

怎樣解決mysql深分頁問題

本篇文章為大家帶來了關於mysql的相關知識,主要介紹了優雅地解決mysql深分頁問題,本文將會討論當mysql表大數據量的情況,如何優化深分頁問題,並附上最近的優化慢sql問題的案例偽代碼,希望對大家有幫助。

推薦學習:mysql影片教學
#日常需求開發過程中,相信大家對於limit一定不會陌生,但使用limit時,當偏移(offset)非常大時,會發現查詢效率越來越慢。一開始limit 2000時,可能200ms,就能查詢出需要的到數據,但是當limit 4000 offset 100000時,會發現它的查詢效率已經需要1S左右,那要是更大的時候呢,只會越來越慢。
概括
本文將會討論當mysql表大數據量的情況,如何優化深分頁問題,並附上最近的優化慢sql問題的案例偽代碼。
1、limit深分頁問題描述
先看看表格結構(隨便舉了個例子,表結構不全,無用字段就不進行展示了)
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
假設我們要查詢的深分頁SQL長這樣
select * from p2p_detail_record ppdr where ppdr .start_time_stamp >1656666798000 limit 0,2000

查詢效率是94ms,是不是很快?那如果我們limit 100000,2000呢,查詢效率是1.5S,已經非常慢,那如果更多呢?

2、sql慢原因分析
讓我們來看看這個sql的執行計畫

也走到了索引,那為什麼還是慢呢?我們先來回顧一下mysql 的相關知識點。
叢集索引和非叢集索引
叢集索引: 葉子節點儲存的是整行的資料。
非叢集索引: 葉子節點儲存的是整行的資料對應的主鍵值。
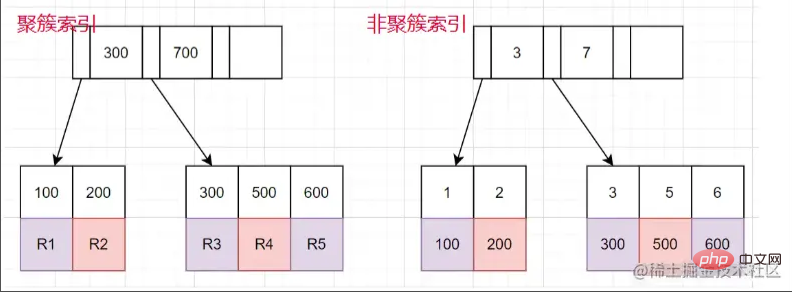
使用非叢集索引查詢的流程
- 透過非叢集索引樹,找到對應的葉子節點,取得到主鍵的值。
- 再透過取到主鍵的值,回到叢集索引樹,找出對應的整行資料。 (整個過程稱為回表)
回到這條sql為什麼慢的問題上,原因如下
1、limit語句會先掃描offset n行,然後丟棄掉前offset行,回傳後n行資料。也就是說limit 100000,10,就會掃描100010行,而limit 0,10,只掃描10行。這裡要回表100010次,大量的時間都在回表這個上面。
方案核心思路: 能不能事先知道要從哪個主鍵ID開始,減少回表的次數
常見解決方案
#透過子查詢優化
select * from p2p_detail_record ppdr where id >= (select id from p2p_detail_record ppdr2 where ppdr2 .start_time_stamp >1656666798000 limit 100000,1) limit 2000
相同的查詢結果,也是10W條開始的第2000條,查詢效率為200ms,是不是快了不少。
標籤記錄法
標籤記錄法: 其實標記一下上次查詢到哪一條了,下次再來查的時候,從該條開始往下掃描。 類似書籤的作用
select * from p2p_detail_record ppdr where ppdr.id > 'bb9d67ee6eac4cab9909bad7c98f54d4' order by id limit 2000 备注:bb9d67ee6eac4cab9909bad7c98f54d4是上次查询结果的最后一条ID
使用標籤記錄法,效能都會不錯的,因為命中了id索引。但是這種方式有幾個缺點。
- 1、只能連續頁查詢,不能跨頁查詢。
- 2、需要一種類似連續自增的欄位(可以使用orber by id的方式)。
方案比較
- 使用透過子查詢最佳化的方式
##優點:可跨頁查詢,想查哪一頁的資料就查哪一頁的資料。
缺點: 效率不如標籤記錄法。 原因: 例如需要查10W條數據後,第1000條,也需要先查詢出非聚簇索引對應的10W1000條數據,在取第10W開始的ID,進行查詢。
- 使用
- 標籤記錄法 的方式
#優點: 查詢效率很穩定,而且非常快速。
缺點:#
- 不跨页查询,
- 需要一种类似连续自增的字段
关于第二点的说明: 该点一般都好解决,可使用任意不重复的字段进行排序即可。若使用可能重复的字段进行排序的字段,由于mysql对于相同值的字段排序是无序,导致如果正好在分页时,上下页中可能存在相同的数据。
实战案例
需求: 需要查询查询某一时间段的数据量,假设有几十万的数据量需要查询出来,进行某些操作。
需求分析 1、分批查询(分页查询),设计深分页问题,导致效率较慢。
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
伪代码实现:
//最小ID
String lastId = null;
//一页的条数
Integer pageSize = 2000;
List<P2pRecordVo> list ;
do{
list = listP2pRecordByPage(lastId,pageSize); //标签记录法,记录上次查询过的Id
lastId = list.get(list.size()-1).getId(); //获取上一次查询数据最后的ID,用于记录
//对数据的操作逻辑
XXXXX();
}while(isNotEmpty(list));
<select id ="listP2pRecordByPage">
select *
from p2p_detail_record ppdr where 1=1
<if test = "lastId != null">
and ppdr.id > #{lastId}
</if>
order by id asc
limit #{pageSize}
</select>这里有个小优化点: 可能有的人会先对所有数据排序一遍,拿到最小ID,但是这样对所有数据排序,然后去min(id),耗时也蛮长的,其实第一次查询,可不带lastId进行查询,查询结果也是一样。速度更快。
总结
1、当业务需要从表中查出大数据量时,而又项目架构没上ES时,可考虑使用标签记录法的方式,对查询效率进行优化。
2、从需求上也应该尽可能避免,在大数据量的情况下,分页查询最后一页的功能。或者限制成只能一页一页往后划的场景。
推荐学习:mysql视频教程
以上是怎樣解決mysql深分頁問題的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 MySQL的角色:Web應用程序中的數據庫
Apr 17, 2025 am 12:23 AM
MySQL的角色:Web應用程序中的數據庫
Apr 17, 2025 am 12:23 AM
MySQL在Web應用中的主要作用是存儲和管理數據。 1.MySQL高效處理用戶信息、產品目錄和交易記錄等數據。 2.通過SQL查詢,開發者能從數據庫提取信息生成動態內容。 3.MySQL基於客戶端-服務器模型工作,確保查詢速度可接受。
 laravel入門實例
Apr 18, 2025 pm 12:45 PM
laravel入門實例
Apr 18, 2025 pm 12:45 PM
Laravel 是一款 PHP 框架,用於輕鬆構建 Web 應用程序。它提供一系列強大的功能,包括:安裝: 使用 Composer 全局安裝 Laravel CLI,並在項目目錄中創建應用程序。路由: 在 routes/web.php 中定義 URL 和處理函數之間的關係。視圖: 在 resources/views 中創建視圖以呈現應用程序的界面。數據庫集成: 提供與 MySQL 等數據庫的開箱即用集成,並使用遷移來創建和修改表。模型和控制器: 模型表示數據庫實體,控制器處理 HTTP 請求。
 docker怎麼啟動mysql
Apr 15, 2025 pm 12:09 PM
docker怎麼啟動mysql
Apr 15, 2025 pm 12:09 PM
在 Docker 中啟動 MySQL 的過程包含以下步驟:拉取 MySQL 鏡像創建並啟動容器,設置根用戶密碼並映射端口驗證連接創建數據庫和用戶授予對數據庫的所有權限
 解決數據庫連接問題:使用minii/db庫的實際案例
Apr 18, 2025 am 07:09 AM
解決數據庫連接問題:使用minii/db庫的實際案例
Apr 18, 2025 am 07:09 AM
在開發一個小型應用時,我遇到了一個棘手的問題:需要快速集成一個輕量級的數據庫操作庫。嘗試了多個庫後,我發現它們要么功能過多,要么兼容性不佳。最終,我找到了minii/db,這是一個基於Yii2的簡化版本,完美地解決了我的問題。
 centos7如何安裝mysql
Apr 14, 2025 pm 08:30 PM
centos7如何安裝mysql
Apr 14, 2025 pm 08:30 PM
優雅安裝 MySQL 的關鍵在於添加 MySQL 官方倉庫。具體步驟如下:下載 MySQL 官方 GPG 密鑰,防止釣魚攻擊。添加 MySQL 倉庫文件:rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm更新 yum 倉庫緩存:yum update安裝 MySQL:yum install mysql-server啟動 MySQL 服務:systemctl start mysqld設置開機自啟動
 centos安裝mysql
Apr 14, 2025 pm 08:09 PM
centos安裝mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安裝 MySQL 涉及以下步驟:添加合適的 MySQL yum 源。執行 yum install mysql-server 命令以安裝 MySQL 服務器。使用 mysql_secure_installation 命令進行安全設置,例如設置 root 用戶密碼。根據需要自定義 MySQL 配置文件。調整 MySQL 參數和優化數據庫以提升性能。
 laravel框架安裝方法
Apr 18, 2025 pm 12:54 PM
laravel框架安裝方法
Apr 18, 2025 pm 12:54 PM
文章摘要:本文提供了詳細分步說明,指導讀者如何輕鬆安裝 Laravel 框架。 Laravel 是一個功能強大的 PHP 框架,它 упростил 和加快了 web 應用程序的開發過程。本教程涵蓋了從系統要求到配置數據庫和設置路由等各個方面的安裝過程。通過遵循這些步驟,讀者可以快速高效地為他們的 Laravel 項目打下堅實的基礎。
 MySQL和PhpMyAdmin:核心功能和功能
Apr 22, 2025 am 12:12 AM
MySQL和PhpMyAdmin:核心功能和功能
Apr 22, 2025 am 12:12 AM
MySQL和phpMyAdmin是強大的數據庫管理工具。 1)MySQL用於創建數據庫和表、執行DML和SQL查詢。 2)phpMyAdmin提供直觀界面進行數據庫管理、表結構管理、數據操作和用戶權限管理。
