

Python 取得旅遊景點資訊及評論並作詞雲、資料視覺化


大家好,我是啃書君!
正所謂:有朋自遠方來,不亦樂乎?有朋友來找我們玩,是一件很快樂的事情,那我們要盡地主之誼,好好帶朋友去玩!那麼問題來了,什麼時候去哪裡玩最好呢,哪裡玩的地方最多呢?
今天將手把手教你使用線程池爬取同程旅行的景點資訊及評論資料並做詞雲、資料視覺化! ! !帶你了解各城市的遊玩景點資訊。
在開始爬取資料之前,我們先來了解線程。
執行緒
進程:進程是程式碼在資料集合上的一次運行活動,是系統進行資源分配和調度的基本單位。
執行緒:是輕量級的進程,是程式執行的最小單元,是進程的一個執行路徑。
一個行程中至少有一個執行緒,行程中的多個執行緒共享行程的資源。
線程生命週期
在創建多執行緒之前,我們先來學習線程生命週期,如下圖:
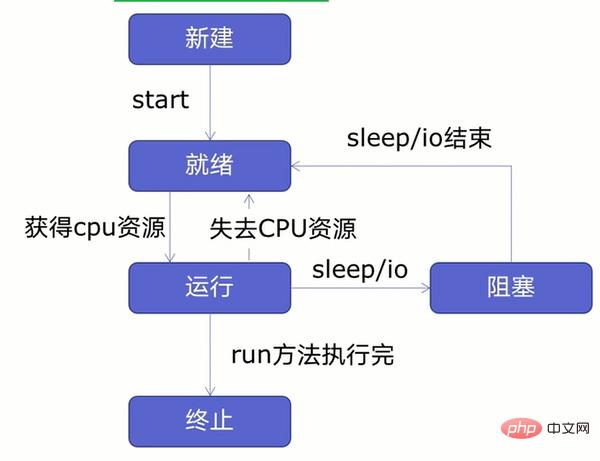
- #由圖可知,執行緒可以分為五個狀態-新建、就緒、運作、阻塞、終止。
- 先新建一個執行緒並開啟執行緒後執行緒進入就緒狀態,就緒狀態的執行緒不會馬上執行,要取得CPU資源才會進入執行狀態,在進入執行狀態後,執行緒有可能會失去CPU資源或遇到休眠、io操作(讀寫等操作)執行緒進入就緒狀態或阻塞狀態,要等休眠、io操作結束或重新取得CPU資源後,才會進入運作狀態,等到執行完後進入終止狀態。
在創建執行緒池之前,我們先來學習如何建立多執行緒。
建立多執行緒建立多執行緒可以分為四個步驟:#建立函數;#建立執行緒;
#啟動線程;
等待結束;
創建函數
為了方便演示,我們拿博客園的網頁做爬蟲函數,具體程式碼如下所示:import requests
urls=[
f'https://www.cnblogs.com/#p{page}'
for page in range(1,50)
]
def get_parse(url):
response=requests.get(url)
print(url,len(response.text))創建線程
 在上一步我們創建了爬蟲函數,接下來將創建線程了,具體程式碼如下所示:
在上一步我們創建了爬蟲函數,接下來將創建線程了,具體程式碼如下所示:
import threading #多线程 def multi_thread(): threads=[] for url in urls: threads.append( threading.Thread(target=get_parse,args=(url,)) )
首先我們導入threading模組,自訂multi_thread函數,再建立一個空列表threads來存放執行緒任務,透過threading.Thread()方法來建立執行緒。其中:
target為運行函數;args為運行函數所需的參數。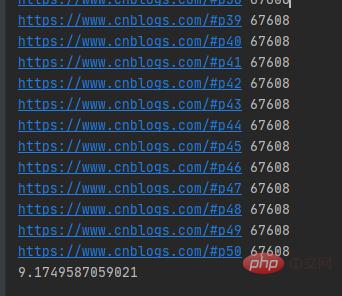
啟動執行緒
######執行緒已經建立好了,接下來將啟動執行緒了,啟動執行緒很簡單,具體程式碼如下所示:###for thread in threads: thread.start()
for thread in threads: thread.join()
if __name__ == '__main__': t1=time.time() multi_thread() t2=time.time() print(t2-t1)
if __name__ == '__main__': t1=time.time() for i in urls: get_parse(i) t2=time.time() print(t2-t1)
线程池原理
一个线程池由两部分组成,如下图所示:
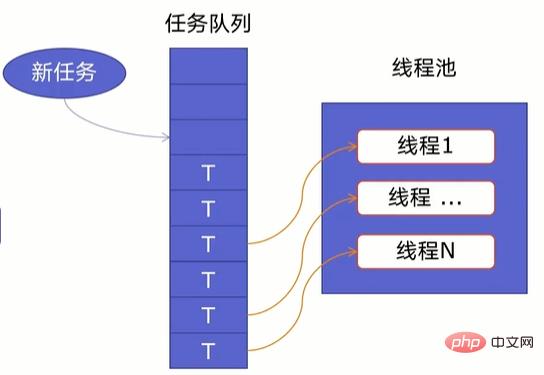
- 线程池:里面提前建好N个线程,这些都会被重复利用;
- 任务队列:当有新任务的时候,会把任务放在任务队列中。
当任务队列里有任务时,线程池的线程会从任务队列中取出任务并执行,执行完任务后,线程会执行下一个任务,直到没有任务执行后,线程会回到线程池中等待任务。
使用线程池可以处理突发性大量请求或需要大量线程完成任务(处理时间较短的任务)。
好了,了解了线程池原理后,我们开始创建线程池。
线程池创建
Python提供了ThreadPoolExecutor类来创建线程池,其语法如下所示:
ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())
其中:
- max_workers:最大线程数;
- thread_name_prefix:允许用户控制由线程池创建的threading.Thread工作线程名称以方便调试;
- initializer:是在每个工作者线程开始处调用的一个可选可调用对象;
- initargs:传递给初始化器的元组参数。
注意:在启动 max_workers 个工作线程之前也会重用空闲的工作线程。
在ThreadPoolExecutor类中提供了map()和submit()函数来插入任务队列。其中:
map()函数
map()语法格式为:
map(调用方法,参数队列)
具体示例如下所示:
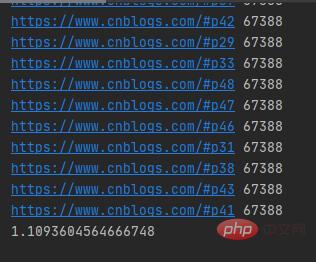
import requestsimport concurrent.futuresimport timeurls=[f'https://www.cnblogs.com/#p{page}'for page in range(1,50)]def get_parse(url):response=requests.get(url)return response.textdef map_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20) as pool:htmls=pool.map(get_parse,urls)htmls=list(zip(urls,htmls))for url,html in htmls:print(url,len(html))if __name__ == '__main__':t1=time.time()map_pool()t2=time.time()print(t2-t1)首先我们导入requests网络请求库、concurrent.futures模块,把所有的URL放在urls列表中,然后自定义get_parse()方法来返回网络请求返回的数据,再自定义map_pool()方法来创建代理池,其中代理池的最大max_workers为20,调用map()方法把网络请求任务放在任务队列中,在把返回的数据和URL合并为元组,并放在htmls列表中。
运行结果如下图所示:
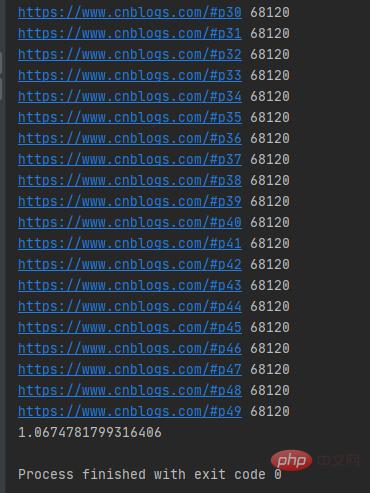
可以发现map()函数返回的结果和传入的参数顺序是对应的。
注意:当我们直接在自定义方法get_parse()中打印结果时,打印结果是乱序的。
submit()函数
submit()函数语法格式如下:
submit(调用方法,参数)
具体示例如下:
def submit_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20)as pool:futuress=[pool.submit(get_parse,url)for url in urls]futures=zip(urls,futuress)for url,future in futures:print(url,len(future.result()))
运行结果如下图所示:
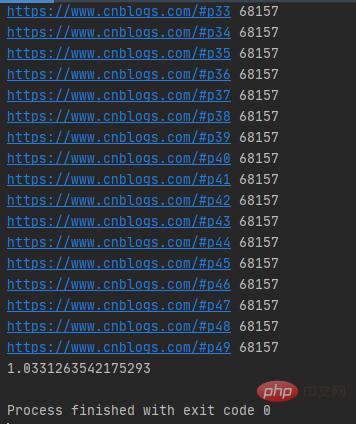
注意:submit()函数输出结果需需要调用result()方法。
好了,线程知识就学到这里了,接下来开始我们的爬虫。
爬前分析
首先我们进入同程旅行的景点网页并打开开发者工具,如下图所示:
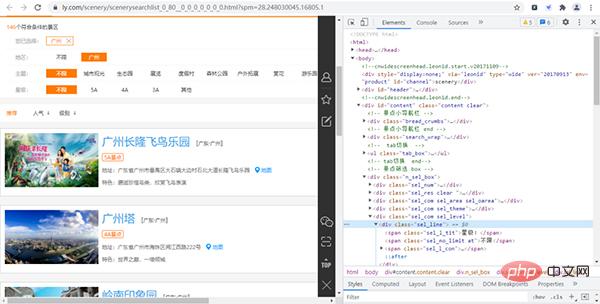
经过寻找,我们发现各个景点的基础信息(详情页URL、景点id等)都存放在下图的URL链接中,
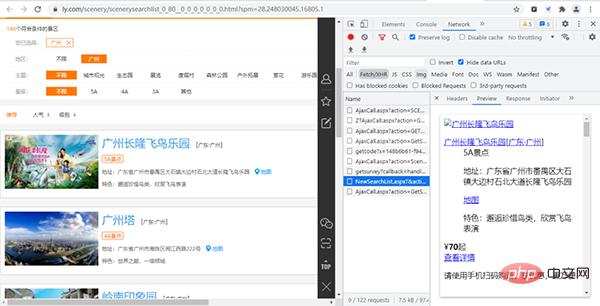
其URL链接为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=2&kw=&pid=6&cid=80&cyid=0&sort=&isnow=0&spType=&lbtypes=&IsNJL=0&classify=0&grade=&dctrack=1%CB%871629537670551030%CB%8720%CB%873%CB%872557287248299209%CB%870&iid=0.6901326566387387
经过增删改查操作,我们可以把该URL简化为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=1&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0
其中page为我们翻页的重要参数。
打开该URL链接,如下图所示:
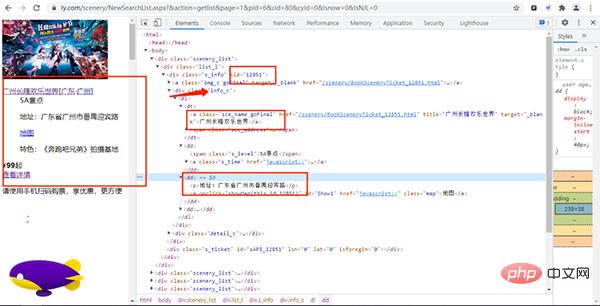
通过上面的URL链接,我们可以获取到很多景点的基础信息,随机打开一个景点的详情网页并打开开发者模式,经过查找,评论数据存放在如下图的URL链接中,
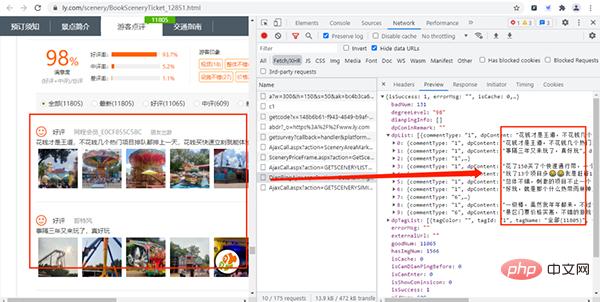
其URL链接如下所示:
https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid=12851&page=1&pageSize=10&labId=1&sort=0&iid=0.48901069375088
其中:action、labId、iid、sort为常量,sid是景点的id,page控制翻页,pageSize是每页获取的数据量。
在上上步中,我们知道景点id的存放位置,那么构造评论数据的URL就很简单了。
实战演练
这次我们爬虫步骤是:
- 获取景点基本信息
- 获取评论数据
- 创建MySQL数据库
- 保存数据
- 创建线程池
- 数据分析
获取景点基本信息
首先我们先获取景点的名字、id、价格、特色、地点和等级,主要代码如下所示:
def get_parse(url):response=requests.get(url,headers=headers)Xpath=parsel.Selector(response.text)data=Xpath.xpath('/html/body/div')for i in data:Scenery_data={'title':i.xpath('./div/div[1]/div[1]/dl/dt/a/text()').extract_first(),'sid':i.xpath('//div[@]/div/@sid').extract_first(),'Grade':i.xpath('./div/div[1]/div[1]/dl/dd[1]/span/text()').extract_first(), 'Detailed_address':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:',''),'characteristic':i.xpath('./div/div[1]/div[1]/dl/dd[3]/p/text()').extract_first(),'price':i.xpath('./div/div[1]/div[2]/div[1]/span/b/text()').extract_first(),'place':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:','')[6:8]}首先自定义方法get_parse()来发送网络请求后使用parsel.Selector()方法来解析响应的文本数据,然后通过xpath来获取数据。
获取评论数据
获取景点基本信息后,接下来通过景点基本信息中的sid来构造评论信息的URL链接,主要代码如下所示:
def get_data(Scenery_data):for i in range(1,3):link = f'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid={Scenery_data["sid"]}&page={i}&pageSize=100&labId=1&sort=0&iid=0.20105777381446832'response=requests.get(link,headers=headers)Json=response.json()commtent_detailed=Json.get('dpList')# 有评论数据if commtent_detailed!=None:for i in commtent_detailed:Comment_information={'dptitle':Scenery_data['title'],'dpContent':i.get('dpContent'),'dpDate':i.get('dpDate')[5:7],'lineAccess':i.get('lineAccess')}#没有评论数据elif commtent_detailed==None:Comment_information={'dptitle':Scenery_data['title'],'dpContent':'没有评论','dpDate':'没有评论','lineAccess':'没有评论'}首先自定义方法get_data()并传入刚才获取的景点基础信息数据,然后通过景点基础信息的sid来构造评论数据的URL链接,当在构造评论数据的URL时,需要设置pageSize和page这两个变量来获取多条评论和进行翻页,构造URL链接后就发送网络请求。
这里需要注意的是:有些景点是没有评论,所以我们需要通过if语句来进行设置。
创建MySQL数据库
这次我们把数据存放在MySQL数据库中,由于数据比较多,所以我们把数据分为两种数据表,一种是景点基础信息表,一种是景点评论数据表,主要代码如下所示:
#创建数据库def create_db():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port)cursor=db.cursor()sql='create database if not exists commtent default character set utf8'cursor.execute(sql)db.close()create_table()#创建景点信息数据表def create_table():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db='commtent')cursor=db.cursor()sql = 'create table if not exists Scenic_spot_data (title varchar(255) not null, link varchar(255) not null,Grade varchar(255) not null, Detailed_address varchar(255) not null, characteristic varchar(255)not null, price int not null, place varchar(255) not null)'cursor.execute(sql)db.close()
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,然后关闭数据库连接,最后调用自定义方法create_table()来创建景点信息数据表。
这里我们只给出了创建景点信息数据表的代码,因为创建数据表只是sql这条语句稍微有点不同,其他都一样,大家可以参考这代码来创建各个景点评论数据表。
保存数据
创建好数据库和数据表后,接下来就要保存数据了,主要代码如下所示:
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,使用了try-except语句,当保存的数据不成功,就调用rollback()方法,撤消当前事务中所做的所有更改,并释放此连接对象当前使用的任何数据库锁。
#保存景点数据到景点数据表中def saving_scenery_data(srr):db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='commtent')cursor = db.cursor()sql = 'insert into Scenic_spot_data(title, link, Grade, Detailed_address, characteristic,price,place) values(%s,%s,%s,%s,%s,%s,%s)'try:cursor.execute(sql, srr)db.commit()except:db.rollback()db.close()
注意:srr是传入的景点信息数据。
创建线程池
好了,单线程爬虫已经写好了,接下来将创建一个函数来创建我们的线程池,使单线程爬虫变为多线程,主要代码如下所示:
urls = [f'https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page={i}&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0'for i in range(1, 6)]def multi_thread():with concurrent.futures.ThreadPoolExecutor(max_workers=8)as pool:h=pool.map(get_parse,urls)if __name__ == '__main__':create_db()multi_thread()创建线程池的代码很简单就一个with语句和调用map()方法
运行结果如下图所示:
好了,数据已经获取到了,接下来将进行数据分析。
数据可视化
首先我们来分析一下各个景点那个月份游玩的人数最多,这样我们就不用担心去游玩的时机不对了。
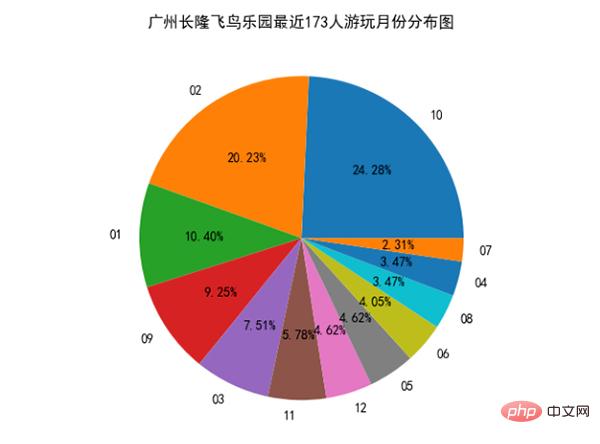
我们发现10月、2月、1月去广州长隆飞鸟乐园游玩的人数占总体比例最多。分析完月份后,我们来看看评论情况如何:
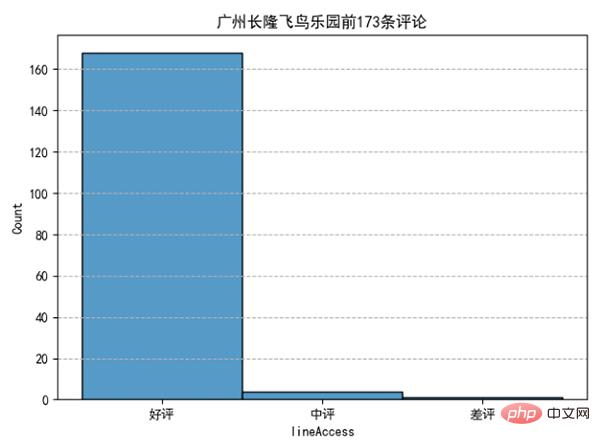
可以发现去好评占了绝大部分,可以说:去长隆飞鸟乐园玩耍,去了都说好。看了评论情况,评论内容有什么:

好了,获取旅游景点信息及评论并做词云、数据可视化就讲到这里了。
以上是Python 取得旅遊景點資訊及評論並作詞雲、資料視覺化的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 mysql 是否要付費
Apr 08, 2025 pm 05:36 PM
mysql 是否要付費
Apr 08, 2025 pm 05:36 PM
MySQL 有免費的社區版和收費的企業版。社區版可免費使用和修改,但支持有限,適合穩定性要求不高、技術能力強的應用。企業版提供全面商業支持,適合需要穩定可靠、高性能數據庫且願意為支持買單的應用。選擇版本時考慮的因素包括應用關鍵性、預算和技術技能。沒有完美的選項,只有最合適的方案,需根據具體情況謹慎選擇。
 mysql安裝後怎麼使用
Apr 08, 2025 am 11:48 AM
mysql安裝後怎麼使用
Apr 08, 2025 am 11:48 AM
文章介紹了MySQL數據庫的上手操作。首先,需安裝MySQL客戶端,如MySQLWorkbench或命令行客戶端。 1.使用mysql-uroot-p命令連接服務器,並使用root賬戶密碼登錄;2.使用CREATEDATABASE創建數據庫,USE選擇數據庫;3.使用CREATETABLE創建表,定義字段及數據類型;4.使用INSERTINTO插入數據,SELECT查詢數據,UPDATE更新數據,DELETE刪除數據。熟練掌握這些步驟,並學習處理常見問題和優化數據庫性能,才能高效使用MySQL。
 mysql 需要互聯網嗎
Apr 08, 2025 pm 02:18 PM
mysql 需要互聯網嗎
Apr 08, 2025 pm 02:18 PM
MySQL 可在無需網絡連接的情況下運行,進行基本的數據存儲和管理。但是,對於與其他系統交互、遠程訪問或使用高級功能(如復制和集群)的情況,則需要網絡連接。此外,安全措施(如防火牆)、性能優化(選擇合適的網絡連接)和數據備份對於連接到互聯網的 MySQL 數據庫至關重要。
 如何針對高負載應用程序優化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何針對高負載應用程序優化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL數據庫性能優化指南在資源密集型應用中,MySQL數據庫扮演著至關重要的角色,負責管理海量事務。然而,隨著應用規模的擴大,數據庫性能瓶頸往往成為製約因素。本文將探討一系列行之有效的MySQL性能優化策略,確保您的應用在高負載下依然保持高效響應。我們將結合實際案例,深入講解索引、查詢優化、數據庫設計以及緩存等關鍵技術。 1.數據庫架構設計優化合理的數據庫架構是MySQL性能優化的基石。以下是一些核心原則:選擇合適的數據類型選擇最小的、符合需求的數據類型,既能節省存儲空間,又能提升數據處理速度
 HadiDB:Python 中的輕量級、可水平擴展的數據庫
Apr 08, 2025 pm 06:12 PM
HadiDB:Python 中的輕量級、可水平擴展的數據庫
Apr 08, 2025 pm 06:12 PM
HadiDB:輕量級、高水平可擴展的Python數據庫HadiDB(hadidb)是一個用Python編寫的輕量級數據庫,具備高度水平的可擴展性。安裝HadiDB使用pip安裝:pipinstallhadidb用戶管理創建用戶:createuser()方法創建一個新用戶。 authentication()方法驗證用戶身份。 fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 Navicat查看MongoDB數據庫密碼的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB數據庫密碼的方法
Apr 08, 2025 pm 09:39 PM
直接通過 Navicat 查看 MongoDB 密碼是不可能的,因為它以哈希值形式存儲。取回丟失密碼的方法:1. 重置密碼;2. 檢查配置文件(可能包含哈希值);3. 檢查代碼(可能硬編碼密碼)。
 mysql workbench 可以連接到 mariadb 嗎
Apr 08, 2025 pm 02:33 PM
mysql workbench 可以連接到 mariadb 嗎
Apr 08, 2025 pm 02:33 PM
MySQL Workbench 可以連接 MariaDB,前提是配置正確。首先選擇 "MariaDB" 作為連接器類型。在連接配置中,正確設置 HOST、PORT、USER、PASSWORD 和 DATABASE。測試連接時,檢查 MariaDB 服務是否啟動,用戶名和密碼是否正確,端口號是否正確,防火牆是否允許連接,以及數據庫是否存在。高級用法中,使用連接池技術優化性能。常見錯誤包括權限不足、網絡連接問題等,調試錯誤時仔細分析錯誤信息和使用調試工具。優化網絡配置可以提升性能
 mysql 需要服務器嗎
Apr 08, 2025 pm 02:12 PM
mysql 需要服務器嗎
Apr 08, 2025 pm 02:12 PM
對於生產環境,通常需要一台服務器來運行 MySQL,原因包括性能、可靠性、安全性和可擴展性。服務器通常擁有更強大的硬件、冗餘配置和更嚴格的安全措施。對於小型、低負載應用,可在本地機器運行 MySQL,但需謹慎考慮資源消耗、安全風險和維護成本。如需更高的可靠性和安全性,應將 MySQL 部署到雲服務器或其他服務器上。選擇合適的服務器配置需要根據應用負載和數據量進行評估。
