
目前,人工智慧在企業規模化應用中,存在諸多難點,例如:研發上線週期長,效果不如預期,資料和模型難匹配等。在此背景下,MLOps應運而生。 MLOps作為幫助在企業中擴展機器學習的關鍵技術正在崛起。
日前,由51CTO組織的AISummit 全球人工智慧技術大會#成功舉辦。在會議開設的「MLOps最佳實踐」專場,開放原子基金會 TOC副主席譚中意、第四範式系統架構師盧冕、網易雲音樂人工智慧研究員吳官林、中國工商銀行軟體開發中心大數據和人工智慧實驗室副主任黃炳帶來了各自的主題演講,圍繞研發運維週期、持續訓練和持續監控、模型版本和血緣、數據線上線下一致性、高效數據供給等熱點方向,探討了MLOps的實戰效果和前沿趨勢。
Andrew NG曾在多個場合表達過AI已經從model centric 轉到 data centric,資料是AI落地最大的挑戰。如何確保資料的高品質供給是關鍵問題,而要解決好這個問題,需要利用MLOps的實踐來幫助AI多快好省的落地。
那麼,MLOps解決哪些問題?如何評估MLOps專案的成熟度?開放原子基金會 TOC副主席、LF AI & Data TAC成員譚中意帶來了主題演講《從model centric 到 data centric — MLOps幫助AI多快好省的落地》,對此進行了詳細的介紹。
譚中意首先分享了一群業內科學家和分析師的觀點。 Andrew NG認為,提升資料品質比提升模型演算法,更能提升AI落地效果,在他看來,MLOps最重要的任務就是在機器學習生命週期的各個階段,始終保持高品質的資料供給。
要實現AI的規模化落地,必須發展MLOps。至於到底什麼是MLOps,業界莫衷一是,他給了自己的解釋:它是「程式碼 模型 資料的持續整合、持續部署、持續訓練和持續監控」。
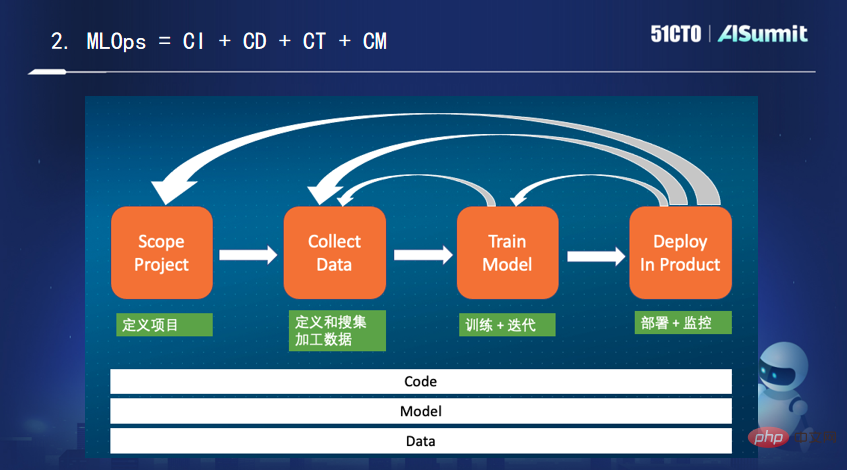
接著,譚中意重點介紹了機器學習領域特有的平台Feature Store(特徵平台)的特性,以及目前市面上主流的特徵平台產品。
最後譚中意就MLOps的成熟度模型進行了簡要闡述。他提到,微軟Azure依照機器學習全流程的自動化程度的高低,把MLOps的成熟模型分成了(0、1、2、3、4)這幾個等級,其中0是沒有自動化的,123是部分自動化,4是高度自動化。
在許多機器學習場景中,面臨著即時特徵運算的需求。從資料科學家離線開發的特徵腳本,到線上即時特徵計算,AI 落地的成本非常高。
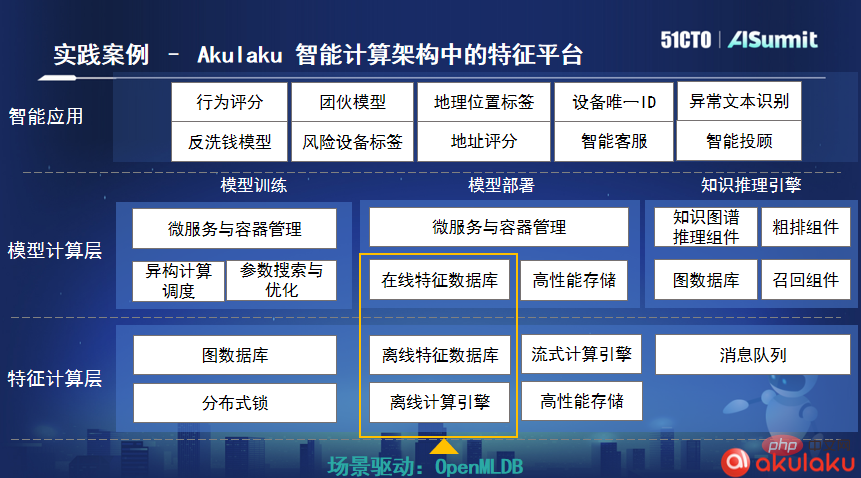
針對這個痛點,第四範式系統架構師、資料庫團隊和高效能運算團隊負責人盧冕在主題演講《開源機器學習資料庫 OpenMLDB:線上線下一致的生產級特徵平台》中重點介紹了 OpenMLDB如何實現機器學習特徵開發即上線的目標,以及如何確保特徵計算的正確性、高效性。
盧冕指出,隨著人工智慧工程化落地的推進,在特徵工程環節,線上線上的一致性校驗帶來了高昂的落地成本。而OpenMLDB恰恰提供了低成本的開源解決方案,它不僅解決了核心問題-機器學習線上線下的一致性,解決了正確性的問題,而且實現了毫秒級的即時的特徵計算。這就是其核心價值所在。
根據盧冕介紹,印尼線上支付公司Akulaku是OpenMLDB開源以後的第一個社群企業用戶,他們把OpenMLDB整合在其智慧運算架構中。在實際業務中,Akulaku平均一天要處理將近10億條訂單數據,使用OpenMLDB後,其處理數據的延遲僅在4毫秒,充分滿足了他們的業務需求。
依托网易云音乐海量数据、精准算法、实时系统的基础,服务于内容分发和商业化多场景,同时满足既要建模效率高,也要使用门槛低,还要模型效果显著等一系列算法工程追求,为此网易云音乐算法工程团队结合音乐业务开始了端到端机器学习平台的实践落地。
网易云音乐人工智能研究员、技术总监吴官林带来了主题演讲《网易云音乐特征平台技术实践》,从云音乐业务背景出发,阐释模型实时化落地方案,结合Feature Store进一步和与会者分享了其思考。
吴官林提到,在云音乐模型算法工程的建设中,主要面临实时化程度低、建模效率低、线上线下不一致导致模型能力受限三大痛点。针对这些痛点,他们从模型实时化开始,在模型实时化覆盖业务的过程中去构建相应的Feature Store平台。
吴官林介绍,他们首先进行了模型实时化在直播场景上的探索并取得了一定成效。在工程上,也探索出一个完整的链路,并落地了一些基础工程建设。但模型实时化聚焦在精排实时场景,但80%以上场景是离线模型。在全链路建模过程中,每个场景开发者都从原点做数据开始,导致了建模周期长,效果还不可预期,新手开发门槛高等问题。考虑到一个模型上线周期,80%时间在做数据相关,其中特征占比高达50%。他们开始着手沉淀特征平台Feature Store。
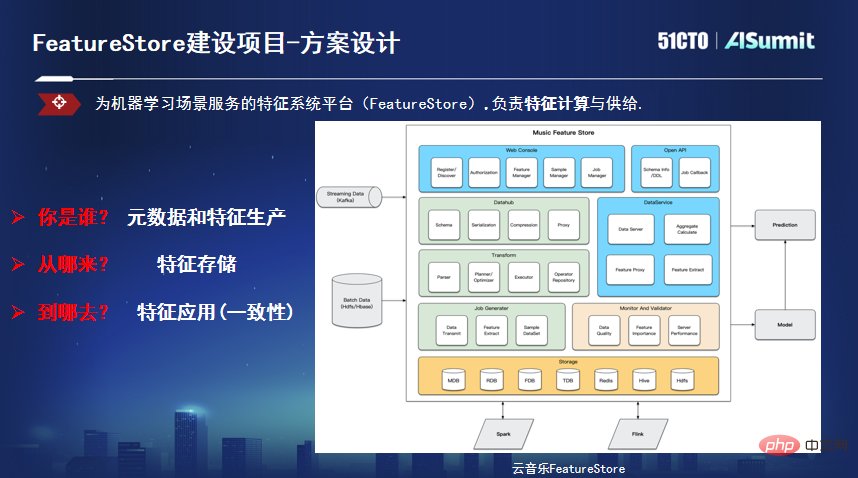
Feature Store主要解决了三方面的问题:一是定义元数据,统一特征血缘、计算、推送过程,实现基于批流一体的高效特征生产链路;二是针对特征的特性进行改造,解决特征存储问题,根据实际使用场景对延迟和吞吐量的不同,提供各种类型的存储引擎;三是解决特征一致性的问题,从统一的API读取指定格式的数据,作为机器学习模型的输入,用于推理、训练等。
中国工商银行软件开发中心大数据和人工智能实验室副主任黄炳在其主题演讲《筑牢金融智能化创新发展的人工智能新基建》重点介绍了工商银行的MLOps实践,涵盖模型研发、模型交付、模型管理、模型迭代运营的全生命周期管理体系的建设流程及技术实践。
之所以需要MLOps,是因为人工智能如火如荼的发展背后,很多已经发生或潜在的“AI技术债”不容忽视。黄炳认为,MLOps的理念是可以解决这些技术债的,“如果说DevOps是解决软件系统技术债问题的利器,DataOps是打开数据资产技术债问题的钥匙,那么脱胎于DevOps理念的MLOps就是治疗机器学习技术债问题的良药”。
在建设过程中,工商银行的MLOps实践经验可以总结为四点:夯实公共能力之“基”,建设企业级数据中台,实现数据沉淀共享;降低应用门槛之“器”,建设相关的建模和服务组装流水线,形成流程化、积木组装化的研发模式;建立AI资产沉淀共享之“法”,最大限度降低AI建设的成本,形成共享共建生态的关键所在;形成模型运营迭代之“术”,根据数据驱动、按照业务价值驱动,建立模型运营体系,是模型质量持续迭代和量化评价的基础。
演讲尾声,黄炳做了两点展望:第一,MLOps需要更安全、更合规。未来企业发展需要非常多的模型来实现数据驱动的智能决策,因此会衍生出更多与模型相关的开发、运维、权限管控、数据隐私、安全性和审计等企业级需求;第二,MLOps需要与其他Ops结合。解决技术债问题是一个复杂的过程,DevOps方案、DataOps方案和MLOps方案必须协调联动,互相赋能,才能充分发挥三者的全部优势,实现“1+1+1>3”的效果。
据IDC预测,到2024年将有60%的企业使用MLOps来实施机器学习工作流。IDC分析师Sriram Subramanian曾如此评价:“MLOps将模型速度缩短到几周——有时甚至是几天,就像使用DevOps加快应用构建的平均时间一样,这就是为什么你需要MLOps。”
目前,我們正處於人工智慧快速擴展的拐點上。企業透過採用MLOps可以建構更多模型、更快實現業務創新,更加多快好省地推進AI的落地。千行百業正在見證和驗證著這樣一個事實:MLOps正在成為企業AI規模化的催化劑。更多精彩內容請點選查看#。
以上是探索企業MLOps落地之路,AISummit 全球人工智慧技術大會「MLOps最佳實踐」專場成功舉辦的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















