

Google推出多模態Vid2Seq,理解視訊IQ在線,字幕君不會下線了|CVPR 2023

華人博士和Google科學家最新提出了預訓練視覺語言模型Vid2Seq,可以分辨和描述一段影片中的多個事件。這篇論文已被CVPR 2023接收。
最近,來自Google的研究員提出了一種用於描述多事件影片的預訓練視覺語言模型-Vid2Seq,目前已被CVPR23接收。
在以前,理解影片內容是一項具有挑戰性的任務,因為影片通常包含在不同時間尺度發生的多個事件。
例如,一個雪橇手將狗拴在雪橇上、然後狗開始跑的影片涉及一個長事件(狗拉雪橇)和一個短事件(狗被拴在雪橇上)。
而促進影片理解研究的一種方法是,透過密集視訊標註任務,該任務包括在一分鐘長的影片中對所有事件進行時間定位和描述。

論文地址:https://arxiv.org/abs/2302.14115
Vid2Seq架構用特殊的時間標記增強了語言模型,使其能夠在同一輸出序列中無縫預測事件邊界和文字描述。
為了對這個統一的模型進行預訓練,研究者透過將轉錄的語音的句子邊界重新表述為偽事件邊界,並將轉錄的語音句子作為偽事件的標註,來利用未標記的旁白影片。

Vid2Seq模型概述
由此產生的Vid2Seq模型在數以百萬計的旁白影片上進行了預訓練,提高了各種密集影片標註基準的技術水平,包括YouCook2、ViTT和ActivityNet Captions。
Vid2Seq也能很好地適用於few-shot的密集視訊標註設定、視訊段落標註任務和標準視訊標註任務。

用於密集視訊標註的視覺語言模型
多模態Transformer架構已經刷新了各種視訊任務的SOTA,例如動作辨識。然而,要讓這樣的架構適應在長達幾分鐘的影片中聯合定位和標註事件的複雜任務,並不簡單。
為了實現這個目標,研究者用特殊的時間標記(如文字標記)來增強視覺語言模型,這些時間標記代表影片中離散的時間戳,類似於空間領域的Pix2Seq。
對於給定的視覺輸入,所產生的Vid2Seq模型既可以接受輸入,也可以產生文字和時間標記的序列。
首先,這使得Vid2Seq模型能夠理解轉錄的語音輸入的時間訊息,它被投射為單一的標記序列。其次,這使Vid2Seq能夠聯合預測密集的事件標註,並在影片中以時間為基礎,同時產生單一的標記序列。
Vid2Seq架構包括一個視覺編碼器和一個文字編碼器,它們分別對視訊幀和轉錄的語音輸入進行編碼。產生的編碼隨後被轉發到文字解碼器,該解碼器自動預測密集事件標註的輸出序列,以及它們在影片中的時間定位。在這個架構初始化時有一個強大的視覺主幹和一個強大的語言模型。

對影片進行大規模預訓練
由於任務的密集性,為密集的影片標註手動收集註解的成本特別高。
因此,研究者使用了無標籤的解說影片對Vid2Seq模型進行預訓練,這些影片在規模上很容易取得。他們還使用了YT-Temporal-1B資料集,其中包括1800萬個涵蓋廣泛領域的旁白影片。
研究者使用轉錄的語音句子及其對應的時間戳作為監督,這些句子被投射為單一的token序列。
然後用一個生成目標對Vid2Seq進行預訓練,該目標教導解碼器僅預測給定視覺輸入的轉錄的語音序列,以及一個鼓勵多模態學習的去噪目標,要求模型在有噪音的轉錄語音序列和視覺輸入的情況下預測掩碼。特別是,透過隨機掩蓋跨度的token,把噪音添加到語音序列中。

下游任務的基準測室結果
由此產生的預訓練的Vid2Seq模型可以透過一個簡單的最大似然目標在下游任務中進行微調,該目標使用教師強迫(即在給在定先前的基礎真實token的情況下預測下一個token)。
經過微調,Vid2Seq在三個標準的下游密集視訊標註基準(ActivityNet Captions、YouCook2和ViTT)和兩個影片剪輯標註基準(MSR-VTT、MSVD)上超越了SOTA。
在論文中,還有額外的消融研究、定性結果,以及在few-shot設定和視訊段落標註任務中的結果。
定性測試
結果表明,Vid2Seq可以預測有意義的事件邊界和標註,而且預測的標註和邊界與轉錄的語音輸入有很大的不同(這也表明輸入中視覺標記的重要性)。

下一個範例有關於烹飪食譜中的一系列指令,是Vid2Seq對YouCook2驗證集的密集事件標註預測的例子:

#接下來是Vid2Seq對ActivityNet Captions驗證集的密集事件標註預測的例子,在所有這些影片中,都沒有轉錄的語音。
不過還是會有失敗的案例,像是下面標紅的這個畫面,Vid2Seq說是一個人對著鏡頭脫帽致敬。
對標SOTA
表5將Vid2Seq與最先進的密集視訊標註方法進行了比較:Vid2Seq在YouCook2、ViTT 和ActivityNet Captions這三個資料集上刷新了SOTA。

Vid2Seq在YouCook2和ActivityNet Captions上的SODA指標比PDVC和UEDVC分別增加了3.5和0.3分。且E2ESG在Wikihow上使用域內純文字預訓練,而Vid2Seq優於此方法。這些結果表明,預先訓練的Vid2Seq模型具有很強的密集事件標註能力。
表6評估了密集視訊標註模型的事件定位表現。與YouCook2和ViTT相比,Vid2Seq在處理密集視訊標註作為單一序列生成任務時更勝一籌。

然而,與PDVC和UEDVC相比,Vid2Seq在ActivityNet Captions上表現不佳。與這兩種方法相比,Vid2Seq整合了較少的關於時間定位的先驗知識,而另兩種方法包括特定的任務組件,如事件計數器或單獨為定位子任務訓練一個模型。
實作細節
- 架構
視覺時間transformer編碼器、文字編碼器和文字解碼器都有12層,12個頭,嵌入維度768,MLP隱藏維度2048。
文字編碼器和解碼器的序列在預訓練時被截斷或填充為L=S=1000個token,在微調期間,S=1000和L=256個token。在推理過程中,使用波束搜尋解碼,追蹤前4個序列並應用0.6的長度歸一化。
- 訓練
作者使用Adam優化器,β=(0.9, 0.999),沒有權重衰減。
在預訓練期間,使用1e^-4的學習率,在前1000次迭代中線性預熱(從0開始),並在其餘迭代中保持不變。
在微調期間,使用3e^-4的學習率,在前10%的迭代中線性預熱(從0開始),其餘90%的迭代中保持餘弦衰減(降至0)。過程中,使用32個視訊的批次量,並在16個TPU v4晶片上分割。
作者對YouCook2進行了40次epoch調整,對ActivityNet Captions和ViTT進行了20次epoch調整,對MSR-VTT進行了5次epoch調整,對MSVD進行了10次epoch調整。
結論
Google提出的Vid2Seq,是一種用於密集視訊標註的新型視覺語言模型,它可以有效地在無標籤的旁白影片上進行大規模的預訓練,並在各種下游密集視訊標註的基準上取得了SOTA的結果。
作者介紹
論文一作:Antoine Yang

Antoine Yang是法國國立電腦及自動化研究院Inria和巴黎高等師範學校École Normale Supérieure的WILLOW團隊的三年級博士生,導師為Antoine Miech, Josef Sivic, Ivan Laptev和Cordelia Schmid。
目前的研究重點是學習用於視訊理解的視覺語言模型。他於2019年在華為諾亞方舟實驗室實習,並在2020年獲得了巴黎綜合理工學院的工程學位和巴黎薩克雷國立大學的數學、視覺和學習碩士學位,2022年在谷歌研究院實習。
以上是Google推出多模態Vid2Seq,理解視訊IQ在線,字幕君不會下線了|CVPR 2023的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 在 Windows 11 上徹底刪除不需要的顯示語言的方法
Sep 24, 2023 pm 04:25 PM
在 Windows 11 上徹底刪除不需要的顯示語言的方法
Sep 24, 2023 pm 04:25 PM
在同一設定上工作太久或與他人分享PC。您可能會安裝一些語言包,這通常會產生衝突。因此,是時候刪除Windows11中不需要的顯示語言了。說到衝突,當有多個語言包時,無意中按Ctrl+Shift會更改鍵盤佈局。如果不注意,這將是手頭任務的障礙。所以,讓我們直接進入方法吧!如何從Windows11中刪除顯示語言? 1.從設定按+開啟“設定”應用,從導覽窗格中前往“時間和語言”,然後按一下“語言和地區”。 WindowsI點選要刪除的顯示語言旁邊的省略號,然後從彈出式選單中選擇「刪除」。在出現的確認提示中按一下“
 在 iPhone 上更改語言的 3 種方法
Feb 02, 2024 pm 04:12 PM
在 iPhone 上更改語言的 3 種方法
Feb 02, 2024 pm 04:12 PM
眾所周知,iPhone是最人性化的電子產品之一,其中一個原因是它可以輕鬆地根據您的喜好進行個性化設定。在個人化設定中,您可以變更語言,這與您在設定iPhone時選擇的語言不同。如果您對多種語言熟悉,或者您的iPhone語言設定錯誤,您可以按照我們下面解釋的方法進行更改。如何更改iPhone的語言[3種方法]iOS允許使用者在iPhone上自由切換首選語言,以適應不同的需求。您可以更改與Siri的互動語言,方便與語音助理溝通。同時,在使用本機鍵盤時,您可以輕鬆地在多種語言之間切換,提高輸入效率。
 給語言大模型加上綜合視聽能力,達摩院開源Video-LLaMA
Jun 09, 2023 pm 09:28 PM
給語言大模型加上綜合視聽能力,達摩院開源Video-LLaMA
Jun 09, 2023 pm 09:28 PM
影片在當今社群媒體和網路文化中扮演著愈發重要的角色,抖音,快手,B站等已經成為數以億計用戶的熱門平台。用戶圍繞影片分享自己的生活點滴、創意作品、有趣時刻等內容,與他人互動和交流。近期,大語言模型展現了令人矚目的能力。我們能否給大模型裝上“眼睛”和“耳朵”,讓它能夠理解視頻,陪著用戶互動呢?從這個問題出發,達摩院的研究人員提出了Video-LLaMA,一個具有綜合視聽能力大模型。 Video-LLaMA能夠感知和理解視訊中的視訊和音訊訊號,並能理解使用者輸入的指令,完成一系列基於音訊視訊的複雜任務,
 如何將Win10電腦的語言設定為漢語?
Jan 05, 2024 pm 06:51 PM
如何將Win10電腦的語言設定為漢語?
Jan 05, 2024 pm 06:51 PM
有時候我們再剛入手安裝好電腦系統之後發現系統時英文的,遇到這種情況我們就需要把電腦的語言改成中文,那麼win10系統裡面該怎麼把電腦的語言改成中文呢,現在就給大家帶來具體的操作方法。 win10電腦語言怎麼改成中文1、開啟電腦點選左下角的開始按鍵。 2、點選左側的設定選項。 3.開啟的頁面選擇「時間和語言」4、開啟後,再點選左側的「語言」5、在這裡就可以設定你要的電腦語言。
 已修復: Alt + Shift 不會更改 Windows 11 上的語言
Oct 11, 2023 pm 02:17 PM
已修復: Alt + Shift 不會更改 Windows 11 上的語言
Oct 11, 2023 pm 02:17 PM
當Alt+Shift不更改Windows11上的語言時,您可以使用Win+空白鍵獲得相同的效果。另外,請確保使用左Alt+Shift而不是鍵盤右側的那些。為什麼Alt+Shift無法更改語言?您沒有更多語言可供選擇。輸入語言熱鍵已變更。最新Windows更新中的錯誤阻止您更改鍵盤語言。卸載最新更新以解決此問題。您處於應用程式的活動視窗中,該應用程式使用相同的熱鍵執行其他操作。你如何使用AltShift更改Windows11上的語言? 1.使用正確的按鍵順序首先,確保您使用的是使用+組合的正確方法。
 吵翻天! ChatGPT到底懂不懂語言? PNAS:先研究什麼是「理解」吧
Apr 07, 2023 pm 06:21 PM
吵翻天! ChatGPT到底懂不懂語言? PNAS:先研究什麼是「理解」吧
Apr 07, 2023 pm 06:21 PM
機器會不會思考這個問題就像問潛水艇會不會游泳一樣。 ——Dijkstra早在ChatGPT發表之前,業界就已經嗅到了大模型帶來的改變。去年10月14日,聖塔菲研究所(Santa Fe Institute)的教授Melanie Mitchell和David C. Krakauer在arXiv發布了一篇綜述,全面調研了所有關於「大規模預訓練語言模型是否可以理解語言」的相關爭論,文中描述了「正方」和「反方」的論點,以及根據這些論點衍生的更廣泛的智力科學的關鍵問題。論文連結:https://arxiv.o
 光動嘴就能玩出原神!用AI切換角色,還能攻擊敵人,網友:'綾華,使用神裡流·霜滅”
May 13, 2023 pm 07:52 PM
光動嘴就能玩出原神!用AI切換角色,還能攻擊敵人,網友:'綾華,使用神裡流·霜滅”
May 13, 2023 pm 07:52 PM
說到這兩年風靡全球的國產遊戲,原神肯定是當仁不讓。根據5月公佈的本年度Q1季手遊收入調查報告,在抽卡手遊裡《原神》以5.67億美金的絕對優勢穩穩拿下第一,這也宣告《原神》在上線短短18個月後單在手機平台總收入就突破30億美金(約RM130億)。如今,開放須彌前最後的2.8海島版本姍姍來遲,在漫長的長草期後終於又有新的劇情和區域可以肝了。不過我不知道有多少“肝帝”,現在海島已經滿探索,又開始長草了。寶箱總共182個+1個摩拉箱(不計入)長草期根本沒在怕的,原神區從來不缺整活兒。不,在長草期間
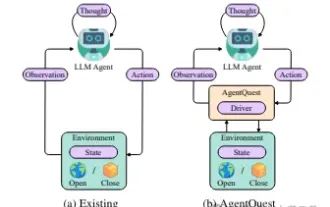 探索智能體的邊界:AgentQuest,一個全面衡量和提升大型語言模型智能體性能的模組化基準框架
Apr 11, 2024 pm 08:52 PM
探索智能體的邊界:AgentQuest,一個全面衡量和提升大型語言模型智能體性能的模組化基準框架
Apr 11, 2024 pm 08:52 PM
基於大模型的持續最佳化,LLM智能體-這些強大的演算法實體已經展現出解決複雜多步驟推理任務的潛力。從自然語言處理到深度學習,LLM智能體正逐漸成為研究和工業界的焦點,它們不僅能理解和生成人類語言,還能在多樣的環境中製定策略、執行任務,甚至使用API調用和編碼來建置解決方案。在這種背景下,AgentQuest框架的提出具有里程碑意義,它不僅僅是一個LLM智能體的評估和進步提供了一個模組化的基準測試平台,而且透過其易於擴展的API,為研究人員提供了一個強大的工具,以更細緻地追蹤和改進這些智能體的性能
