

深入報告:大模型驅動 AI 全面加速!黃金十年開啟

經歷過去70 年的“三起兩落”,伴隨底層晶片、算力、數據等基礎設施的完善&進步,全球AI 產業正逐步從運算智能走向感知智能、認知智能,並相應形成「晶片、算力設施、AI 框架&演算法模型、應用場景」的產業分工、協作體系。自2019年以來,AI 大模型帶來問題泛化求解能力大幅提升,「大模型小模型」逐步成為產業主流技術路線,驅動全球AI 產業發展全面加速,並形成「晶片算力基礎設施AI 框架&演算法庫應用場景」的穩定產業價值鏈結構。
本期的智慧內參,我們推薦中信證券的報告《大模型驅動 AI 全面提速,產業黃金十年投資週期開啟》,解讀人工智慧產業現況與產業發展核心問題。資料來源:中信證券
一、人工智慧的「三起三落」
自1956 年「人工智慧」概念&理論首次被提出,AI 產業&科技發展主要經歷三大發展階段。
1 ) 20 世紀 50 年代 ~20 世紀 70 年代:受制於算力表現、資料量等,更停留在理論 層次。 1956 年達特茅斯會議推動了全球第一次人工智慧浪潮的出現,當時樂觀的氣氛瀰漫著整個學界,在演算法方面出現了很多世界級的發明,其中包括一種叫做增強學習的雛形,增強學習就是GoogleAlphaGo 演算法核心思想內容。而 70 年代初,AI 遭遇了瓶頸:人們發現邏輯證明器、感知器、增強學習等只能做很簡單、用途狹隘的任務,稍微超出範圍就無法應付。當時的電腦有限的記憶體和處理速度不足以解決任何實際的 AI 問題。這些計算複雜度以指數程度增加,成為了不可能的計算任務。
2 ) 20 世紀 80 年代 ~20 世紀 90 年代:專家系統是人工智慧的第一次商業化嘗試,高 昂的硬體成本、有限的適用場景限制了市場的進一步向前發展。 在 80 年代,專家系統 AI程式開始為全世界的公司所採納,而「知識處理」成為了主流 AI 研究的焦點。專家系統的能力來自於它們儲存的專業知識,知識庫系統和知識工程成為了 80 年代 AI 研究的主要方向。但是專家系統的實用性僅限於某些特定情景,不久後人們對專家系統的狂熱追捧轉向巨大的失望。另一方面,1987 年到 1993 年現代 PC 的出現,其費用遠低於專家系統所使用的 Symbolics 和 Lisp 等機器。相較於現代 PC,專家系統被認為古老陳舊而非常難以維護。於是,政府經費開始下降,寒冬又一次來臨。
3 ) 2015 年至今:逐步形成完整的產業鏈分工、協作系統。 人工智慧第三起的標誌性事件發生在 2016 年 3 月,Google DeepMind 研發的 AlphaGo 在圍棋人機大戰中擊敗韓國職業九段棋手李世石。隨後,大眾開始熟知人工智慧,各領域的熱情都被調動起來。這次事件確立了以 DNN 神經網路演算法為基礎的統計分類深度學習模型,這類模型相比於過往更加泛化,透過不同的特徵值提取可以適用於不同的應用場景中。同時,2010 年-2015 年行動互聯網的普及也為深度學習演算法帶來了前所未有的資料養分。得益於資料量的上漲、運算力的提升和機器學習新演算法的出現,人工智慧開始大調整。人工智慧的研究領域也不斷擴大,包括專家系統、機器學習、演化計算、模糊邏輯、電腦視覺、自然語言處理、推薦系統等。深度學習的發展,讓人工智慧進入新的發展高潮。
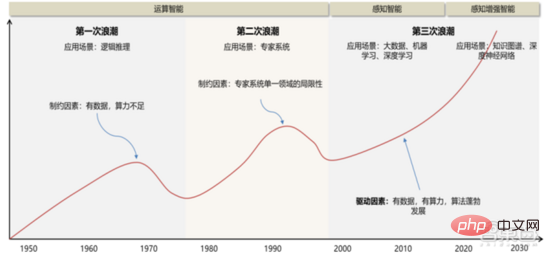
▲ 人工智慧發展的三波浪潮
人工智慧第三波帶給我們一批能給商業化落地的場景,DNN 演算法的優秀表現讓語音辨識與影像辨識在安防、教育領域貢獻了第一批成功的商業案例。而近年來基於神經網路演算法之上的 Transformer 等演算法的開發讓 NLP(自然語言處理)的商業化也提上了日程,預計在未來 3-5 年看到成熟的商業化場景。
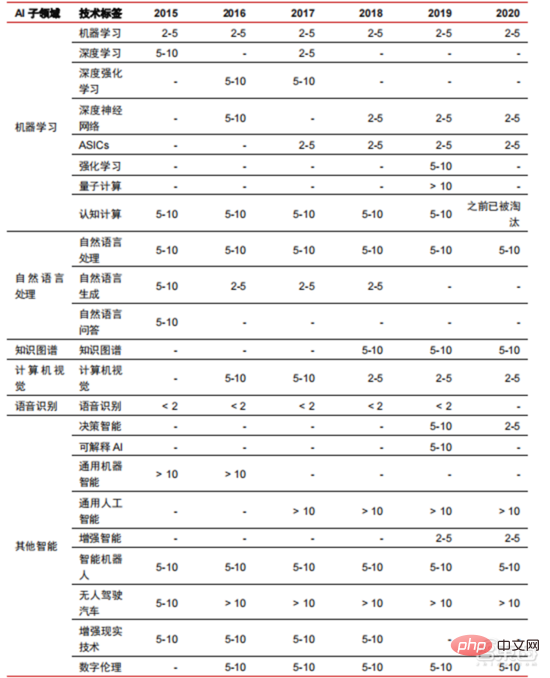
▲ 人工智慧技術產業化所需年數
二、分工逐步完整,落地場景不斷拓展
經歷過去5~6 年的發展,全球AI 產業正逐步形成分工協作、完整的產業鏈結構,並開始在部分領域形成典型應用情境。
1、AI 晶片:從 GPU 到 FPGA 、 ASIC 等,效能不斷提升
晶片是 AI 產業的製高點 。本輪人工智慧產業繁榮,緣於大幅提升的 AI 算力,使得深度學習和多層神經網路演算法成為可能。 人 工智慧在各行業迅速滲透,資料隨之大量成長,導致演算法模型極為複雜,處理物件異構,運算效能要求高。因此人工智慧深度學習需要異常強大的平行處理能力,與CPU 相比,AI 晶片擁有更多邏輯運算單元(ALU)用於資料處理,適合對密集型資料進行並行處理,主要類型包括圖形處理器( GPU)、現場可程式閘陣列(FPGA)、專用積體電路(ASIC)等。
從使用場景來看,相關硬體包括:雲側推理晶片、雲端側測試晶片、終端處理晶片、IP 核心等。在雲端的「訓練」或「學習」環節,英偉達 GPU 具備較強競爭優勢,Google TPU 也在積極拓展市場與應用。在終端的「推理」應用領域 FPGA 和 ASIC 可能具備優勢。美國在 GPU 與 FPGA 領域較強優勢,擁有英偉達、賽靈思、AMD 等優勢企業,Google、亞馬遜也積極開發 AI 晶片。
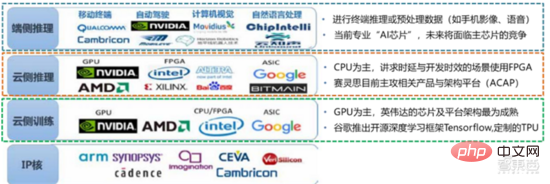
▲ 晶片在不同AI 環節的應用
▲ 人工智慧神經網路演算法模型複雜度
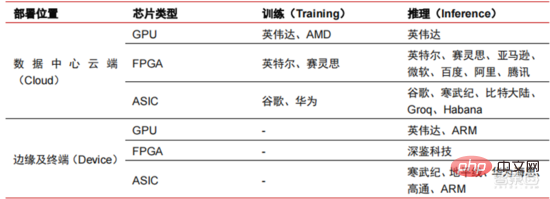
▲ 晶片廠商佈局
在高效能運算市場,借助AI 晶片的平行運算能力實現對複雜問題的求解是目前的主流方案。根據 Tractica 數據顯示,2019 年全球 AI HPC市場規模約 13.6 億美元,預計到 2025 年市場規模達 111.9 億美元,7 年 CAGR 為 35.1%。 AI HPC 市場規模佔 2019 年的 13.2% 提高至 2025 年的 35.5%。同時 Tractica 數據顯示,2019 年全球 AI 晶片市場規模為 64 億美元,預計到 2023 年市場規模達 510 億美元,市場空間成長近 10 倍。
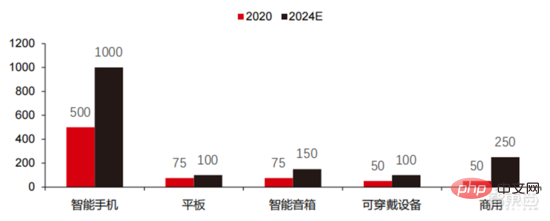
▲ 邊緣運算晶片出貨量(百萬,按終端設備)
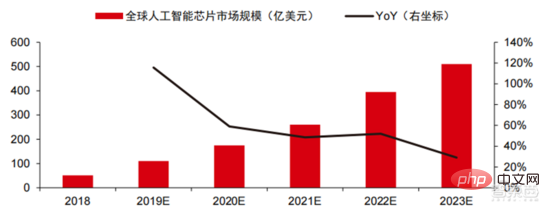
▲ 全球人工智慧晶片市場規模(億美元)
近兩年內,國內湧現了大量自研的晶片類公司,以自研GPU 的摩爾線程、自研自動駕駛晶片的寒武紀等為代表。摩爾線程於 2022 年 3 月發布了 MUSA 統一系統架構及第一代晶片“蘇堤”,摩爾線程的新架構支援英偉達的 cuda 架構。根據IDC 數據,在2021 年上半年中國人工智慧晶片中,GPU 一直是市場首選,佔有90%以上的市場份額,但隨其他晶片的穩步發展,預計到2025 年GPU 佔比將逐步降低至80% 。
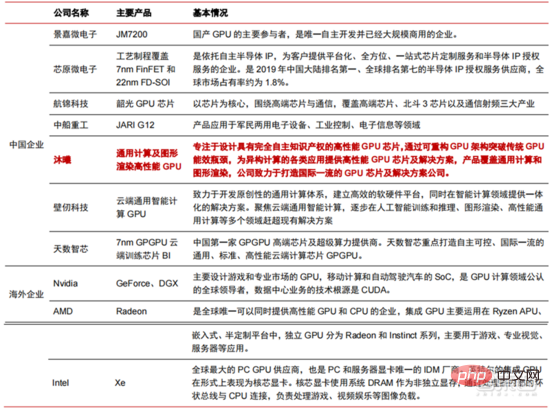
▲ GPU 晶片主要玩家及技術路線狀況
2、 算力設施:借助雲端運算、自建等方式,算力規模、單位成本等指標不斷改善
過去算力發展有效緩解了人工智慧的發展瓶頸。 人工智慧作為一個年代久遠的概念,過去的發展一直受限於算力不足,其算力需求的主要來自兩個面向:1)人工智慧最大挑戰之一是辨識度與準確度不高,而要提高準確度就需要提高模型的規模和精確度,這就需要更強的算力支撐。 2)隨著人工智慧的應用場景逐漸落地,圖像、語音、機器視覺和遊戲等領域的數據呈現爆發性增長,也對算力提出了更高的要求,使得計算技術進入新一輪高速創新期。而過去十幾年算力的發展有效緩解了人工智慧的發展瓶頸,未來智慧運算將呈現出需求更大、效能要求更高、需求隨時隨地且多樣化的特性。
由於接近物理極限,算力成長的摩爾定律逐步失效,算力產業正處於多要素綜合創新 階段。 過去算力供應提升主要透過製程製程微縮,即在同一晶片內增加電晶體堆疊的數量來提高運算效能。但隨著製程製程不斷逼近物理極限,成本不斷提高,使得摩爾定律逐漸失效,算力產業進入後摩爾時代,算力供應需要透過多要素綜合創新提高。目前算力供給有四個層面:單晶片算力、整機算力、資料中心算力和網路化算力,分別透過不同技術進行持續演進升級,以滿足智慧時代多樣化算力的供給需求。此外,透過軟硬體系統的深度融合與演算法最佳化提升計算系統整體效能,也是算力產業演進的重要方向。
算力規模: 根據中國信通院2021 年發布的《中國算力發展指數白皮書》,2020 年全球算力總規模依舊保持增長態勢,總規模達429EFlops,年增39%,其中基礎算力規模313EFlops、智能算力規模107EFlops、超算算力規模9EFlops,智能算力佔比提高。我國算力發展節奏與全球相似,2020 年我國算力總規模達到 135EFlops,佔全球算力規模的 39%,達到 55%的高位成長,並實現連續三年增速維持 40%以上。
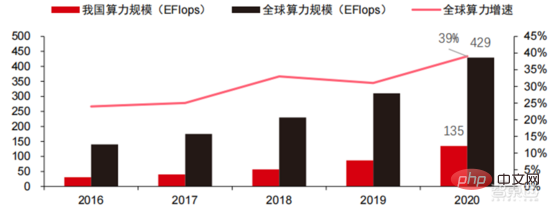
▲ 全球算力規模變化
#算力結構 :我國與全球發展相似,智慧算力成長迅速,佔比從2016 年的3%提升至2020 年的41%。而基礎算力佔比由 2016 年的 95%下降至 2020 年的 57%,在下游需求驅動下,以智慧運算中心為代表的人工智慧算力基礎設施發展迅速。同時在未來需求方面,根據華為2020 年發布的《泛在算力:智能社會的基石》報告,隨著人工智慧的普及,預計到2030 年,人工智慧算力的需求將相當於1,600 億顆高通驍龍855 內建AI 晶片,相當於2018 年的約390 倍、2020 年的約120 倍。
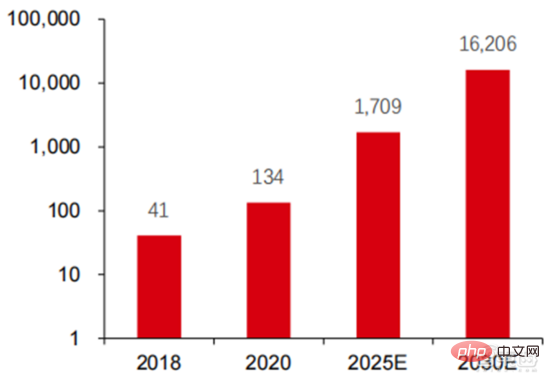
▲ 預計2030 年人工智慧算力需求(EFlops)
資料儲存:非關聯式資料庫以及用於儲存、治理非結構資料的資料湖迎來需求爆發。 近年來全球資料量呈現爆發式成長,根據IDC 統計,2019 年全球產生的資料量為41ZB,過去十年的CAGR 接近50%,預計到2025 年全球資料量或高達175ZB,2019-2025年仍將維持近30%的複合增速,其中超過80%的數據都將是處理難度較高的文字、影像、音訊視訊等非結構化資料。資料量(尤其是非結構化資料)的激增使得關係型資料庫的弱點愈加凸顯,面對幾何指數成長的數據,傳統為結構型資料設計的關係型資料庫縱向疊加的資料延展模式難以滿足。
非關聯式資料庫以及用於儲存、治理非結構資料的資料湖,因其靈活性以及易延展性逐漸佔據市場中越來越多的份額。根據 IDC,2020 年全球 Nosql 資料庫的市場規模為 56 億美元,預計 2025 年將成長至 190 億美元,2020-2025 年複合成長率為 27.6%。同時,根據 IDC,2020 年全球資料湖市場規模為 62 億美元,2020 年市場規模成長率為 34.4%。
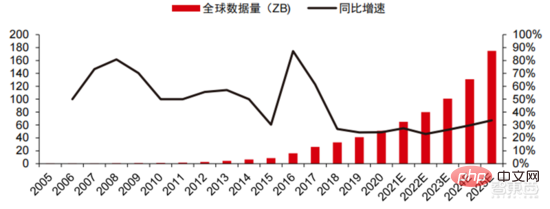
▲ 全球数据量及同比增速(ZB,%)
3、AI 框架:相对趋于成熟,少数巨头主导
Tensorflow (产业界)、 PyTorch (学术界)逐步实现主导。 谷歌推出的 Tensorflow为主流与其他开源模块如 Keras(Tensorflow2 集成了 Keras 模块)、Facebook 开源的PyTorch 等一起构成了目前 AI 学习的主流框架。Google Brain 自 2011 年成立起开展了面向科学研究和谷歌产品开发的大规模深度学习应用研究,其早期工作即是 TensorFlow 的前身 DistBelief。DistBelief 在谷歌和 Alphabet 旗下其他公司的产品开发中被改进和广泛使用。2015 年 11 月,在 DistBelief 的基础上,谷歌大脑完成了对“第二代机器学习系统”TensorFlow 的开发并对代码开源。相比于前作,TensorFlow 在性能上有显著改进、构架灵活性和可移植性也得到增强。
Tensorflow 与 Pytorch 虽然本身是开源模块,但因为深度学习框架庞大的模型与复杂度导致其修改与更新基本完全是由谷歌完成,从而谷歌与 Facebook 也通过对 Tensorflow与 PyTorch 的更新方向直接主导了产业界对人工智能的开发模式。
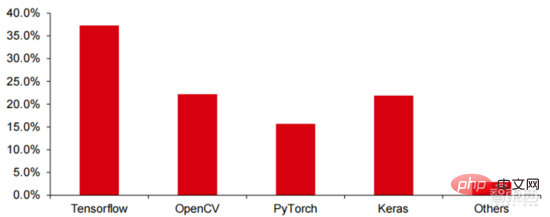
▲ 全球商用人工智能框架市场份额结构(2021)
Microsoft 在 2020 年以 10 亿美元注资 OpenAI,获得 GPT-3 语言模型的独家许可。GPT-3 是目前在自然语言生成中最为成功的应用,不仅可以用于写“论文”,也可以应用于“自动生成代码”,自今年 7 月发布后,也被业界视为最强大的人工智能语言模型。而Facebook 早在 2013 年创立了 AI 研究院,FAIR 本身并没有像 AlphaGo 和 GPT-3 那样著名的模型和应用,但是它的团队已经在 Facebook 本身感兴趣的领域发表了学术论文,包括计算机视觉、自然语言处理和对话型 AI 等。2021 年,谷歌有 177 篇论文被 NeurIPS(目前人工智能算法的最高期刊)接收并发表,Microsoft 有 116 篇,DeepMind 有 81 篇,Facebook 有 78 篇,IBM 有 36 篇,而亚马逊只有 35 篇。
4、 算法模型:神经网络算法为主要理论基础
深度学习正在向深度神经网络过渡。 机器学习是通过多层非线性的特征学习和分层特征提取,对图像、声音等数据进行预测的计算机算法。深度学习为一种进阶的机器学习,又称深度神经网络(DNN:Deep Neural Networks )。针对不同场景(信息)进行的训练和推断,建立不同的神经网络与训练方式,而训练即是通过海量数据推演,优化每个神经元的权重与传递方向的过程。而卷积神经网络,能考虑单一像素与周边环境变量,并简化数据提取数量,进一步提高神经网络算法的效率。
神经网络算法成为大数据处理核心。 AI 通过海量标签数据进行深度学习,优化神经网络与模型,并导入推理决策的应用环节。90 年代是机器学习、神经网络算法快速崛起的时期,算法在算力支持下得到商用。90 年代以后,AI 技术的实际应用领域包括了数据挖掘、工业机器人、物流、语音识别、银行业软件、医疗诊断和搜索引擎等。相关算法的框架成为科技巨头的布局重点。
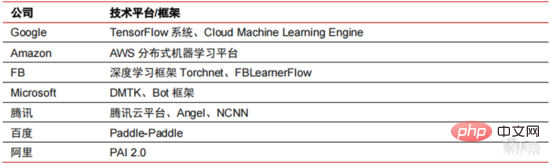
▲ 主要科技巨头算法平台框架
技术方向上,计算机视觉与机器学习为主要的技术研发方向。 根据 ARXIV 数据,从理论研究的角度看,计算机视觉和机器学习两个领域在 2015-2020 年发展迅速,其次是机器人领域。2020 年,ARXIV 上 AI 相关出版物中,计算机视觉领域出版物数量超过 11000,位于 AI 相关出版物数量之首。
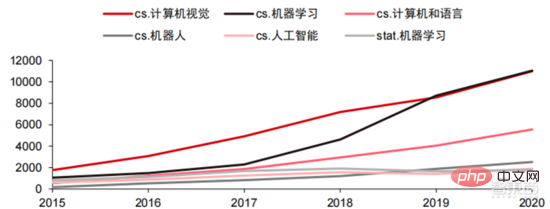
▲ 2015-2020 年 ARXIV 上 AI 相关出版物数量
在過去五年,我們觀察到以CNN 與DNN 為主的神經網路演算法是近年來發展最快的機器學習演算法,因其在電腦視覺、自然語言處理等領域中的優異表現,大幅加快了人工智慧應用的落地速度,是電腦視覺、決策智慧迅速邁向成熟的關鍵因素。從側視圖可以看出,在語音辨識任務上,標準的 DNN 方法相較於傳統的 KNN、SVM 與隨機森林等方法都有明顯的優勢。
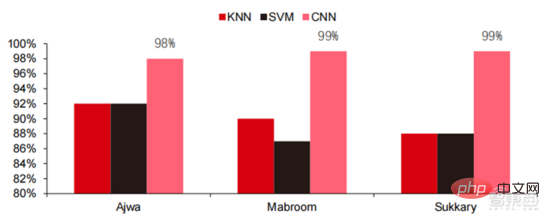
▲ 卷積演算法突破了傳統影像處理的準確度瓶頸,首次實現工業化可用
訓練成本上看,神經網路演算法訓練人工智慧的成本明顯降低。 ImageNet 是一個包含超過 1400 萬張圖像的資料集,用於訓練人工智慧演算法。根據史丹佛DAWNBench 團隊的測試,2020 年訓練一個現代的圖像識別系統僅需約7.5 美元,比2017 年的1100 美元下降了99%以上,這主要受益於演算法設計的優化、算力成本的下降,以及大規模人工智慧訓練基礎設施的進步。訓練系統的速度越快,評估並用新資料更新系統的速度就越快,這將進一步加快 ImageNet 系統的訓練速度,提高開發和部署人工智慧系統的生產力。
訓練時間分佈上看,神經網路演算法訓練所需時間全面降低。 透過分析每個時期的訓練時間分佈,發現在過去幾年中,訓練時間大大縮短,且訓練時間的分佈更加集中,這主要受益於加速器晶片的廣泛使用。
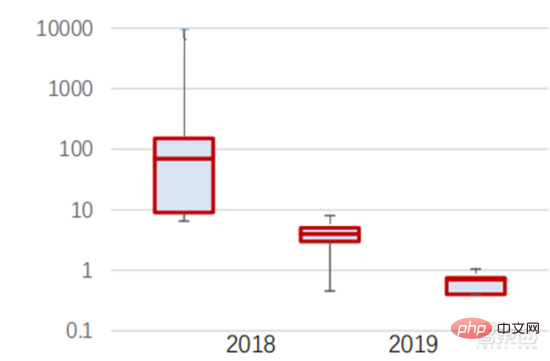
▲ ImageNet 訓練時間分佈(分鐘)
在卷積神經網路的推動下,電腦視覺準確率測試成績明顯提升,正處於產業化階段。 電腦視覺準確率在過去的十年中取得了巨大的進步,這主要歸功於機器學習技術的應用。 Top-1 準確度測試人工智慧系統為影像分配正確標籤的能力越強,那麼其預測結果(在所有可能的標籤中)與目標標籤越相同。在有額外的訓練資料(例如來自社群媒體的照片)的情況下,2021 年1 月在Top-1 準確度測試上每10 次嘗試中會出現1 次錯誤,而2012年12 月每10 次嘗試中會出現4 次錯誤。而另一項精確率測試Top-5 會讓電腦回答目標標籤是否在分類器的前五個預測中,其準確率從2013 年的85%提高到2021 年的99%,超過了代表人類水平的成績94.9%。
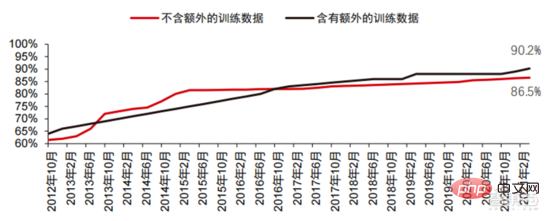
▲ TOP-1 準確率變更
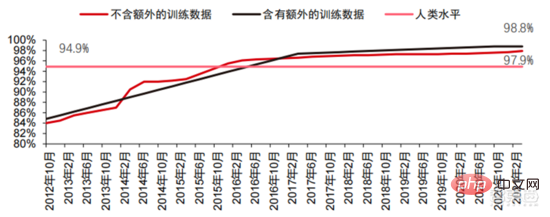
▲ TOP-5準確率變更
################################################################################################################################################## ###在神經網路演算法發展的過程中,### ###Transformer### ###模型在過去五年裡成為了主流,整合了### ###過去各種零散的小模型。 ### Transformer 模型是Google在 2017 年推出的 NLP 經典模型(Bert就是使用的 Transformer)。模型的核心部分通常由兩大部分組成,分別是編碼器與解碼器。編/解碼器主要由兩個模組組合成:前饋神經網路(圖中藍色的部分)和注意力機制(圖中玫紅色的部分),解碼器通常多一個(交叉)注意力機制。編碼器和解碼器透過模仿神經網路對資料進行分類與再次聚焦,在機器翻譯任務上模型表現超過了 RNN 和 CNN,只需要編/解碼器就能達到很好的效果,可以高效地並行化。 ###
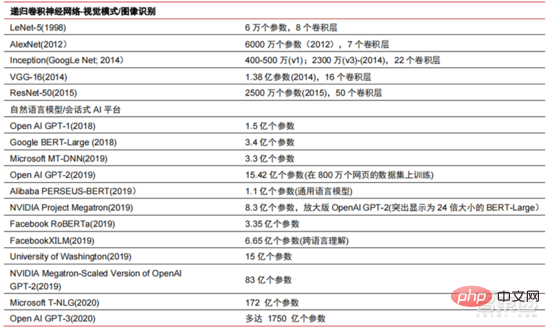
AI 大模式化是過去兩年興起的新潮流,自我監督學習 預訓練模式微調適應方案逐漸 成為主流, AI 模型邁向大數據支撐下的泛化成為可能。 傳統的小模型用特定領域有標註的資料訓練,通用性差,換到另一個應用場景中往往不適用,需要重新訓練。而 AI 大模型通常是在大規模無標註資料上進行訓練,將大模型進行微調就可以滿足多種應用任務的需求。以 OpenAI、Google、微軟、Facebook、NVIDIA 等機構為代表,佈局大規模智慧模型已成為全球引領性趨勢,並形成了 GPT-3、Switch Transformer 等大參數量的基礎模型。
2021 年底英偉達與微軟共同開發的 Megatron-LM 擁有 83 億個參數,而 Facebook 開發的Megatron 則擁有 110 億個參數。這些參數大多來自於 reddit、wikipedia、新聞網站等,對大量資料儲存及分析所需的資料湖等工具將會是下一步研發的焦點之一。
5、應用程式場景: 逐步在安防、互聯網、零售等領域實現落地
目前在應用端最成熟的技術是語音辨識、圖像辨識等,圍繞著這些領域,國內、美國都 有大量的企業上市,並形成一定的產業群。 在語音辨識領域,較成熟的上市企業包括科大訊飛與先前被微軟以 290 億美元收購的 Nuance。
智慧醫療: AI 醫療多應用於醫療輔助情境。 在醫療健康領域的 AI 產品涉及智慧問診、病史採集、語音電子病歷、醫療語音輸入、醫學影像診斷、智慧追蹤、醫療雲端平台等多類應用情境。從醫院就診流程來看,診前產品多為語音助理產品,如導診、病史採集等,診中產品多為語音電子病例、影像輔助診斷,診後產品以追蹤追蹤類為主。綜合整個就診流程中的不同產品,目前 AI 醫療的主要應用領域仍以輔助場景為主,取代醫師的體力及重複性勞動。 AI 醫療的海外龍頭企業是 Nuance,公司 50%的業務來自智慧醫療解決方案,而病歷等臨床醫療文獻轉寫方案是醫療業務的主要收入來源。
智慧城市:大城市病和新型城鎮化為城市治理帶來新挑戰,刺激 AI 城市治理的需求。 大中型城市隨著人口和機動車數量的增加,城市擁擠等問題較為突出。隨著新型城鎮化的推進,智慧城市將會成為中國城市的主要發展模式。而智慧城市涉及的 AI 安防、AI 交通治理將會成為 G 端的主要落地方案。 2016 年杭州首次進行都市資料腦改造,尖峰壅塞指數下降至 1.7 以下。目前以阿里為代表的城市數據大腦已經進行了超過 15 億元的投資,主要集中在智慧安防、智慧交通等領域。我國智慧城市產業規模持續擴大,前瞻產業研究院預計 2022 年可達 25 兆元,2014 年至 2022 年的年均複合成長率為 55.27%。
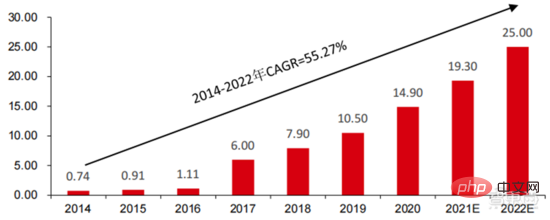
▲ 2014-2022 智慧城市市場規模及預測(單位:兆元)
智慧物流 2020 年市場規模高達 5710 億元,智慧倉儲迎來千億市場。 物流產業成本居高不下及數位轉型的背景下,倉儲物流及產品製造環節面臨自動化、數位化、智慧轉型的迫切需求,以提升製造和流通效率。根據中國物流與採購聯合會的數據,2020年中國智慧物流市場高達5,710億元,2013-2020年的年均複合成長率為21.61%。物聯網、大數據、雲端運算、人工智慧等新一代資訊技術既促進了智慧物流行業的發展,也對智慧物流行業提出了更高的服務要求,智慧物流市場規模有望持續擴大。根據 GGII 測算,2019 年中國智慧倉儲市場規模近 900 億元,而前瞻研究院預計這一數字將在 2025 年達到 1,500億以上。
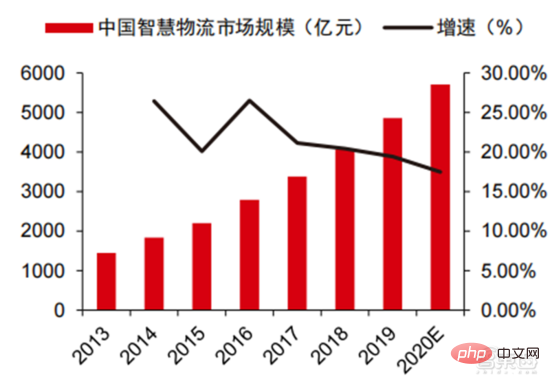
▲ 2013-2020 年中國智慧物流市場規模及增速
新零售:人工智慧將帶來人力成本的縮減與營運效率的提升。 Amazon Go 為亞馬遜提出的無人商店概念,無人商店於 2018 年 1 月 22 日在美國西雅圖正式對外營運。 AmazonGo 結合了雲端運算和機器學習,應用拿了就走技術(Just Walk Out Technology)和智慧辨識技術(Amazon Rekognition)。店內的相機、感應監測器以及背後的機器演算法會辨識消費者拿走的商品項目,並且在顧客走出店時將自動結帳,是零售商業領域的全新變革。
雲端化的人工智慧模組元件是各大網路巨擘目前在人工智慧商業化的主要發力方向, 將人工智慧技術整合在公有雲服務中進行出售。 Google Cloud Platform 的 AI 技術一直走在產業的最前沿,並致力於將先進的 AI 技術融入雲端運算服務中心。近年來,Google收購多家AI 公司,並發表 AI 專用晶片 TPU、雲端服務 Cloud AutoML 等產品完善佈局。目前Google的AI 能力已經涵蓋認知服務、機器學習、機器人、數據分析&協作等領域。有別於部分雲廠商在AI 領域相對分散的產品,Google在AI 產品的營運上更加完整和體系化,將垂直應用整合為AI 基礎元件,將Tensorflow 與TPU 運算整合為基礎設施,形成了一個完整的AI 平台服務。
百度是中國 AI 能力最強的公有雲廠商,百度 AI 的核心策略是開放賦能。 百度建構以DuerOS、Apollo 為代表的 AI 平台,開放生態,形成資料與場景的正向迭代。基於百度網路搜尋的資料基礎,自然語言處理、知識圖譜和使用者畫像技術逐漸成熟。在平台以及生態層,百度雲是很大的運算平台,開放給所有的合作夥伴,變成基礎的支撐平台,上面有百度大腦的各種能力。同時也有一些垂直的解決方案,例如基於自然語言的人機互動的新一代作業系統,以及與智慧駕駛相關的 Apollo。整車廠商可以調用其中他們需要的能力,汽車電子廠商也可以調用他們需要的相應能力,共建整個平台和生態。
三、 產業變化: AI 大模式逐步成為主流,產業發展可望全 面加速
最近幾年來,AI 產業的技術演進路線主要呈現如下特徵:底層模組性能的不斷提升,注重模型的泛化能力,從而幫助AI 演算法的通用性最佳化,並反哺資料收集。 AI 技術的持續發展依靠底層演算法的突破,這同時需要以算力為核心的基礎能力建構以及有大數據支撐進行知識和經驗學習的環境。大模型在產業內的快速流行,大模型小模型的運作模式,以及晶片、算力基礎設施等底層環節能力的不斷改善,以及由此帶來的應用場景類別、場景深度的持續提升,並最終帶來產業基礎能力、應用場景之間的不斷相互促進,並在正向循環邏輯下,驅動全球AI 產業發展不斷提速。
大模型帶來較強的通用問題求解能力。 目前大部分人工智慧正處於“手工作坊式”,面對各類產業的下游應用,AI 逐漸展現出碎片化、多樣化的特點,模型通用性不高。為提升通用求解能力,大模型提供了一個可行方案,即「預訓練大模型 下游任務微調」。此方案指從大量標記和未標記的資料中捕獲知識,透過將知識儲存到大量的參數中並對特定任務進行微調,提高模型泛化能力。
大模型可望進一步突破現有模式結構的精確度限制,結合嵌套小模型訓練,進一步提升 特定場景下的模式效率。 過去十年中,模型精度提升主要依賴網路在結構上的變革,但隨著神經網路結構設計技術逐漸成熟並趨於收斂,精確度提升達到瓶頸,而大模型的應用有望突破這一瓶頸。以Google的視覺遷移模型Big Transfer,BiT 為例,使用ILSVRC-2012(128萬張圖片,1000 個類別)和JFT-300M(3 億張圖片,18291 個類別)兩個資料集來訓練ResNet50,精確度分別是77%和79%,大模型的使用使得處於瓶頸的精確度進一步提高。另外使用 JFT-300M 訓練 ResNet152x4,精確度可以上升到 87.5%,相比 ILSVRC-2012 ResNet50 結構提升了 10.5%。
大模型 小型模型 :泛化大模型人工智慧的推廣並結合特定場景下的資料最佳化將成為中期人工智慧產業商業化的關鍵。原先針對特定場景重新提取資料訓練的模式,已被實踐證明難以獲利,重新訓練模型的成本過高,而獲得的模型泛用性低下,難以重複利用。而在晶片算力性能不斷提高的大背景下,大模型嵌套小模型的嘗試提供給了廠商另一個思路,透過分析海量資料獲得泛用模型,再透過嵌套特定小模型的方式為不同場景進行最佳化,節省了大量成本。阿里雲、華為雲、騰訊雲等公有雲廠商都在積極開發自研的大模型平台,提升模型的通用型。
以英偉達為代表的 AI 晶片巨頭,在新一代晶片中針對產業中常用的 AI#模型,特別設 計了新引擎以大幅提升運算能力。 英偉達的 Hopper 架構引入了 Transformer 引擎,大幅加速了 AI 訓練。 Transformer 引擎採用軟體和自訂 NVIDIA Hopper Tensor Core 技術,該技術旨在加速訓練基於常見 AI 模型建構模組(即 Transformer)建構的模型。這些Tensor Core 能夠應用 FP8 和 FP16 混合精度,以大幅加速 Transformer 模型的 AI運算。採用 FP8 的 Tensor Core 運算在吞吐量方面是 16 位元運算的兩倍。 Transformer引擎利用客製化的、經 NVIDIA 調優的啟發式演算法來解決上述挑戰,可在 FP8 與FP16 計算之間動態選擇,並自動處理每層中這些精度之間的重新投射和縮放。根據英偉達提供的數據,Hopper 架構在訓練 Transformer 模型時,效率可以達到安培模型的 9 倍。
在大模型技術趨勢下,雲端廠商正逐步成為算力市場中的核心玩家,在人工智慧技術框架透過大模型往泛用化發展後,雲端廠商也能夠借助PaaS 能力把底層IaaS 能力與PaaS結合,為市場提供通用性解決方案。我們看到隨著大模型的出現,人工智慧需要處理與分析的資料量日漸上升,同時這部分資料從過去的專業資料集轉換為通用型大數據。雲端運算巨頭可以透過本身強大的 PaaS 能力與底層 IaaS 基礎結合,為人工智慧廠商提供一站式的數據處理,這也幫助雲端運算巨頭成為本輪人工智慧浪潮的主要受益者之一。
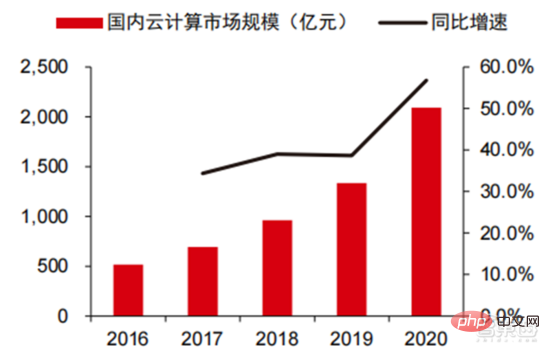
▲ 國內雲端運算市場規模
目前AWS、Azure 等國際主流雲端廠商與阿里雲、騰訊雲、華為雲等國內頭部雲廠商都已開始在資料儲存、資料處理等PaaS 能力上重點發力。儲存能力方面,NoSQL 類型資料庫與在資料種類日益繁雜的未來會湧現更多機會,如 Google Cloud 就已經在物件類別、傳統的關聯式資料庫以及 NoSQL 類型資料庫分散佈局。而在資料處理方面,Data Lake與 Data Warehouse 的重要性愈發凸顯,雲端運算巨頭透過完善這部分產品線,建構了一個完整的資料循環模式,並結合其底層的 IaaS 基礎能力。完整的產品線與閉合的資料循環模式將是未來雲端運算巨頭在 AI 中間層競爭的最大優勢。
伴隨AI 產業鏈結構的逐步清晰,以及大模型帶來的產業運作效率、技術深度的大幅改善,中期維度,假設AI技術不發生跳變式躍遷前提下,我們判斷AI 產業鏈價值可望逐步向兩端靠攏,中間環節價值可望持續減弱,並逐步形成「晶片算力基礎設施AI 框架&演算法庫應用場景」的典型產業鏈結構,同時在這樣的產業結構安排下,我們預計上游的晶片企業、雲端基礎設施廠商,以及下游的應用廠商可望逐步成為AI 產業快速發展的核心受益者。
大模型帶來AI 底層基礎技術架構的統一,以及對算力的龐大需求等特徵,天然有利於雲端運算公司在此過程中發揮基礎性角色:雲端運算具有全球分佈最為廣泛、最強大的硬體算力設施,同時AI 框架、通用演算法最為一種典型PaaS 能力,亦傾向於整合到雲端廠商的平台能力當中。因此從技術通用性、實際商業需求等維度,在大模型的推動下,雲端運算巨頭有望逐步成為算力設施基礎演算法框架環節能力的主要供應商,並不斷侵蝕現有的AI 演算法平台商的商業空間。從過去雲廠商各類產品的報價中可以發現,以 AWS 與 Google 產品為例,美國東部地區的 Linus按需使用價格正在階梯式降低。
從圖中可以看到,具有 2 個 vCPU,2 個 ECU 和 7.5GiB的 m1.large 產品價格從 2008 年的約 0.4 美元/小時持續下降到了 2022 年約 0.18 美元/小時。而 Google Cloud 具有 8 個 vCPU 與 30GB 記憶體的 n1-standard-8 產品的隨選使用價格也從 2014 年的 0.5 美元/小時下降到 2022 年的 0.38 美元/小時,可見雲端運算價格呈現全面下降趨勢。在未來 3-5 年,我們將看到更多的 AI 即服務(AIaaS)產品。先前提到的大模型趨勢,尤其是GPT-3 的誕生掀起了這個潮流,由於GPT-3 龐大的參數量,必須要在龐大的公有雲算力如Azure 規模的計算設施上才能運行,於是微軟將它打造成了能夠透過web API 取得的服務,這也會促使更多的大模型出現。
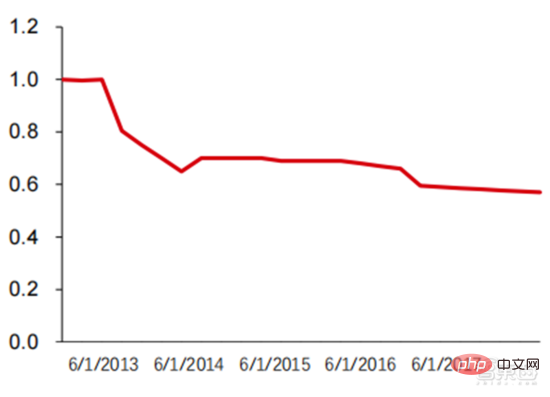
▲ AWS EC2 歷史標準化價格(美元/小時)
在目前的算力條件與可展望的技術能力支持下,應用端將持續透過資料擷取實現演算法迭代與最佳化,完善目前認知智能當中仍存在的不足(影像辨識方向),並嘗試往決策智慧發展。根據目前的技術能力以及硬體算力支持,實現完全決策智慧仍需較長時間;現有場景的繼續深化的基礎上做出局部性的智慧化將是 3-5 年內的主要方向。目前的 AI 應用層面仍過於單點化,而完成局部性的串連將成為實現決策智慧的第一步。人工智慧的軟體類應用將包括從底層的驅動程序,到上層的應用程式、演算法框架,從面向商業(製造、金融、物流、零售、房地產等),到人類(元宇宙、醫療、人形機器人等)、自動駕駛等領域。
智東西認為,伴隨AI 晶片、算力設施、數據等基礎要素的不斷完善,以及大模型帶來的問題泛化求解能力的大幅提升,AI 產業正形成「晶片算力基礎設施AI 框架&演算法庫應用場景」的穩定產業價值鏈結構,AI 晶片廠商、雲端運算廠商(算力設施演算法框架)、AI 應用場景廠商、平台型演算法框架廠商等有望持續成為產業核心受益者。
以上是深入報告:大模型驅動 AI 全面加速!黃金十年開啟的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 大宗交易的虛擬貨幣交易平台排行榜top10最新發布
Apr 22, 2025 am 08:18 AM
大宗交易的虛擬貨幣交易平台排行榜top10最新發布
Apr 22, 2025 am 08:18 AM
選擇大宗交易平台時應考慮以下因素:1. 流動性:優先選擇日均交易量超50億美元的平台。 2. 合規性:查看平台是否持有美國FinCEN、歐盟MiCA等牌照。 3. 安全性:冷錢包存儲比例和保險機制是關鍵指標。 4. 服務能力:是否提供專屬客戶經理和定制化交易工具。
 數字貨幣交易所App前十名蘋果版下載入口匯總
Apr 22, 2025 am 09:27 AM
數字貨幣交易所App前十名蘋果版下載入口匯總
Apr 22, 2025 am 09:27 AM
提供各種複雜的交易工具和市場分析。覆蓋 100 多個國家,日均衍生品交易量超 300 億美元,支持 300 多個交易對與 200 倍槓桿,技術實力強大,擁有龐大的全球用戶基礎,提供專業的交易平台、安全存儲解決方案以及豐富的交易對。
 排名前十的虛擬貨幣交易app有哪些 十大數字貨幣交易所平台推薦
Apr 22, 2025 pm 01:12 PM
排名前十的虛擬貨幣交易app有哪些 十大數字貨幣交易所平台推薦
Apr 22, 2025 pm 01:12 PM
2025年安全的數字貨幣交易所排名前十依次為:1. Binance,2. OKX,3. gate.io,4. Coinbase,5. Kraken,6. Huobi,7. Bitfinex,8. KuCoin,9. Bybit,10. Bitstamp,這些平台均採用了多層次的安全措施,包括冷熱錢包分離、多重簽名技術以及24/7的監控系統,確保用戶資金的安全。
 穩定幣有哪些?穩定幣如何交易?
Apr 22, 2025 am 10:12 AM
穩定幣有哪些?穩定幣如何交易?
Apr 22, 2025 am 10:12 AM
常見的穩定幣有:1. 泰達幣(USDT),由Tether發行,與美元掛鉤,應用廣泛但透明性曾受質疑;2. 美元幣(USDC),由Circle和Coinbase發行,透明度高,受機構青睞;3. 戴幣(DAI),由MakerDAO發行,去中心化,DeFi領域受歡迎;4. 幣安美元(BUSD),由幣安和Paxos合作,交易和支付表現出色;5. 真實美元(TUSD),由TrustTo
 目前有多少穩定幣交易所?穩定幣種類有多少?
Apr 22, 2025 am 10:09 AM
目前有多少穩定幣交易所?穩定幣種類有多少?
Apr 22, 2025 am 10:09 AM
截至2025年,穩定幣交易所數量約為千家。 1. 法定貨幣支持的穩定幣包括USDT、USDC等。 2. 加密貨幣支持的穩定幣如DAI、sUSD。 3. 算法穩定幣如TerraUSD。 4. 還有混合型穩定幣。
 幣圈十大交易所有哪些 最新幣圈app推薦
Apr 24, 2025 am 11:57 AM
幣圈十大交易所有哪些 最新幣圈app推薦
Apr 24, 2025 am 11:57 AM
選擇可靠的交易所至關重要,Binance、OKX、Gate.io等十大交易所各具特色,CoinGecko、Crypto.com等新app也值得關注。

 2025下一個千倍幣可能有哪些
Apr 24, 2025 pm 01:45 PM
2025下一個千倍幣可能有哪些
Apr 24, 2025 pm 01:45 PM
截至2025年4月,有七个加密货币项目被认为具有显著增长潜力:1. Filecoin(FIL)通过分布式存储网络实现快速发展;2. Aptos(APT)以高性能Layer 1公链吸引DApp开发者;3. Polygon(MATIC)提升以太坊网络性能;4. Chainlink(LINK)作为去中心化预言机网络满足智能合约需求;5. Avalanche(AVAX)以快速交易和
