

提升支付寶搜尋體驗,螞蟻、北大基於層次化對比學習文本生成框架

文字產生任務通常採用 teacher forcing 的方式來訓練,這種訓練方式使得模型在訓練過程中只能見到正樣本。然而生成目標與輸入之間通常會存在某些約束,這些約束通常由句子中的關鍵元素體現,例如在query 改寫任務中,“麥當勞點餐” 不能改成“肯德基點餐”,這裡面起到約束作用的關鍵元素是品牌關鍵字。透過引入對比學習在生成的過程中加入負樣本的模式使得模型能夠有效地學習到這些限制。
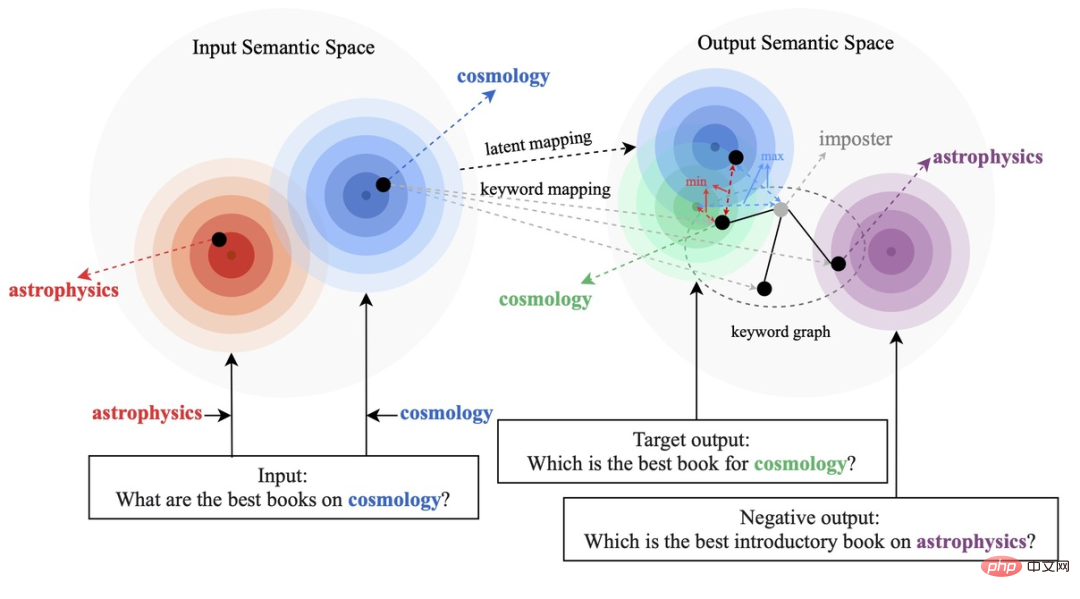
現有的基於對比學習方法主要集中在整句層面實現[1][2],而忽略了句子中的詞粒度的實體的訊息,下圖中的例子展示了句子中關鍵字的重要意義,對於一個輸入的句子,如果對它的關鍵字進行替換(e.g. cosmology->astrophysics),句子的含義會發生變化,從而在語義空間中的位置(由分佈來表示)也會改變。而關鍵字作為句子中最重要的訊息,對應於語意分佈上的一個點,它很大程度上也決定了句子分佈的位置。同時,在某些情況下,現有的對比學習目標對模型來說顯得過於容易,導致模型無法真正學習到區分正負例之間的關鍵資訊。
基於此,來自螞蟻集團、北大等機構的研究者提出了一種多粒度對比生成方法,設計了層次化對比結構,在不同層級上進行資訊增強,在句子粒度上增強學習整體的語義,在詞粒度上增強局部重要資訊。研究論文已被 ACL 2022 接收。

論文網址:https://aclanthology.org/2022.acl-long.304.pdf
#方法
我們的方法是基於經典的CVAE文本生成框架[3][4],每個句子都可以映射成為向量空間中的一個分佈,而句子中的關鍵字則可以看成是這個分佈上採樣得到的一個點。我們一方面透過句子粒度的對比來增強隱空間向量分佈的表達,另一方面透過構造的全局關鍵字graph 來增強關鍵字點粒度的表達,最後透過馬氏距離對關鍵字的點和句子的分佈構造層次間的對比來增強兩個粒度的訊息表達。最終的損失函數由三種不同的對比學習 loss 相加而得到。
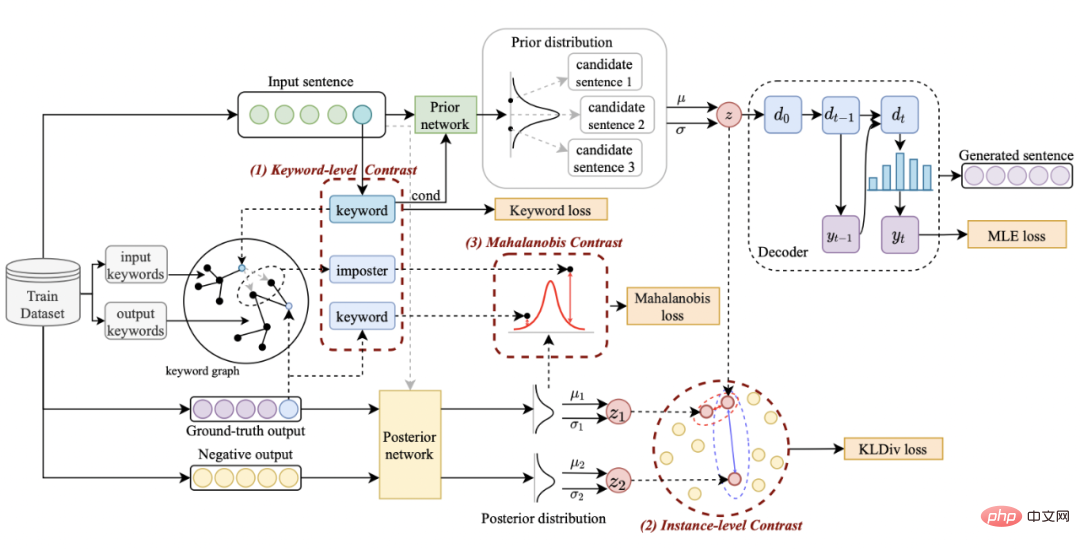
句子粒度對比學習
##在Instance-level,我們利用原始輸入x、目標輸出

#及對應的輸出負樣本構成了句子粒度的比較pair
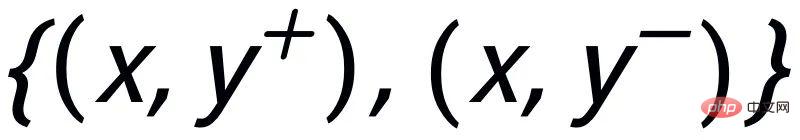
。我們利用一個先驗網路學習到先驗分佈
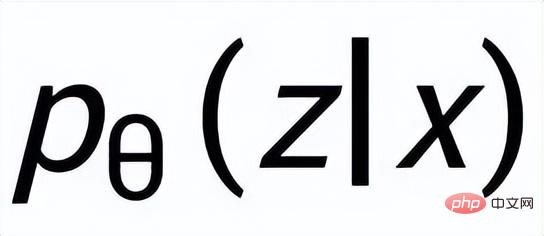
#,記為
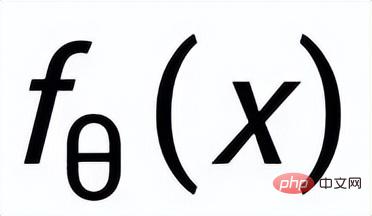
#;透過一個後驗網路學習到近似的後驗分佈
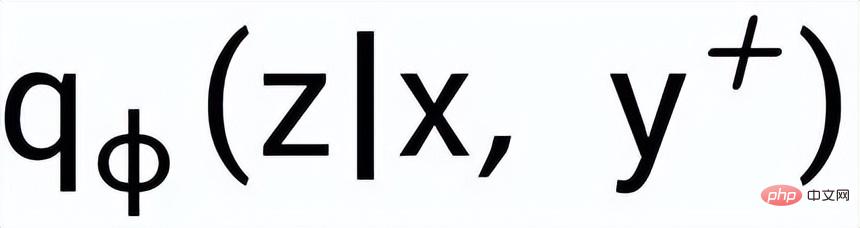
與
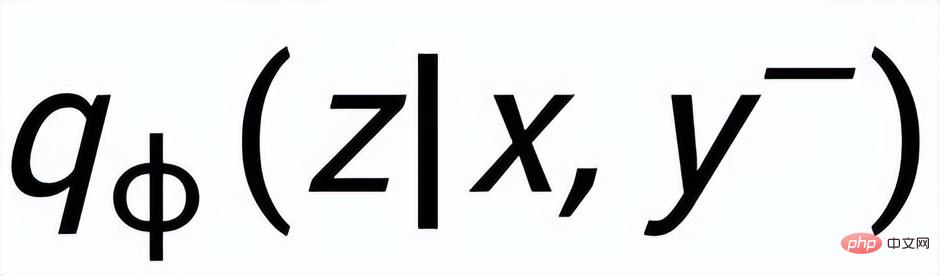
#,分別記為
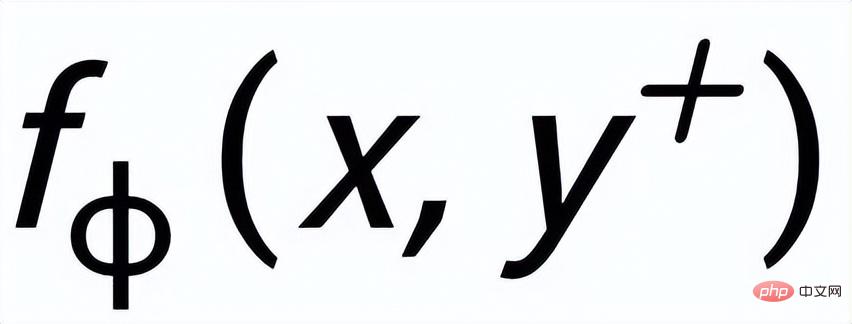
#和
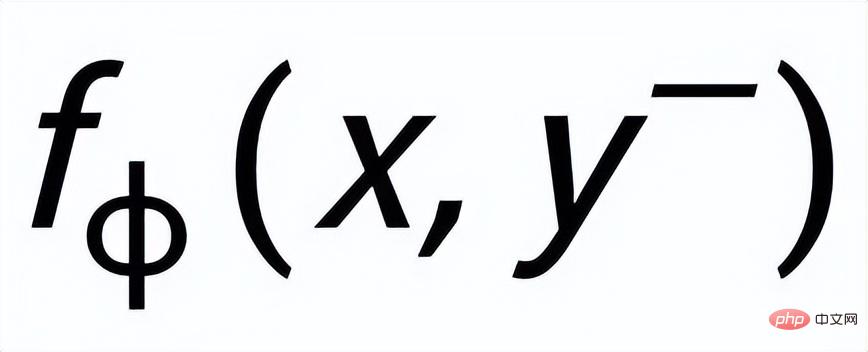
。句子粒度對比學習的目標就是盡可能縮小先驗分佈和正後驗分佈的距離,同時盡可能推大的先驗分佈與負後驗分佈的距離,對應的損失函數如下:
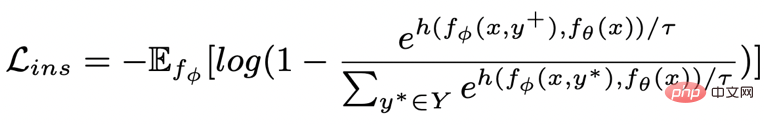
其中為正樣本或負樣本,為溫度係數,用來表示距離度量,這裡我們使用KL 散度(Kullback–Leibler divergence )[5] 來測量兩個分佈直接的距離。
關鍵字粒度對比學習
- 關鍵字網絡
關鍵字粒度的對比學習是用來讓模型更多的關注到句子中的關鍵訊息,我們透過利用輸入輸出文字對應的正負關係建構一個keyword graph 來達到這個目標。具體來說,根據一個給定的句對

,我們可以分別從其中確定一個關鍵字

和


#(關鍵字抽取的方法我採用經典的TextRank 演算法[6]);對於一個句子

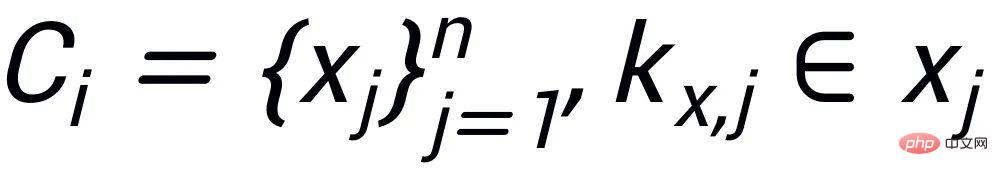

## ,可能存在與其關鍵字
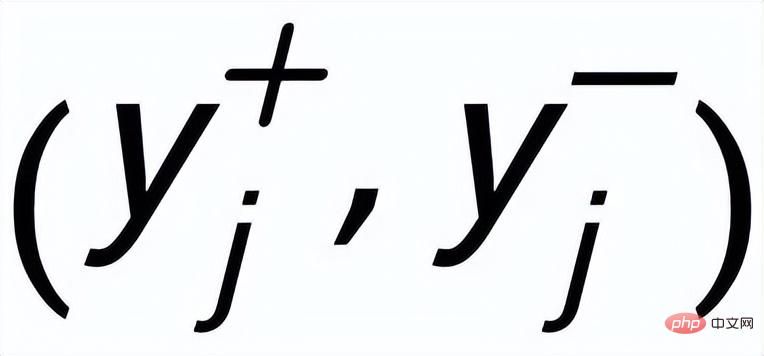
#相同的其他句子,這些句子共同組成一個集合

與負例關鍵字
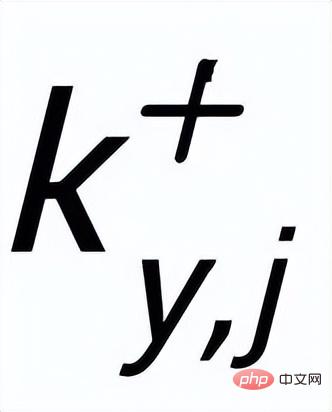
#。這樣在整個集合中,對任何一個輸出的句子

#,可以認為它所對應的關鍵字

與每個周圍的

(透過句子之間的正負關係關聯)之間都存在著一條正邊
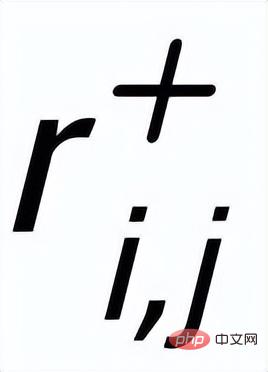
,和每一個周圍的

#之間都存在一條負邊

#。基於這些關鍵字節點和他們直接的邊,我們就可以建構一個keyword graph

我們使用BERT embedding[7] 來作為每個節點

的初始化,並使用一個MLP層來學習每條邊的表示
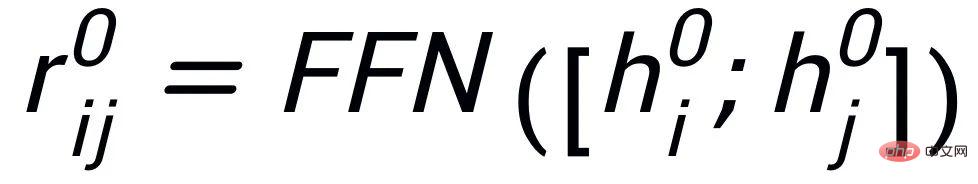
。我們透過一個graph attention (GAT) 層和MLP 層來迭代式地更新關鍵字網路中的節點和邊,每個迭代中我們先透過如下的方式更新邊的表示:
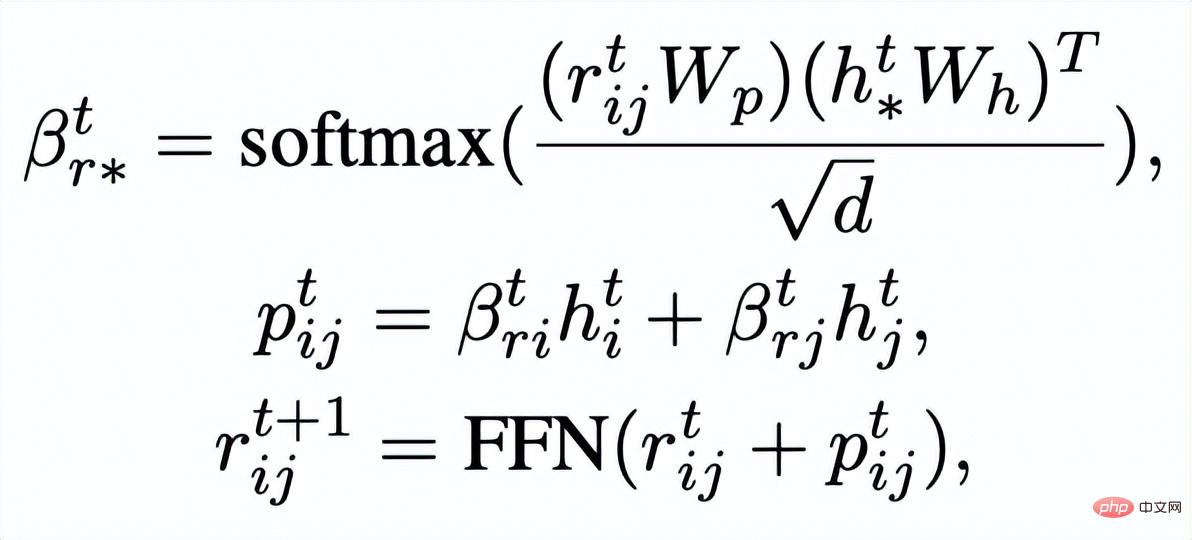
##這裡

可以是

或

#。
############然後根據更新後的邊##########
,我們透過一個graph attention 層來更新每個節點的表示:
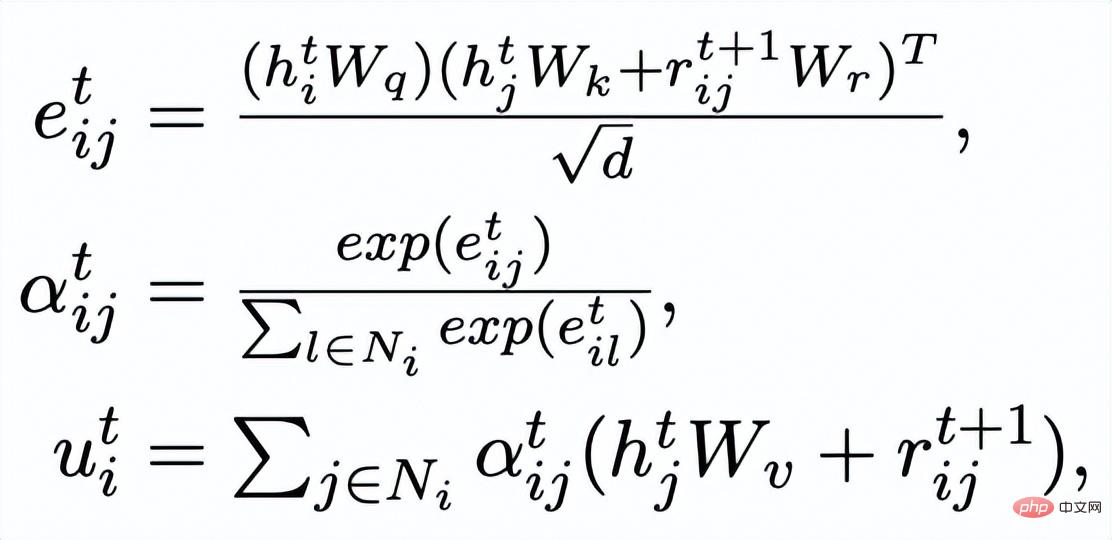
這裡
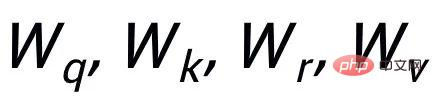
#都是可學習的參數,

#為注意力權重。為了防止梯度消失的問題,我們在

#上加上了殘差連接,得到該迭代中節點的表示

。我們使用最後一個迭代的節點表示作為關鍵字的表示,記為 u。
- 關鍵字比較


關鍵字粒度的比較來自於輸入句子的關鍵字

和一個偽裝(impostor)節點

。我們將輸入句子的輸出正樣本中提取的關鍵字記為
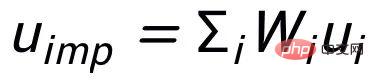
,它在上述關鍵字網路中的負鄰居節點記為
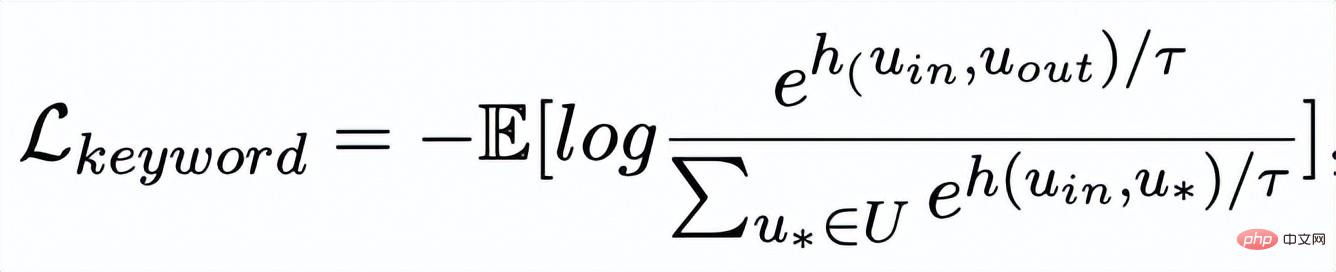
,則

,關鍵字粒度的比較學習loss 計算如下:

這裡

,h(·) 用來表示距離測量,在關鍵字粒度的對比學習中我們選用了餘弦相似度來計算兩個點之間的距離。
- 在跨粒度對比學習
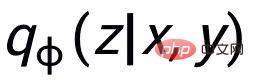
#可以注意到上述句子粒度和關鍵字粒度的對比學習分別是在分佈和點上實現,這樣兩個粒度的獨立對比可能由於差異較小導致增強效果減弱。對此,我們基於點和分佈之間的馬氏距離(Mahalanobis distance)[8] 構建不同粒度之間對比關聯,使得目標輸出關鍵字到句子分佈的距離盡可能小於imposter 到該分佈的距離,從而彌補各粒度獨立對比可能帶來的對比消失的缺陷。具體來說,跨粒度的馬氏距離對比學習希望盡可能縮小句子的後驗語義分佈

和

之間的距離,同時盡可能拉大其與
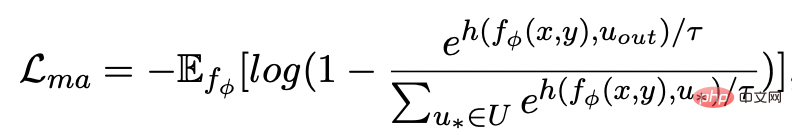
之間的距離,損失函數如下:



這裡
同樣用來指
#或
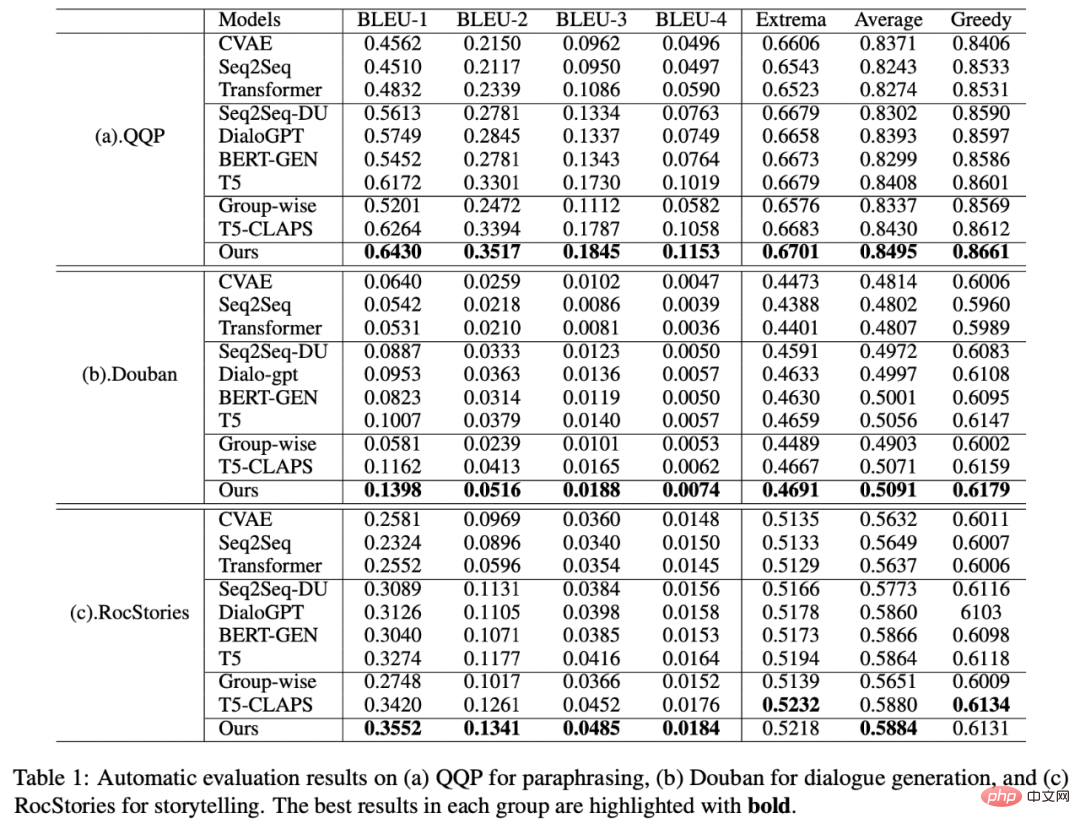
#,而h(·) 為馬氏距離。
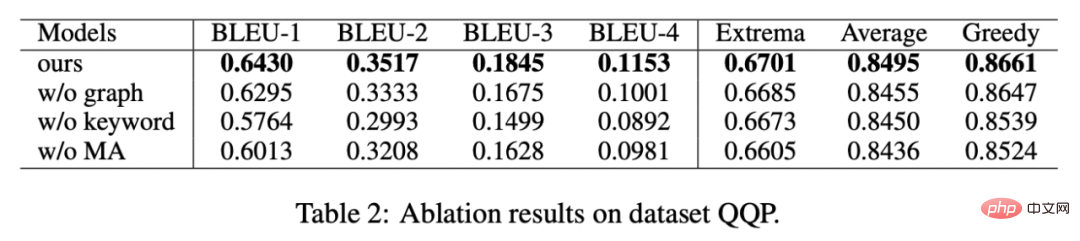
消融分析
我們對是否採用關鍵字、是否採用關鍵字網路以及是否採用馬氏距離對比分佈進行了消融分析實驗,結果顯示這三種設計對最後的結果確實起到了重要的作用,實驗結果如下圖所示。
視覺化分析
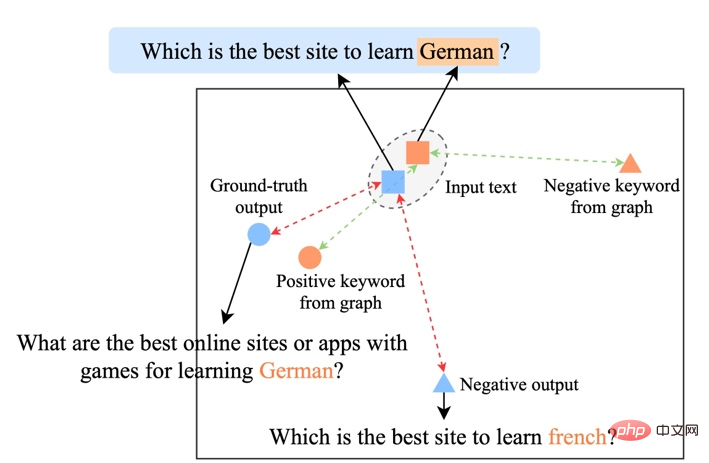
為了研究不同層級對比學習的作用,我們對隨機採樣的case 進行了可視化,透過t-sne[22] 進行降維處理後得到下圖。圖中可以看出,輸入句子的表示與抽取的關鍵字表示接近,這說明關鍵字作為句子中最重要的訊息,通常會決定語義分佈的位置。並且,在對比學習中我們可以看到經過訓練,輸入句子的分佈與正樣本更接近,與負樣本遠離,這說明對比學習可以起到幫助修正語意分佈的作用。
關鍵字重要性分析
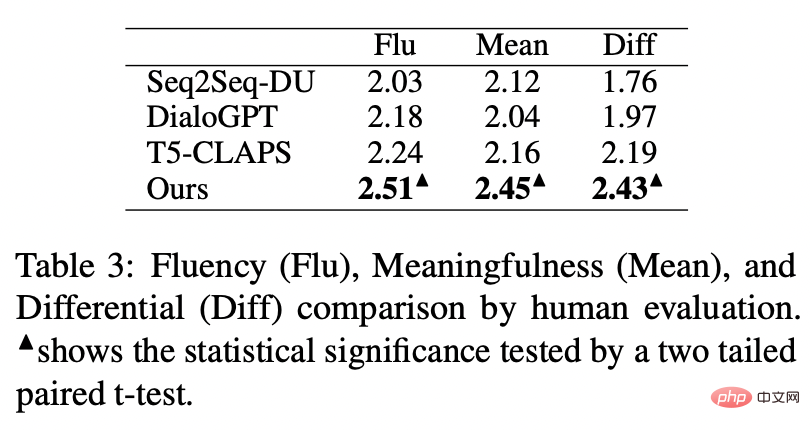
最後,我們探討採樣不同關鍵字的影響。如下表所示,對於一個輸入問題,我們透過 TextRank 抽取和隨機選擇的方法分別提供關鍵字作為控制語意分佈的條件,並檢查產生文字的品質。關鍵字作為句子中最重要的訊息單元,不同的關鍵字會導致不同的語意分佈,產生不同的測試,選擇的關鍵字越多,產生的句子越準確。同時,其他模型產生的結果也展示在下表中。

業務應用程式
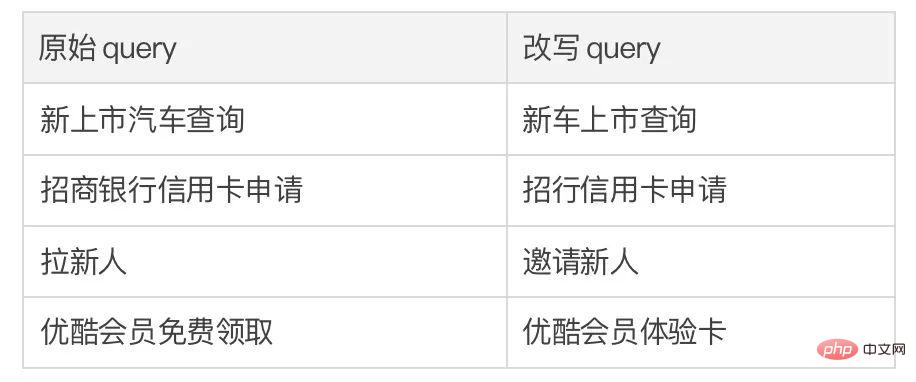
這篇文章中我們提出了一種跨粒度的層次化對比學習機制,在多個文本生成的資料集上均超過了具有競爭力的基線工作。基於該工作的 query 改寫模型在也在支付寶搜尋的實際業務場景成功落地,取得了顯著的效果。支付寶搜尋中的服務覆蓋領域寬廣且領域特色顯著,用戶的搜尋query 表達與服務的表達存在巨大的字面差異,導致直接基於關鍵字的匹配難以取得理想的效果(例如用戶輸入query「新上市汽車查詢”,無法召回服務“新車上市查詢”),query 改寫的目標是在保持query 意圖不變的情況下,將用戶輸入的query 改寫為更貼近服務表達的方式,從而更好的匹配到目標服務。如下是一些改寫範例:
以上是提升支付寶搜尋體驗,螞蟻、北大基於層次化對比學習文本生成框架的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 刪除 Windows 11 搜尋中的新聞和趨勢內容的方法
Oct 16, 2023 pm 08:13 PM
刪除 Windows 11 搜尋中的新聞和趨勢內容的方法
Oct 16, 2023 pm 08:13 PM
當您按一下Windows11中的搜尋欄位時,搜尋介面會自動展開。它在左側顯示最近程式的列表,在右側顯示Web內容。 Microsoft在那裡顯示新聞和趨勢內容。今天的支票宣傳了必應新的DALL-E3圖像生成功能、「與必應聊天龍」的提議、有關龍的更多資訊、來自網路部分的熱門新聞、遊戲建議和趨勢搜尋部分。整個項目清單與您在電腦上的活動無關。雖然一些用戶可能會喜歡查看新聞的能力,但所有這些都可以在其他地方大量獲得。其他人可能會直接或間接將其歸類為促銷甚至廣告。 Microsoft使用介面來推廣自己的內容,
 百度進階搜尋怎麼用
Feb 22, 2024 am 11:09 AM
百度進階搜尋怎麼用
Feb 22, 2024 am 11:09 AM
百度高級搜尋怎麼用百度搜尋引擎是目前中國最常用的搜尋引擎之一,它提供了豐富的搜尋功能,其中之一就是進階搜尋。進階搜尋可以幫助使用者更精確地搜尋到所需的信息,提高搜尋效率。那麼,百度高級搜尋要怎麼使用呢?第一步,打開百度搜尋引擎首頁。首先,我們需要開啟一個百度的官方網站,也就是www.baidu.com。這是百度搜索的入口。第二步,點選進階搜尋按鈕。在百度搜尋框的右側,有
 閒魚怎麼搜尋用戶
Feb 24, 2024 am 11:25 AM
閒魚怎麼搜尋用戶
Feb 24, 2024 am 11:25 AM
閒魚怎麼搜尋用戶?在軟體閒魚中,我們可以直接在軟體裡面去找想要溝通的使用者。但卻不清楚該怎麼搜尋用戶。在搜尋後的用戶中查看即可。接下來就是小編為用戶帶來的搜尋用戶方式介紹的介紹,有興趣的用戶快來一起看看吧!閒魚怎麼搜尋用戶答:在搜尋後的用戶中查看詳情介紹:1、進入軟體,點選搜尋框。 2、輸入使用者名稱,點選搜尋。 3.再選擇搜尋框下的【用戶】,即可找到對應用戶了。
 深入探討模型、資料與架構:一份詳盡的54頁高效能大語言模型綜述
Jan 14, 2024 pm 07:48 PM
深入探討模型、資料與架構:一份詳盡的54頁高效能大語言模型綜述
Jan 14, 2024 pm 07:48 PM
大規模語言模型(LLMs)在許多重要任務中展現了引人注目的能力,包括自然語言理解、語言生成和複雜推理,並對社會產生了深遠的影響。然而,這些出色的能力卻需要大量的訓練資源(如左圖)和較長的推理時間(如右圖)。因此,研究人員需要開發有效的技術手段來解決它們的效率問題。此外,從圖的右邊還可以看出,一些高效率的LLMs(LanguageModels)如Mistral-7B,已經成功應用於LLMs的設計和部署中。這些高效的LLMs在保持與LLaMA1-33B相近的準確性的同時,能夠大大減少推理內存
 wps表格找不到正在搜尋的資料,請檢查搜尋選項位置
Mar 19, 2024 pm 10:13 PM
wps表格找不到正在搜尋的資料,請檢查搜尋選項位置
Mar 19, 2024 pm 10:13 PM
智能為主導的時代,辦公室軟體也普及開來,Wps表格由於它的靈活性被廣大的辦公室人員採用。在工作上要求我們不只是要學會簡單的表格製作和文字輸入,我們要掌握更多的操作技能,才能完成實際工作中的任務,有數據的報表,運用表格更方便更清楚更準確。今天我們帶給大家的課程是:wps表格找不到正在搜尋的資料,為什麼請檢查搜尋選項位置? 1.先選取Excel表格,雙擊開啟。然後在該介面中,選取所有的儲存格。 2、然後在該介面中,點選頂部工具列裡「檔案」裡的「編輯」選項。 3、其次在該介面中,點選頂部工具列裡的“
 多模態大模型最全綜述來了! 7位微軟研究員大力合作,5大主題,成文119頁
Sep 25, 2023 pm 04:49 PM
多模態大模型最全綜述來了! 7位微軟研究員大力合作,5大主題,成文119頁
Sep 25, 2023 pm 04:49 PM
多模態大模型最全綜述來了!由微軟7位華人研究員撰寫,足足119頁——它從目前已經完善的和還處於最前沿的兩類多模態大模型研究方向出發,全面總結了五個具體研究主題:視覺理解視覺生成統一視覺模型LLM加持的多模態大模型多模態agent並專注於一個現象:多模態基礎模型已經從專用走向通用。 Ps.這也是為什麼論文開頭作者就直接畫了一個哆啦A夢的形象。誰適合閱讀這份綜述(報告)?用微軟的原話來說:只要你有興趣學習多模態基礎模型的基礎知識和最新進展,無論你是專業研究員還是在校學生,這個內容都非常適合你一起來
 碾壓H100,英偉達下一代GPU曝光!首個3nm多晶片模組設計,2024年亮相
Sep 30, 2023 pm 12:49 PM
碾壓H100,英偉達下一代GPU曝光!首個3nm多晶片模組設計,2024年亮相
Sep 30, 2023 pm 12:49 PM
3奈米製程,性能超越H100!最近,根據外媒DigiTimes爆料,英偉達正在開發下一代GPU,代號為「Blackwell」的B100據稱,作為面向人工智慧(AI)和高性能計算(HPC)應用的產品,B100將採用台積電的3nm工藝過程,以及更為複雜的多晶片模組(MCM)設計,並將於2024年第四季現身。對於壟斷了人工智慧GPU市場80%以上份額的英偉達來說,則可以藉著B100趁熱打鐵,在這波AI部署的熱潮中進一步狙擊AMD、英特爾等挑戰者。根據英偉達的估計,到2027年,該領域的產值預計將達到約
 手機淘寶怎麼搜尋店鋪 搜尋店舖名的方法
Mar 13, 2024 am 11:00 AM
手機淘寶怎麼搜尋店鋪 搜尋店舖名的方法
Mar 13, 2024 am 11:00 AM
手機淘寶app軟體內提供的商品好物非常多,隨時隨地想買就買,而且件件都是正品,每一件商品的價格標籤一清二楚,完全沒有任何的複雜操作,享受更加便捷的購物樂趣。隨心所欲自由搜尋選購,不同品類的商品板塊都是開放的,添加個人的收貨地址以及聯絡電話,方便快遞公司聯繫到你,實時查看最新的物流動態,那麼有些新人用戶第一次使用它,不知道如何搜尋商品,當然只需要在搜尋欄輸入關鍵字就能找到所有的商品結果,自由選購根本停不下來,現在小編在線詳細為手機淘寶用戶們帶來搜尋店鋪名的方法。 1.先打開手機淘寶app,
