
根據The Information報導,前谷歌人工智慧研究員Jacob Devlin最近離開公司加入了OpenAI,但在此之前,他爆料曾向谷歌母公司Alphabet的CEO 桑達爾·皮查伊(Sundar Pichai)警告,谷歌的聊天機器人Bard正在以一種間接的方式從ChatGPT獲取數據。

還記得百度文心一言被質疑是「套殼」事件嗎?近日外媒爆料,Google似乎也這麼乾了。
根據The Information報道,前谷歌人工智慧研究員Jacob Devlin最近離開公司加入了OpenAI,但在此之前,他爆料曾向谷歌母公司Alphabet的CEO 桑達爾·皮查伊(Sundar Pichai)警告,Google的聊天機器人Bard正在以一種間接的方式從ChatGPT獲取數據。
根據Devlin描述,Bard的開發團隊造訪了一個名為ShareGPT的網站,該網站分享發布了大量用戶透過ChatGPT取得的聊天內容。這意味著,Bard使用了ChatGPT現成的資料來「武裝」自己,相當於竊取了ChatGPT的早期成果。

對此,Google發言人Chris Pappas 很快就向媒體發布聲明,堅決而明確地表示,"Bard沒有使用任何ShareGPT或ChatGPT的數據進行訓練。( 「Bard is not trained on any data from ShareGPT or ChatGPT.」)"
對於媒體追問谷歌Bard此前是否曾經利用過ChatGPT的數據,Pappas拒絕回答,堅稱自己能說的只是如上聲明內容。
這事件不由得令人想起日前百度文心一言遭遇的類似質疑。
3月下旬,有網友發文質疑百度文心一言作畫實質上是「把中文句子機翻成英語單詞,拿去用國外剛剛開源的人工智能Stable Diffusion生成了圖畫,再返給你,說是自己畫的。」
當時網友舉的例子包括在文心一言輸入指令,要求其畫出“滑鼠和總線”,文心一言作出的畫面是“老鼠和公共汽車”,因為“滑鼠”和“總線”對於的英文是“mouse”和“bus”。
對此百度方面也是緊急回應。 3月23日,百度發布聲明稱,文心一言完全是百度自研的大語言模型,文生圖能力來自文心跨模態大模型ERNIE-ViLG。在大模型訓練中,百度使用的是全球網路公開數據,符合業界慣例。同時表示文心一言正在使用過程中不斷學習成長,希望大家給自研技術和產品一點信心。
隨後,百度對類似問題做了修正,使用者很快發現相關問題已經不存在,顯示類似情況正隨著使用者回饋而修正。
對於百度文心一言的問題,業界專家也表示使用網路公開資料是業界基本操作。這個行業存在一批專門為AI應用訓練資料的中間服供商,它們基於公開資料標註訓練的AI資料集確實存在同時被多個AI應用採用的情況。
不過業內基本操作在消費者層面可能不會得到同樣的理解和認同,此番谷歌Bard被曝使用ChatGPT的數據進行訓練也在國外引發軒然大波,不少網友指責谷歌是在盜竊OpenAI的成果。
包括網站資訊在內的網路公開資料很容易被技術手段抓取,這對搜尋引擎出身的Google更是小菜一碟。加上這樣的爆料來自谷歌剛離職的員工,可信度自然提升了一大截。
不過也有網友指出,Devlin離開GoogleAI團隊後轉而加入了競爭對手OpenAI,其爆料難免涉及商業利益,真實度有待進一步確認。
不過在極客網看來,不管這樣的事件真實度如何,都充分錶明一個「鐵律」:AI大模型領域真是一步落後步步落後,後來者想要趕上先發者是水平,非常不容易。
這背後的影響因素很多,包括演算法、算力,以及訓練資料的品質等。更重要的是,先發的AI大模型在探明成功之路後,便會一直訓練、一直進化,不會停下來等待追趕者。
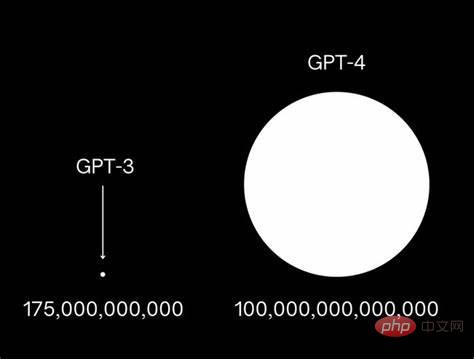
正因為如此,OpenAI的GPT已經很快由GPT-3升級到了GPT-4時代,為此還引發了包括馬斯克在內的多位名人聯名發佈公開信,呼籲大公司暫停大模型的研發速度,避免威脅人類。
李彥宏先前面對媒體訪談時也表示,儘管在某些領域表現更出色,整體看百度文心一言與OpenAI ChatGPT的水平還有一兩個月的差距。他同時指出,ChatGPT早期剛推出時外界回饋比文心一言還要糟糕。
對於GoogleBard來說,還有一個不利消息是據傳谷歌的Brain 人工智慧團隊正在與另一家隸屬於Alphabet 的人工智慧公司DeepMind 合作,共同進行一個代號為Gemini 的新項目,目標是開發出一個能與OpenAI的GPT競爭的產品。這似乎在暗示,Google對Bard並不自信,希望開發更領先的AI大模型,打造更先進的AI聊天機器人。
以上是Google也乾了? Bard被曝使用ChatGPT的資料進行訓練 大模型真是一步落後步步落後的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















