

在 Python中處理大型機器學習資料集的簡單方法

本文的目標受眾:
- 想要對大量資料集執行 Pandas/NumPy 操作的人。
- 希望使用Python在大數據上執行機器學習任務的人。

本文將使用 .csv 格式的檔案來示範 python 的各種操作,其他格式如陣列、文字檔案等也是如此。
為什麼我們不能將 pandas 用於大型機器學習資料集呢?
我們知道Pandas 使用電腦記憶體(RAM) 來載入您的機器學習資料集,但是,如果您的電腦有8 GB 的記憶體(RAM),那麼為什麼pandas 仍然無法載入2 GB 的資料集呢?原因是使用 Pandas 加載 2 GB 檔案不僅需要 2 GB RAM,還需要更多內存,因為總內存需求取決於資料集的大小以及您將在該資料集上執行的操作。
以下是載入到電腦記憶體中的不同大小的資料集的快速比較:
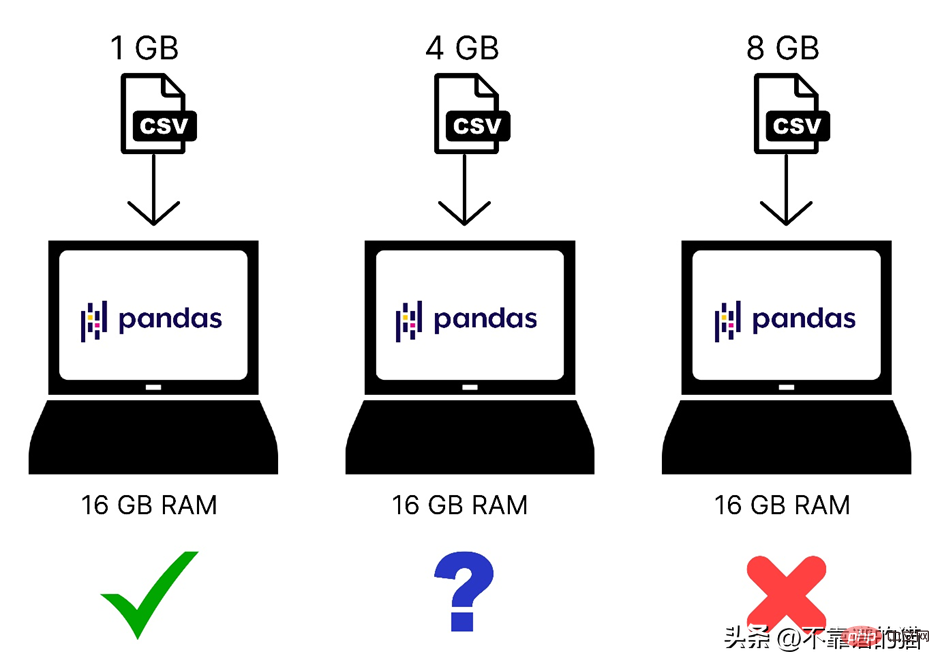
#此外,Pandas只使用作業系統的一個內核,這使得處理速度很慢。換句話說,我們可以說pandas不支持並行(將一個問題分解成更小的任務)。
假設電腦有4 個內核,下圖是載入CSV 檔案的時候pandas 使用的內核數:
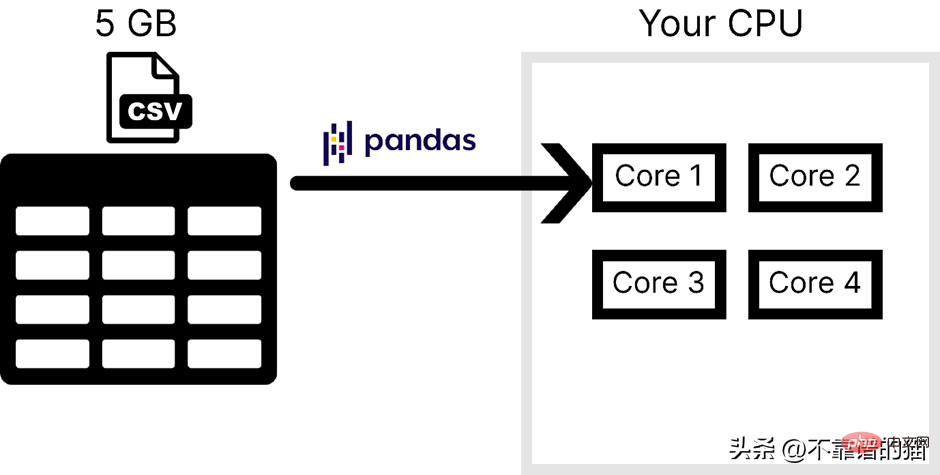
普遍不使用pandas 處理大型機器學習資料集的主要原因有以下兩點,一是電腦記憶體使用量,二是缺乏並行性。在 NumPy 和 Scikit-learn中,對於大數據集也面臨相同的問題。
為了解決這兩個問題,可以使用名為Dask的python函式庫,它能夠使我們在大型資料集上執行pandas、NumPy和ML等各種操作。
Dask是如何運作的?
Dask是在分區中載入你的資料集,而pandas通常是將整個機器學習資料集作為一個dataframe。在Dask中,資料集的每個分區都被認為是一個pandas dataframe。
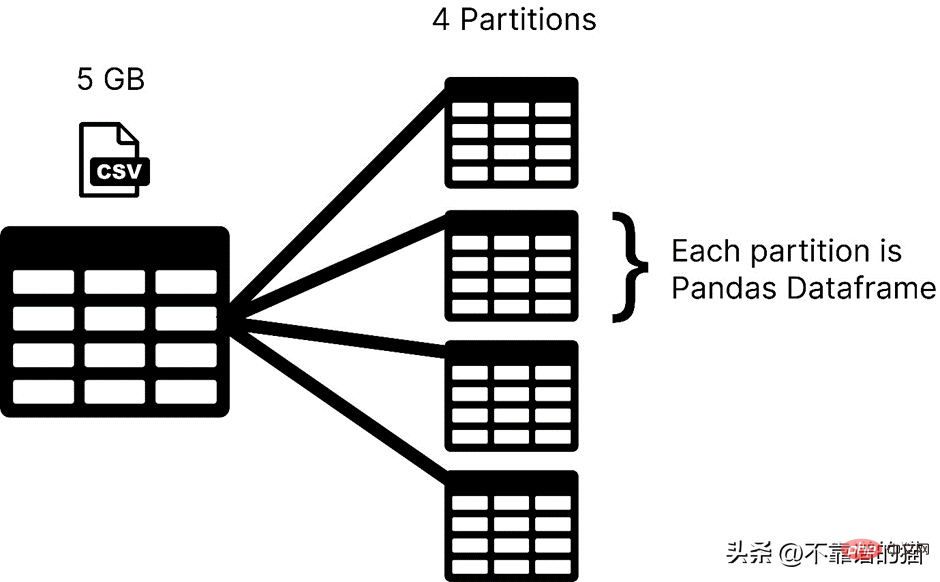
Dask 一次載入一個分割區,因此您不必擔心出現記憶體分配錯誤問題。
以下是使用dask 在電腦記憶體中載入不同大小的機器學習資料集的比較:
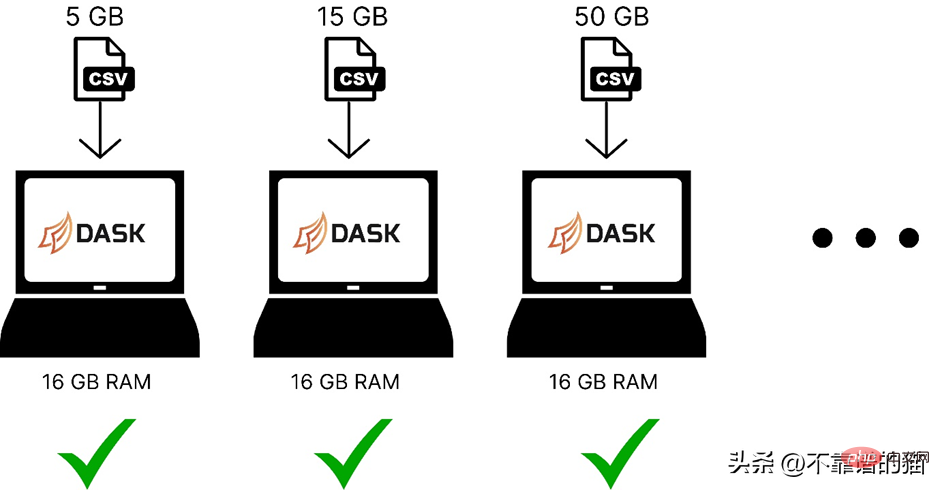
Dask 解決了平行性問題,因為它將資料拆分為多個分區,每個分區使用一個單獨的內核,這使得資料集上的計算更快。
假設電腦有4 個內核,以下是dask 在載入5 GB csv 檔案時的方式:
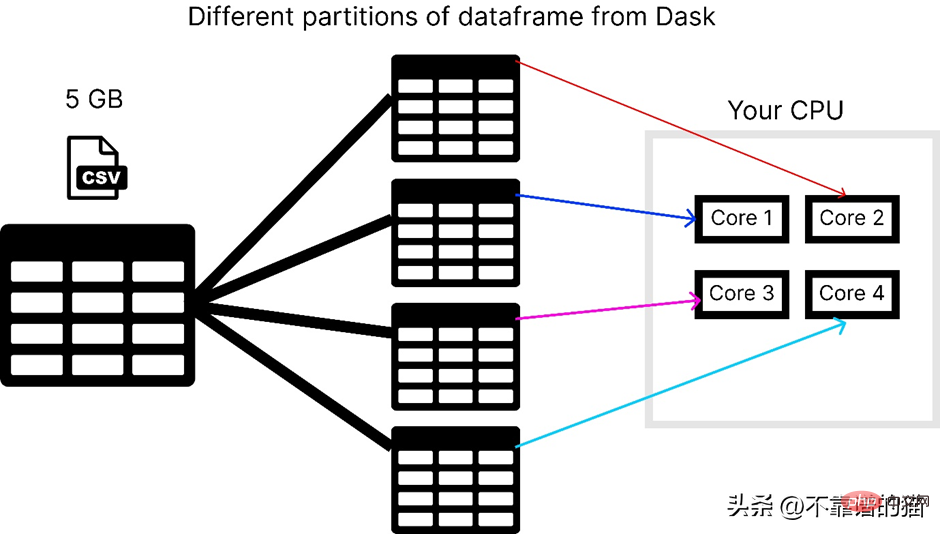
要使用dask 函式庫,您可以使用下列指令進行安裝:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>
Dask 有幾個模組,如dask.array、dask.dataframe 和dask.distributed,只有在您分別安裝了對應的函式庫(如NumPy、pandas 和Tornado)後才能運作。
如何使用 dask 處理大型 CSV 檔案?
dask.dataframe 用於處理大型 csv 文件,首先我嘗試使用 pandas 導入大小為 8 GB 的資料集。
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pandas</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">as</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">df</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">read_csv</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">“data</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">csv”</span>)
它在我的 16 GB 記憶體筆記型電腦中引發了記憶體分配錯誤。
現在,嘗試使用dask.dataframe 導入相同的8 GB 資料
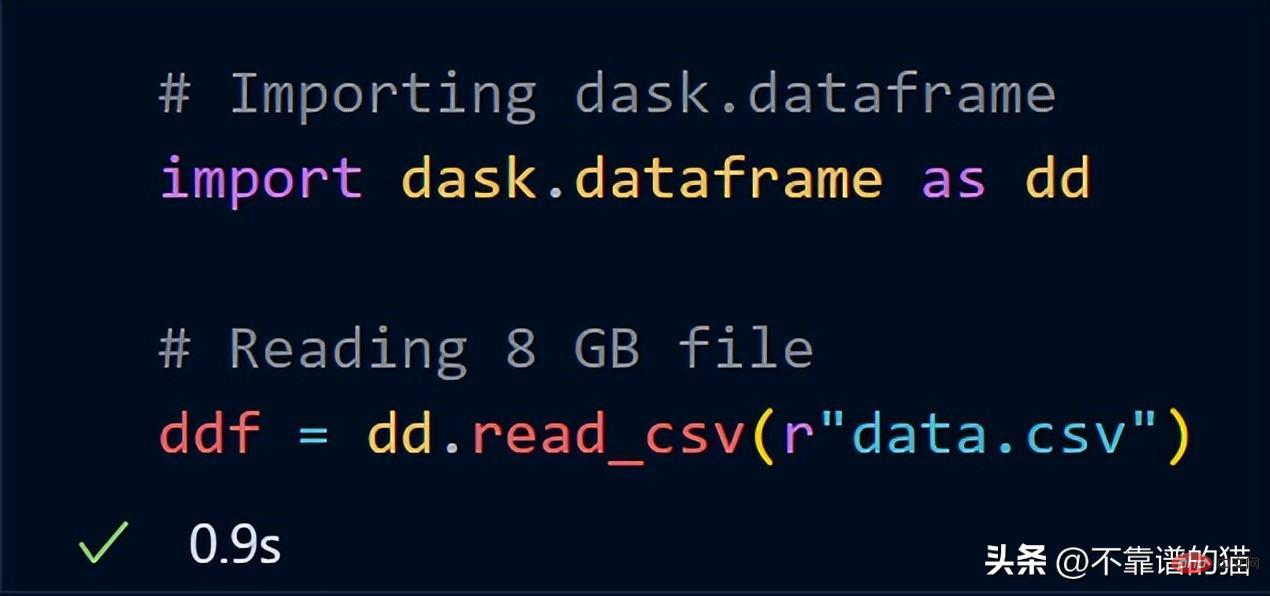
#dask 只花了一秒鐘就將整個8 GB 檔案載入到ddf變數中。
讓我們看看 ddf 變數的輸出。
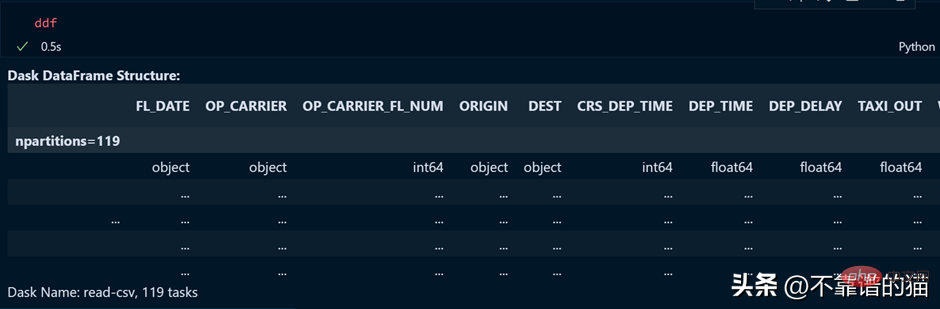
如您所見,執行時間為 0.5 秒,這裡顯示已分割為 119 個分割區。
您還可以使用以下方法檢查資料幀的分區數:
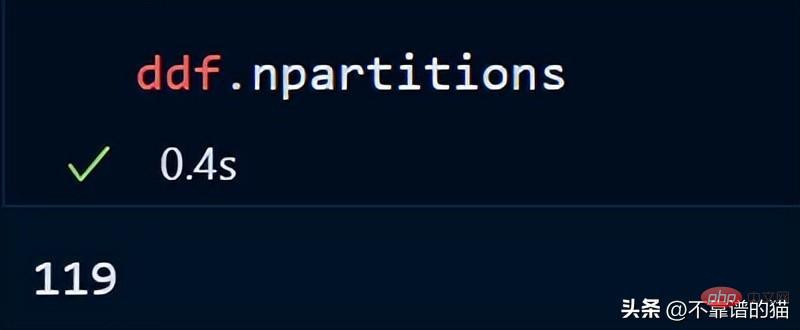
#預設情況下,dask 將我的8 GB CSV 檔案載入到119 個分區(每個分區大小為64MB),這是根據可用的實體記憶體和電腦的核心數來完成的。
也可以在載入 CSV 檔案時使用 blocksize 參數指定我自己的分割區數。
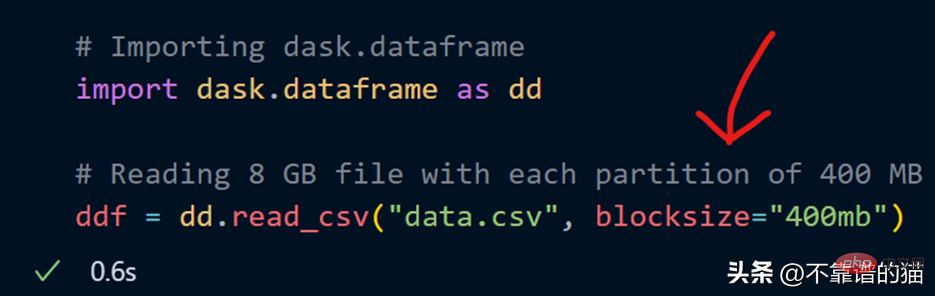
現在指定了字串值為400MB 的blocksize 參數,這使得每個分割區大小為400 MB,讓我們看看有多少個分割區
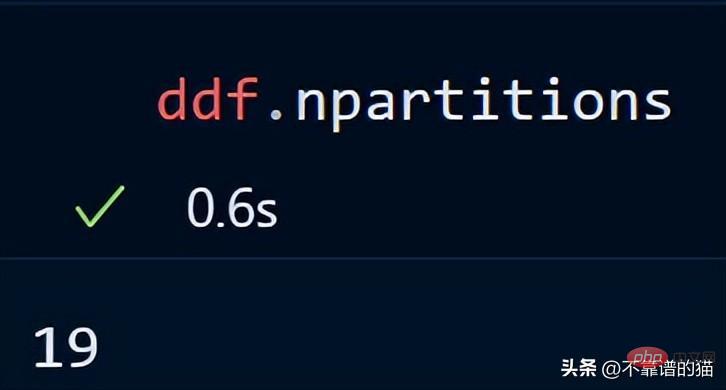
關鍵點:使用Dask DataFrames 時,一個好的經驗法則是將分割區保持在100MB 以下。
使用下列方法可呼叫dataframe的特定分割區:
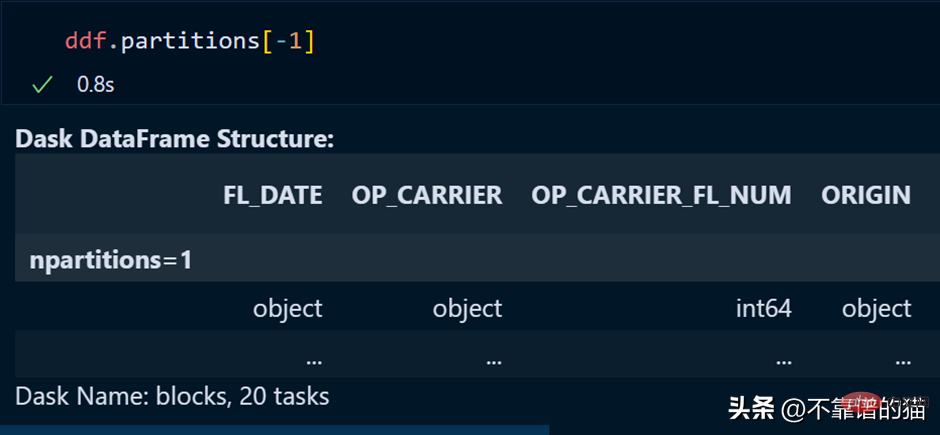
也可透過使用負索引來呼叫最後一個分割區,就像我們在呼叫清單的最後一個元素時所做的那樣。
讓我們看看資料集的形狀:
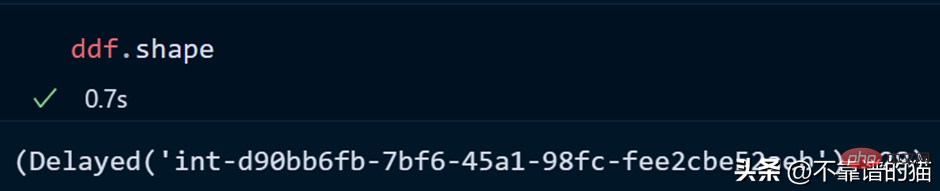
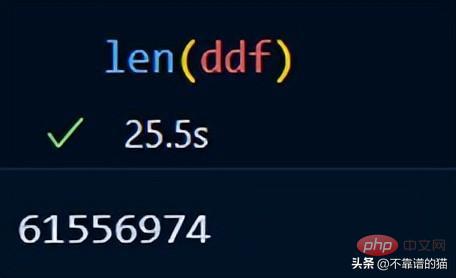
您可以使用len() 檢查資料集的行數:
#Dask 已經包含了範例資料集。我將使用時間序列資料向您展示 dask 如何對資料集執行數學運算。
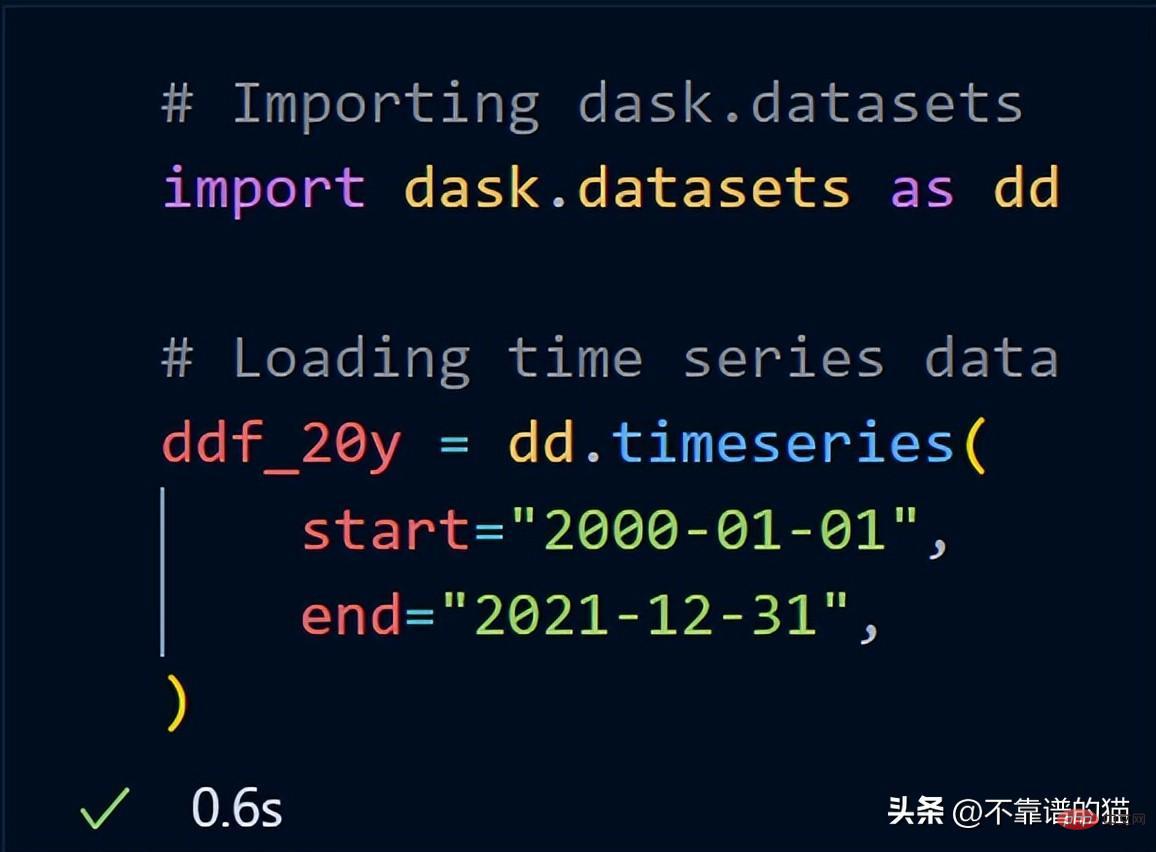
導入dask.datasets後,ddf_20y 載入了從 2000 年 1 月 1 日到 2021 年 12 月 31 日的時間序列資料。
讓我們看看我們的時間序列資料的分區數。
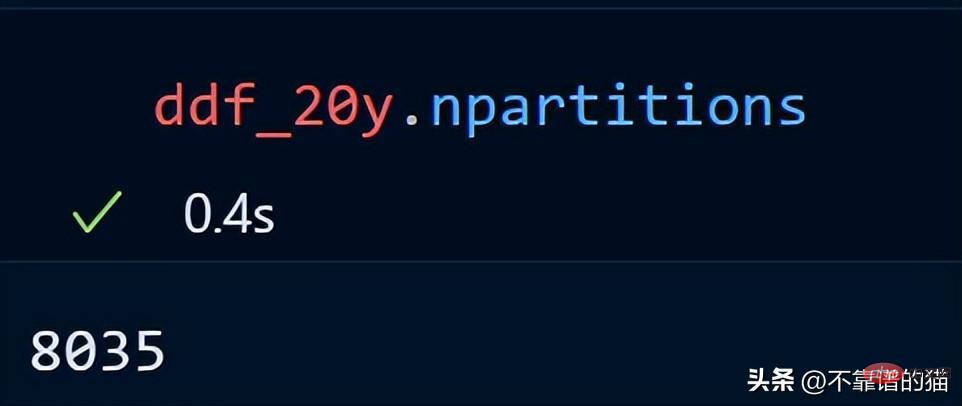
20 年的時間序列資料分佈在 8035 個分割區。
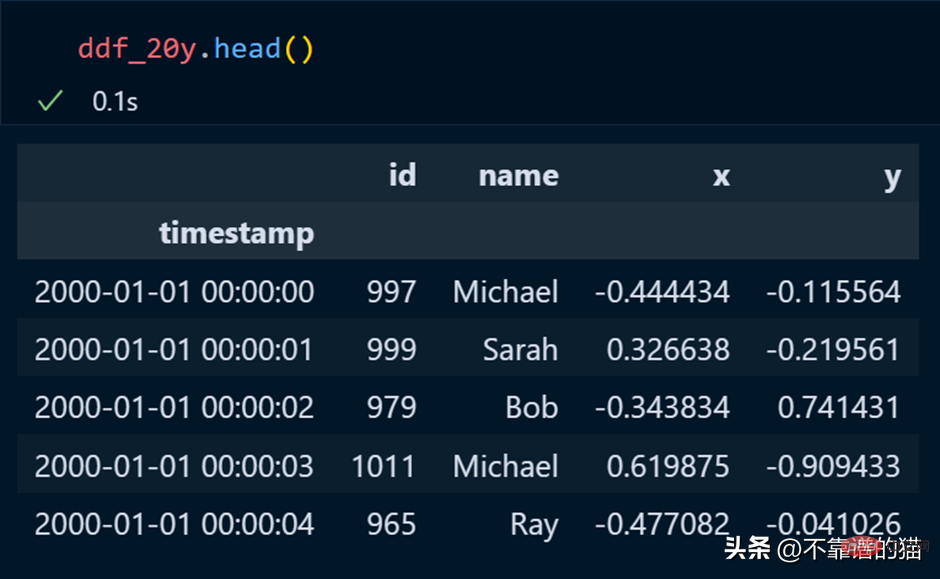
在 pandas 中,我們使用 head 列印資料集的前幾行,dask 也是這樣。
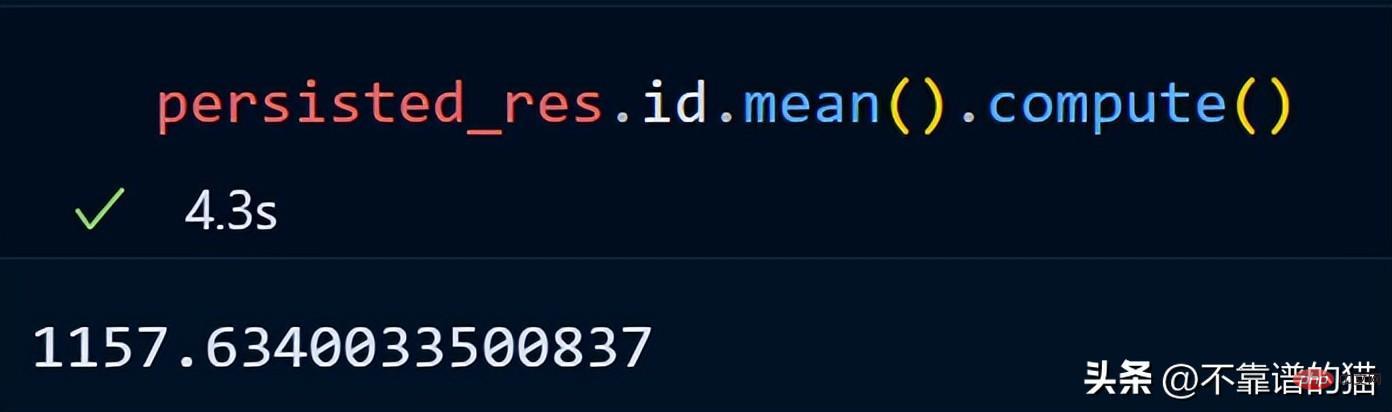
讓我們計算 id 列的平均值。
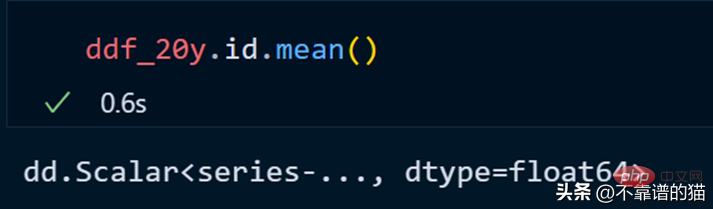
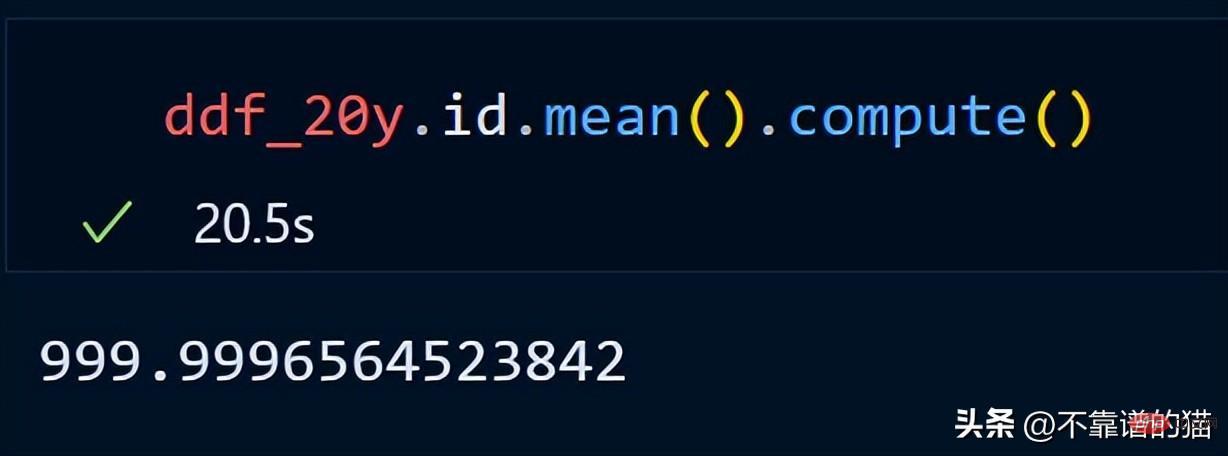
dask不會列印dataframe的總行數,因為它使用惰性計算(直到需要時才顯示輸出)。為了顯示輸出,我們可以使用compute方法。
假設我想將資料集的每一列進行歸一化(將值轉換為0到1之間),Python程式碼如下:
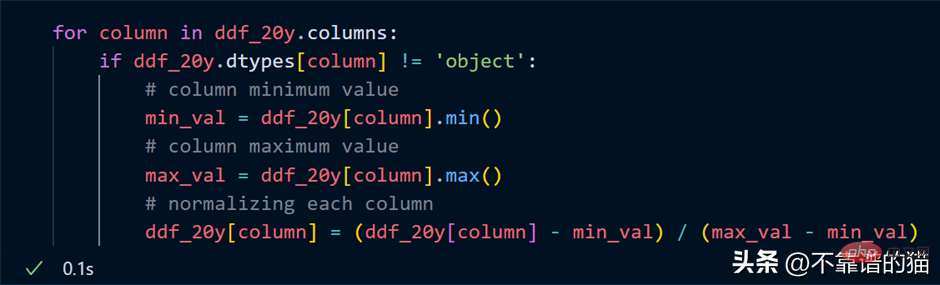
循環遍歷列,找到每列的最小值和最大值,並使用簡單的數學公式對這些列進行歸一化。
關鍵點:在我們的歸一化範例中,不要認為會發生實際的數值計算,它只是惰性求值(在需要之前永遠不會向您顯示輸出)。
為什麼要使用 Dask 陣列?
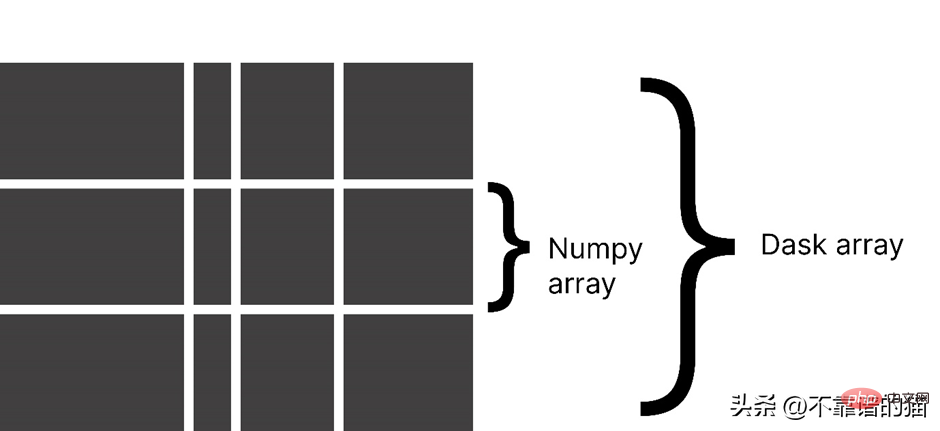
Dask 將陣列分成小塊,其中每個區塊都是一個 NumPy 陣列。
dask.arrays 用於處理大數組,以下Python程式碼使用 dask 建立了一個 10000 x 10000 的數組並將其儲存在 x 變數中。
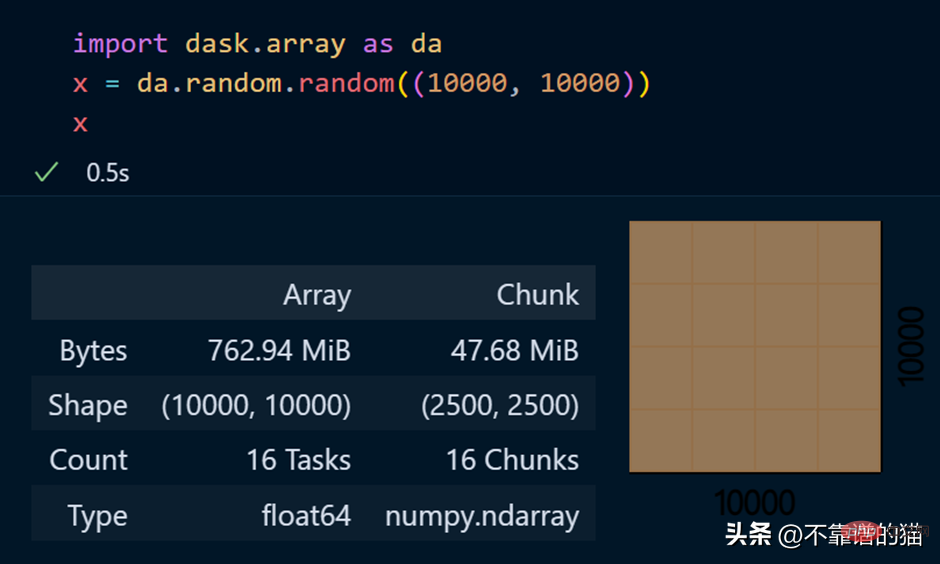
呼叫該 x 變數會產生有關陣列的各種資訊。
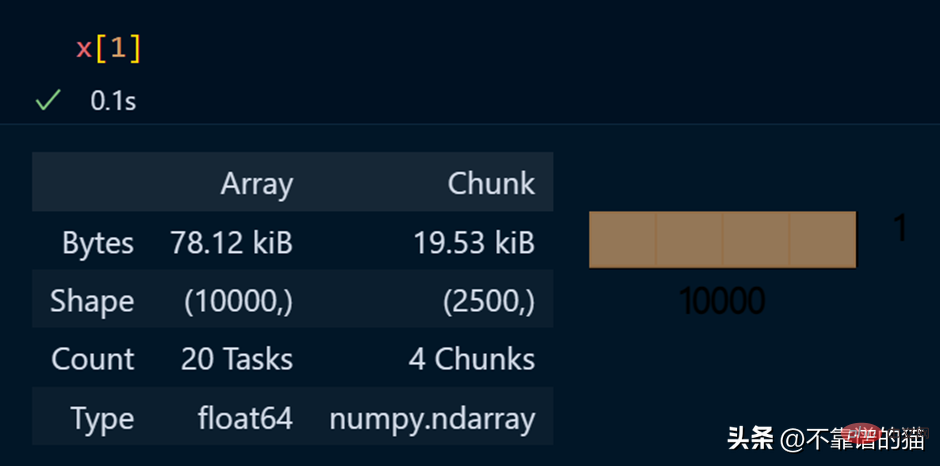
查看陣列的特定元素
對dask 陣列進行數學運算的Python範例:
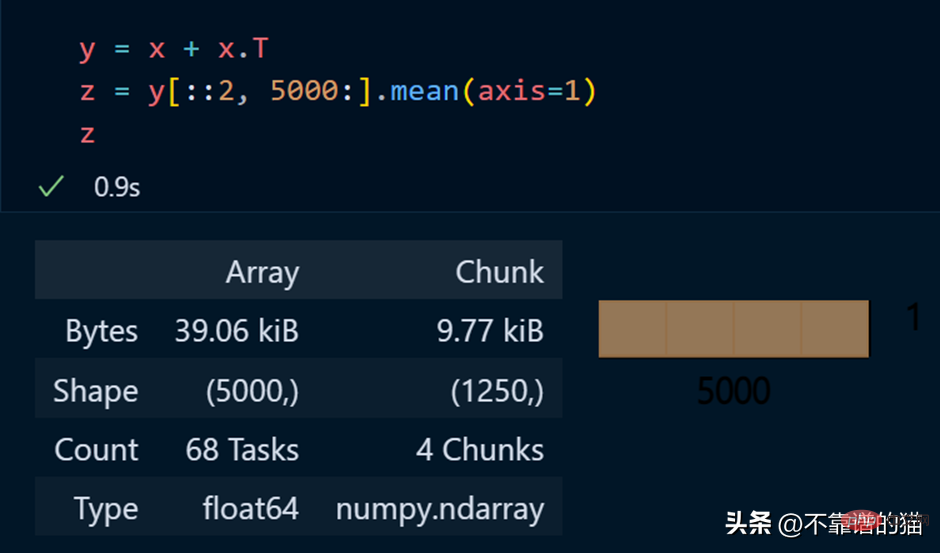
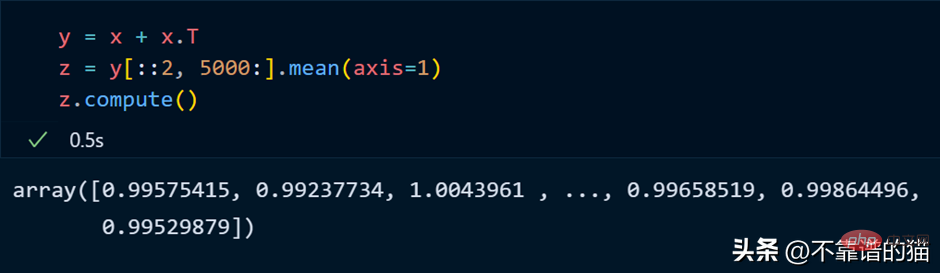
正如您所看到的,由于延迟执行,它不会向您显示输出。我们可以使用compute来显示输出:
dask 数组支持大多数 NumPy 接口,如下所示:
- 数学运算:+, *, exp, log, ...
- sum(), mean(), std(), sum(axis=0), ...
- 张量/点积/矩阵乘法:tensordot
- 重新排序/转置:transpose
- 切片:x[:100, 500:100:-2]
- 使用列表或 NumPy 数组进行索引:x[:, [10, 1, 5]]
- 线性代数:svd、qr、solve、solve_triangular、lstsq
但是,Dask Array 并没有实现完整 NumPy 接口。
你可以从他们的官方文档中了解更多关于 dask.arrays 的信息。
什么是Dask Persist?
假设您想对机器学习数据集执行一些耗时的操作,您可以将数据集持久化到内存中,从而使数学运算运行得更快。
从 dask.datasets 导入了时间序列数据
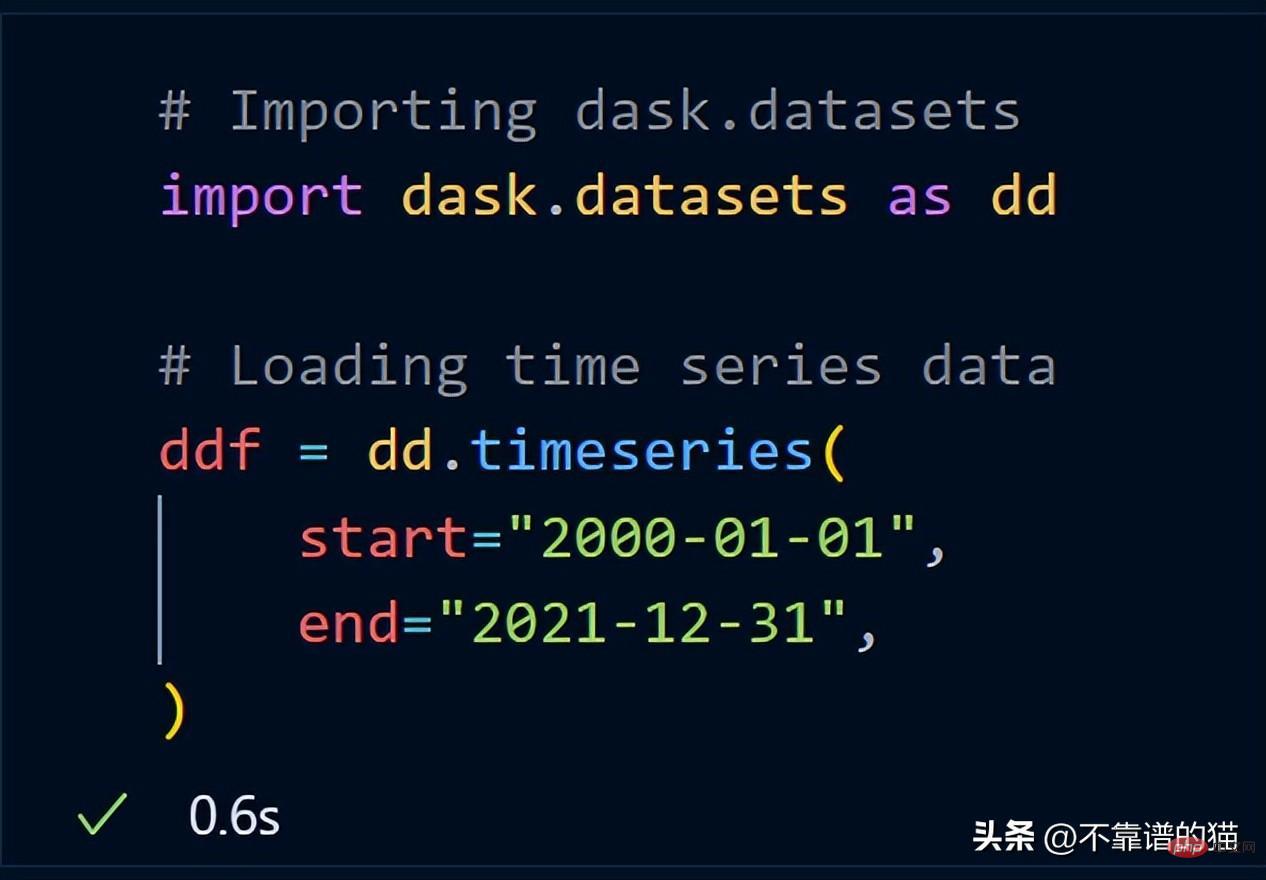
让我们取数据集的一个子集并计算该子集的总行数。
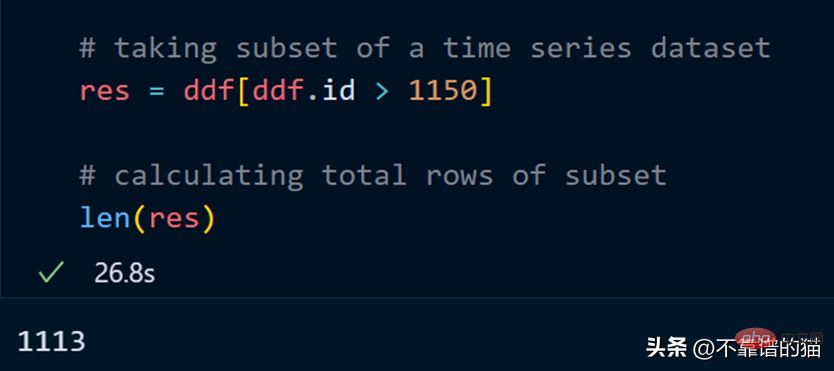
计算总行数需要 27 秒。
我们现在使用 persist 方法:
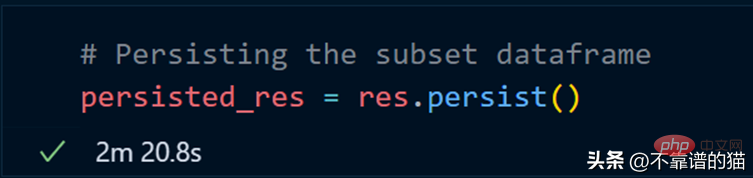
持久化我们的子集总共花了 2 分钟,现在让我们计算总行数。
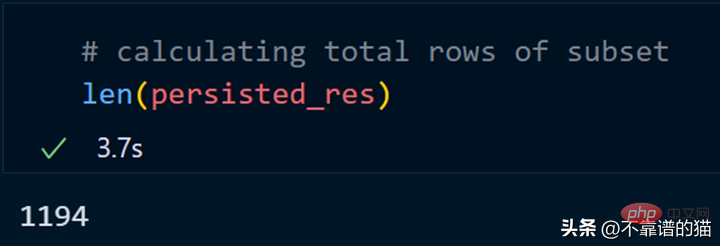
同样,我们可以对持久化数据集执行其他操作以减少计算时间。
persist应用场景:
- 数据量大
- 获取数据的一个子集
- 对子集应用不同的操作
为什么选择 Dask ML?
Dask ML有助于在大型数据集上使用流行的Python机器学习库(如Scikit learn等)来应用ML(机器学习)算法。
什么时候应该使用 dask ML?
- 数据不大(或适合 RAM),但训练的机器学习模型需要大量超参数,并且调优或集成技术需要大量时间。
- 数据量很大。
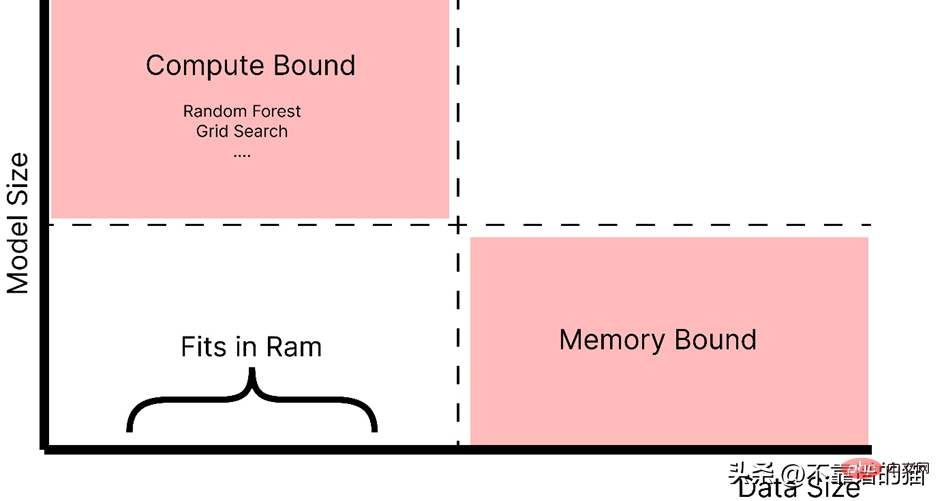
正如你所看到的,随着模型大小的增加,例如,制作一个具有大量超参数的复杂模型,它会引起计算边界的问题,而如果数据大小增加,它会引起内存分配错误。因此,在这两种情况下(红色阴影区域)我们都使用 Dask 来解决这些问题。
如官方文档中所述,dask ml 库用例:
- 对于内存问题,只需使用 scikit-learn(或其他ML 库)。
- 对于大型模型,使用 dask_ml.joblib 和scikit-learn estimators。
- 对于大型数据集,使用 dask_ml estimators。
让我们看一下 Dask.distributed 的架构:
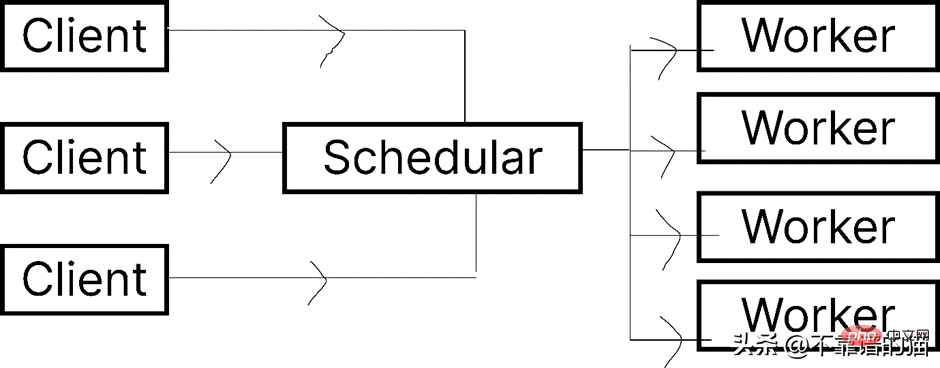
Dask 让您能够在计算机集群上运行任务。在 dask.distributed 中,只要您分配任务,它就会立即开始执行。
简单地说,client就是提交任务的你,执行任务的是Worker,调度器则执行两者之间通信。
python -m <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span> distributed –upgrade
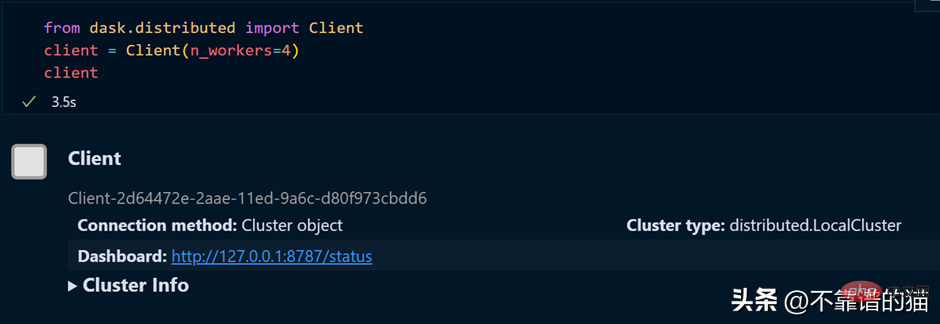
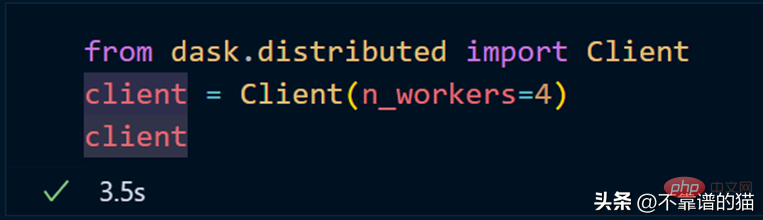
如果您使用的是单台机器,那么就可以通过以下方式创建一个具有4个worker的dask集群
如果需要dashboard,可以安装bokeh,安装bokeh的命令如下:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">bokeh</span>
就像我们从 dask.distributed 创建客户端一样,我们也可以从 dask.distributed 创建调度程序。
要使用 dask ML 库,您必须使用以下命令安装它:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>-ml
我们将使用 Scikit-learn 库来演示 dask-ml 。
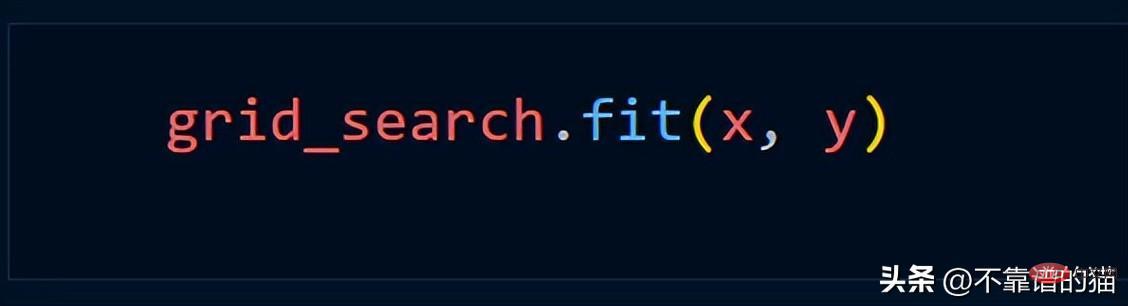
假設我們使用Grid_Search 方法,我們通常使用以下Python程式碼
#使用dask.distributed 建立一個叢集:
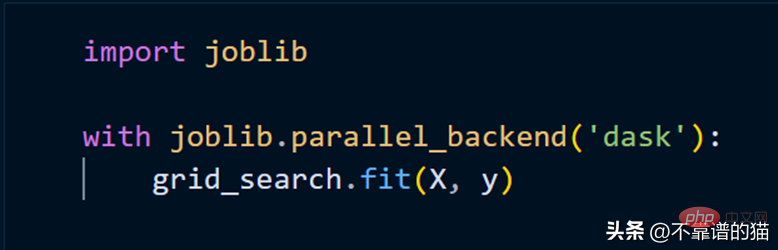
要使用群集來擬合scikit-learn 模型,我們只需要使用joblib。
以上是在 Python中處理大型機器學習資料集的簡單方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
