
在MySQL中,負載平衡是指將多個MySQL伺服器組成一個集群,透過分攤資料庫查詢請求的方式,以達到提高資料庫系統效能的目的。 MySQL負載平衡是為了解決單一資料庫處理大量請求時的瓶頸問題,透過將請求平衡分配到多台伺服器上,達到提高資料庫系統效能的目的;同時,負載平衡也可以提高資料庫系統的可用性,一旦其中一台伺服器發生故障,其他伺服器可以繼續處理請求,從而保證了服務的持續性。

本教學操作環境:windows7系統、mysql8版本、Dell G3電腦。
什麼是MySQL負載平衡?
MySQL負載平衡是指將多個MySQL伺服器組成一個集群,透過分攤資料庫查詢請求的方式,以達到提高資料庫系統效能的目的。負載平衡可以實現高可用性、可擴展性和負載平衡。
負載平衡的基本想法很簡單:在一個伺服器叢集中盡可能的平均負載量。基於這個思路,我們通常的做法是在伺服器前端設定一個負載平衡器。負載平衡器的作用是將請求的連線路由到最空閒的可用伺服器上。
如圖 1,顯示了一個大型網站負載平衡設定。其中一個負責 HTTP 流量,另一個用於 MySQL 存取。
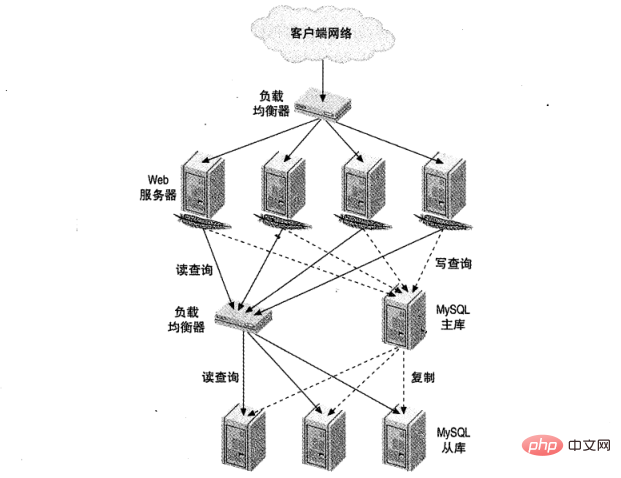
為什麼需要MySQL負載平衡?
MySQL負載平衡是為了解決單一資料庫處理大量請求時的瓶頸問題,透過將請求平衡分配到多台伺服器上,達到提高資料庫系統效能的目的。同時,負載平衡也可以提高資料庫系統的可用性,一旦其中一台伺服器發生故障,其他伺服器可以繼續處理請求,從而保證了服務的持續性。
負載平衡有五個常見目的:
可擴展性。負載平衡對某些擴充很有幫助,例如讀寫分離時從備庫讀取資料。
高效率。負載平衡因為能夠控制請求被路由到何處,因此有助於更有效的使用資源。
可用性。靈活的負載平衡方案能夠大幅提高服務的可用性。
透明性。客戶端無需知道是否存在負載平衡器,也不需要關係在負載平衡器的背後有多少機器。呈現給客戶端看到的就是一個透明的伺服器。
一致性。如果應用程式是有狀態的(資料庫事務、網站會話等),那麼負載平衡器就可以將相關的查詢指向同一個伺服器,以防止狀態遺失。
MySQL負載平衡的實現方式
而對於負載平衡的實現,一般有兩種方式:直接連接和引入中間件。
有些人認為負載平衡就是配置在應用程式和 MySQL 伺服器直接東西,但實際上這並不是唯一的負載平衡方法。接下來我們就討論常見的應用直連的方法,及其相關注意事項。
此種方式下,容易出現一個最大的問題:髒資料。一個典型的例子是,當用戶評論了一篇博文,然後重新加載頁面,卻沒有看到新增的評論。
當然,我們也不能因為髒資料的問題,就將讀寫分開棄之不用。實際上,對於許多應用,可能對髒數據的容忍度比較高,此時就可以大膽的引入此種方式。
那麼對於髒資料的容忍度比較低的應用,如何進行讀寫分離呢?接下來,我們將讀寫分離再進一步區分,相信你總能找到適合自己的策略。
1) 基於查詢分離
如果應用程式只有少數數據不能容忍髒數據,我們可以將所有不能容忍髒數據的讀和寫都分配到master 上。其它的讀取查詢所分配的 slave 上。此策略很容易實現,但如果容忍髒資料的查詢比較少,很可能會出現無法有效使用備庫的情況。
2) 基於髒資料分離
這是基於查詢分離策略的小改進。需要做一些額外的工作,例如讓應用程式檢查複製延遲,以確定備庫資料是否最新。許多報表類應用程式都可以使用這個策略:只需要晚上載入的資料複製到備庫接口,並不關心是不是完全跟上了主庫。
3) 基於會話分離
這個策略比髒資料分離策略更深入 一些。它是判斷用戶是否修改了數據,用戶不需要看到其他用戶的最新數據,只需要看到自己的更新。
具體可以在會話層設定一個標記位,表示使用者是否做了更新,使用者一旦做了更新,就將該使用者的查詢在一段時間內指向主庫。
這種策略在簡單和有效性之間做了很好的妥協,是一種較推薦的策略。
當然,如果你的想法夠多,可以把基於會話的分離策略和複製延遲監控策略結合起來。如果使用者在 10 秒前更新了數據,而所有備庫延遲在 5 秒內,就可以大膽的從備庫中讀取數據。要注意的是,記得為整個會話選擇同一個備庫,否則一旦多個備庫的延遲不一致,就會給使用者造成困擾。
4) 基於全域版本 / 會話分離
透過記錄主庫日誌座標和備庫已複製的座標對比,確認備庫是否更新資料。當應用程式指向寫入操作時,在提交交易後,執行一次 SHOW MASTER STATUS 操作,然後將主庫日誌座標儲存在快取中,作為被修改物件或會話的版本號碼。當應用程式連接到備庫時,執行 SHOW SLAVE STATUS,並將備庫上的座標和快取中的版本號進行比較。如果備庫比主庫記錄點更新,表示備庫已更新對應數據,可放心的使用。
實際上,許多讀寫分離策略都需要監控複製延遲來決定讀取查詢的分配。不過要注意的是,SHOW SLAVE STATUS 得到的 Seconds_behind_master 欄位的值並不能精確的表示延遲。我們可以使用 Percona Toolkit 中的 pt-heartbeat 工具更好的監控延遲。
對於一些比較簡單的應用,可以為不同目的建立 DNS。最簡單的方法是唯讀伺服器擁有一個 DNS 名(read.mysql-db.com),給負責寫入作業的伺服器起另一個 DNS 名(write.mysql-db.com)。如果備庫能夠跟得上主庫,就把只讀 DNS 名指向到備庫,否則,就指向到主庫。
這種策略非常容易實現,但有一個很大的問題是:無法完全控制 DNS。
這種策略較為危險,即使可以透過修改 /etc/hosts 檔案來避免 DNS 無法完全控制的問題,但仍不失理想策略。
透過在伺服器間轉移虛擬位址,來實現負載平衡。是不是感覺和修改 DNS 很像?但實際上完全是兩碼事。轉移 IP 位址允許 DNS 名保持不變,我們可以透過 ARP 指令(不了解 ARP,看這裡)強制使 IP 位址的變更快速且原子性的通知到局域網路上。
一個比較方便的技術是為每個實體伺服器分配一個固定的 IP 位址。此 IP 位址固定在伺服器上,不再改變。然後可以為每個邏輯上的 「服務」(可以理解為容器)使用一個虛擬 IP 位址。
這樣,IP 就能夠很方便的在伺服器間轉移,無需重新配置應用,實作也更加容易。
上面的策略都是假定應用是和MySQL 伺服器之間連接的,但是許多負載平衡都會引入一個中間件,作為網絡通信的代理。它一邊接受所有的通信,另一邊將這些請求分發的指定伺服器上,並將執行結果發送回請求機器。圖 2 展示了此種架構。 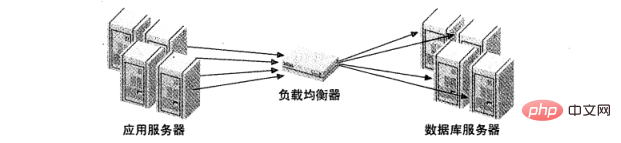
現在有許多負載平衡硬體和軟體,但很少有專門為 MySQL 伺服器設計的。 Web 伺服器通常更需要負載平衡,因此許多多用途的負載平衡設備都會支援 HTTP,而對其他用途則只有一些很少的基本特性。
MySQL 連線只是正常的 TCP/IP 連接,所以可以在 MySQL 上使用多用途負載平衡器。但由於缺乏 MySQL 專有的特性,因此會多一些限制:
有很多演算法用來決定哪個伺服器接受下一個連線。每個廠商都有各自不同的演算法,有以下常用方法:
隨機分配。從可用的伺服器集區中隨機選擇一個伺服器來處理請求。
輪詢。以循環順序傳送請求到伺服器,例如:A、B、C、A、B、C。
哈希。透過連接的來源 IP 位址進行哈希,將其對應到池中的同一個伺服器上。
最快回應。將連線分配給能夠最快處理請求的伺服器上。
最少連線數。將連線分配給擁有最少活躍連線的伺服器上。
權重。根據機器的性能等條件,給不同機器配置不同的權重,以便讓高效能的機器能處理更多的連接。
上述各種方法沒有最好,只有最適合的,這取決於特定的工作負載。
另外,我們只描述了即時處理的演算法。但有時候使用排隊演算法可能會更有效。例如,一個演算法可能只維護給定的資料庫伺服器並發數量,同一時刻只允許不超過 N 個活躍事務。如果有太多的活躍事務,就將新的請求放到一個佇列裡,然後讓可用伺服器清單來處理。
最常見的複製結構就是一個主庫加多個備庫。這種架構的擴展性較差,但我們可以透過一些方法結合負載平衡來獲得更好的效果。
我們不能也不應該在應用的開始就想著把架構做成阿里那樣的架構。最好的方式是實現應用目前所明確需要的,並為可能的快速成長做好預先規劃。
另外,為可擴展性制定一個數字目標是很有意義的,就像我們為效能製定了一個精確目標,滿足 10K 或 100K 並發一樣。這樣可以透過相關理論來避免諸如序列化或交互操作的開銷問題帶入到我們的應用中。
在 MySQL 擴展策略方面,典型的應用在成長到非常龐大時,通常先從單一伺服器轉移到向外擴展的擁有備庫的架構,再到資料分片或按功能分區。這裡要注意的是,我們不提倡諸如 “儘早分片,盡量分片” 的建議。實際上,分片很複雜,而且成本很高,最主要的是許多應用可能根本不需要。與其花大成本去分片,不如先去看看新的硬體和新版本的 MySQL 有哪些變化,也許這些新變化會帶給你驚喜。
總結
為擴展性量化指標。
【相關推薦:mysql影片教學】
以上是mysql中什麼是負載平衡的詳細內容。更多資訊請關注PHP中文網其他相關文章!
























