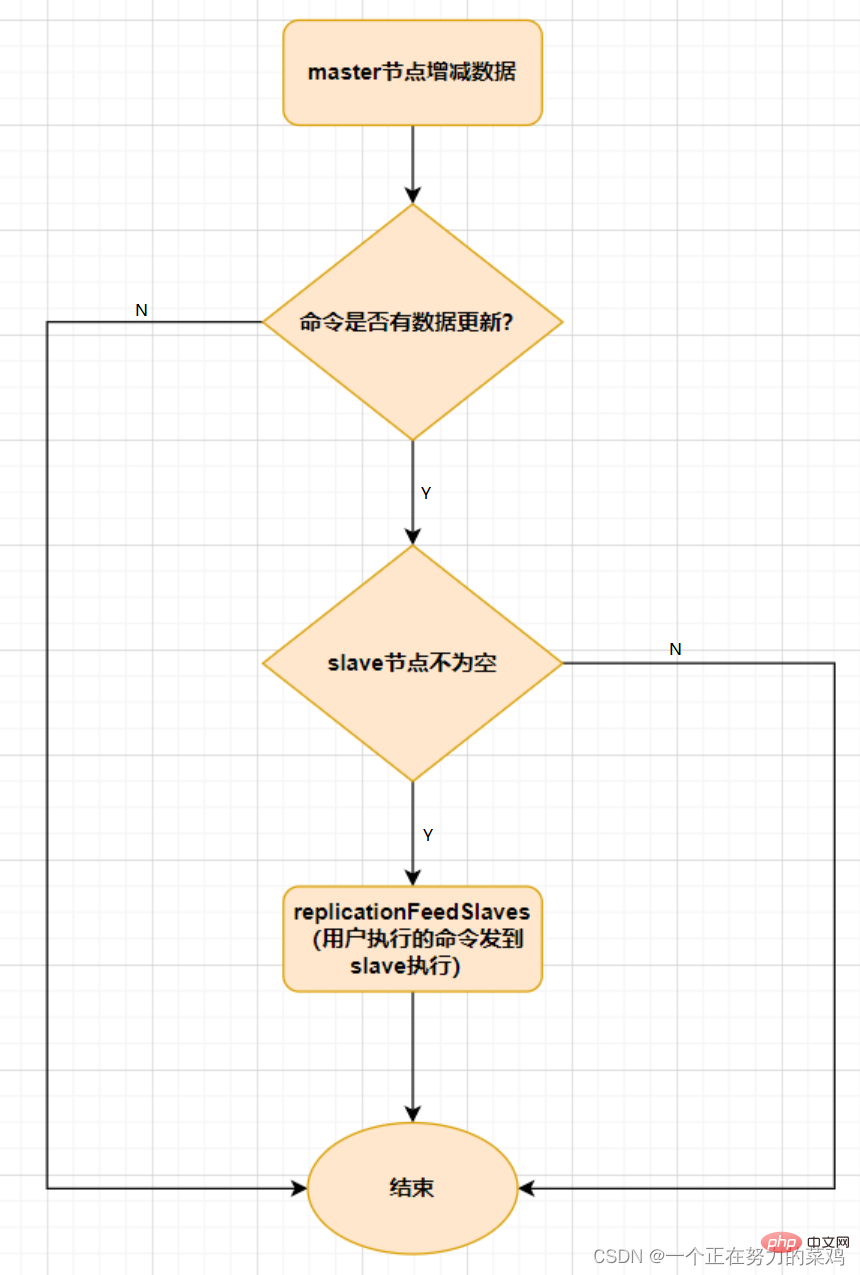
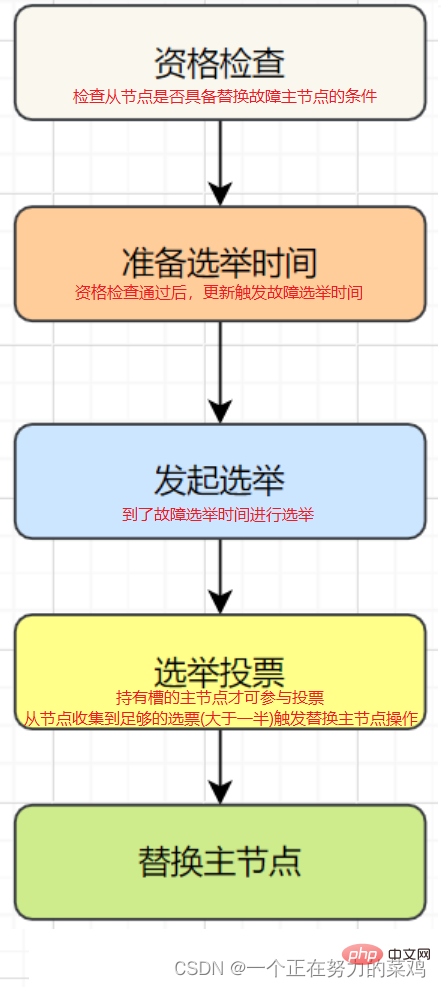
既然是分布式存储,Cluster集群使用的分布式算法是一致性Hash嘛?并不是,而是Hash Slot插槽算法 插槽算法把整个数据库被分为16384个slot(槽),每个进入Redis的键值对根据key进行散列,分配到这16384插槽中的一个 使用的哈希映射也比较简单,用CRC16算法计算出一个16位的值,再对16384取模,数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点都可以处理这16384个槽 集群中的每个节点负责一部分的hash槽,比如当前集群有A、B、C个节点,每个节点上的哈希槽数 =16384/3,那么就有: 节点A负责0~5460号哈希槽 节点B负责5461~10922号哈希槽 节点C负责10923~16383号哈希槽Redis Cluster集群中,需要确保16384个槽对应的node都正常工作,如果某个node出现故障,它负责的slot也会失效,整个集群将不能工作 为了保证高可用,Cluster集群引入了主从复制,一个主节点对应一个或者多个从节点,当其它主节点ping一个主节点A时,如果半数以上的主节点与 A通信超时,那么认为主节点A宕机,如果主节点宕机时,就会启用从节点Redis的每一个节点上都有两个玩意,一个是插槽slot(0~16383),另外一个是cluster,可以理解为一个集群管理的插件,当我们存取的key到达时,Redis会根据Hash Slot插槽算法取到编号在0~16383之间的哈希槽,通过这个值去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
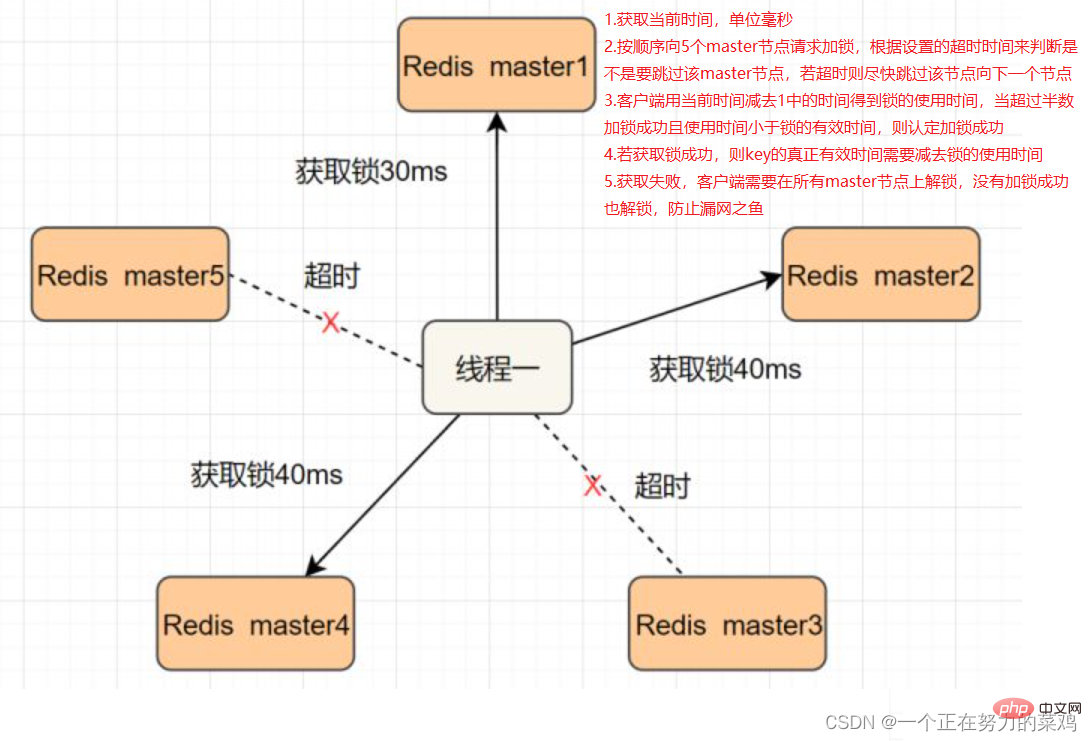
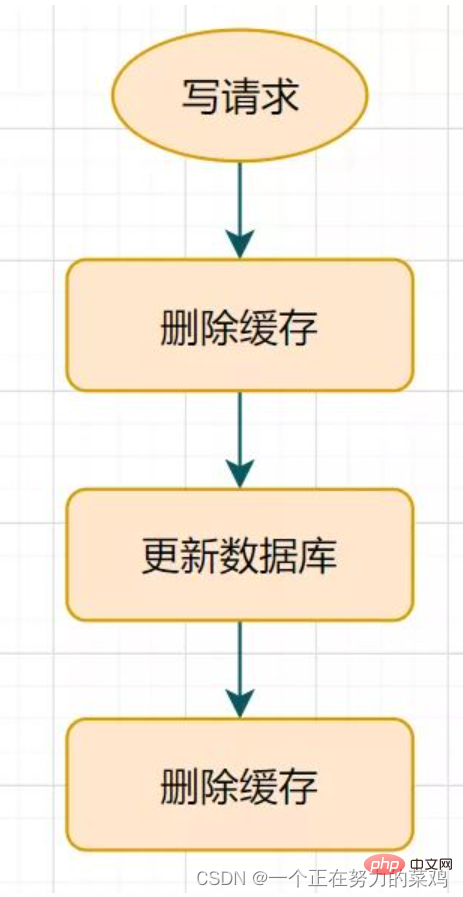
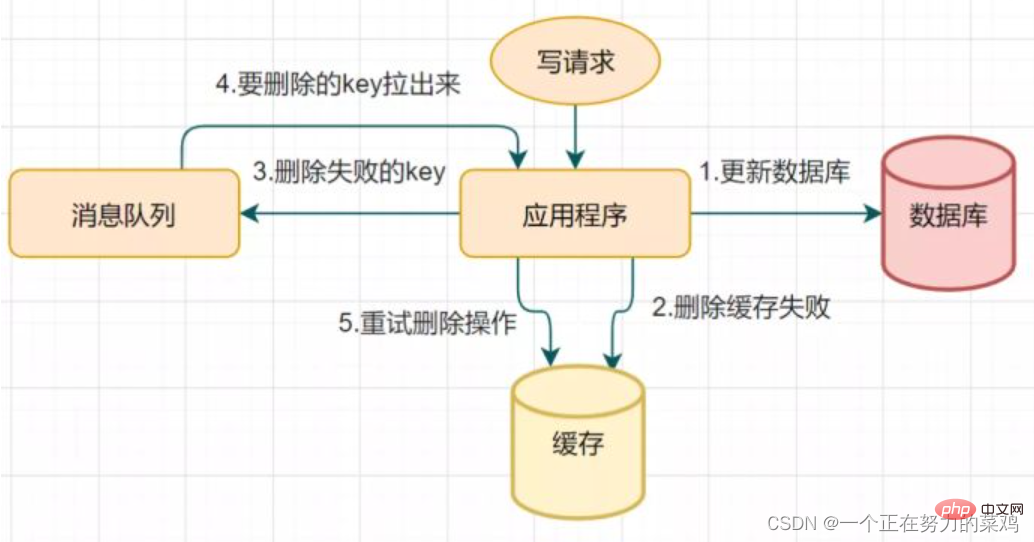
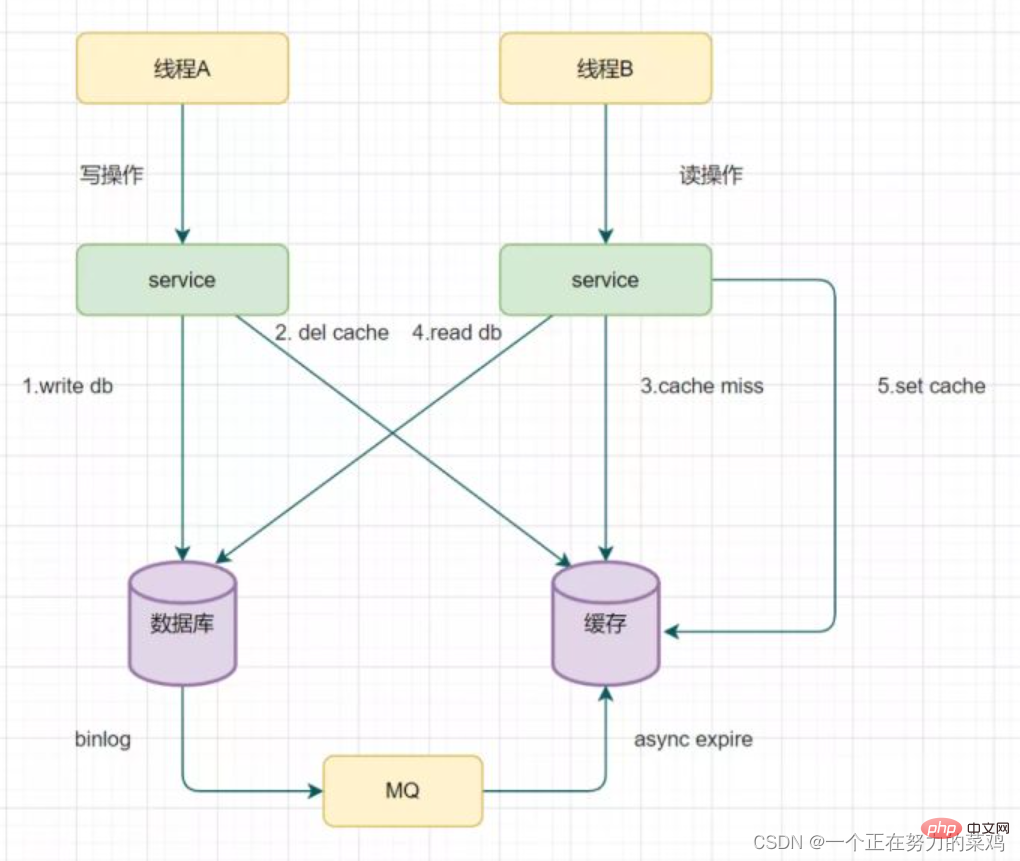
推薦學習:Redis影片教學
以上是圖文詳解Redis集群與擴展的詳細內容。更多資訊請關注PHP中文網其他相關文章!























