

Graph-DETR3D: 在多視角3D目標偵測中對重疊區域再思考

arXiv論文“Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection“,22年6月,中科大、哈工大和商湯科技的工作。

從多個影像視圖中偵測3-D目標是視覺場景理解的一項基本而富有挑戰性的任務。由於其低成本和高效率,多視圖3-D目標偵測顯示出了廣泛的應用前景。然而,由於缺乏深度訊息,透過3-D空間中的透視圖去精確檢測目標,極為困難。最近,DETR3D引入一種新的3D-2D query範式,用於聚合多視圖影像以進行3D目標檢測,並實現了最先進的性能。
本文透過密集的引導性實驗,量化了位於不同區域的目標,並發現「截斷實例」(即每個影像的邊界區域)是阻礙DETR3D效能的主要瓶頸。儘管在重疊區域中合併來自兩個相鄰視圖的多個特徵,但DETR3D仍然存在特徵聚合不足的問題,因此錯過了充分提高檢測性能的機會。
為了解決這個問題,提出Graph-DETR3D,透過圖結構學習(GSL)自動聚合多視圖影像資訊。在每個目標查詢和2-D特徵圖之間建立動態3D圖,以增強目標表示,尤其是在邊界區域。此外,Graph-DETR3D得益於一種新的深度不變(depth-invariant)多尺度訓練策略,其透過同時縮放影像大小和目標深度來保持視覺深度的一致性。
Graph-DETR3D的差異在於兩點,如圖所示:(1)動態圖特徵的聚合模組;(2)深度不變的多尺度訓練策略。它遵循DETR3D的基本結構,由三個組件組成:影像編碼器、transformer解碼器和目標預測頭。給定一組影像I={I1,I2,…,IK}(由N個週視攝影機捕捉),Graph-DETR3D旨在預測感興趣邊框的定位和類別。首先用影像編碼器(包括ResNet和FPN)將這些影像變成一組相對L個特徵圖級的特徵F。然後,建立一個動態3-D圖,透過動態圖特徵聚合(dynamic graph feature aggregation,DGFA)模組廣泛聚合2-D信息,優化目標查詢的表示。最後,利用增強的目標查詢輸出最終預測。
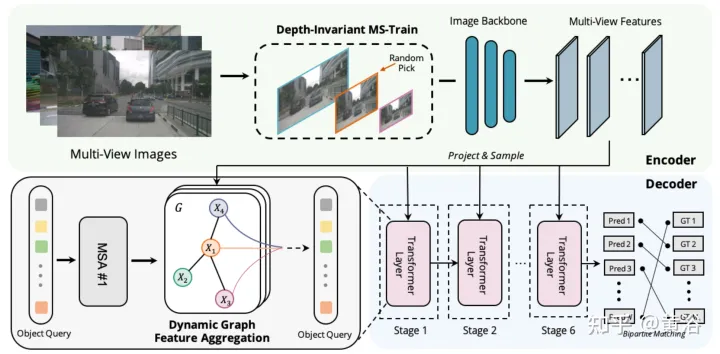
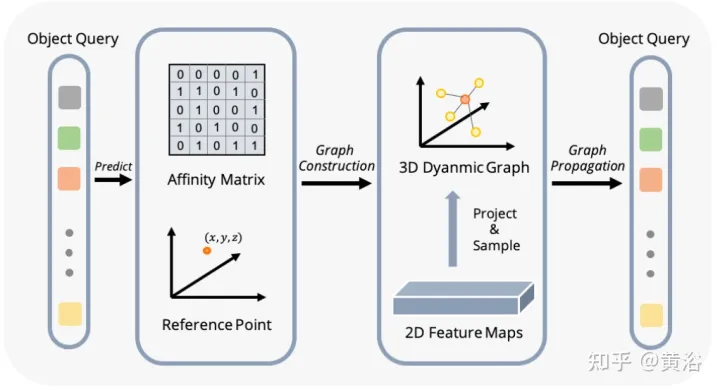
如圖顯示動態圖特徵聚合(DFGA)流程:首先為每個目標查詢建構一個可學習的3-D圖,然後從2-D影像平面採樣特徵。最後,透過圖連接(graph connections)增強了目標查詢的表示。這種相互連接的訊息傳播(message propagation)方案支援對圖結構構造和特徵增強的迭代細化方案。
多尺度訓練是2D和3D目標偵測任務中常用的資料增強策略,經證明有效且推理成本低。然而,它很少出現在基於視覺的3-D檢測方法中。考慮到不同輸入影像大小可以提高模型的穩健性,同時調整影像大小和修改攝影機內參來實現普通多尺度訓練策略。
一個有趣的現像是,最終的效能急劇下降。透過仔細分析輸入數據,發現簡單地重新縮放影像會導致透視-多義問題:當目標調整到較大/較小的比例時,其絕對屬性(即目標的大小、到ego point的距離)不會改變。
作為一個具體範例,如圖顯示這個多義問題:儘管(a)和(b)中所選區域的絕對3D位置相同,但影像像素的數量不同。深度預測網路傾向於基於影像的佔用面積來估計深度。因此,圖中的這種訓練模式可能會讓深度預測模型糊塗,並進一步惡化最終表現。

為此從像素透視重新計算深度。演算法偽代碼如下:

如下是解碼運算:

重新計算的像素大小是:
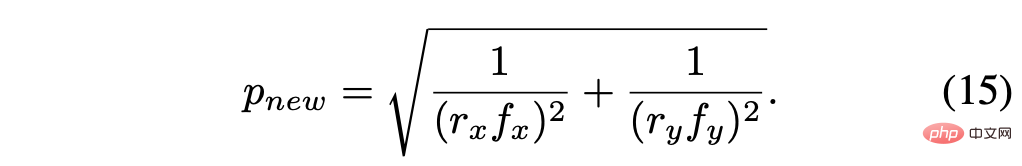
假設尺度因子r = rx = ry,則簡化得到:
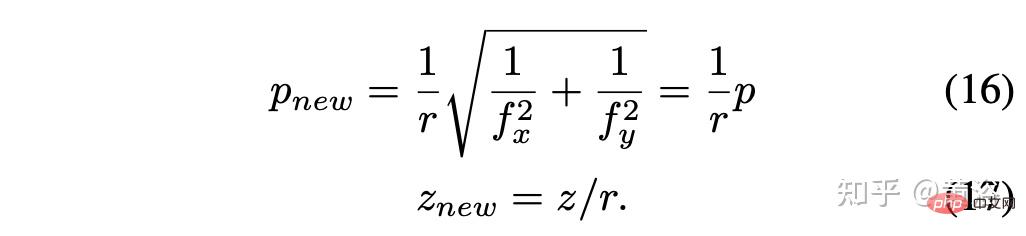
實驗結果如下:
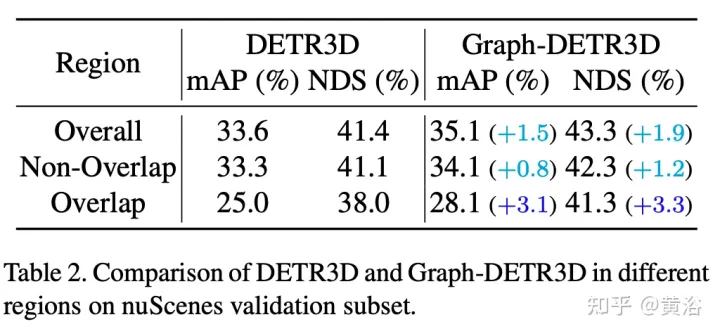
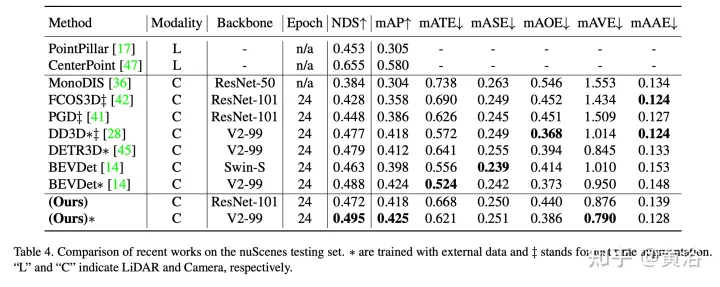
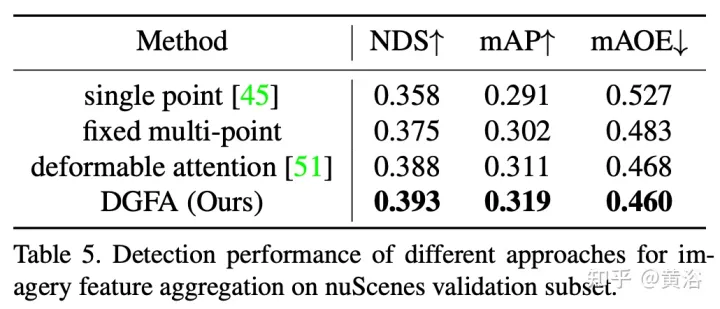
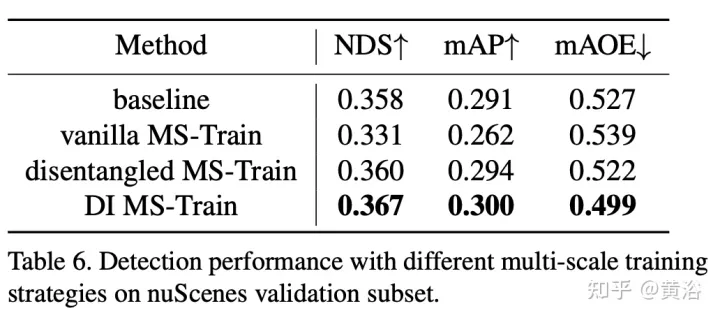
註:DI = Depth-Invariant
#以上是Graph-DETR3D: 在多視角3D目標偵測中對重疊區域再思考的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3的论文终于来了!这个模型于两周前发布,采用了与Sora相同的DiT(DiffusionTransformer)架构,一经发布就引起了不小的轰动。与之前版本相比,StableDiffusion3生成的图质量有了显著提升,现在支持多主题提示,并且文字书写效果也得到了改善,不再出现乱码情况。StabilityAI指出,StableDiffusion3是一个系列模型,其参数量从800M到8B不等。这一参数范围意味着该模型可以在许多便携设备上直接运行,从而显著降低了使用AI
 用於精確目標偵測的多網格冗餘邊界框標註
Jun 01, 2024 pm 09:46 PM
用於精確目標偵測的多網格冗餘邊界框標註
Jun 01, 2024 pm 09:46 PM
一、前言目前領先的目標偵測器是基於深度CNN的主幹分類器網路重新調整用途的兩級或單級網路。 YOLOv3就是這樣一種眾所周知的最先進的單級檢測器,它接收輸入圖像並將其劃分為大小相等的網格矩陣。具有目標中心的網格單元負責偵測特定目標。今天分享的,就是提出了一種新的數學方法,該方法為每個目標分配多個網格,以實現精確的tight-fit邊界框預測。研究者也提出了一種有效的離線複製貼上資料增強來進行目標偵測。新提出的方法顯著優於一些目前最先進的目標偵測器,並有望獲得更好的效能。二、背景目標偵測網路旨在使用
 你是否真正掌握了座標系轉換?自動駕駛離不開的多感測器問題
Oct 12, 2023 am 11:21 AM
你是否真正掌握了座標系轉換?自動駕駛離不開的多感測器問題
Oct 12, 2023 am 11:21 AM
一先導與重點文章主要介紹自動駕駛技術中幾種常用的座標系統,以及他們之間如何完成關聯與轉換,最終建構出統一的環境模型。這裡重點理解自車到相機剛體轉換(外參),相機到影像轉換(內參),影像到像素有單位轉換。 3d向2d轉換會有對應的畸變,平移等。重點:自車座標系相機機體座標系需要被重寫的是:平面座標系像素座標系難點:要考慮影像畸變,去畸變和加畸變都是在像平面上去補償二簡介視覺系統一共有四個座標系:像素平面座標系(u,v)、影像座標系(x,y)、相機座標系()與世界座標系()。每種座標系之間均有聯繫,
 DualBEV:大幅超越BEVFormer、BEVDet4D,開卷!
Mar 21, 2024 pm 05:21 PM
DualBEV:大幅超越BEVFormer、BEVDet4D,開卷!
Mar 21, 2024 pm 05:21 PM
這篇論文探討了在自動駕駛中,從不同視角(如透視圖和鳥瞰圖)準確檢測物體的問題,特別是如何有效地從透視圖(PV)到鳥瞰圖(BEV)空間轉換特徵,這一轉換是透過視覺轉換(VT)模組實施的。現有的方法大致分為兩種策略:2D到3D和3D到2D轉換。 2D到3D的方法透過預測深度機率來提升密集的2D特徵,但深度預測的固有不確定性,尤其是在遠處區域,可能會引入不準確性。而3D到2D的方法通常使用3D查詢來採樣2D特徵,並透過Transformer學習3D和2D特徵之間對應關係的注意力權重,這增加了計算和部署的
 自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
軌跡預測在自動駕駛中承擔著重要的角色,自動駕駛軌跡預測是指透過分析車輛行駛過程中的各種數據,預測車輛未來的行駛軌跡。作為自動駕駛的核心模組,軌跡預測的品質對於下游的規劃控制至關重要。軌跡預測任務技術堆疊豐富,需熟悉自動駕駛動/靜態感知、高精地圖、車道線、神經網路架構(CNN&GNN&Transformer)技能等,入門難度很高!許多粉絲期望能夠盡快上手軌跡預測,少踩坑,今天就為大家盤點下軌跡預測常見的一些問題和入門學習方法!入門相關知識1.預習的論文有沒有切入順序? A:先看survey,p
 目標偵測新SOTA:YOLOv9問世,新架構讓傳統卷積重煥生機
Feb 23, 2024 pm 12:49 PM
目標偵測新SOTA:YOLOv9問世,新架構讓傳統卷積重煥生機
Feb 23, 2024 pm 12:49 PM
在目标检测领域,YOLOv9在实现过程中不断进步,通过采用新架构和方法,有效提高了传统卷积的参数利用率,这使得其性能远超前代产品。继2023年1月YOLOv8正式发布一年多以后,YOLOv9终于来了!自2015年JosephRedmon和AliFarhadi等人提出了第一代YOLO模型以来,目标检测领域的研究者们对其进行了多次更新和迭代。YOLO是一种基于图像全局信息的预测系统,其模型性能不断得到增强。通过不断改进算法和技术,研究人员取得了显著的成果,使得YOLO在目标检测任务中表现出越来越强大
 GSLAM | 一個通用的SLAM架構和基準
Oct 20, 2023 am 11:37 AM
GSLAM | 一個通用的SLAM架構和基準
Oct 20, 2023 am 11:37 AM
突然發現了一篇19年的論文GSLAM:AGeneralSLAMFrameworkandBenchmark開源程式碼:https://github.com/zdzhaoyong/GSLAM直接上全文,感受這項工作的品質吧~1摘要SLAM技術最近取得了許多成功,並吸引了高科技公司的關注。然而,如何同一現有或新興演算法的介面,一級有效地進行關於速度、穩健性和可移植性的基準測試仍然是問題。本文,提出了一個名為GSLAM的新型SLAM平台,它不僅提供評估功能,還為研究人員提供了快速開發自己的SLAM系統的有用
 首個多視角自動駕駛場景影片產生世界模型 | DrivingDiffusion: BEV資料與模擬新思路
Oct 23, 2023 am 11:13 AM
首個多視角自動駕駛場景影片產生世界模型 | DrivingDiffusion: BEV資料與模擬新思路
Oct 23, 2023 am 11:13 AM
作者的一些個人思考在自動駕駛領域,隨著BEV-based子任務/端到端方案的發展,高品質的多視圖訓練資料和相應的模擬場景建立愈發重要。針對當下任務的痛點,「高品質」可以解耦成三個面向:不同維度上的長尾場景:如障礙物資料中近距離的車輛以及切車過程中精準的朝向角,以及車道線資料中不同曲率的彎道或較難收集的匝道/匯入/合流等場景。這些往往靠大量的資料收集和複雜的資料探勘策略,成本高昂。 3D真值-影像的高度一致:當下的BEV資料取得往往受到感測器安裝/標定,高精地圖以及重建演算法本身的誤差影響。這導致了我
