

影像大面積缺失,也能逼真修復,新模型CM-GAN兼顧全域結構與紋理細節

影像修復是指對影像缺失區域進行補全,是電腦視覺的基本任務之一。該方向有許多實際應用,例如物體移除、影像重定向、影像合成等。
早期的修復方法是基於影像區塊合成或顏色擴散來填滿影像缺失部分。為了完成更複雜的影像結構,研究人員開始轉向數據驅動的方案,他們利用深度生成網路來預測視覺內容和外觀。透過在大量影像上進行訓練,並藉助重建和對抗損失,生成式修復模型已被證明可以在包括自然影像和臉部在內的各種類型輸入資料上產生更具視覺吸引力的結果。
然而,現有工作只能在完成簡單的圖像結構方面顯示出良好的結果,生成整體結構複雜和細節高保真的圖像內容仍然是一個巨大的挑戰,特別是當影像空洞(hole)很大的時候。
從本質上講,影像修復面臨兩個關鍵問題:一個是如何將全局上下文準確地傳播到不完整區域,另一個是合成與全局線索一致的真實局部細節。為了解決全域情境傳播問題,現有網路利用編碼器 - 解碼器結構、空洞卷積、脈絡注意力或傅立葉卷積來整合長程特徵依賴,擴大有效感受野。此外,兩階段方法和迭代空洞填充依靠預測粗略結果來增強全局結構。然而,這些模型缺乏一種機制來捕獲未遮罩區域的高級語義,並有效地將它們傳播到空洞中以合成一個整體的全局結構。
基於此,來自羅徹斯特大學和Adobe Research 的研究者提出了一種新的生成網絡:CM-GAN(cascaded modulation GAN),該網絡可以更好地合成整體結構和局部細節。 CM-GAN 中包含一個帶有傅立葉卷積塊的編碼器,用於從帶有空洞的輸入影像中提取多尺度特徵表徵。 CM-GAN 中還有一個雙流解碼器,該解碼器在每個尺度層都設定一個新型級聯的全域空間調變區塊。
在每個解碼器區塊中,研究者首先應用全域調變來執行粗略和語意感知的結構合成,然後進行空間調變來進一步以空間自適應方式調整特徵圖。此外,研究設計了一種物體感知訓練方案,以防止空洞內產生偽影,從而滿足現實場景中物體移除任務的需求。該研究進行了廣泛的實驗表明,CM-GAN 在定量和定性評估方面都顯著優於現有方法。

- 論文網址:https://arxiv.org/pdf/2203.11947.pdf
- #專案位址:https://github.com/htzheng/CM-GAN-Inpainting
#我們先來看看圖片修復效果,與其他方法相比, CM-GAN 可以重建更好的紋理:

#CM-GAN 可以合成更好的全域結構:

CM-GAN 具有更好的物件邊界:

下面我們來看下該研究的方法和實驗結果。
方法
級聯調變 GAN
為了更好地建模影像補全的全域上下文,該研究提出一種將全域碼調變與空間碼調變級聯的新機制。此機制有助於處理部分無效的特徵,同時更好地將全域上下文注入空間域內。新架構 CM-GAN 可以很好地綜合整體結構和局部細節,如下圖 1 所示。

如下圖2(左) 所示,CM-GAN 是基於一個編碼器分支和兩個並行級聯解碼器分支來產生視覺輸出。編碼器以部分影像和遮罩為輸入,產生多尺度特徵圖 。
。
與大多數編碼器- 解碼器方法不同,為了完成整體結構,該研究從全連接層的最高級別特徵 中提取全局樣式代碼s,然後進行
中提取全局樣式代碼s,然後進行 歸一化。此外,基於 MLP 的映射網路會從雜訊中產生樣式代碼 w,以模擬影像產生的隨機性。代碼 w 與 s 結合產生一個全域代碼 g = [s; w],用於之後的解碼步驟。
歸一化。此外,基於 MLP 的映射網路會從雜訊中產生樣式代碼 w,以模擬影像產生的隨機性。代碼 w 與 s 結合產生一個全域代碼 g = [s; w],用於之後的解碼步驟。
全域空間級聯調變。為了在解碼階段更好地連接全局上下文,研究提出了全局空間級聯調製 (CM,cascaded modulation)。如圖 2(右)所示,解碼階段是基於全域調變區塊(GB)和空間調變區塊(SB)兩個分支,並行上取樣全域特徵 F_g 和局部特徵 F_s。

與現有方法不同,CM-GAN 引進了一種將全域情境注入空洞區域的新方法。在概念層面上,它由每個尺度的特徵之間的級聯全局和空間調製組成,並且自然地集成了全局上下文建模的三種補償機制:1)特徵上採樣;2) 全局調製;3 )空間調製。
物體感知訓練
為訓練產生遮罩的演算法至關重要。本質上,採樣的遮罩應該類似於在實際用例中繪製的遮罩,並且遮罩應避免覆蓋整個物體或任何新物體的大部分。過度簡化的遮罩方案可能會導致偽影。
為了更好地支援真實的物體移除用例,同時防止模型在空洞內合成新物體,該研究提出了一種物體感知訓練方案,在訓練期間生成了更真實的掩碼,如下圖4 所示。

具體來說,研究首先將訓練影像傳遞給全景分割網路PanopticFCN 以產生高度準確的實例級分割註釋,然後對自由空洞和物體空洞的混合進行採樣作為初始掩碼,最後計算空洞和圖像中每個實例之間的重疊率。如果重疊率大於閾值,則該方法將前景實例從空洞中排除;否則,空洞不變並模擬物體完成,其中閾值設為 0.5。研究隨機擴展和平移物體遮罩以避免過度擬合。此外,該研究還擴大了實例分割邊界上的空洞,以避免將空洞附近的背景像素洩漏到修復區域。
訓練目標與 Masked-R_1 正則化
該模型結合對抗性損失和基於分割的感知損失進行訓練。實驗表明,該方法在純粹使用對抗性損失時也能取得很好的效果,但加入感知損失可以進一步提高性能。
#此外,該研究還提出了一種專門用於穩定修復任務的對抗性訓練的 masked-R_1 正則化,其中利用掩碼 m 來避免計算掩碼外的梯度懲罰。
實驗
該研究在Places2 資料集上以512 × 512 解析度進行了影像修復實驗,並給出了模型的定量和定性評估結果。
定量評估:下表 1 為 CM-GAN 與其他遮罩方法的比較。結果表明,CM-GAN 在 FID、LPIPS、U-IDS 和 P-IDS 方面明顯優於其他方法。在感知損失的幫助下,LaMa、CM-GAN 比 CoModGAN 和其他方法獲得了明顯更好的 LPIPS 分數,這歸功於預訓練感知模型提供的額外語義指導。與 LaMa/CoModGAN 相比,CM-GAN 將 FID 從 3.864/3.724 降低到 1.628。

如下表3 所示,在有無微調的情況下,CM-GAN 在LaMa 和CoModGAN 掩碼上都取得了明顯優於LaMa 和CoModGAN 的性能增益,表明該模型具有泛化能力。值得注意的是,在 CoModGAN 掩碼,物體感知掩碼上訓練的 CM-GAN 性能依然優於 CoModGAN 掩碼,證實了 CM-GAN 具有更好的生成能力。

定性評估:圖5、圖6、圖8 展示了CM-GAN 與SOTA 方法在合成掩碼方面的可視化比較結果。 ProFill 能夠產生不連貫的全域結構,CoModGAN 產生結構偽影和色彩斑點,LaMa 在自然場景上容易產生較大的影像模糊。相較之下,CM-GAN 方法產生了更連貫的語義結構、紋理更清晰,可適用於不同場景。






以上是影像大面積缺失,也能逼真修復,新模型CM-GAN兼顧全域結構與紋理細節的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 此 Apple ID 尚未在 iTunes Store 中使用:修復
Jun 10, 2024 pm 05:42 PM
此 Apple ID 尚未在 iTunes Store 中使用:修復
Jun 10, 2024 pm 05:42 PM
使用AppleID登入iTunesStore時,可能會在螢幕上拋出此錯誤提示「此AppleID尚未在iTunesStore中使用」。沒有什麼可擔心的錯誤提示,您可以按照這些解決方案集進行修復。修正1–更改送貨地址此提示出現在iTunesStore中的主要原因是您的AppleID個人資料中沒有正確的地址。步驟1–首先,開啟iPhone上的iPhone設定。步驟2–AppleID應位於所有其他設定的頂部。所以,打開它。步驟3–在那裡,打開“付款和運輸”選項。步驟4–使用面容ID驗證您的存取權限。步驟
 如何解決Win11驗證憑證失敗的問題?
Jan 30, 2024 pm 02:03 PM
如何解決Win11驗證憑證失敗的問題?
Jan 30, 2024 pm 02:03 PM
有win11用戶在使用憑證登入時,收到的卻是您的憑證無法驗證的錯誤提示,這是怎麼回事?小編調查此問題後,發現可能有幾種不同的情況直接或間接導致該問題,以下就和小編一起來看看吧。
 如何修復iPhone上的紅眼
Feb 23, 2024 pm 04:31 PM
如何修復iPhone上的紅眼
Feb 23, 2024 pm 04:31 PM
所以,你在上一次聚會上拍了一些很棒的照片,但不幸的是,你拍的大部分照片都是紅眼睛。照片本身很棒,但其中的紅色眼睛有點破壞了圖像。更不用說,其中一些派對照片可能來自您朋友的手機。今天,我們將看看如何從照片中去除紅眼。是什麼原因導致照片中的眼睛發紅?使用閃光燈拍照時,紅眼現象往往會出現。這是因為閃光燈的光線直接照射到眼睛後部,引起眼底血管反射光線,從而在照片中呈現紅色眼睛的效果。幸運的是,隨著技術的不斷進步,現在一些相機已經配備了紅眼修正功能,可以有效解決這個問題。透過使用此功能,相機會在拍照
 PHP 500錯誤全面指南:原因、診斷與修復
Mar 22, 2024 pm 12:45 PM
PHP 500錯誤全面指南:原因、診斷與修復
Mar 22, 2024 pm 12:45 PM
PHP500錯誤全面指南:原因、診斷與修復在PHP開發過程中,我們常會遇到HTTP狀態碼為500的錯誤。這種錯誤通常被稱為"500InternalServerError",它是指在伺服器端處理請求時發生了一些未知的錯誤。在本文中,我們將探討PHP500錯誤的常見原因、診斷方法以及修復方法,並提供具體的程式碼範例供參考。 1.500錯誤的常見原因1.
 解決Win11藍屏問題的簡易指南
Dec 27, 2023 pm 02:26 PM
解決Win11藍屏問題的簡易指南
Dec 27, 2023 pm 02:26 PM
很多朋友在使用電腦作業系統時,總會出現藍屏的狀況,就算是最新的win11系統,也難逃藍屏的命運,因此今天小編帶來了win11藍屏修復教程。無論大家有沒有遇過藍屏,都可以先學習一下,以備不時之需。 win11藍屏怎麼修復方法一1、如果我們如果遇到了藍屏,先重啟系統,查看是否能夠正常啟動。 2、可以正常啟動的話,右鍵點擊桌面上的“電腦”,選擇“管理”3、接著在彈出視窗左側展開“系統工具”,選擇“事件檢視器”4、在事件檢視器中,我們就可以看到具體是什麼問題導致的藍色畫面。 5.接著只要依照藍屏的狀況以及事
 WIN10音量無法調整進行修復的操作方法
Mar 27, 2024 pm 05:16 PM
WIN10音量無法調整進行修復的操作方法
Mar 27, 2024 pm 05:16 PM
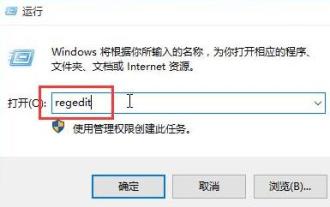
1.按win+r開啟運行窗口,輸入【regedit】回車,開啟註冊表編輯器。 2.在開啟的登錄編輯程式中,依序點選展開【HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindowsCurrentVersionRun】,在右側空白處,點選右鍵選擇【新建-字串值】,並重新命名為【systray.exe】。 3.雙擊開啟systray.exe,將其數值資料修改為【C:WindowsSystem32systray.exe】,點選【確定】儲存設定。
 如何解決csrss.exe導致的藍色畫面問題
Dec 28, 2023 pm 06:24 PM
如何解決csrss.exe導致的藍色畫面問題
Dec 28, 2023 pm 06:24 PM
若您的電腦啟動後常出現藍色畫面現象,伴隨而來的可能是Windows系統對csrss.exe檔產生的嚴重錯誤(停止碼為0xF4)。現在就讓我們來看看它怎麼修復吧! csrss.exe藍色畫面如何修正先同時按"Ctrl+Alt+Del"按鍵,這時將會跳出來自MicrosoftWindows工作管理員的介面。點選「任務管理器」的選項卡,畫面列出所有正在執行的程式以及它們所佔用的資源狀況等資訊。再次點擊進入“進程”選項卡,再次點擊“映像名稱”,然後在該清單中找到"csrss.exe"檔案。點擊「結束進程」的按鈕
 修復因為網卡驅動程式異常導致無法上網的方法
Jan 06, 2024 pm 06:33 PM
修復因為網卡驅動程式異常導致無法上網的方法
Jan 06, 2024 pm 06:33 PM
有的朋友發現自己的電腦因為網卡驅動程式不正常上不了網,想要知道怎麼修復,其實現在的系統都自帶驅動程式修復功能,因此我們只需要手動更新一下驅動程式就可以了,實在不行還能使用驅動軟體。網路卡驅動程式不正常上不了網怎麼修復:PS:如果突然出現的這個問題,可以先試試看重啟電腦喲~重啟後還不行在繼續下面的操作。方法一:1、首先,點選工作列中的右鍵,選擇「開始功能表」2、在右鍵選單中開啟「裝置管理員」。 3.點選“網路介面卡”,然後選擇“更新驅動程式”點擊“自動搜尋驅動程式”後,更新完成即可正常上網5、也有些用戶是因
