
AI面試機器人透過利用靈犀智慧語音語意平台的人機語音對話能力模擬招募者與求職者進行多輪語音溝通,達到線上化面試的效果。本文詳細描述了AI面試機器人的後端架構組成、對話引擎設計、資源需求預估策略、服務效能最佳化方法。 AI面試機器人上線一年多來,累積接待了 百萬 次面試請求,大幅提升了招募者招募效率、求職者面試體驗。
58同城生活服務平台包括房產、汽車、招聘、本地服務(黃頁)四大老牌業務,平台連接著海量的C端用戶和B端商家, B端商家可以在平台上發布房源、車源、職位、生活服務等各類資訊(我們稱之為「貼文」),平台將這些貼文分發給C端用戶供其瀏覽從而幫助他們取得自己所所需的訊息,幫助B端商家分發傳播訊息從而獲取目標客戶,為了提升B端商家獲取目標客戶效率,提升C端用戶體驗,平台在個性化推薦、智慧化連接等方面持續地在進行著產品創新。
以招募為例,受2020年疫情的影響,傳統的線下招募面試方式受到了較大的衝擊,平台上求職者透過微聊、影片等線上化面試請求量急增,由於一位招募者在同一時刻只能與一位求職者建立線上化的視訊面試管道,導致求職者、招募者兩端連結成功率較低。為了提升求職者使用者體驗、提升招募者面試效率,58同城TEG AI Lab與招募業務線等多個部門協同打造了一款智慧化招募面試工具:神奇面試間。本產品主要由三個人組成:客戶端、音訊視訊通訊、AI面試機器人(請參閱: 人物|李忠:AI面試機器人打造智慧化招募 )。
本文將主要聚焦在AI面試機器人上,AI面試機器人透過利用靈犀智能語音語意平台的人機語音對話的能力模擬招募者與求職者進行多輪語音溝通,達到線上化面試的效果。一方面可解決一位招募者只能回應一位求職者的線上化面試要求,提升招募者作業效率;另一方面能滿足求職者不限時間、地點進行視訊面試,同時將個人履歷從傳統的文字描述介紹轉換成更直觀生動的視頻化自我展示。本文詳細描述了AI面試機器人的後端架構組成、人機語音對話引擎設計、如何預估資源需求應對流量擴容、如何優化服務性能來保證整體AI面試機器人服務的穩定性、可用性。
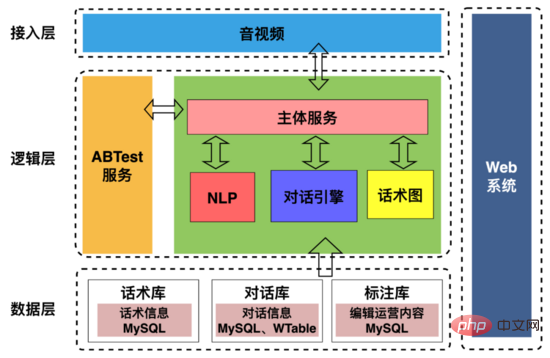
AI面試機器人架構如上圖所示,包括:
1、存取層:主要用來處理與上下游的交互,包括與音視頻端約定通信協議;提取面試中用戶畫像、抽取機器人用戶交互時間軸信息下發招聘部門。
2、邏輯層:主要是用來處理機器人和用戶的對話交互,包括將機器人的問題文本合成為語音數據發送給用戶,對用戶進行提問,讓機器人可以“ 說得出 ” ;用戶回覆後,將用戶回覆語音數據透過VAD(Voice Activity Detection)斷句,串流語音辨識為文本,讓機器人「 聽得見 」;對話引擎根據用戶的回覆文字和話術圖決定回覆內容然後合成語音發送給用戶,從而實現機器人和用戶的「 溝通交流 」。
3、資料層:存放話術圖、對話記錄、標註資訊等基礎資料。
4、web系統:視覺化配置話術結構、對話策略、標註面試對話資料。
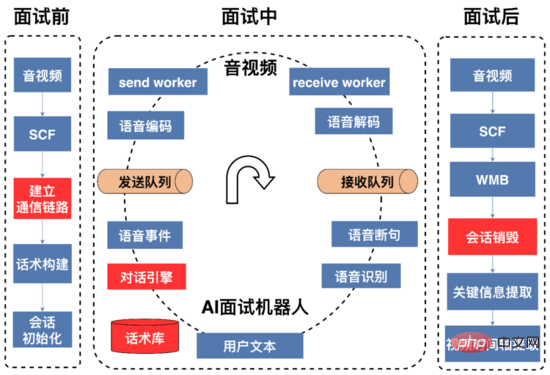
一次完整的AI面試流程如上圖所示,可以被劃分為面試前、面試中、面試後三階段。
面試前: 主要是建立通訊連結以及資源初始化,AI面試機器人與影音端的語音訊號是透過 UDP 傳送的,音訊視訊與AI面試機器人通訊所需的 IP 和 連接埠 是需要動態維護。音視頻端透過SCF(SCF是58自主研發的RPC框架)介面發起面試請求,該請求一方面從AI面試機器人處實時動態獲取IP與端口資源用於音視頻後續將此次面試過程的採集到的語音訊號發到AI機器人,另一方面告訴AI機器人需要將響應用戶的語音訊號所需要發送的IP與端口,由於SCF支援負載平衡,所以音視訊端發起的面試請求會隨機打到AI面試機器人服務叢集上某台機器,這時候這台機器上的AI面試機器人透過SCF透傳的參數獲取到音視頻端的ip和端口,接下來AI面試機器人服務首先嘗試從 可用端口隊列 (服務初始化的時候創建的該隊列,以隊列的資料結構存放可用的連接埠對)中poll第一個可用連接埠對(發送連接埠和接收連接埠組成的pair),如果取得成功,服務會把這台機器的IP和連接埠通過SCF面試請求介面回傳給音視訊端,後續雙方就可以進行UDP通訊了,面試完成後,服務會把連接埠對push到可用埠佇列。如果取得連接埠對失敗,服務會透過SCF介面傳回給音訊視訊端建立通訊失敗代碼,音訊端可以重試或放棄此面試請求。
建立通訊流程:
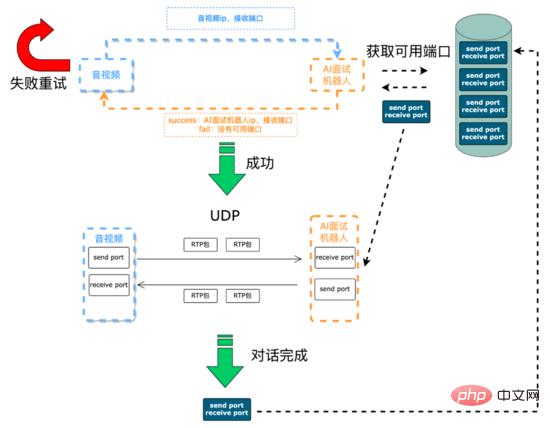
在語音訊號傳輸過程,在系統中我們採用了RTP協定作為音訊媒體協定。 RTP協定 即即時傳輸協定(Real-time Transport Protocol),為ip網路語音、影像、傳真等多種需要即時傳輸的多媒體資料提供 端對端 的即時傳輸服務。 RTP封包由兩部分組成:標頭和有效載荷。
RTP標頭:
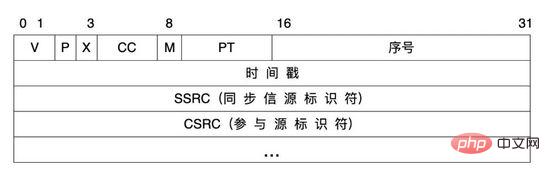
屬性解釋:
| ##屬性 | 解釋 |
| V | RTP 協定版本的 版本號 ,佔 2 位,目前協定版本號碼為 2 |
| P | |
| ###################################填入標誌 ,佔 1 位,如果 P=1 ,那麼該封包的尾部填入一個或多個額外的 8 位數組,則它們不是有效載荷的一部份################ ###X### | 擴充標誌 ,佔 1 位,若 X=1 ,則在 RTP 標頭後面跟著一個擴充標頭 |
CC |
參與源數, CSRC 計數器,佔 4 位,指示 CSRC 標識符的數量 |
M |
標記,佔 1 位,不同載荷有不同的含義,對於視頻,標記一幀的結束;對於音頻,標記會話的開始。 |
PT |
#酬載類型,佔 7 位,用於說明 RTP 封包中酬載的類型,如音訊、影像等,在串流媒體中大部分是用來區分音訊串流和視訊串流的,以便於客戶端解析。 |
序號 |
#佔 16 位,用來識別發送者所寄送 RTP 封包的序號, 每寄一張報文 ,序號增加 1 。這個字段當下層的承載協定用 UDP 的時候,網路情況不好的時候可以用來 檢查丟包 。同時網路出現抖動可以用來對資料進行重新排序。 |
時間戳記 |
#佔 32 位,反應了該 RTP 封包的 第一個八位組的取樣時刻 ,接收者可以用時間戳來計算延遲和延遲抖動,並進行同步控制。 |
SSRC |
#用於識別同步訊號源 ,該標識可以隨機選擇,參加同一個視訊會議兩個同步訊號源不能有相同的 SSRC |
CSRC |
每個 CSRC 識別碼佔 32 位,可以有 0 ~ 15 個。每個 CSRC 標示了包含在該 RTP 封包酬載中的所有特約信源。 |
面試中: 在此過程中,AI面試機器人首先發送開場白,開場白文本透過tts(Text To Speech)合成為語音數據,語音數據經過編碼,進行壓縮,發送到約定好的音視頻端的IP和端口,用戶根據聽到的問題進行相關回复;AI面試機器人將接收到的用戶語音流進行解碼,通過vad斷句、流式語音識別為文本,對話引擎根據用戶回复文本和話術結構狀態圖決定回复內容,AI面試機器人和用戶不斷對話交互,直到話術結束或用戶掛斷面試。
面試後: 一旦AI面試機器人收到影音關於面試結束的請求,AI面試機器人將回收面試準備階段申請的資源如端口、線程等;構建用戶的畫像(涉及到用戶最快到崗時間、是否從事過該工作、年齡等資訊)提供給招募方,方便商家進行篩選,以及對面試對話進行錄音儲存。
錄音方案:
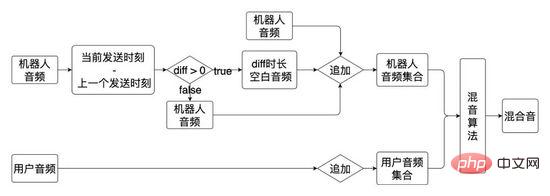
在整個面試流程中AI面試機器人和使用者互動是由 對話引擎基於話術流程 驅動的,其中話術是一個有向無環圖,最初話術圖是兩分支話術(所有節點的邊
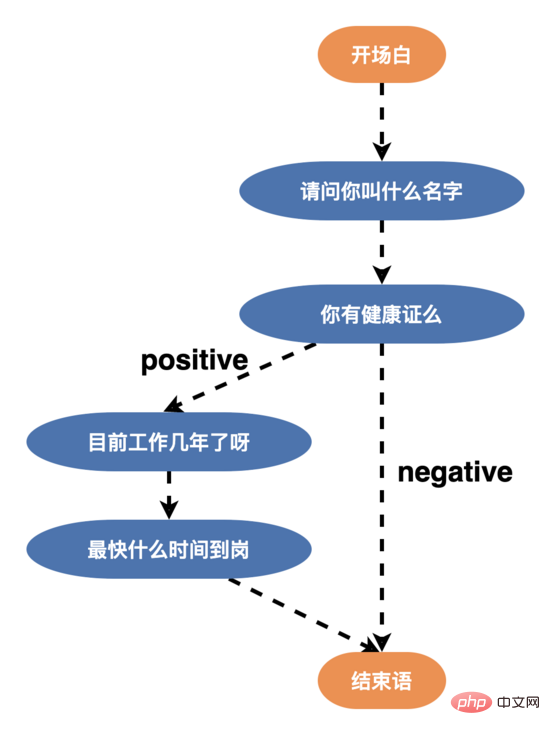
因此為了提高使用者的對話意願,提升機器人的智慧對話能力,我們重構了話術結構,設計了多分支話術(某個節點的邊>= 3),如下所示,使用者可以根據年齡、學歷、個性個人化地回覆使用者不同的話術,新話術結構上線後,面試完成率超過了 50% 。
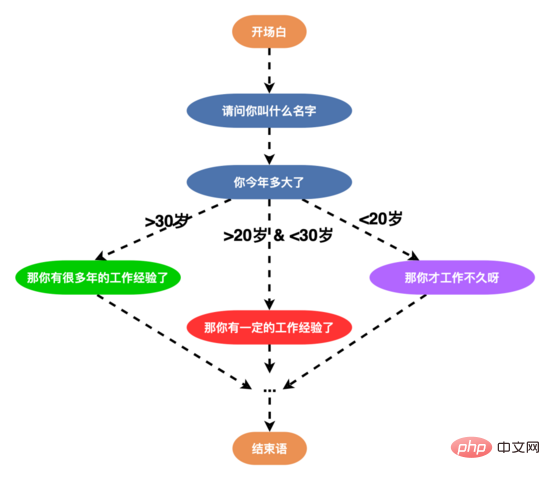
同時為了更細緻地設計對話策略,我們在策略鏈上設計了 節點級 的策略鏈,可以為單一節點客製化個人化的對話策略,滿足個性化的對話需求。
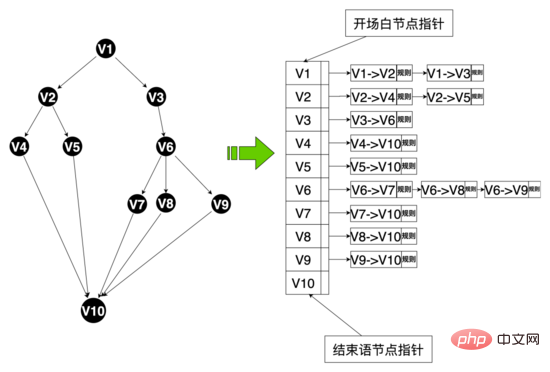
資料層面: 為了實現多分支話術,我們重新設計了話術相關的資料結構,抽象化一些資料實體包括:話術表、話術節點、話術邊等。話術節點透過話術編號綁定到話術上,同時維護話術文本等屬性,話術邊維護節點之間的拓撲關係,有開始節點、結束節點,話術邊透過邊編號綁定這個邊上的命中正規、語料等規則,同時可以使用邊id為這個邊自訂自己的規則。策略鏈透過策略鏈編號綁定不同的策略,話術、節點透過策略鏈編號綁定不同的策略鏈。
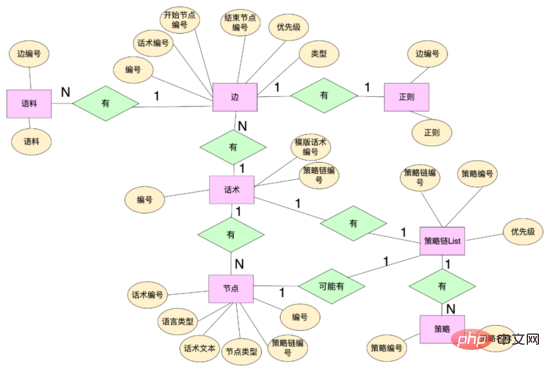
程式碼層面: 抽象化邊、節點、話術類別、話術狀態類別概念,邊和節點是資料層的映射,邊上也維護了正規、語料等命中邏輯,話術類維護了開場白節點、話術圖等關鍵信息,話術圖是整個話術拓撲結構的映射,維護了節點和以該節點為開始節點邊集合的映射,話術狀態類別維護了話術的當前狀態,包括話術類別和當前節點,系統可以根據話術當前節點,從話術圖中獲取到以該節點為開始節點的所有邊(類似 鄰接表 ),根據用戶當前的回復去匹配不同邊上的規則,如果命中,那麼話術圖就流轉到命中邊的結束節點,同時從該節點上獲取機器人的回复內容,話術結構就流轉起來了。
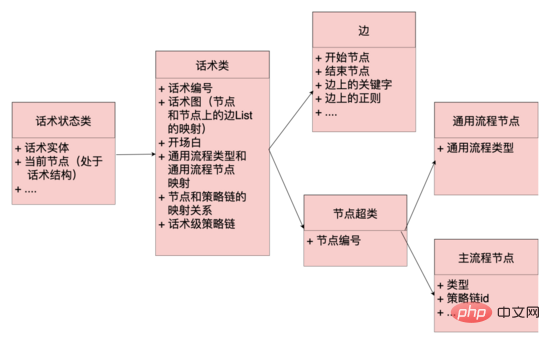
話術圖資料結構:
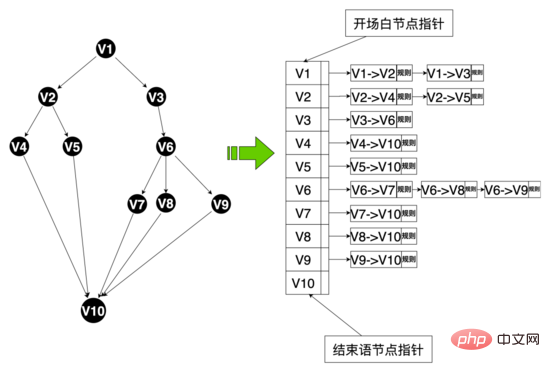
透過以上資料結構,系統平台能快速回應業務方的話術客製化需求,例如招募方可以自訂每個招募職位的問題,我們將這些問題抽象化為話術中的虛擬節點,使用虛擬邊將虛擬節點連結起來,從而為不同職位提供個人化的面試問題,實現千人千面的效果。
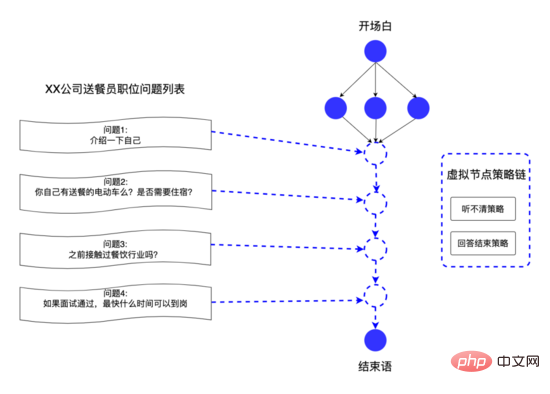
神奇面試間上線後效果良好,因此業務方希望進行快速擴量,AI面試機器人需要支援最高同時線上千人以上,因此我們從資源管理、資源預估、性能試驗、監控四方面入手,有效提升了AI面試機器人服務的性能,線上實際使用中,優化後服務可同時接待的面試請求能力為優化前 20倍 。
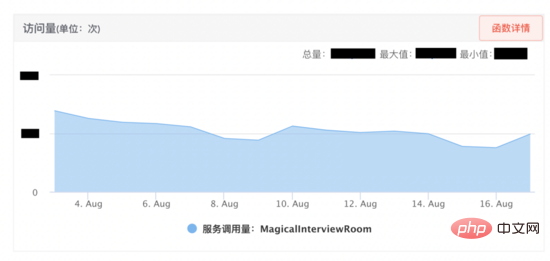
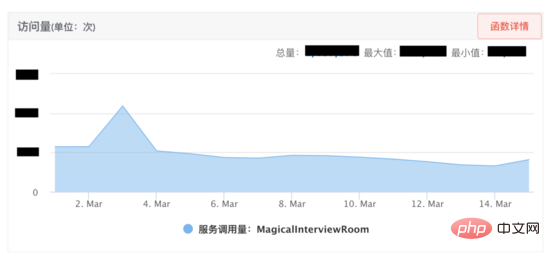
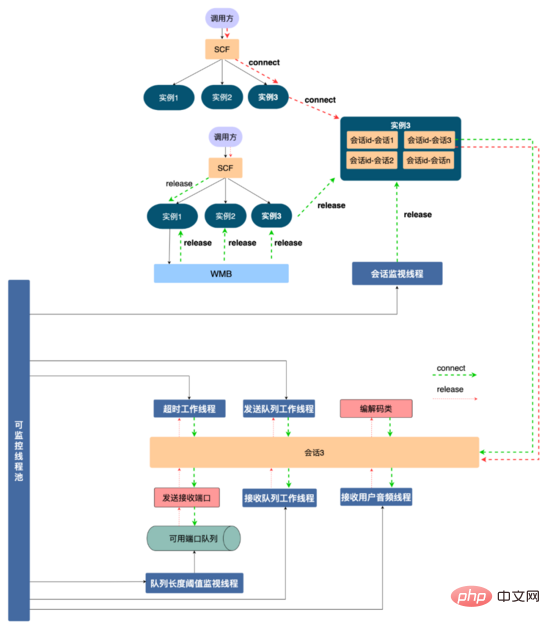
資源管理方案: 為了更好地管理服務中所使用的資源,防止資源耗盡,我們設計瞭如下所示的資源管理方案。首先AI面試機器人跟音視訊是透過SCF約定通訊協議,由於SCF是負載平衡的,所以呼叫方請求會 隨機 打到叢集中某台機器上,例如某一次請求打到服務實例1,通訊協定可以將這次面試的交互綁定到該實例,接下來是抽象化一個 會話 的概念(代碼層面是一個會話類,每一個會話是一個線程),將這一通面試中申請的資源例如發送接收端口、編解碼類別、各種執行緒資源註冊到會話上,在程式碼上保證釋放會話時一定釋放註冊在會話上的資源,這樣不同視訊面試透過 執行緒的隔離性 實現了資源隔離,從而方便進行資源管理。
同時透過會話id(呼叫方透過通訊協定約定好的,具有全域唯一性)將會話實例綁定到會話容器上。使用者掛斷的時候呼叫SCF釋放資源,由於SCF的隨機性,請求可能打到服務實例3,實例3上是沒有這次面試的會話,為了釋放資源,我們使用WMB(五八同城自研訊息佇列) 廣播 這個釋放資源訊息,訊息體內含有會話id,所有服務實例都會消費到這一訊息,而服務實例1含有該會話id,找到與會話id綁定的會話,呼叫會話的資源釋放功能,將會使用到的資源釋放(其餘實例會丟棄該訊息)。
如果因為某些原因釋放請求沒有執行,會話容器有一個 會話監視執行緒 ,可以掃描會話容器中所有會話的生命週期,為會話設定一個最大的生命週期(例如10分鐘),如果會話過期,主動觸發會話的資源回收,釋放會話資源。同時對於會話中申請的線程、連接埠等有限資源,我們使用 集中式 管理,並使用執行緒池對執行緒集中管理,將所有可用連接埠放入到一個佇列中,對佇列剩餘連接埠進行監控,以確保服務的穩定性和可用性。
機器資源預估:
限制資源 |
瓶頸關注點 |
#會話申請的暫存資源 |
臨時資源是否可以及時回收,例如連接埠、執行緒、編解碼類別等資源。 |
機器網路頻寬 |
#1000MB/s >> 2500 * 32 KB/s |
#機器硬碟資源 |
商家自訂問題 LRU 淘汰策略 |
#執行緒 |
執行緒池佇列中任務大小、任務執行耗時、建立執行緒數量監控等指標 |
效能實驗:
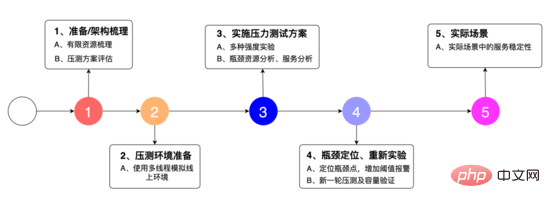
我們設計如上圖所示的實驗方案: 1、是對系統的架構進行梳理,發現其中有限的資源,同時整理壓力測試方案,2、是使用多執行緒模擬線上環境,3、是多種強度的強度試驗,瓶頸資源的分析,服務的分析。 4、定位瓶頸點,增加閾值警報,重新試驗,5、是在實際場景中的服務的穩定性表現。
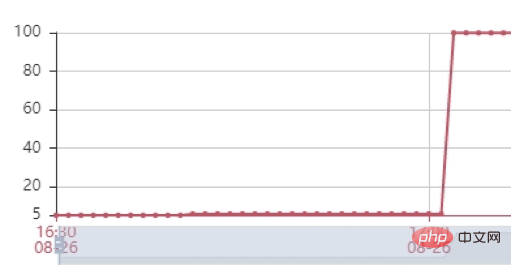
壓力測試: 接下來我們進行壓力測試,嘗試多種強度請求量試驗,當使用2500請求/min對介面進行壓力測試,發現服務的主要瓶頸是在服務的 堆記憶體 上。從下圖可以看到服務的堆疊記憶體很快到達100%,介面無回應。我們dump堆內存後發現堆內存中出現幾百個DialingInfo對象,每個對象佔用18.75MB,查看代碼可知,這個對象使用來存放AI面試機器人和用戶的對話內容,allRobotVoiceBuffer和allUserVoiceBuffer兩個對象各自佔用一半的記憶體大小,allRobotVoiceBuffer是存放機器人的語音訊息(存放形式:byte陣列),allUserVoiceBuffer是存放使用者的語音訊息。
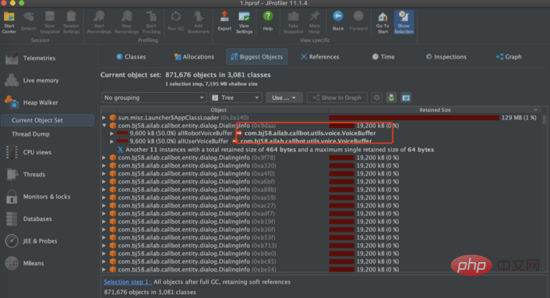
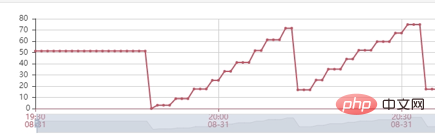
檢視程式碼可以發現allRobotVoiceBuffer和allUserVoiceBuffer這兩個物件 初始化 服務的時候就共同佔用了18.75MB(這個數值是因為要存放5min的音訊數據),我們需要考慮這個初始化大小是否合理,分析神奇面試間歷史通話數據,可以看出來 63% 的用戶沒有回答機器人第一個問題直接掛斷面試,因此我們嘗試降低這兩個物件初始化記憶體大小,將allRobotVoiceBuffer修改為0.47MB(這個數值為機器人第一個問題音訊的大小),allUserVoiceBuffer為0MB,同時由於allRobotVoiceBuffer和allUserVoiceBuffer這兩個物件可以ms等級擴充,如果對話內容超過物件大小可以實現擴容不影響服務,修改後我們仍然使用2500min/請求去壓力測試,服務可以實現穩定的垃圾回收。
細粒度的監控:
指標類型 |
概述 |
#服務關鍵性指標 |
請求量、成功量、失敗量、沒有可用埠等 13 個指標 |
資源性指標 |
可用埠佇列長度小於閾值、快取個人化問題超過閾值等 5 個指標 |
流程性指標 |
建構話術失敗、下發關鍵資訊失敗、下發時間軸失敗等 52 個指標 |
執行緒池監控指標 |
#要求建立執行緒數量、正在執行的任務數量、任務平均耗時 6一個指標 |
職位問答環節指標 |
#取得語音答案異常、答案預熱平均耗時等 9 個指標 |
ASR 指標 |
#自研語音辨識平均時長、自研辨識失敗等 18 個指標 |
Vad 指標 |
#呼叫次數、最大耗時等 4 個指標 |
本 文主要介紹了AI面試機器人的後端架構,AI面試機器人和用戶的互動全流程,對話引擎的核心功能以及服務效能優化實踐等工作。 後續我們將持續支援神奇面試間專案的功能迭代以及效能優化,進一步將AI面試機器人落地到不同的業務。
1、RTP: A Transport Protocol for Real-Time Applications. H. Schulzrinne R. Frederick S. Casner V. Jacobson
張馳, 58 同城 AI Lab 後端資深開發工程師, 2019 年 12 月加入 58 同城,目前主要從事語音互動相關的後端研發工作。 2016 年碩士畢業於北方工業大學,曾就職於便利蜂、中國電子,從事後端開發工作。
以上是AI面試機器人後端架構實踐的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















