
本篇文章為大家帶來了關於Python的相關知識,其中主要整理了解析參數的三種方法相關問題,第一個選項是使用argparse,它是一個流行的Python模組,專門用於命令列解析;另一種方法是讀取JSON 文件,我們可以在其中放置所有超參數;第三種也是鮮為人知的方法是使用YAML 文件,下面一起來看一下,希望對大家有幫助。

【相關推薦:Python3影片教學 】
今天我們分享的主要目的就是透過在Python 中使用指令列和設定檔來提高程式碼的效率
Let's go!
我們以機器學習當中的調參過程來進行實踐,有三種方式可供選擇。第一個選項是使用argparse,它是一個流行的Python 模組,專門用於命令列解析;另一種方法是讀取JSON 文件,我們可以在其中放置所有超參數;第三種也是鮮為人知的方法是使用YAML 檔案!好奇嗎,讓我們開始吧!
在下面的程式碼中,我將使用 Visual Studio Code,這是一個非常有效率的整合 Python 開發環境。這個工具的美妙之處在於它透過安裝擴充功能支援每種程式語言,整合終端並允許同時處理大量Python 腳本和Jupyter 筆記本
資料集,使用的是Kaggle 上的共用自行車資料集
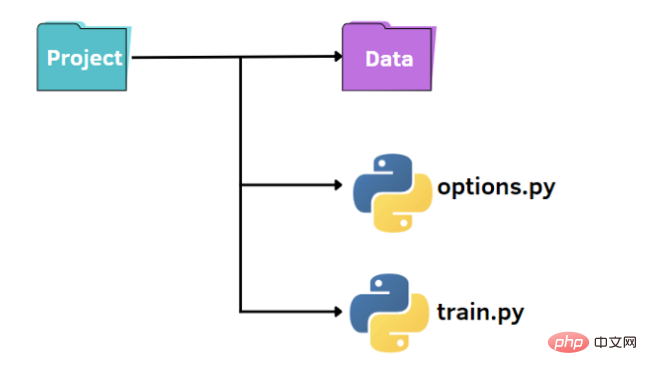
就像上圖所示,我們有一個標準的結構來組織我們的小專案:
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from options import train_options
df = pd.read_csv('data\hour.csv')
print(df.head())
opt = train_options()
X=df.drop(['instant','dteday','atemp','casual','registered','cnt'],axis=1).values
y =df['cnt'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
if opt.normalize == True:
scaler = StandardScaler()
X = scaler.fit_transform(X)
rf = RandomForestRegressor(n_estimators=opt.n_estimators,max_features=opt.max_features,max_depth=opt.max_depth)
model = rf.fit(X_train,y_train)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_pred, y_test))
mae = mean_absolute_error(y_pred, y_test)
print("rmse: ",rmse)
print("mae: ",mae)import argparse
def train_options():
parser = argparse.ArgumentParser()
parser.add_argument("--normalize", default=True, type=bool, help='maximum depth')
parser.add_argument("--n_estimators", default=100, type=int, help='number of estimators')
parser.add_argument("--max_features", default=6, type=int, help='maximum of features',)
parser.add_argument("--max_depth", default=5, type=int,help='maximum depth')
opt = parser.parse_args()
return optpython train.py
 要更改超參數的預設值,有兩種方法。第一個選項是在 options.py 檔案中設定不同的預設值。另一個選擇是從命令列傳遞超參數值:
要更改超參數的預設值,有兩種方法。第一個選項是在 options.py 檔案中設定不同的預設值。另一個選擇是從命令列傳遞超參數值:
python train.py --n_estimators 200
python train.py --n_estimators 200 --max_depth 7
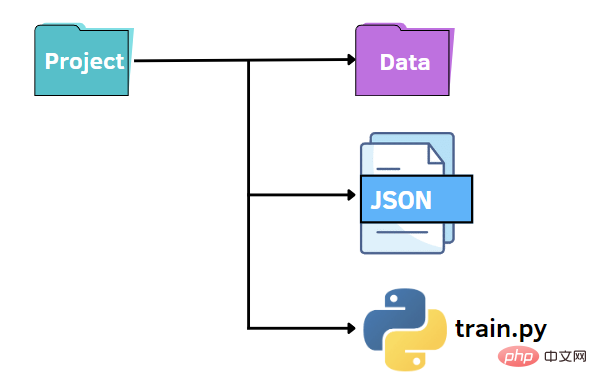 和前面一樣,我們可以保持類似的檔案結構。在這種情況下,我們將 options.py 檔案替換為 JSON 檔案。換句話說,我們想在 JSON 檔案中指定超參數的值並將它們傳遞給 train.py 檔案。與 argparse 程式庫相比,JSON 檔案可以是一種快速且直覺的替代方案,它利用鍵值對來儲存資料。下面我們建立一個 options.json 文件,其中包含我們稍後需要傳遞給其他程式碼的資料。
和前面一樣,我們可以保持類似的檔案結構。在這種情況下,我們將 options.py 檔案替換為 JSON 檔案。換句話說,我們想在 JSON 檔案中指定超參數的值並將它們傳遞給 train.py 檔案。與 argparse 程式庫相比,JSON 檔案可以是一種快速且直覺的替代方案,它利用鍵值對來儲存資料。下面我們建立一個 options.json 文件,其中包含我們稍後需要傳遞給其他程式碼的資料。
{
"normalize":true,
"n_estimators":100,
"max_features":6,
"max_depth":5
}f = open("options.json", "rb")
parameters = json.load(f)if parameters["normalize"] == True: scaler = StandardScaler() X = scaler.fit_transform(X) rf=RandomForestRegressor(n_estimators=parameters["n_estimators"],max_features=parameters["max_features"],max_depth=parameters["max_depth"],random_state=42) model = rf.fit(X_train,y_train) y_pred = model.predict(X_test)
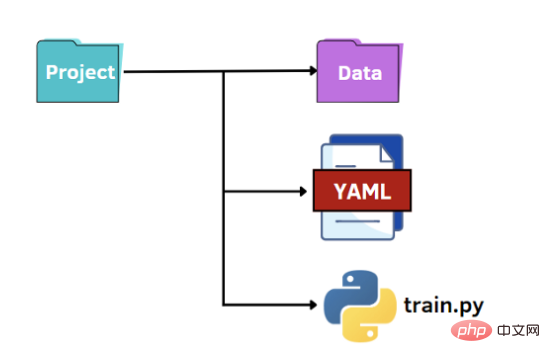 最後一種選擇是利用YAML 的潛力。與 JSON 檔案一樣,我們將 Python 程式碼中的 YAML 檔案作為字典讀取,以存取超參數的值。 YAML 是一種人類可讀的資料表示語言,其中層次結構使用雙空格字元表示,而不是像 JSON 檔案中的括號。下面我們展示options.yaml 檔案將包含的內容:
最後一種選擇是利用YAML 的潛力。與 JSON 檔案一樣,我們將 Python 程式碼中的 YAML 檔案作為字典讀取,以存取超參數的值。 YAML 是一種人類可讀的資料表示語言,其中層次結構使用雙空格字元表示,而不是像 JSON 檔案中的括號。下面我們展示options.yaml 檔案將包含的內容:
normalize: True n_estimators: 100 max_features: 6 max_depth: 5
import yaml
f = open('options.yaml','rb')
parameters = yaml.load(f, Loader=yaml.FullLoader)設定檔的編譯速度非常快,而 argparse 則需要為我們要新增的每個參數編寫一行程式碼。
所以我們應該根據自己的不同情況來選擇最為合適的方式
例如,如果我們需要為參數添加註釋,JSON 是不合適的,因為它不允許註釋,而YAML和argparse 可能非常適合。
【相關推薦:Python3影片教學 】
以上是Python解析參數的三種方法詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!























