

pcie3.0x4最大速度是多少

PCIe3.0x4理論最大讀或寫的速度為4GB/s,不考慮協定開銷,每秒可以傳輸4GB/4K個4K大小的IO,該值為1M,即理論上最大IOPS為1000K。因此,一個SSD不管底層用什麼介質,flash還是3d xpoint,介面速度就這麼塊,最大IOPS是不可能超過這個值的。

本教學操作環境:windows7系統、Dell G3電腦。
PCIe介面介紹
PCIe發展到現在,速度世代比一代快。

Link Width這一行,我們看到X1,X2,X4…,這是什麼意思?這是指PCIe連接的通道數(Lane)。就像高速一樣,有單根道,有2根道的,有4根道的,不過像8根道或更多道的公路不常見,但PCIe是可以最多32條道的。

兩個裝置之間的PCIe連接,叫做一個Link,如下圖所示:

從A到B,之間是雙向連接,車可以從A駛向B,同時,車也可以從B駛向A,各行其道。兩個PCIe設備之間,有專門的發送和接收通道,資料可以同時往兩個方向傳輸,PCIe spec稱這種工作模式為雙單工模式(dual-simplex),可以理解為全雙工模式。
SATA是什麼工作模式呢?

和PCIe一樣,SATA也有獨立的發送和接收通道,但與PCIe工作模式不一樣:同一時間,只有一條道可以進行資料傳輸,也就是說,你在一條道上發送數據,另外一條道上不能接收數據,反之亦然。這種工作模式應該是半雙工模式。 PCIe就像我們的手機,雙方可以同時講話,而SATA就是對講機了,一個人在說話,另外一個人就只能聽不能說。
回到前面PCIe頻寬那張表,上面的頻寬,例如PCIe3.0x1,頻寬為2GB/s,是指雙向頻寬,即讀寫頻寬。如果單指讀或寫,該值應該減半,即1GB/s的讀速度或寫速度。
我們來看看表格裡面的頻寬是怎麼算出來的。
PCIe是序列匯流排,PCIe1.0的線上位元傳輸速率為2.5Gb/s,物理層使用8/10編碼,即8位元的數據,實際上在物理線路上是需要傳輸10位元的,因此:
PCIe1.0 x 1的带宽=(2.5Gb/s x 2(双向通道))/ 10bit = 0.5GB/s
這是單一Lane的頻寬,有幾條Lane,那麼整個頻寬就0.5GB/s乘以Lane的數目。
PCIe2.0的線上位元傳輸速率在PCIe1.0的基礎上翻了一倍,為5Gb/s,物理層同樣使用8/10編碼,所以:
PCIe2.0 x 1的带宽=(5Gb/s x 2(双向通道))/ 10bit = 1GB/s
同樣,有多少Lane,頻寬就是1GB/s乘以Lane的數目。
PCIe3.0的線上位元傳輸速率沒有在PCIe2.0的基礎上翻倍,不是10Gb/s,而是8Gb/s,但物理層使用的是128/130編碼進行資料傳輸,所以:
PCIe3.0 x 1的带宽=(8Gb/s x 2(双向通道))/ 8bit = 2GB/s
同樣,有多少個Lane,頻寬就是2GB/s乘以Lane的數目。
由於採用了128/130編碼,128位元的數據,只額外增加了2bit的開銷,有效數據傳輸比率增大,雖然線上位元傳輸率沒有翻倍,但有效數據頻寬還是在PCIe2.0的基礎上做到翻倍。
這裡值得一提的是,上面算出的資料頻寬已經考慮到8/10或128/130編碼,因此,大家在算頻寬的時候,沒有必要再考慮線上編碼的問題了。
和SATA單通道不同,PCIe連接可以透過增加通道數來擴展頻寬,彈性十足。通道數越多,速度越快。不過,通道數越多,成本越高,佔用更多空間,還有就是更耗電。因此,使用多少通道,應該在性能和其他因素之間進行一個綜合考慮。單考慮效能的話,PCIe最高頻寬可達64GB/s,PCIe 3.0 x 32對應的頻寬,很恐怖的一個資料。不過,現有的PCIe介面SSD,一般最多使用4通道,如PCIe3.0x4,雙向頻寬為8GB/s,讀取或寫入頻寬為4GB/s。

幾個GB/s的傳輸速度,讀寫小電影那是槓槓的。
在此,順便來算算PCIe3.0x4理論上最大的4K IOPS。 PCIe3.0x4理論最大讀取或寫入的速度為4GB/s,不考慮協定開銷,每秒可傳輸4GB/4K個4K大小的IO,值為1M,即理論上最大IOPS為1000K。因此,一個SSD,不管你底層用什麼介質,flash還是3d xpoint,介面速度就這麼塊,最大IOPS是不可能超過這個值的。
PCIe是從PCI發展過來的,PCIe的」e」是express的簡稱,快的意思。 PCIe怎麼就能比PCI(或PCI-X)快呢? PCIe在實體傳輸上,跟PCI有著本質上的差異:PCI使用並口傳輸數據,而PCIe使用的是串口傳輸。我PCI並行匯流排,單一時脈週期可以傳輸32bit或64bit,怎麼就比不了你單一時脈週期傳輸1個bit資料的串列匯流排呢?
在實際時脈頻率比較低的情況下,並口因為可以同時傳輸若干比特,速率確實比串列埠快。隨著技術的發展,資料傳輸速率要求越來越快,要求時脈頻率也越來越快,但是,並行匯流排時脈頻率不是想快就能快的。

在發送端,資料在某個時鐘沿傳出去(左邊時鐘第一個上升沿),在接收端,資料在下個時鐘沿(右邊時鐘第二個上升沿)接收。因此,要在接收端能正確採集到數據,要求時脈的週期必須大於數據傳輸的時間(從發送端到接收端,flight time)。受限於資料傳輸時間(該時間也隨著資料線長度的增加而增加),因此時脈頻率不能做得太高。另外,時脈訊號在線上傳輸的時候,也會有相位偏移(clock skew ),影響接收端的資料擷取;還有,並行傳輸,接收端必須等最慢的那個bit資料到了以後,才能鎖住整個數據(signal skew)。
PCIe使用序列匯流排進行資料傳輸就沒有這些問題。它沒有外部時脈訊號,它的時脈資訊透過8/10編碼或128/130編碼嵌入在資料流,接收端可以從資料流裡面恢復時脈訊息,因此,它不受資料在線上傳輸時間的限制,你導線多長都沒有問題,你資料傳輸頻率多快也沒有問題;沒有外部時脈訊號,自然就沒有所謂的clock skew問題;由於是串列傳輸,只有一個bit傳輸,所以不存在signal skew問題。但是,如果使用多條lane傳輸資料(串列中又有並行,哈哈),這個問題又回來了,因為接收端同樣要等最慢的那個lane上的資料到達才能處理整個資料。
PCIe匯流排的基礎知識
與PCI匯流排不同,PCIe匯流排使用端對端的連接方式,在一條PCIe連結的兩端只能各連接一個設備,這兩個設備互為是資料傳送端和資料接收端。 PCIe匯流排除了匯流排連結外,還有多個層次,在傳送端傳送資料時會透過這些層次,而接收端接收資料時也會使用這些層次。 PCIe匯流排使用的層次結構與網路協定堆疊較為類似。
PCIe連結使用“端對端的資料傳送方式”,發送端和接收端都含有TX(發送邏輯)和RX(接收邏輯),其結構如圖所示。

由上圖所示,在PCIe匯流排的實體連結的一個資料路徑(Lane)中,由兩組差分訊號,共4個訊號線組成。其中發送端的TX部件與接收端的RX部件使用一組差分信號連接,該鏈路也被稱為發送端的發送鏈路,也是接收端的接收鏈路;而發送端的RX部件與接收端的TX部件使用另一組差分訊號連接,該鏈路也被稱為發送端的接收鏈路,也是接收端的發送鏈路。一個PCIe連結可以由多個Lane組成。
高速差分訊號電氣規範要求其發送端串接一個電容,以進行AC耦合。此電容也稱為AC耦合電容。 PCIe鏈路使用差分訊號進行資料傳送,一個差分訊號由D 和D-兩根訊號組成,訊號接收端透過比較這兩個訊號的差值,判斷發送端發送的是邏輯「1」還是邏輯「0 」。
與單端訊號相比,差分訊號抗干擾的能力更強,因為差分訊號在佈線時要求“等長”、“等寬”、“貼近”,而且在同層。因此外部幹擾雜訊將被「同值」且「同時」載入到D 和D-兩根訊號上,其差值在理想情況下為0,對訊號的邏輯值產生的影響較小。因此差分訊號可以使用更高的總線頻率。
此外使用差分訊號能有效抑制電磁幹擾EMI(Electro Magnetic Interference)。由於差分訊號D 與D-距離很近且訊號振幅相等、極性相反。這兩根線與地線間耦合電磁場的振幅相等,將相互抵消,因此差分訊號對外界的電磁幹擾較小。當然差分訊號的缺點也是顯而易見的,一是差分訊號使用兩根訊號傳送一位資料;二是差分訊號的佈線相對嚴格一些。
PCIe連結可以由多個Lane組成,目前PCIe連結可以支援1、2、4、8、12、16和32個Lane,即×1、×2、×4、×8 、×12、×16和×32寬度的PCIe連結。每一個Lane上使用的匯流排頻率與PCIe匯流排所使用的版本相關。
第1個PCIe匯流排規格為V1.0,之後依序為V1.0a,V1.1,V2.0和V2.1。目前PCIe匯流排的最新規範為V2.1,而V3.0正在開發過程中,預計2010年發布。不同的PCIe匯流排規格所定義的匯流排頻率和連結編碼方式並不相同,如表41所示。
PCIe匯流排規格與總線頻率和編碼的關係
| #PCIe匯流排規格 | 匯流頻率[1 ] | 單Lane的峰值頻寬 | 編碼方式 |
|---|---|---|---|
| #1.x | #1.25GHz | 2.5GT/s | #8/10b編碼 |
| #2.x | 2.5GHz | 5GT/s | 8/10b編碼 |
| #3.0 | #4GHz | 8GT/s | 128/130b編碼 |
如上表所示,不同的PCIe匯流排規格所使用的匯流排頻率並不相同,其所使用的資料編碼方式也不相同。 PCIe匯流排V1.x和V2.0規範在物理層中使用8/10b編碼,即在PCIe鏈路上的10 bit中含有8 bit的有效資料;而V3.0規範使用128/130b編碼方式,即在PCIe鏈路上的130 bit中含有128 bit的有效資料。
由上表所示,V3.0規範所使用的匯流排頻率雖然只有4GHz,但其有效頻寬是V2.x的兩倍。下文將以V2.x規格為例,說明不同寬度PCIe連結所能提供的峰值頻寬,如表42所示。
PCIe匯流排的峰值頻寬
| PCIe匯流排的資料位寬 | ×1 | ##×2 | ×4 | ×8 | ×12 | ×16 | ##×32|
|---|---|---|---|---|---|---|---|
| 5 | #10 | #20 | #40 | 60 | 80 | 160 |
常見問題欄位!
以上是pcie3.0x4最大速度是多少的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 請關閉電源並連接PCIe電源線
Feb 19, 2024 am 11:09 AM
請關閉電源並連接PCIe電源線
Feb 19, 2024 am 11:09 AM
如果您看到錯誤訊息請關閉電源並連接Windows11/10PC上的PCIe電源線,請閱讀此貼文以了解如何解決該問題。當PCIe設備(通常是圖形卡)未能獲得足夠的電力時,可能會觸發此錯誤。可能的原因包括PCIe電源線故障、連接問題或電源不足。若未正確連接電源線,也可能導致此問題。請關閉電源並連接此顯示卡的PCIE電源線(S)初次使用個人電腦的使用者或缺乏組裝電腦系統經驗的人經常會遇到這種問題。如果PCIe電纜因振動或時間推移而鬆動,也可能會導致該錯誤訊息的出現。本文將介紹解決此問題所需採取的步驟
 pcie4.0和pcie3.0介面一樣嗎
Mar 13, 2023 pm 04:39 PM
pcie4.0和pcie3.0介面一樣嗎
Mar 13, 2023 pm 04:39 PM
pcie4.0和pcie3.0介面不一樣,它們是兩個不同版本的PCIe標準。兩者的差異:1、PCIe4.0提供了更快的資料傳輸速度,高達16GT/s,是PCIe3.0的兩倍;2、PCIe 4.0支援更多的頻寬,最高可達69.6GB/s,而PCIe3.0最高只能支援32GB/s;3、PCIe4.0支援更多的通道,可以支援更多的設備;4、PCIe4.0支援更低的電力消耗。
 延遲 1 年,PCIe 6.0/7.0 規範部署遇阻礙
Jun 15, 2024 pm 04:45 PM
延遲 1 年,PCIe 6.0/7.0 規範部署遇阻礙
Jun 15, 2024 pm 04:45 PM
本站6月15日消息,週邊組件互連特別興趣小組(PCI-SIG)本週召開舉辦2024開發者大會,公佈了PCIe6.0和PCIe7.0的最新進展情況,表示上述兩個標準雖然已取得一定進展,但部署普及時間比預期慢。 PCI-SIG目前已推遲啟動“一致性計劃”(ComplianceProgram),PCIe6.0的初步一致性測試原定於今年3月開始,目前已經推遲到“第2季度”,也就是會在本月底前測試。 2023年(上)和2024年(下)的PCIe標準發布路線圖該機構表示PCIe6.0深度一致性測試將於20
 pcie3.0x4最大速度是多少
Mar 15, 2023 pm 05:09 PM
pcie3.0x4最大速度是多少
Mar 15, 2023 pm 05:09 PM
PCIe3.0x4理論最大讀取或寫入的速度為4GB/s,不考慮協定開銷,每秒可傳輸4GB/4K個4K大小的IO,值為1M,即理論上最大IOPS為1000K。因此,一個SSD不管底層用什麼介質,flash還是3d xpoint,介面速度就這麼塊,最大IOPS是不可能超過這個值的。
 PCIe 7.0 規範正式初稿(0.5 版本)公佈,仍有望明年全面發布
Apr 04, 2024 am 08:37 AM
PCIe 7.0 規範正式初稿(0.5 版本)公佈,仍有望明年全面發布
Apr 04, 2024 am 08:37 AM
本站4月3日消息,PCIe規範制定組織PCI-SIG近日宣布PCIe7.0規範的0.5版本,也就是其正式初稿現已向PCI-SIG成員公佈。相較於2022年初發布的PCIe6.0規範,PCIe7.0規範在沿用PAM4訊號調製方式的同時再次翻倍速率,可實現128GT/s的原始資料速率,並在x16配置下實現512GB/s的雙向比特率。 PCIe7.0架構的開發重點在於提升頻道參數、覆蓋範圍和能源效率,旨在為800G乙太網路、AI/ML工作負載,超大規模資料中心、高效能運算、量子運算、雲端等資料密集型應用提供可
 2024 年科隆遊戲展 |華碩和微星揭示 GPU 和 M.2 SSD 的創新快速釋放機制
Aug 25, 2024 am 06:30 AM
2024 年科隆遊戲展 |華碩和微星揭示 GPU 和 M.2 SSD 的創新快速釋放機制
Aug 25, 2024 am 06:30 AM
在 Gamescom 2024 上,華碩和 MSI 推出了一些很酷的 GPU 和 M.2 SSD 快速釋放機制,確實引人注目。這些新功能旨在讓建構 PC 的人們的生活變得更輕鬆,尤其是在處理那些笨重的組件時。華碩羅勒
 PCIe 6 發熱咋辦?英特爾提交新驅動,透過控制總線速度緩解
Jun 04, 2024 am 10:28 AM
PCIe 6 發熱咋辦?英特爾提交新驅動,透過控制總線速度緩解
Jun 04, 2024 am 10:28 AM
本站5月11日消息,PCIe版本更迭帶來了更高的頻寬、更快的傳輸速度,同時也帶來了更多的熱量。英特爾公司最近發布Linux驅動程序,透過開源的「PCIe頻寬控制器」來遏制熱量,在熱量達到一定閾值時自動控制鏈路速度。本站註:PCIe版本更迭不僅提高了傳輸速度,還要求更好的訊號完整性和更低的訊號損耗,因此往往需要更高的時脈頻率、更大的功率和編碼最佳化,而所有這些都會產生額外的熱量。英特爾工程師IlpoJärvinen在最新的補丁說明中寫道:「該系列補丁僅增加了對控制PCIe鏈路速度的支援。控制PCIe
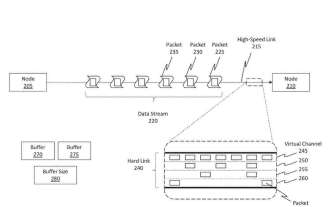 改進HoloLens內部PCIe資料連結傳輸:微軟分享AR/VR專利
Jan 03, 2024 pm 02:05 PM
改進HoloLens內部PCIe資料連結傳輸:微軟分享AR/VR專利
Jan 03, 2024 pm 02:05 PM
(映維網Nweon2023年12月27日)有線連接通常稱為“硬連結”,它將一個節點物理連接到另一個節點。一種有線連接是PCIe。 PCIe是一種用於連接高速節點的接口,而儘管諸如PCIe等高速連接終端和協定提供了實質性的優勢,但所述類型的終端需要高功率運行。對於頭戴裝置這樣的電池供電計算架構,這會對系統造成巨大的負擔。在名為「Errorrecoveryandpowermanagementbetweennodesofaninterconnectionnetwork」的專利申請中,微軟介紹了透過從錯誤條