

VectorFlow:結合影像和向量做交通佔用和流預測

arXiv論文“VectorFlow: Combining Images and Vectors for Traffic Occupancy and Flow Prediction“,2022年8月9日,清華大學工作。

預測道路智體的未來行為是自主駕駛中的關鍵任務。雖然現有模型在預測智體未來行為方面取得了巨大成功,但有效預測多智體聯合一致的行為仍然是一個挑戰。最近,有人提出了occupancy flow fields(OFF)表示法,透過佔用網格和流的組合來表示道路智體的聯合未來狀態,支持聯合一致的預測。
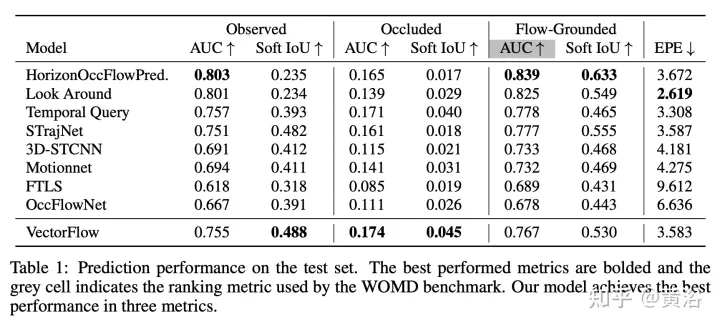
這項工作提出一種新的occupancy flow fields預測器,從光柵化交通影像中學習特徵的影像編碼器,和捕捉連續智體軌跡和地圖狀態資訊的向量編碼器,二者結合起來,產生準確的佔用和流預測。在產生最終預測之前,兩個編碼特徵由多個注意模組融合。該模型在Waymo開放資料集佔用和串流預測挑戰(Occupancy and Flow Prediction Challenge)中排名第三,在遮蔽佔用率和預測任務(occluded occupancy and flow prediction task)中實現了最佳效能。
OFF表示(“Occupancy Flow Fields for Motion Forecasting in Autonomous Driving“,arXiv 2203.03875,3,2022)是一種時空網格,其中每個網格單元包括i)任何智體佔用單元的機率和ii)表示佔用該單元智體運動的流。其提供了更好的效率和可擴展性,因為預測occupancy flow fields的計算複雜性與場景中道路智體的數量無關。
如圖是OFF框架圖。編碼器結構如下。第一層接收所有三種類型的輸入點,並用PointPillars啟發的編碼器進行處理。交通燈和道路點直接放置在網格中。智體在每個輸入時間步t的狀態編碼是,從每個智體BEV框內均勻採樣固定大小的點網格,並把這些點與相關智體狀態屬性(包括時間t的one-hot編碼)放置在網格。每個pillar為其包含的所有點輸出一個嵌入。解碼器結構如下。第二級接收每個pillar嵌入作為輸入,並產生每個網格單元佔用和流預測。解碼器網路基於EfficientNet,用EfficientNet作為主幹來處理每個pillar嵌入得到特徵映射(P2,…P7),其中Pi從輸入下採樣2^i。然後用BiFPN網路以雙向方式融合這些多尺度特徵。然後,用最高解析度特徵映射P2在所有時間步回歸所有智體類K的佔用和流預測。具體地,解碼器為每個網格單元輸出一個向量,同時預測佔用和流。
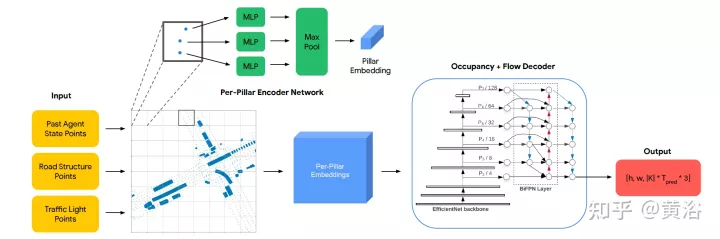
針對本文,做以下問題設定:給定場景中交通智體1秒的歷史和場景上下文,如地圖座標,目標是預測i)未來觀察到的佔用率,ii)未來遮蔽的佔用率,以及iii)在一個場景中未來8個路點上所有車輛的未來流,其中每個路點覆蓋1秒的間隔。
將輸入處理為光柵化影像和一組向量。為了獲得影像,在給定觀察智體軌跡和地圖資料的情況下,相對於自動駕駛汽車(SDC)的局部座標,在過去的每個時間步驟中創建一個光柵化網格。為了獲得與光柵化影像一致的向量化輸入,遵循相同的變換,相對於SDC的局部視圖,旋轉和移動輸入智體和地圖座標。
編碼器包含兩個部分:編碼光柵化表示的VGG-16模型,和編碼向量化表示的VectorNe模型。透過交叉注意模組將向量化特徵與VGG-16最後兩步驟的特徵進行融合。透過FPN-式樣網絡,融合後的特徵上採樣到原始分辨率,作為輸入的光柵化特徵。
解碼器是單一2D卷積層,將編碼器輸出對應到occupancy flow fields預測,該預測包括一系列8網格圖,表示未來8秒內每個時間步的佔用和流預測。
如圖:
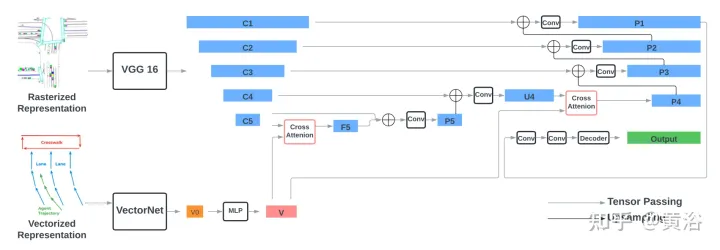
用torchvision的標準VGG-16模型,作為光柵化編碼器,並遵循VectorNet(代碼https://github.com/Tsinghua -MARS-Lab/DenseTNT)的實作。 VectorNet的輸入包含i)一組形狀為B×Nr×9的道路元素向量,其中B是批次大小,Nr=10000是道路元素向量的最大數,最後一個維度9表示每個向量和向量ID中兩個端點的位置(x,y)和方向(cosθ,sinθ);ii)一組形狀為B×1280×9的智體向量,包括場景中最多128個智體的向量,其中每個智體具有來自觀察位置的10個向量。
遵循VectorNet,首先根據每個交通元素的ID運行局部圖,然後在所有局部特徵上運行全局圖,獲得形狀為B×128×N的向量化特徵,其中N是交通元素的總數,包括道路元素和智體。透過MLP層將特徵的大小進一步增加四倍,獲得最終的向量化特徵V,其形狀為B×512×N,其特徵大小與影像特徵的通道大小一致。
VGG每個層級的輸出特徵表示為{C1、C2、C3、C4、C5},相對於輸入影像和512隱藏維,跨步長(strides)為{1、2、4、 8、16}像素。透過交叉注意模組將向量化特徵V與形狀為B×512×16×16的光柵化影像特徵C5融合,獲得相同形狀的F5。交叉注意的query項是影像特徵C5,扁平為有256個令牌(tokens)的B×512×256形狀,Key和Value項是具有N個令牌的向量化特徵V。
接著在通道維上連接F5和C5,經過兩個3×3卷積層,得到形狀為B×512×16×16的P5。 P5透過FPN風格的2×2上取樣模組做上取樣並與C4(B×512×32x32)連接,產生和C4一樣形狀的U4。之後在V和U4之間執行另一輪融合,遵循相同的程序,包括交叉注意,獲得P4(B×512×32×32)。最後,P4由FPN式樣網路逐漸上取樣,並與{C3,C2,C1}連接,產生形狀為B×512×256×256的EP1。將P1通過兩個3×3 卷積層,得到形狀為B×128×256的最終輸出特徵。
解碼器是單一2D卷積層,輸入通道大小為128,輸出通道大小為32(8個路點×4個輸出維度)。
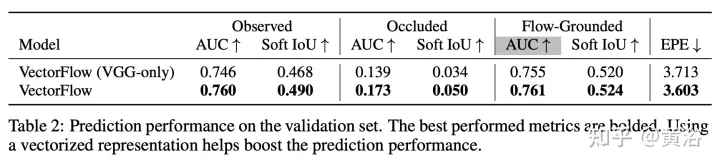
結果如下:
以上是VectorFlow:結合影像和向量做交通佔用和流預測的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Windows 11 上的智慧型應用程式控制:如何開啟或關閉它
Jun 06, 2023 pm 11:10 PM
Windows 11 上的智慧型應用程式控制:如何開啟或關閉它
Jun 06, 2023 pm 11:10 PM
智慧型應用程式控制是Windows11中非常有用的工具,可幫助保護你的電腦免受可能損害資料的未經授權的應用程式(如勒索軟體或間諜軟體)的侵害。本文將解釋什麼是智慧型應用程式控制、它是如何運作的,以及如何在Windows11中開啟或關閉它。什麼是Windows11中的智慧型應用控制?智慧型應用程式控制(SAC)是Windows1122H2更新中引入的新安全功能。它與MicrosoftDefender或第三方防毒軟體一起運行,以阻止可能不必要的應用,這些應用程式可能會減慢設備速度、顯示意外廣告或執行其他意外操作。智慧應用
 五官亂飛,張嘴、瞪眼、挑眉,AI都能模仿到位,影片詐騙要防不住了
Dec 14, 2023 pm 11:30 PM
五官亂飛,張嘴、瞪眼、挑眉,AI都能模仿到位,影片詐騙要防不住了
Dec 14, 2023 pm 11:30 PM
好強大的AI模仿能力,真的防不住,完全防不住。現在AI的發展已經達到這種程度了嗎?你前腳讓自己的五官亂飛,後腳,一模一樣的表情就被復現出來,瞪眼、挑眉、噘嘴,不管多麼誇張的表情,都模仿的非常到位。加大難度,讓眉毛挑的再高些,眼睛睜的再大些,甚至連嘴型都是歪的,虛擬人物頭像也能完美復現表情。當你在左邊調整參數時,右邊的虛擬頭像也會相應地改變動作給嘴巴、眼睛一個特寫,模仿的不能說完全相同,只能說表情一模一樣(最右邊)。這項研究來自慕尼黑工業大學等機構,他們提出了GaussianAvatars,這種
 MotionLM:多智能體運動預測的語言建模技術
Oct 13, 2023 pm 12:09 PM
MotionLM:多智能體運動預測的語言建模技術
Oct 13, 2023 pm 12:09 PM
本文經自動駕駛之心公眾號授權轉載,轉載請洽出處。原標題:MotionLM:Multi-AgentMotionForecastingasLanguageModeling論文連結:https://arxiv.org/pdf/2309.16534.pdf作者單位:Waymo會議:ICCV2023論文想法:對於自動駕駛車輛安全規劃來說,可靠地預測道路代理未來行為是至關重要的。本研究將連續軌跡表示為離散運動令牌序列,並將多智能體運動預測視為語言建模任務。我們提出的模型MotionLM有以下幾個優點:首
 你知道程式設計師再過幾年會沒落?
Nov 08, 2023 am 11:17 AM
你知道程式設計師再過幾年會沒落?
Nov 08, 2023 am 11:17 AM
《ComputerWorld》雜誌曾經寫過一篇文章,說“編程到1960年就會消失”,因為IBM開發了一種新語言FORTRAN,這種新語言可以讓工程師寫出他們所需的數學公式,然後提交給電腦運行,所以程式設計就會終結。圖片又過了幾年,我們聽到了一種新說法:任何業務人員都可以使用業務術語來描述自己的問題,告訴電腦要做什麼,使用這種叫做COBOL的程式語言,公司不再需要程式設計師了。後來,據說IBM開發了一門名為RPG的新程式語言,可以讓員工填寫表格並產生報告,因此大部分企業的程式設計需求都可以透過它來完成圖
 GR-1傅利葉智慧通用人形機器人即將開始預售!
Sep 27, 2023 pm 08:41 PM
GR-1傅利葉智慧通用人形機器人即將開始預售!
Sep 27, 2023 pm 08:41 PM
身高1.65米,體重55公斤,全身44個自由度,能夠快速行走、敏捷避障、穩健上下坡、抗衝擊幹擾的人形機器人,現在可以帶回家了!傅利葉智慧的通用人形機器人GR-1已開啟預售機器人大講堂傅利葉智慧FourierGR-1通用人形機器人現已開放預售。 GR-1擁有高度仿生的軀幹構型和擬人化的運動控制,全身44個自由度,具備行走、避障、越障、上下坡、抗干擾、適應不同路面等運動能力,是通用人工智慧的理想載體。官網預售頁:www.fftai.cn/order#FourierGR-1#傅利葉智能需要改寫的內
 華為將在智慧穿戴領域推出玄璣感知系統 可根據心率評估用戶情緒狀態
Aug 29, 2024 pm 03:30 PM
華為將在智慧穿戴領域推出玄璣感知系統 可根據心率評估用戶情緒狀態
Aug 29, 2024 pm 03:30 PM
近日,華為宣布將於9月推出搭載玄璣感知系統的全新智慧穿戴新品,預計為華為的最新智慧手錶。該新品將整合先進的情緒健康監測功能,玄璣感知系統以其六大特性——準確性、全面性、快速性、靈活性、開放性和延展性——為用戶提供全方位的健康評估。系統採用超感知模組,優化了多通道光路架構技術,大幅提升了心率、血氧和呼吸速率等基礎指標的監測精度。此外,玄璣感知系統也拓展了以心率資料為基礎的情緒狀態研究,不僅限於生理指標,還能評估使用者的情緒狀態和壓力水平,並支持超過60項運動健康指標監測,涵蓋心血管、呼吸、神經、內分泌、
 行人軌跡預測有哪些有效的方法和普遍的Base方法?頂會論文分享!
Oct 17, 2023 am 11:13 AM
行人軌跡預測有哪些有效的方法和普遍的Base方法?頂會論文分享!
Oct 17, 2023 am 11:13 AM
軌跡預測近兩年風頭正猛,但大都聚焦於車輛軌跡預測方向,自動駕駛之心今天就為大家分享頂會NeurIPS上關於行人軌跡預測的演算法—SHENet,在受限場景中人類的移動模式通常在一定程度上符合有限的規律。基於這個假設,SHENet透過學習隱含的場景規律來預測一個人的未來軌跡。文章已經授權自動駕駛之心原創!作者的個人理解由於人類運動的隨機性和主觀性,目前預測一個人的未來軌跡仍然是一個具有挑戰性的問題。然而,由於場景限制(例如平面圖、道路和障礙物)以及人與人或人與物體的互動性,在受限場景中人類的移動模式通
 一文讀懂智慧汽車滑板底盤
May 24, 2023 pm 12:01 PM
一文讀懂智慧汽車滑板底盤
May 24, 2023 pm 12:01 PM
01什麼是滑板底盤所謂滑板式底盤,即將電池、電動傳動系統、懸吊、煞車等零件提前整合在底盤上,實現車身和底盤的分離,設計解耦。基於這類平台,車企可以大幅降低前期研發和測試成本,同時快速回應市場需求打造不同的車款。尤其是無人駕駛時代,車內的佈局不再是以駕駛為中心,而是會注重空間屬性,有了滑板式底盤,可以為上部車艙的開發提供更多的可能。如上圖,當然我們看滑板底盤,不要上來就被「噢,就是非承載車身啊」的第一印象框住。當年沒有電動車,所以沒有幾百公斤的電池包,沒有能取消轉向柱的線傳轉向系統,沒有線傳煞車系
