
DeepRec(PAI-TF)是阿里巴巴集團統一的開源推薦引擎(https://github.com/alibaba/DeepRec),主要用於稀疏模型訓練和預測,可支撐千億特徵、萬億樣本的超大規模稀疏訓練,在訓練表現和效果方面均有明顯優勢;目前DeepRec已支援淘寶搜尋、推薦、廣告等場景,並廣泛應用於淘寶、天貓、阿里媽媽、高德等業務。
英特爾自2019年以來就與阿里巴巴PAI團隊緊密合作,將英特爾人工智慧(Artificial Intelligence,AI)技術應用到DeepRec中,針對算子、子圖、runtime 、框架層和模型等多個層面進行最佳化,以充分發揮英特爾軟硬體優勢,協助阿里巴巴加速內外部AI業務效能。
目前主流的開源引擎對超大規模稀疏訓練場景的支援尚有一定限制,例如,不支持線上訓練、特徵無法動態載入、線上部署迭代不方便等,特別是效能難以達到業務需求的問題尤其明顯。為解決上述問題,DeepRec基於TensorFlow1.15針對稀疏模型場景進行了深度客製化最佳化,主要措施包含以下三類:
##模型效果:主要透過增加EmbeddingVariable(EV)動態彈性特性功能以及改進Adagrad Optimizer來實現最佳化。 EV功能解決了原生Variable size大小難以預估、特徵衝突等問題,並提供了豐富的特徵准入和淘汰策略等進階功能;同時,針對特徵出現頻次進行冷熱自動配置特徵維度問題,增加了高頻特徵表達力,緩解了過擬合,能夠明顯提高稀疏模型效果;
#訓練和推理性能:針對稀疏場景,DeepRec在分佈式、子圖、算子、Runtime等方面進行了深度性能優化,包括分散式策略優化、自動流水線SmartStage、自動圖融合、Embedding和Attention等圖優化、常見稀疏算子優化、內存管理優化,大幅降低了記憶體使用量,顯著加速了端到端的訓練和推理性能;
#部署及Serving :DeepRec支援增量模型導出和加載,實現了10TB級別的超大模型分鐘級別的在線訓練和更新上線,滿足了業務對時效性的高要求;針對稀疏模型中特徵存在冷熱傾斜的特性,DeepRec提供了多級混合存儲(可達四級混合存儲,即HBM DRAM PMem SSD)的能力,可在提升大模型效能的同時降低成本。
英特爾技術輔助DeepRec實現高效能# 英特爾與阿里巴巴PAI團隊的緊密合作在實現以上三個獨特優勢中都發揮了重要作用,DeepRec三大優勢也充分體現了英特爾技術的巨大價值:
在效能優化方面,英特爾超大規模雲端軟體團隊與阿里巴巴緊密合作,針對CPU平台,從算子、子圖、框架、runtime等多個層級進行最佳化,充分利用英特爾® 至強® 可擴展處理器的各種新特徵,更大程度發揮硬體優勢;
為了提升DeepRec在CPU平台的易用性,也搭建了modelzoo來支援絕大部分主流推薦模型,並將DeepRec的獨特EV功能應用到這些模型中,實現了開箱即用的使用者體驗。
同時,針對超大規模稀疏訓練模型EV對儲存和KV查找操作的特殊需求,英特爾傲騰創新中心團隊提供基於英特爾® 傲騰TM 持久記憶體(簡稱「PMem」)的記憶體管理和儲存方案,支援並配合DeepRec多層次混合儲存方案,滿足了大記憶體和低成本需求;可程式解決方案事業部團隊 使用FPGA實現對Embedding的KV查找功能,大幅提升了Embedding查詢能力,同時可釋放更多的CPU資源。結合CPU、PMem和FPGA的不同硬體特點,從系統角度出發,針對不同需求更加充分地發揮英特爾軟硬體優勢,可加速DeepRec在阿里巴巴AI業務中的落地,並為整個稀疏場景的業務生態提供更優的解決方案。
Intel® DL Boost為DeepRec提供關鍵效能加速
Intel® DL Boost(Intel® 深度學習加速)對DeepRec的最佳化,主要體現在框架最佳化、算子最佳化、子圖最佳化和模型最佳化四個層面。
##自英特爾® 至強® 可擴充處理器問世以來,透過從AVX 256 升級到AVX-512,英特爾將AVX 的能力提高了一倍,大大提升了深度學習訓練和推理能力;而第二代英特爾® 至強® 可擴展處理器中又引入DL Boost_VNNI,大幅提升了INT8 乘加運算效能;自第三代英特爾® 至強® 可擴充處理器之後,英特爾推出支援BFloat16(BF16)資料類型的指令集,以進一步提升深度學習訓練與推理效能。隨著硬體技術的不斷創新和發展,英特爾將在下一代至強® 可擴展處理器推出新的AI處理技術,進一步提高 VNNI 和 BF16 從 1 維-向量到 2 維-矩陣的能力。上述的硬體指令集技術在DeepRec的最佳化中均已有所應用,使得針對不同的運算需求可使用不同的硬體特徵,也驗證了英特爾® AVX-512和BF16非常適合稀疏場景的訓練和推理加速。
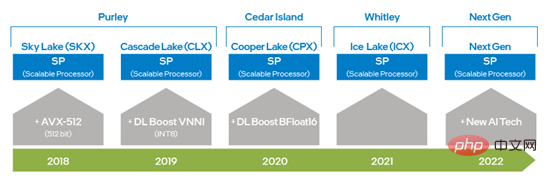
#圖一英特爾x86 平台AI 能力演進圖
#DeepRec整合了英特爾開源的跨平台深度學習效能加速庫oneDNN(oneAPI Deep Neural Network Library ),並且將oneDNN原有的執行緒池修改,統一成DeepRec的Eigen執行緒池,減少了執行緒池切換開銷,避免了不同執行緒池之間競爭而導致的效能下降問題。 oneDNN已經針對大量主流算子實現了性能優化,包括MatMul、BiasAdd、LeakyReLU等在稀疏場景中的常見算子,能夠為搜廣推模型提供強有力的性能支撐,並且oneDNN中的算子也支持BF16資料類型,與搭載BF16指令集的第三代英特爾® 至強® 可擴充處理器同時使用,可顯著提升模型訓練與推理效能。
在DeepRec編譯選項中,只要加入 “--config=mkl_threadpool”,便可輕鬆開啟oneDNN最佳化。
# oneDNN雖可用來大幅提升運算密集型算子的效能,但搜尋廣告推薦模型中存在大量稀疏算子,如Select、DynamicStitch、Transpose、Tile、SparseSegmentMean等,這些算子的原生實現大部分存在一定的訪存優化空間,對此可採用針對性方案實現額外優化。此最佳化呼叫AVX-512指令,只需在編譯指令中加入 “--copt=-march=skylake-avx512”即可開啟。以下為其中兩個優化案例。
案例一:Select算符實作原理是依據條件來做元素的選擇,此時可採用英特爾® AVX-512的mask load方式,如圖二左圖所示,以減少原先由if條件帶來大量判斷所導致的時間開銷,然後再通過批量選擇提升數據讀寫效率,最終線上測試表明,性能提升顯著;

圖二Select算子最佳化案例
案例二:同樣,可以使用英特爾® AVX-512的unpack和shuffle指令對transpose算子進行優化,即通過小Block的方式對矩陣進行轉置,如圖二右圖所示,最終經線上測試表明,性能提升同樣十分顯著。
圖最佳化是目前AI效能最佳化的主要有效手段之一。同樣的,當DeepRec應用在大規模稀疏場景下時,通常存在著以embedding特徵為主的大量特徵信息處理,並且embedding中包含了大量小型算子;為了實現通用的性能提升,優化措施在DeepRec中加入了fused_embedding_lookup功能,對embedding子圖進行融合,減少了大量冗餘操作,同時配合以英特爾® AVX-512指令加速計算,最終embedding子圖性能提升顯著。
透過在tf.feature_column.embedding_column(..., do_fusion=True) API將do_fusion設定為True,即可開啟embedding子圖優化功能。
#基於CPU平台,英特爾在DeepRec建構了涵蓋WDL、DeepFM、DLRM、DIEN、 DIN、DSSM、BST、MMoE、DBMTL、ESMM等多個主流模型的獨特推薦模型集合,涉及召回、排序、多目標等多種常見的場景;並針對硬體平台進行效能最佳化,相較於其他框架,為這些模型基於Criteo等開源資料集在CPU平台上帶來極大的效能提升。
其中表現最突出的當屬混合精度的BF16和Float32的最佳化實作。透過在DeepRec中增加自訂控制DNN層資料類型的功能,來滿足稀疏場景高效能和高精度的需求;開啟最佳化的方式如圖三所示,透過keep_weights保留目前variable的資料類型為Float32,用於防止梯度累積導致的精確度下降,而後再採用兩個cast操作將DNN操作轉換成BF16進行運算,依托第三代英特爾® 至強® 可擴充處理器所具備的BF16硬體運算單元,大幅提升DNN運算性能,同時透過圖融合cast操作進一步提升性能。

#圖三混合精確度最佳化開啟方式
# 為了能夠展示BF16對模型精度AUC(Area Under Curve)和性能Gsteps/s的影響,針對現有modelzoo的模型都應用以上混合精度優化方式。阿里巴巴PAI團隊使用DeepRec在阿里雲平台的評測顯示#[1]#,基於Criteo資料集,使用BF16最佳化後,模型WDL精準度或AUC可以逼近FP32,且BF16模型的訓練性能提升達1.4倍,效果顯著。
未來,為了更大程度地發揮CPU平台硬體優勢,尤其是將新硬體特性的效果最大化, DeepRec將從不同角度進一步實施最佳化,包括最佳化器算子、attention子圖、新增多目標模型等,以便為稀疏場景打造更高效能的CPU解決方案。
使用PMem實作Embedding儲存
對於超大規模稀疏模型訓練與預測引擎(千億特徵、萬億樣本、模型10TB等級),若全部採用動態隨機存取記憶體(Dynamic Random Access Memory,DRAM)來存儲,會大幅提升總擁有成本 (Total Cost of Ownership ,TCO),同時為企業的IT 運作和管理帶來巨大壓力,讓AI 解決方案的落地遭遇挑戰。
PMem具有更高儲存密度和資料持久化優勢,I/O 效能接近 DRAM ,成本更為經濟實惠,可充分滿足超大規模稀疏訓練和預測在高效能和大容量兩方面的需求。
PMem支援兩種操作模式,即記憶體模式(Memory Mode)和應用直接存取模式(App Direct Mode)。在記憶體模式中,它與普通的易失性(非持久性)系統記憶體完全一樣,但成本更低,能在保持系統預算的同時實現更高容量,並在單一伺服器中提供TB 等級的內存總容量;相較於記憶體模式,應用直接存取模式則可利用PMem的持久化特性。在應用直接存取模式下,PMem和與其相鄰的DRAM內存都會被識別為可按字節尋址的內存,操作系統可以將PMem硬體作為兩種不同的設備來使用,一種是FSDAX模式,PMem被配置成區塊設備,使用者可以將其格式化成一個檔案系統來使用; 另一種是DEVDAX模式,PMem被驅動為單一字元設備,依賴核心(5.1以上)提供的KMEM DAX特性,把PMem當作易失性記憶體使用,接取記憶體管理系統,作為一個和DRAM類似的、較慢較大的記憶體NUMA節點,應用可透明存取。
在超大規模特徵訓練中, Embedding 變數儲存佔用 90%以上的內存,記憶體容量會成為其瓶頸之一。將EV 存到PMem 可以打破這一瓶頸,創造多項價值,例如提高大規模分散式訓練的記憶體儲存能力、支援更大模型的訓練和預測、減少多台機器之間的通訊、提升模型訓練效能,同時降低TCO。
在Embedding多層混合儲存中,PMem同樣是打破DRAM瓶頸的絕佳選擇。目前將EV存到PMem已具備三種方式,且在如下這三種方式下運行micro-benchmark、WDL 模型和WDL-proxy模型,性能非常接近於將EV存到DRAM,這無疑使得其TCO獲得了很大優勢:
阿里巴巴PAI團隊在阿里雲記憶體增強型實例ecs.re7p.16xlarge上採用3種保存EV的方式進行了Modelzoo中的WDL單機模型對比測試[2],這3種方式分別是將EV存到DRAM,採用基於Libpmem庫的分配器來保存EV和採用基於Memkind庫的分配器來保存EV,測試結果顯示將EV存到PMem與將EV存到DRAM的效能非常接近。

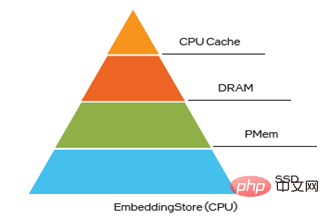
#圖四Embedding多層混合儲存
由此,下一步最佳化計畫將採用PMem保存模型,把稀疏模型checkpoint檔案存到持久記憶體中,來實現多個數量級的效能提升,擺脫目前用SSD保存恢復超大模型需要較長時間,且期間訓練預測會中斷的窘境。
FPGA加速Embedding Lookup
##大規模稀疏訓練及預測涵蓋多種場景,例如分散式訓練、單機和分散式預測以及異構計算訓練等。它們與傳統卷積神經網路(Convolutional Neural Network,CNN)或循環神經網路(Recurrent Neural Networks,RNN)相比有一個關鍵的不同,那就是embedding table的處理,而這些場景中的Embedding table處理需求面臨新的挑戰:
DeepRec透過PS-worker架構來支援超大規模任務場景。在PS-worker架構中,儲存與運算分離,Embedding table以Key-Value的形式被儲存在(幾十、上百個)Parameter Servers中,這些PS為(幾百、上千個)Worker提供存取、更新模型參數的服務,其關鍵的指標就是流通量和訪問時延。而面對大規模稀疏模型訓練與預測,現有框架中PS-worker的實現就顯露了其瓶頸:
為了解決流通量瓶頸和延遲的問題,優化中引入了支援CXL (Compute Express Link)的英特爾® Agilex TM I系列FPGA,實施路徑如圖五所示:
# 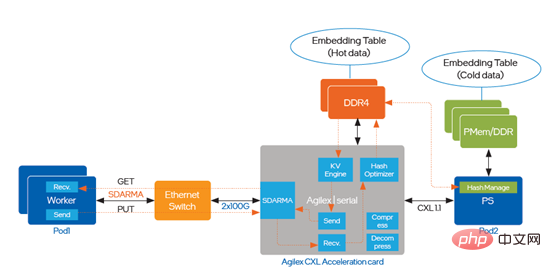
圖五引入英特爾®AgilexTM I系列FPGA實作最佳化## 基于英特尔® AgilexTM I系列 FPGA的加速方案能在一个硬件平台支持上述所有场景,流通量显著提升,同时提供较低的访问时延。 前文介绍了针对DeepRec在CPU、PMem和FPGA不同硬件的优化实现方案,并成功部署到阿里巴巴多个内部和外部业务场景,在实际业务中也获得了明显的端到端性能加速,从不同角度解决了超大规模稀疏场景面临的问题和挑战。众所周知,英特尔为AI应用提供了多样化的硬件选择,为客户选择更优性价比的AI方案提供了可能;与此同时,英特尔与阿里巴巴及广大客户正一同基于多样化硬件实施软硬一体的创新协作和优化,从而更充分地发挥英特尔技术和平台的价值。英特尔也期望继续和业界伙伴合作展开更深入地合作,持续为AI技术的部署落地贡献力量。 英特尔并不控制或审计第三方数据。请您审查该内容,咨询其他来源,并确认提及数据是否准确。 性能测试结果基于2022年4月27日和2022年5月23日进行的测试,且可能并未反映所有公开可用的安全更新。详情请参阅配置信息披露。没有任何产品或组件是绝对安全的。 描述的成本降低情景均旨在在特定情况和配置中举例说明特定英特尔产品如何影响未来成本并提供成本节约。情况均不同。英特尔不保证任何成本或成本降低。 英特尔技术特性和优势取决于系统配置,并可能需要支持的硬件、软件或服务得以激活。产品性能会基于系统配置有所变化。没有任何产品或组件是绝对安全的。更多信息请从原始设备制造商或零售商处获得,或请见intel.com。 英特尔、英特尔标识以及其他英特尔商标是英特尔公司或其子公司在美国和/或其他国家的商标。 ©英特尔公司版权所有 [1] 如欲了解更多性能测试详情,请访问https://github.com/alibaba/DeepRec/tree/main/modelzoo/WDL [2] 如欲了解更多性能测试详情,请访问https://help.aliyun.com/document_detail/25378.html?spm=5176.2020520101.0.0.787c4df5FgibRE#re7p
总结
法律声明
以上是英特爾協助建構開源大規模稀疏模型訓練 / 預測引擎 DeepRec的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















