
隨著機器學習模型在預測和分析資料方面變得越來越流行,隨機森林演算法的使用正在獲得動力。隨機森林是一種監督學習演算法,用於機器學習領域的回歸和分類任務。它的工作原理是在訓練時建立大量決策樹並輸出類,即類的模式(分類)或單一樹的平均預測(回歸)。
在本文中,我們將討論如何使用線上真實資料集實作隨機森林演算法。我們還將提供詳細的程式碼解釋和每個步驟的描述,以及對模型效能和視覺化的評估。
我們將使用的資料集是“Breast Cancer Wisconsin (Diagnostic) Dataset”,它是公開可用的,可以透過 UCI 機器學習儲存庫存取。該資料集有 569 個實例,具有 30 個屬性和兩個類別—惡性和良性。我們的目標是根據 30 個屬性對這些實例進行分類,並確定它們是良性還是惡性。您可以從https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data下載資料集。
首先,我們將匯入必要的函式庫:
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
接下來,我們將載入資料集:
df = pd.read_csv(r"C:UsersUserDownloadsdatabreast_cancer_wisconsin_diagnostic_dataset.csv") df
輸出:
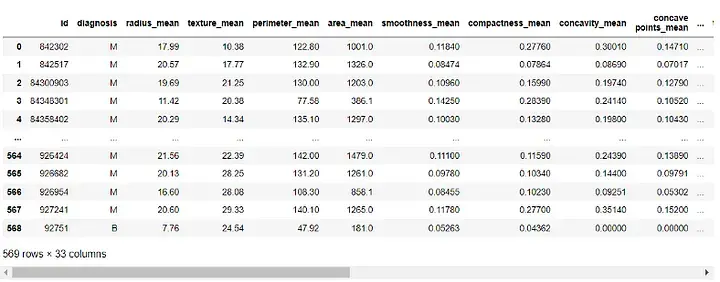
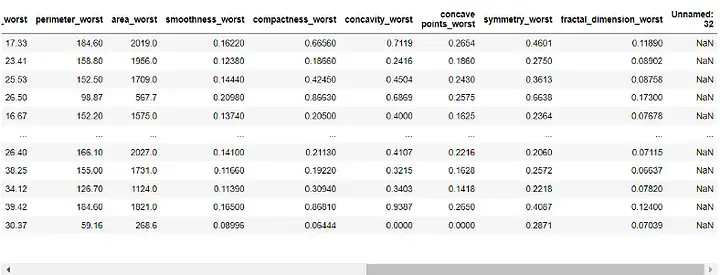
在建立模型之前,我們需要先對資料進行預處理。由於'id' 和'Unnamed: 32' 列對我們的模型沒有用,我們將刪除它:
df = df.drop([ 'id' , 'Unnamed: 32' ], axis=1) df
輸出:
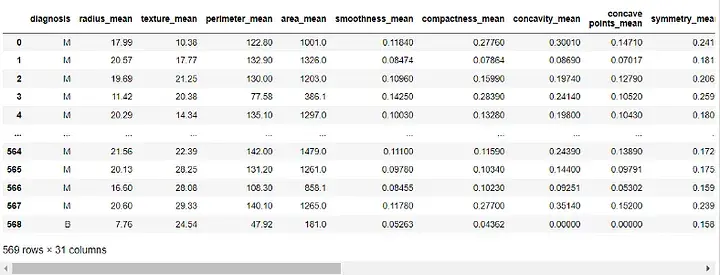
#接下來,我們將把「診斷」列分配給我們的目標變數並將其從我們的特徵中刪除:
target = df['diagnosis']
features = df.drop('diagnosis', axis=1)我們現在將把我們的資料集分成訓練集和測試集。我們將使用70% 的資料進行訓練,30% 的資料用於測試:
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.3, random_state=42)
 透過我們的資料預處理並分成訓練和測試集,我們現在可以建立我們的隨機森林模型:
透過我們的資料預處理並分成訓練和測試集,我們現在可以建立我們的隨機森林模型:
rf = RandomForestClassifier(n_estimators=100, random_state=42) rf.fit(X_train, y_train)
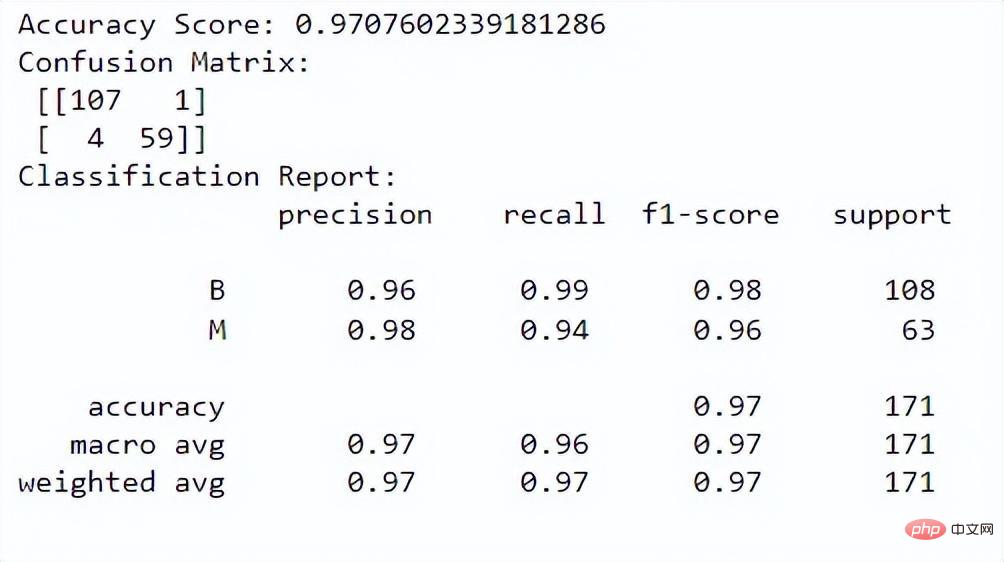
現在,我們可以評估模型的效能。我們將使用準確度分數、混淆矩陣和分類報告進行評估:
y_pred = rf.predict(X_test)
# 准确度分数
print("Accuracy Score:", accuracy_score(y_test, y_pred))
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:n", conf_matrix)
# Classification Report
class_report = classification_report(y_test, y_pred)
print("Classification Report:n", class_report)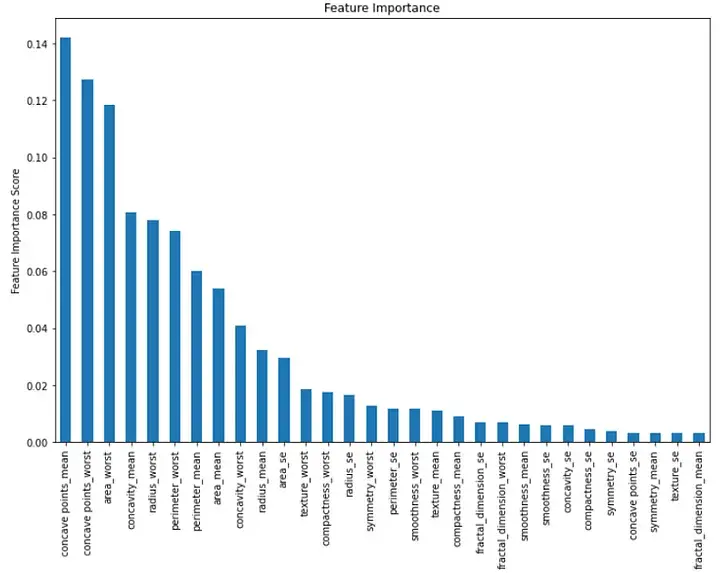
##準確度分數告訴我們模型在正確分類實例方面的表現如何。混淆矩陣讓我們更了解我們模型的分類性能。分類報告為我們提供了兩個類別的精確度、召回率、f1 分數和支援值。
#########最後,我們可以視覺化模型中每個特徵的重要性。我們可以透過建立一個顯示特徵重要性值的長條圖來做到這一點:#########importance = rf.feature_importances_ feat_imp = pd.Series(importance, index=features.columns) feat_imp = feat_imp.sort_values(ascending=False)
plt.figure(figsize=(12,8))
feat_imp.plot(kind='bar')
plt.ylabel('Feature Importance Score')
plt.title("Feature Importance")
plt.show()總之,在機器學習中實作隨機森林演算法是分類任務的強大工具。我們可以使用它根據多個特徵對實例進行分類並評估我們模型的性能。在本文中,我們使用了線上真實資料集,並提供了詳細的程式碼解釋和每個步驟的描述,以及對模型效能和視覺化的評估。
以上是機器學習中實作隨機森林演算法的指南的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















