
本文討論使用LazyPredict來建立簡單的ML模型。 LazyPredict創建機器學習模型的特點是不需要大量的程式碼,同時在不修改參數的情況下進行多模型擬合,從而在眾多模型中選出性能最佳的一個。
本文討論使用LazyPredict來建立簡單的ML模型。 LazyPredict創建機器學習模型的特點是不需要大量的程式碼,同時在不修改參數的情況下進行多模型擬合,從而在眾多模型中選出性能最佳的一個。

本文包含的內容如下:
LazyPredict號稱最先進的Python軟體包,它的誕生正在徹底改變機器學習模型的開發方式。透過使用LazyPredict,可以快速建立各種基本模型,幾乎不需要任何程式碼,從而騰出時間來選擇最適合我們資料的模型。
LazyPredict的主要優點是可以讓模型選擇更加容易,而不需要對模型進行大量的參數調整。 LazyPredict提供了一種快速有效的方法來尋找和適配資料的最佳模型。
接下來,讓我們透過這篇文章來探索和學習更多關於LazyPredict的用法。
LazyPredict函式庫的安裝是一項非常簡單的任務。如同安裝任何其他Python庫一樣,只需一行程式碼輕鬆搞定。
!pip install lazypredict
在這個例子中,我們將利用Sklearn套件中的乳癌資料集。
現在,讓我們來載入資料。
from sklearn.datasets import load_breast_cancer from lazypredict.Supervised import LazyClassifier data = load_breast_cancer() X = data.data y= data.target
為了選擇最佳分類器模型,現在讓我們部署"LazyClassifier "演算法。這些特徵和輸入參數適用於此類別。
LazyClassifier( verbose=0, ignore_warnings=True, custom_metric=None, predictions=False, random_state=42, classifiers='all', )
接著把該模型套用到載入好的資料並進行擬合。
from lazypredict.Supervised import LazyClassifier from sklearn.model_selection import train_test_split # split the data X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state =0) # build the lazyclassifier clf = LazyClassifier(verbose=0,ignore_warnings=True, custom_metric=None) # fit it models, predictions = clf.fit(X_train, X_test, y_train, y_test) # print the best models print(models)
執行上述程式碼之後,得到下面結果:
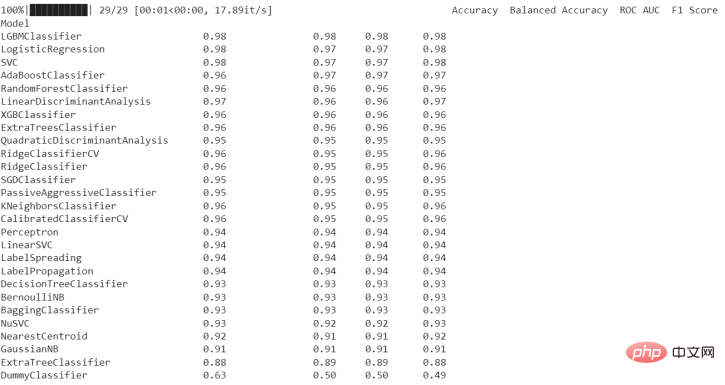
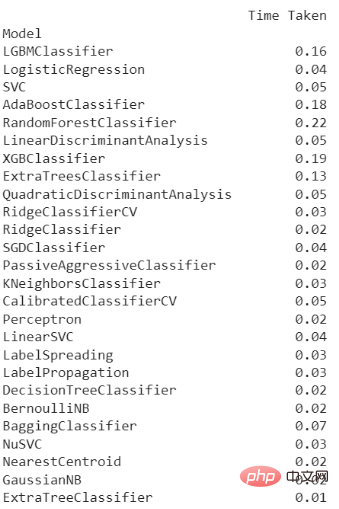
然後,我們可以進行以下工作,來看看模型的細節。
model_dictionary = clf.provide_models(X_train,X_test,y_train,y_test)
接下來,設定模型的名稱來顯示詳細的步驟資訊。
model_dictionary['LGBMClassifier']

在這裡,我們可以看到SimpleImputer被用於整個資料集,然後是StandardScaler用於數字特徵。在這個資料集中沒有分類或序數特徵,但如果有,就會分別使用OneHotEncoder和OrdinalEncoder。 LGBMClassifier模型在轉換和歸類後接收資料。
LazyClassifier的內部機器學習模型使用sci-kit-learn工具箱進行評估和擬合。 LazyClassifier函數在被呼叫時,會在我們的資料上自動建立和擬合各種模型,包括決策樹、隨機森林、支援向量機等。你提供的一組性能標準,如準確率、回想率或F1得分,都用來評估這些模型。訓練集用於擬合,而測試集則用於評估。
在對模型進行評估和擬合後,LazyClassifier會提供一份評估結果總結(如上表),以及每個模型的頂級模型和效能指標清單。由於不需要手動調整或選擇模型,你可以快速簡單地評估許多模型的性能,並選擇最適合數據的模型。
使用"LazyRegressor "函數,可以再次為迴歸模型完成相同的工作。讓我們匯入一個適合回歸任務的資料集(使用波士頓資料集)。
現在,讓我們使用LazyRegressor來擬合我們的資料。
from lazypredict.Supervised import LazyRegressor from sklearn import datasets from sklearn.utils import shuffle import numpy as np # load the data boston = datasets.load_boston() X, y = shuffle(boston.data, boston.target, random_state=0) X = X.astype(np.float32) # split the data X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state =0) # fit the lazy object reg = LazyRegressor(verbose=0, ignore_warnings=False, custom_metric=None) models, predictions = reg.fit(X_train, X_test, y_train, y_test) # print the results in a table print(models)
程式碼執行結果如下:
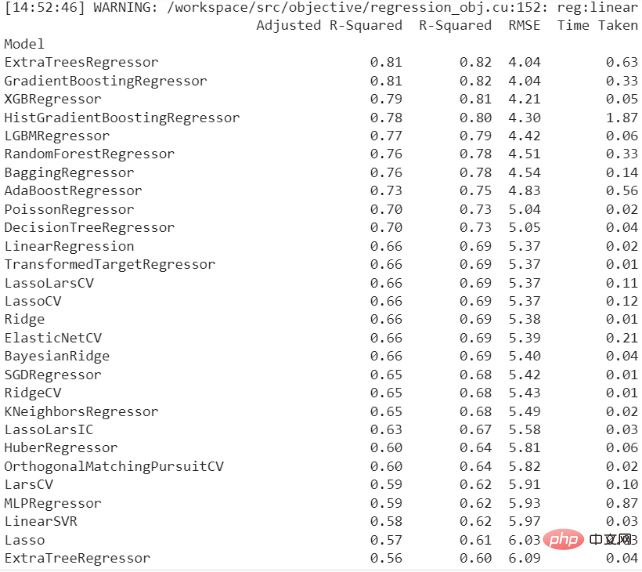
以下是对最佳回归模型的详细描述:
model_dictionary = reg.provide_models(X_train,X_test,y_train,y_test) model_dictionary['ExtraTreesRegressor']

这里可以看到SimpleImputer被用于整个数据集,然后是StandardScaler用于数字特征。这个数据集中没有分类或序数特征,但如果有的话,会分别使用OneHotEncoder和OrdinalEncoder。ExtraTreesRegressor模型接收了转换和归类后的数据。
LazyPredict库对于任何从事机器学习行业的人来说都是一种有用的资源。LazyPredict通过自动创建和评估模型的过程来节省选择模型的时间和精力,这大大提高了模型选择过程的有效性。LazyPredict提供了一种快速而简单的方法来比较几个模型的有效性,并确定哪个模型系列最适合我们的数据和问题,因为它能够同时拟合和评估众多模型。
阅读本文之后希望你现在对LazyPredict库有了直观的了解,这些概念将帮助你建立一些真正有价值的项目。
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
原文标题:LazyPredict: A Utilitarian Python Library to Shortlist the Best ML Models for a Given Use Case,作者:Sanjay Kumar
以上是LazyPredict:為你選擇最佳ML模型!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















