
嘉賓| 黃彬
整理| 塗承燁
日前,在51CTO主辦的AISummit 全球人工智慧技術大會上,網易雲音樂演算法平台研發專家黃彬帶來了主題演講《網易雲音樂在線預估系統的實踐與思考》,從技術研發的視角分享瞭如何建立一套高性能、易用,且功能豐富的一個預估系統的相關實踐與思考。
現在將演講內容整理如下,希望對諸君有所啟發。
首先,我們來看看整個預估系統的一個架構,如下圖:
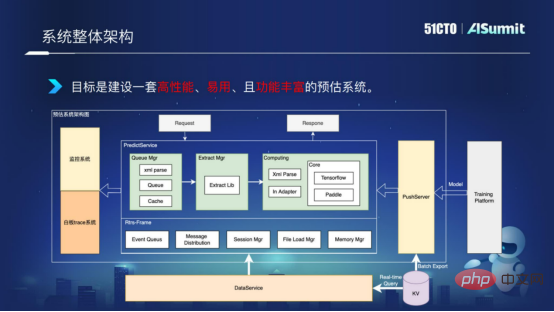
系統整體架構
中間的Predict Server,是預估系統的核心元件,包含查詢元件、特徵處理元件,和模型運算元件。左側的監控系統用於線網服務的監控,確保系統網路的暢通。右側的PushServer用於模型推送,把最新的模型推送進線上預估系統進行預測。
目標是建立一套高效能、易用,且功能豐富的一個預估系統。
如何提升運算效能?我們常見的計算效能問題有哪些,我從三個方面來闡述。
在通用方案裡,我們的特徵計算和模型計算是分進程部署的,這樣就會導致有大量的特徵存在跨服務、跨語言的傳遞,會帶來多次編解碼和記憶體拷貝,導致會存在比較大的效能開銷。
我們知道在模型更新時,會有大塊類型的申請和釋放。然而在一些通用方案裡,它不會自備模型預熱的方案,這會導致模型更新的過程中有比較高的耗時抖動,無法支援模型的即時化更新。
一般的框架使用的是同步機制,並發度不夠,CPU利用率比較低,無法滿足高並發的運算需求。
那麼,我們在預估系統裡面是如何解決這些效能瓶頸呢?
我們為什麼要做這樣一個事情?因為在傳統方案裡,我們都知道特徵處理和模型計算分進程部署,這樣就會帶來比較多的特定的跨網路傳輸,序列化、反序化,還有頻繁的記憶體申請和釋放。尤其是在推薦場景的特徵量特別大時,這樣就會帶來比較明顯的效能開銷。下圖中,靠上方的流程圖就展示了通用方案裡的具體情況。
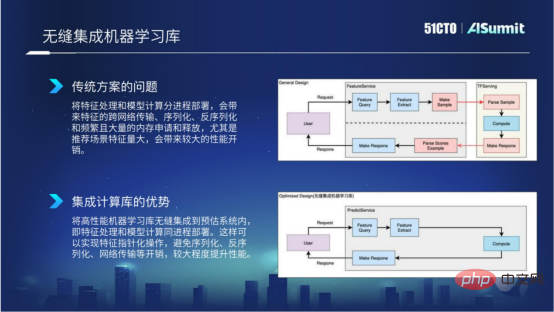
無縫整合式計器學習庫
為了解決上述問題,我們就在預估系統裡面將高效能運算學習架構整合到預估系統內部,這樣的好處就是我們能夠確保特徵處理和模型計算能夠同進程部署,能夠以指針的形式去實現對特徵的操作,避免序列化、反序列化以及網絡傳輸的開銷,從而在特徵計算以及特徵處理這一件帶來比較好的運算效能提升,這就是無縫整合機器學習帶來的好處。
首先,整個系統採用全非同步的架構設計。非同步架構帶來的好處就是外部呼叫是無堵塞等待的,所以非同步機制可以確保在CPU高負載的情況下,例如在60%到70%的情況下,依舊保持線網服務的耗時穩定性。
其次,訪存最佳化。訪存優化主要是基於伺服器的NUMA架構,我們採用了綁核運作的方式。透過這種方式能夠去解決先前NUMA架構存在的遠端記憶體存取的問題,從而提升了我們服務的運算效能。
第三,平行計算。我們對計算任務進行分片的處理,採用多執行緒並發的方式做計算,這樣就能夠較大程度降低服務的時耗,提升資源的使用率。
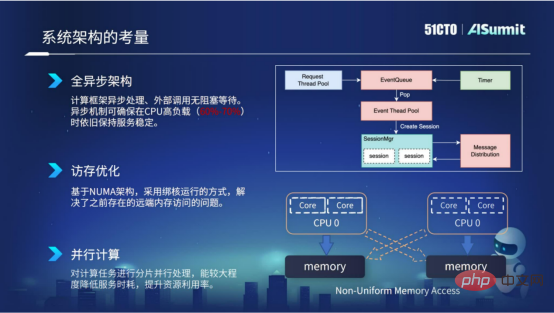
架構設計考量
以上就是我們在預估系統的系統架構考量上的實踐。
多層緩存,主要應用在特徵查詢階段和初級階段。我們封裝的快取機制,一方面能夠降低查詢的外部調用,另一方面也能夠減少特徵抽取導致反覆無效的計算。
透過快取的方式,可以極大程度的提升查詢和抽取的效率。尤其在查詢階段,我們根據特徵的重要性以及根據特徵的量級,我們封裝了多種元件,例如同步查詢、非同步查詢以及特徵批量導入等元件。
第一種是同步查詢,主要適用於一些比較重要的特徵,當然同步查詢的效能沒有那麼有效率。
第二種是非同步查詢,主要針對一些「艾特維度」的特徵,這些特徵有可能重要程度不是那麼高,那麼就可以採用這種非同步查詢的方式。
第三種是特徵批次導入,主要適用於特徵規模不是特別大的特徵資料。我們將這些特徵批次匯入到進程內部,就可以實現特徵的在地化查詢,效能是非常有效率的。
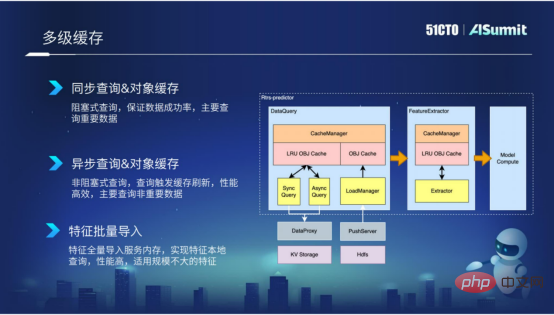
多層快取
介紹完快取機制之後,我們來看看模型運算的行為最佳化。模型計算,我們主要從模型輸入最佳化、模型載入最佳化以及核心最佳化,這三個面向進行最佳化。
在模型輸入這一塊,大家都知道TF Servering採用的是Example的輸入。範例輸入會存在Example的構造、Example的序列化反序化以及模型內部呼叫Parse Example的情況,這樣就會存在比較明顯的耗時。
在下圖中,我們看【優化前】的截圖展示了模型計算優化前的資料統計情況。我們可以看到,有一個比較長的Parse Example解析耗時,並且在Parse Example解析完之前,其他op是沒有辦法執行並行調度的。為了解決模型樹的效能問題,我們在預估系統中封裝了高效能的模型輸入方案。透過新的方案,我們能夠實現特徵輸入零拷貝,從而減少這種Example的構造耗時以及解析耗時。
在下圖中,我們看【優化後】的截圖展示了模型計算優化之後的資料統計情況,我們可以看到,已經沒有了Parse Example解析耗時,就只剩下Example的解析耗時。

模型計算最佳化
介紹完模型輸入最佳化,我們來看看模型加載的優化。 Tensorflow的模型載入是懶載入的模式,模型載入到內部之後,它不會進行模型預熱,而是要等到線網正式請求來了之後才會進行模型預熱,這樣就會導致模型載入之後會有比較嚴重的耗時抖動。
為了解決這個問題,我們在預估系統內部實現了自動的模型預熱功能,並且實現了新舊模型的熱切換,也實現了舊模型的非同步卸載和記憶體釋放。這樣透過這些模型載入的一些最佳化手段,實現模型的分鐘更新能力。
接下來,我們來看看模型核心的最佳化。目前我們主要是對Tensorflow核心做了一些核心同步優化,以及我們會根據模型去調整op間和op內的一些線程池等等。
以上就是我們在模型計算方面的一些效能最佳化的嘗試。
透過介紹上面的效能最佳化方案之後,我們來看看最終的效能最佳化成果。
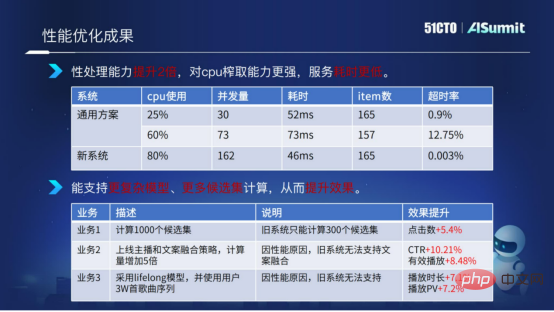
效能最佳化成果
這裡我們使用預估系統和通用方案的系統做了一個比較。我們可以看到預估系統在CPU使用達到80%的情況下,整個服務的運算耗時以及超時率都非常穩定,非常低。透過對比,我們可以得出新方案(預估系統)在計算處理這一塊,性能是有提升兩倍,對CPU的榨取能力更強,服務耗時更低。
得益於我們對系統的最佳化,我們可以為業務演算法提供更多模型的複雜度計算以及更多候選集的計算。
上圖中舉了一個例子,候選集從之前的300個候選集擴充到1000個候選集,同時我們增加了模型計算複雜度以及使用了一些比較複雜的特徵,分別在多個業務裡帶來了比較好的效果提升。
以上就是預估系統在效能最佳化上以及效能最佳化成果的介紹。
系統採用分層的架構設計。我們將整個預估系統分成三層,分為底層架構層、中間模板層、上層結構層。
底層架構層主要提供非同步機制、任務佇列、並發調度、網路通訊等。
中間模板層主要提供與模型運算相關的元件,包括查詢管理、快取管理、模型載入管理、模型運算管理。
上層接口層主要提供Highlevel的接口,業務僅需實現此層接口,大量減少程式碼開發。
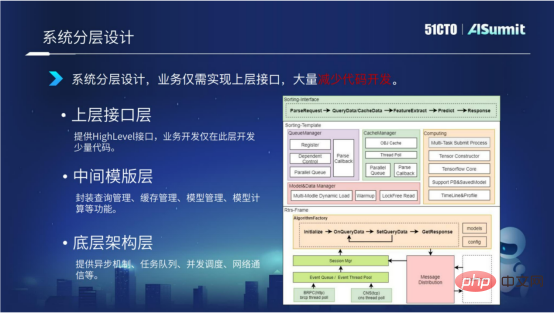
透過系統的分層架構設計,不同業務之間完全可以重複使用底層和中間層的程式碼,開發只需要關注最上層的少量程式碼開發就可以。同時,我們也在進一步的思考,有沒有辦法進一步減少上層介面層的程式碼開發?下面我們來詳細介紹一下。
透過基於動態pb技術實現特徵查詢和特徵解析形成的通用化方案的封裝,能夠實現僅透過XML配置表名、查詢KEY、快取時間、查詢依賴等就能實現特徵查詢、解析、快取全流程。
如下圖所示,我們透過少量的幾行配置,就能夠實現複雜的一個查詢邏輯。同時,透過查詢封裝提升了查詢的效率。

特徵計算可以說是整個預估系統裡面,程式碼開發複雜度最高的一個模組,那麼什麼是特徵計算呢?
特徵計算包括離線過程和線上過程。離線過程其實就是離線樣本,透過處理得到離線訓練平台所需的一些格式,例如TF Recocd的格式。線上過程,主要是對線上的請求做一些特徵計算,透過處理得到線上預測平台需要的一些格式。離線過程和線上流程,其實對特徵處理的計算邏輯是完全一樣的。但因為離線流程和線上流程的運算平台不一樣,使用的語言不一樣,就需要開發多套程式碼來實現特徵計算,所以有以下三個問題。
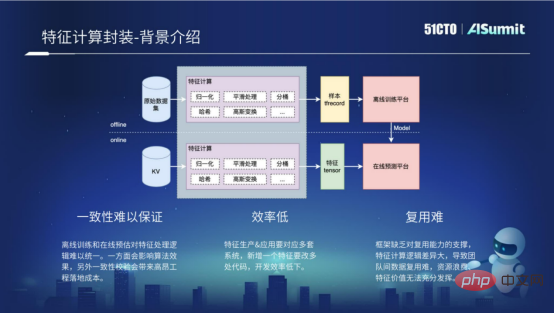
一致性難以保證的根本原因是離線訓練和線上預測對特徵處理邏輯難以統一。一方面會影響演算法的效果,另一方面會導致在開發過程中帶來比較高昂的一次性校驗成本。
如果要新加一個特徵,就需要涉及離線流程和線上流程的多套程式碼的開發,導致開發效率非常的低。
復用難,主要原因是框架缺乏對復用能力的支持,導致不同業務之間想要做到特徵計算的複用,變得非常難。
以上就是特徵計算框架存在的一些問題。
為了解決這些問題,我們將依照以下四點思路來逐步解決。
首先,我們提出算子的概念,將特徵計算抽象成算子的封裝。其次,算子封裝之後,我們建立一個算子庫,透過算子庫能夠提供業務之間算子的複用能力。然後,我們基於算子,定義特徵計算描述語言DSL。透過這種描述語言,我們能夠完成特徵計算的配置化表達。最後,就是前面介紹的,因為線上流程和離線流程存在多套邏輯,會導致邏輯不一致的問題,我們就需要解決特徵一次性的問題。
以上四點,就是我們如何對特徵計算框架進行封裝的想法。

為了實作算符抽象,首先必須實作資料協定的統一。我們利用動態pb的技術,根據特徵的原始資料訊息,將任意的一個特徵按照統一的資料進行處理,這樣就為我們的算子封裝提供了資料基礎。接下來,我們對特徵處理的過程進行抽樣封裝,將特徵計算過程抽象化成解析、計算、組裝、異常處理幾個過程,並且統一計算過程API,從而實現了算符抽象。
有了算子的抽象之後,我們就可以建立算子庫。算子庫分為平台通用算子庫和業務自訂算子庫。平台通用算子庫主要是實現公司級的複用。業務自訂算子庫主要是針對業務的一些自訂場景及特徵,實現群組內的重複使用。我們透過算子的封裝以及算子庫的建設,實現特徵計算的多場景重複使用,提升開發效率。
特徵計算的配置化表達,是指定義特徵計算表達的配置化語言叫做DSL。透過配置化語言,我們能夠實現算子的多層嵌套表達,能夠實現四則運算等等。下圖中的第一幅截圖展示了配置化語言的具體語法情況。

我們透過特徵計算的配置化語言能帶來什麼好處呢?
第一,我們能夠透過配置化完成整個特徵計算,從而達到開發效率的提升。
第二,我們能夠透過發布特徵計算來配置化表達,實現特徵計算的熱更新。
第三,訓練和預測使用同一份特徵計算的配置,從而實現線上線下一致性。
這就是特徵計算表達帶來的好處。
前面說到,特徵計算分為離線流程和線上流程。因為離線和線上的多平台原因,導致邏輯計算的不一致。為了解決這個問題,我們在特徵運算框架裡,實現了特徵運算框架的跨平台運作能力。核心邏輯採用C 開發,對外暴露的是C 介面以及Java介面。在打包建置的過程中,能夠一鍵實現C 的so庫以及jar包,從而確保特徵計算能夠運行在線計算的C 平台以及離線的Spark平台或者說Flink平台,並且用特徵計算表達,可以確保特徵計算實現線上線下邏輯的一致性。
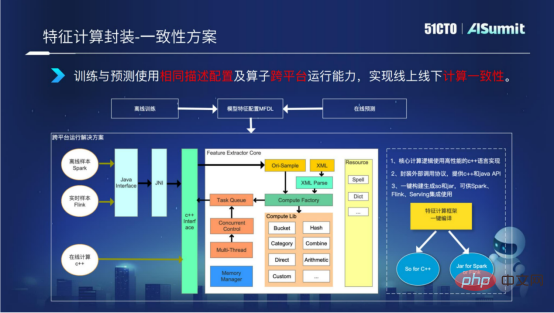
上面介紹的是特徵計算的具體情況。下面我們來看看特徵計算目前已經取得的一些成果。
我們現在已經沉澱了120家的算子,透過特徵計算的DSL語言能夠實現配置化,完成整個特徵計算。透過我們提供的跨平台運作能力,實現了線上線下邏輯不一致的問題。
下圖中的截圖展示了透過少量的配置,就可以實現整個特徵計算的過程,較大程度提高了特徵計算的開發性效率。

上述介紹了我們在開發效率提升的一個探索。總得來說,我們透過系統的分層設計,提高程式碼的複用度,以及透過對查詢、對抽取、對模型計算的封裝,能夠實現配置化的開發流程。
模型計算同樣也是採用封裝的形式。透過配置化表達的形式,實現模型的載入、模型的輸入建構、模型的計算等等,使用幾行配置,實現整個模型計算的表達過程。

下面我們來看看模型即時化的落地案例。
我們為什麼要做這樣的模型即時化專案?
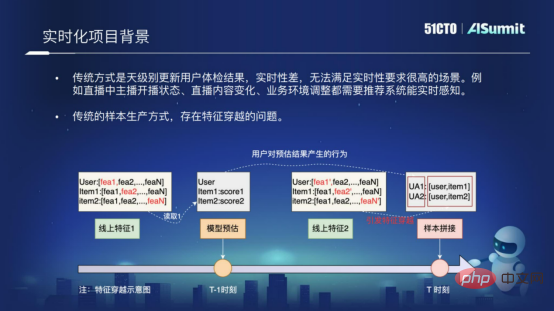
主要原因是傳統的推薦系統是天級別更新使用者推薦結果的系統,它的即時性非常差,無法滿足這種即時性要求比較高的場景,例如我們的直播場景,或者說其他一些即時性要求比較高的場景。
還有一個原因是傳統的樣本生產方式,是存在特徵穿越的問題。什麼是特徵穿越呢?下圖中展示了特徵穿越產生的根本原因,是因為我們在做樣本拼接的過程中,我們採用的是「T-1」時刻的模型預估結構,和「T」時刻的特徵進行拼接,這樣就會出現特徵穿越的問題。特徵穿越會非常大程度的影響線網推薦的效果。為了解決即時性的問題,以及為了解決樣本穿越的問題,我們就在預估系統裡去落地這樣一個模型即時化的方案。
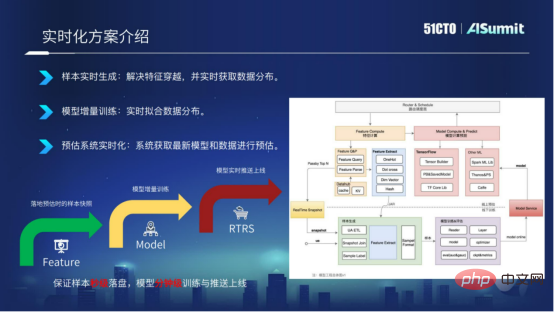
模型即時化方案從三個維度進行闡述。
 ##
##
樣本即時產生。我們基於線上預估系統,將預估系統的特徵即時落地到Kafka,透過RACE ID的形式關聯,這樣我們就能夠確保樣本實現秒級落盤,並且能夠解決特徵穿越的問題。
模型增量訓練。有了樣本的秒級落盤之後,我們就可以修改訓練模組,實現模型的漸進訓練,就能實現模型的分鐘更新。
預估系統即時化。有了模型的分鐘級匯出之後,我們透過模型推送服務Push Server,將最新的模型推送到線上預估系統,能夠讓現場預估系統使用最新的模型進行預測。
模型即時化方案總得來說,就是要實現樣本的秒級落盤,實現模型的分鐘級訓練和分鐘級線上更新。
我們現在的模型即時化方案,已經在多個場景進行了落地。透過模型即時化方案,在業務上有比較好的效果提升。
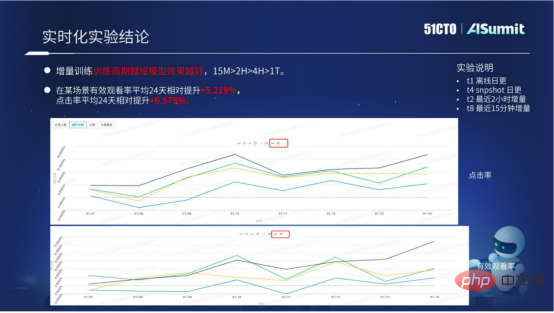
上圖中,主要展示了模型即時化方案的具體實驗數據。我們可以看到增量訓練,它的訓練週期越短越好。透過具體的數據,我們可知週期為15分鐘的效果遠大於2小時、10小時、一天的。現在的模型即時化方案已經有一套標準化的存取流程,能夠大量為業務帶來比較好的效果提升。
上述介紹了預估系統如何提升運算效能,如何提升開發效率,以及如何透過工程的手段帶來專案演算法提升三個面向的探索與嘗試。
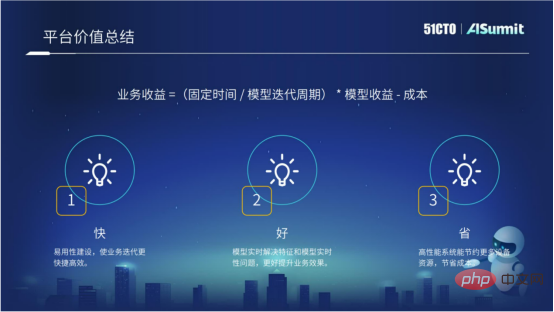
整個預估系統的平台價值,或者說整個預估系統的平台目的,可以概括成三個字,就是「快、好、省」。
「快」就是前面介紹的應用性建構。我們希望透過持續的應用性建設,使得業務的迭代能夠更有效率。
「好」就是希望透過工程手段,例如透過模型即時化方案,以及透過特徵計算的線上線下邏輯一致性方案,能夠為業務帶來比較好的效果提升。
「省」就是使用預估系統的更高效能,能夠更節省運算資源,以及節省運算成本。
未來,我們會朝著這三個目標持續努力。
以上就是我對雲端音樂預估系統的介紹,我的分享到此為止就結束了,謝謝各位!
以上是網易雲音樂演算法平台研發專家黃彬:網易雲音樂線上預估系統的實踐與思考的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















