

詳解怎麼使用Golang爬取必應壁紙


做爬蟲不用說,就是用python就好,一個requests包走天下。但是呢,聽說golang內建的http包非常牛逼,咱就是說不得整點活,也剛好學習學習新東西,複習下http協議的請求和回應相關的知識點。話不多說,咱直接開整
這篇文章爬下必應壁紙先小試牛刀。狗頭保命狗頭保命狗頭保命
#爬蟲流程概述
graph TD 请求数据 --> 解析数据 --> 数据入库
上圖的流程圖大家可以看到,其實爬蟲並不麻煩,整個流程就只有三步而已。接下來具體聊聊每一步需要做什麼
請求資料:在這裡我們需要使用golang中的內建套件http套件向目標位址發起請求,這一步就完成了
解析資料:這裡我們需要對請求到的資料進行解析,因為不是整個請求到的資料我們都需要,我們只需要某些具體的關鍵的資料而已。這一步也叫資料清洗
資料入庫:不難理解,這就是將解析好的資料進行入庫操作
實戰分析
先到必應壁紙官網上觀察,做爬蟲的話是需要對資料特別敏感的。這是首頁訊息,整個頁面是非常簡潔的
接下來,需要調出瀏覽器的開發者工具(這個大家應該都非常熟悉吧,不熟悉的話很難跟下去的喔)。直接按下F12或右鍵點擊檢查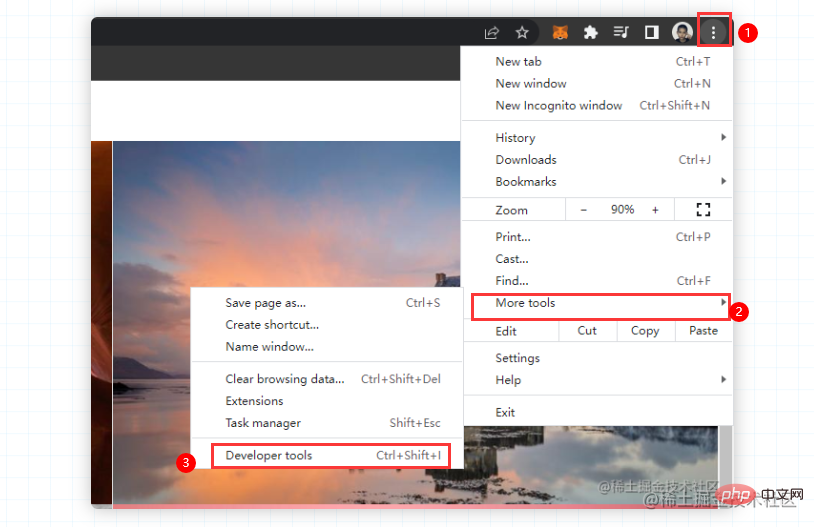
 但是呢?在必應桌布上,右鍵不能呼叫控制台,只能手動調出了。大家不用擔心,照第一張圖操作就好。如果有同學的chrome是中文的,也是一樣的操作,選擇更多工具,選擇開發者工具即可
但是呢?在必應桌布上,右鍵不能呼叫控制台,只能手動調出了。大家不用擔心,照第一張圖操作就好。如果有同學的chrome是中文的,也是一樣的操作,選擇更多工具,選擇開發者工具即可
不出意外呢,大家一定看到的是這樣的頁面
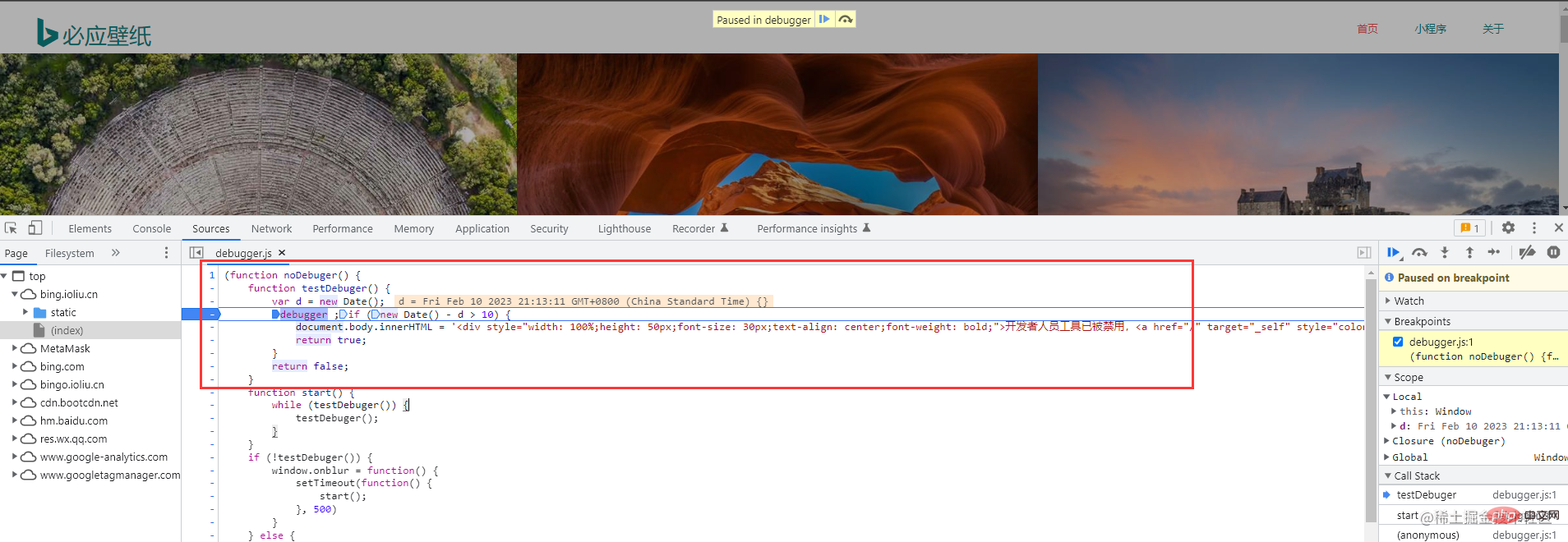 這個沒關係的,只是必應壁紙網站的一些反爬錯誤而已。 (我很久之前爬的時候還沒有這個反爬錯誤)這個是不影響我們操作的
這個沒關係的,只是必應壁紙網站的一些反爬錯誤而已。 (我很久之前爬的時候還沒有這個反爬錯誤)這個是不影響我們操作的
接下來選擇這個工具,幫助我們快速定位到我們想要的元素上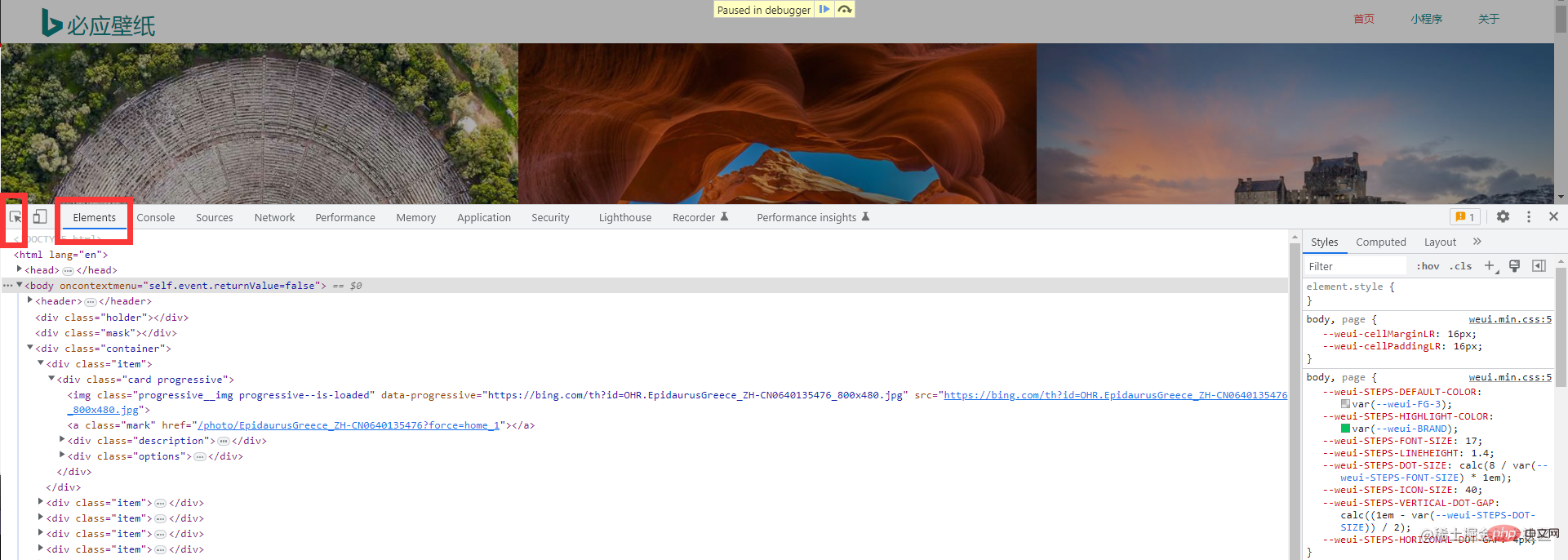 然後我們就能找到我們所需的圖片資訊
然後我們就能找到我們所需的圖片資訊
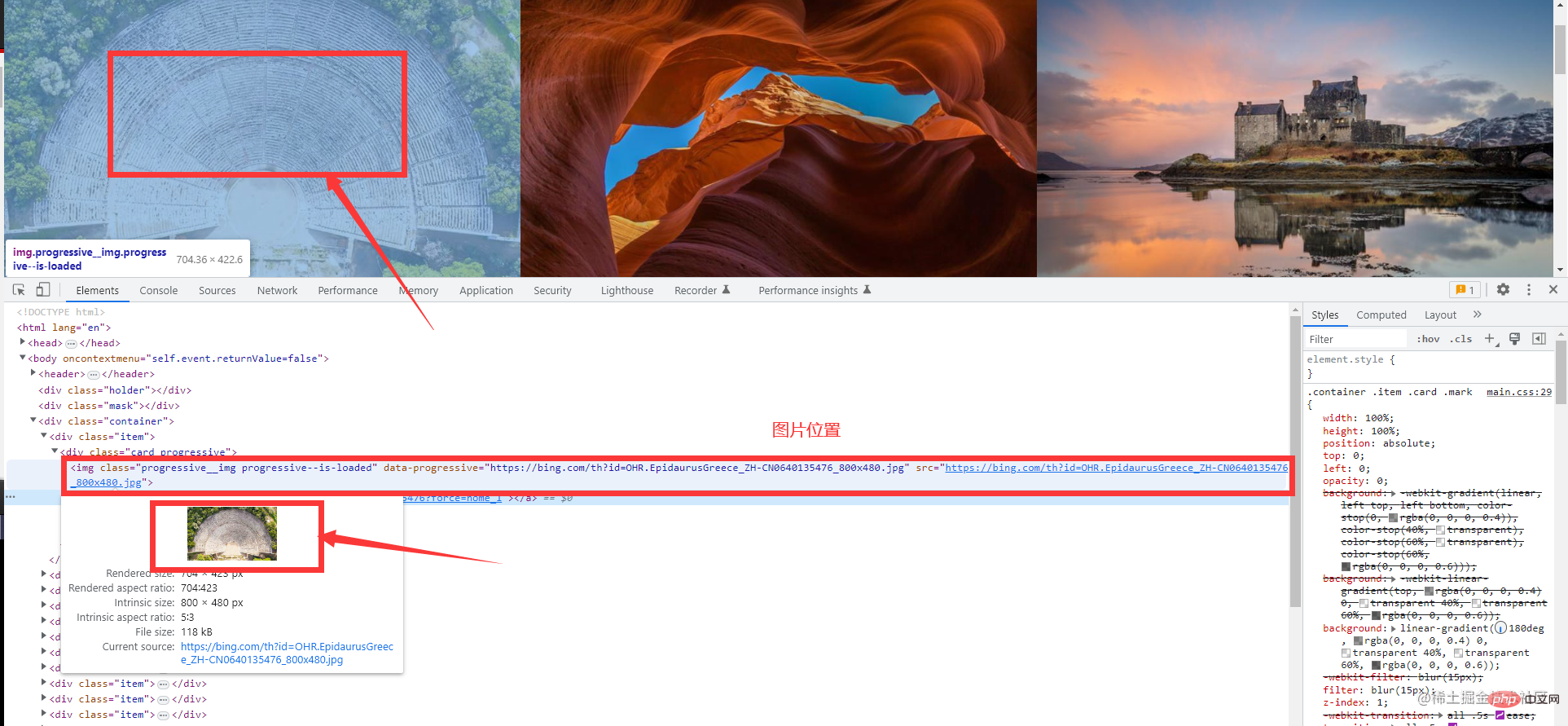
程式碼實戰
下面是爬取一頁的資料
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"io"
"io/ioutil"
"log"
"net/http"
"os"
"time"
)
func Run(method, url string, body io.Reader, client *http.Client) {
req, err := http.NewRequest(method, url, body)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
if resp.StatusCode != http.StatusOK {
log.Printf("请求失败,状态码:%d", resp.StatusCode)
return
}
defer resp.Body.Close() // 关闭响应对象中的body
query, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Println("生成goQuery对象失败")
return
}
query.Find(".container .item").Each(func(i int, s *goquery.Selection) {
imgUrl, _ := s.Find("a.ctrl.download").Attr("href")
imgName := s.Find(".description>h3").Text()
fmt.Println(imgUrl)
fmt.Println(imgName)
DownloadImage(imgUrl, i, client)
time.Sleep(time.Second)
fmt.Println("-------------------------")
})
}
func DownloadImage(url string, index int, client *http.Client) {
req, err := http.NewRequest("POST", url, nil)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Println("读取请求体失败")
return
}
baseDir := "./image/image-%d.jpg"
f, err := os.OpenFile(fmt.Sprintf(baseDir, index), os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
log.Println("打开文件失败", err.Error())
return
}
defer f.Close()
_, err = f.Write(data)
if err != nil {
log.Println("写入数据失败")
return
}
fmt.Println("下载图片成功")
}
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
Run(method, url, nil, client)
}下面是爬取多頁資料爬取多頁的程式碼沒有多大的改動,我們還是需要先觀察網站的特點
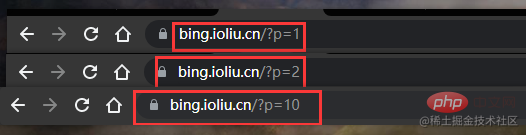 發現什麼了嗎?第一頁p=1,第二頁p=2,第十頁p=10
發現什麼了嗎?第一頁p=1,第二頁p=2,第十頁p=10
所以我們直接起一個for循環,然後復用之前爬取單頁的程式碼就行
// 爬取多页的main函数如下
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
for i := 1; i < 5; i++ { // 实现分页操作
Run(method, fmt.Sprintf(url, i), nil, client)
}
}總結
在我們這個例子中,我們解析網頁資料使用的工具的一個第三方包,因為用正規真的太麻煩了
推薦學習:Golang教學
#以上是詳解怎麼使用Golang爬取必應壁紙的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何使用 Golang 安全地讀取和寫入檔案?
Jun 06, 2024 pm 05:14 PM
如何使用 Golang 安全地讀取和寫入檔案?
Jun 06, 2024 pm 05:14 PM
在Go中安全地讀取和寫入檔案至關重要。指南包括:檢查檔案權限使用defer關閉檔案驗證檔案路徑使用上下文逾時遵循這些準則可確保資料的安全性和應用程式的健全性。
 Golang框架與Go框架:內部架構與外部特性對比
Jun 06, 2024 pm 12:37 PM
Golang框架與Go框架:內部架構與外部特性對比
Jun 06, 2024 pm 12:37 PM
GoLang框架與Go框架的差異體現在內部架構與外部特性。 GoLang框架基於Go標準函式庫,擴充其功能,而Go框架由獨立函式庫組成,以實現特定目的。 GoLang框架更靈活,Go框架更容易上手。 GoLang框架在效能上稍有優勢,Go框架的可擴充性更高。案例:gin-gonic(Go框架)用於建立RESTAPI,而Echo(GoLang框架)用於建立Web應用程式。
 從前端轉型後端開發,學習Java還是Golang更有前景?
Apr 02, 2025 am 09:12 AM
從前端轉型後端開發,學習Java還是Golang更有前景?
Apr 02, 2025 am 09:12 AM
後端學習路徑:從前端轉型到後端的探索之旅作為一名從前端開發轉型的後端初學者,你已經有了nodejs的基礎,...
 Go語言中哪些庫是由大公司開發或知名的開源項目提供的?
Apr 02, 2025 pm 04:12 PM
Go語言中哪些庫是由大公司開發或知名的開源項目提供的?
Apr 02, 2025 pm 04:12 PM
Go語言中哪些庫是大公司開發或知名開源項目?在使用Go語言進行編程時,開發者常常會遇到一些常見的需求,�...
 Golang的目的:建立高效且可擴展的系統
Apr 09, 2025 pm 05:17 PM
Golang的目的:建立高效且可擴展的系統
Apr 09, 2025 pm 05:17 PM
Go語言在構建高效且可擴展的系統中表現出色,其優勢包括:1.高性能:編譯成機器碼,運行速度快;2.並發編程:通過goroutines和channels簡化多任務處理;3.簡潔性:語法簡潔,降低學習和維護成本;4.跨平台:支持跨平台編譯,方便部署。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 Debian上Golang日誌的輪轉策略是什麼
Apr 02, 2025 am 08:39 AM
Debian上Golang日誌的輪轉策略是什麼
Apr 02, 2025 am 08:39 AM
在Debian系統中,Go語言的日誌輪轉通常依賴於第三方庫,而非Go標準庫自帶功能。 lumberjack是一個常用的選擇,它可以與各種日誌框架(例如zap、logrus)配合使用,實現日誌文件的自動輪轉和壓縮。以下是一個使用lumberjack和zap庫的示例配置:packagemainimport("gopkg.in/natefinch/lumberjack.v2""go.uber.org/zap""go.uber.org/zap/zapcor
 Golang和C:並發與原始速度
Apr 21, 2025 am 12:16 AM
Golang和C:並發與原始速度
Apr 21, 2025 am 12:16 AM
Golang在並發性上優於C ,而C 在原始速度上優於Golang。 1)Golang通過goroutine和channel實現高效並發,適合處理大量並發任務。 2)C 通過編譯器優化和標準庫,提供接近硬件的高性能,適合需要極致優化的應用。
