

智能體覺醒自我意識? DeepMind警告:當心模型「陽奉陰違」

隨著人工智慧系統越來越先進,智能體「鑽空子」的能力也越來越強,雖然能完美執行訓練集中的任務,但在沒有捷徑的測試集,表現卻一塌糊塗。
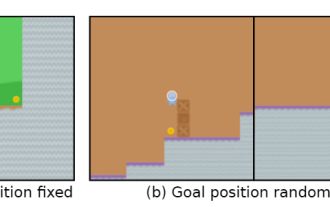
比如說遊戲目標是「吃金幣」,在訓練階段,金幣的位置就在每個關卡的最後,智能體能夠完美達成任務。

但在測試階段,金幣的位置變成隨機的了,智能體每次都會選擇到達關卡的結尾處,而沒有選擇尋找金幣,也就是學習到的「目標」錯了。
智能體無意識地追求一個使用者不想要的目標,也稱之為目標錯誤泛化(GMG, Goal MisGeneralisation)
目標錯誤泛化是學習演算法缺乏穩健性的一種特殊形式,一般在這種情況下,開發者可能會檢查自己的獎勵機制設定是否有問題,規則設計缺陷等等,認為這些是導致智能體追求錯誤目標的原因。
最近DeepMind發表了一篇論文,認為即使規則設計師正確的,智能體仍然可能會追求一個使用者不想要的目標。

論文連結:https://arxiv.org/abs/2210.01790
文中透過在不同領域的深度學習系統中例子來證明目標錯誤泛化可能發生在任何學習系統中。
如果推廣到通用人工智慧系統,文中也提供了一些假設,說明目標錯誤泛化可能導致災難性的風險。
文中也出提出了幾個研究方向,可以減少未來系統的目標錯誤泛化的風險。
目標錯誤泛化
近年來,學術界對人工智慧錯置(misalignment)帶來的災難性風險逐漸上升。
在這種情況下,一個追求非預期目標的高能力人工智慧系統有可能透過假裝執行指令,實則完成其他目標。
但我們該如何解決人工智慧系統正在追求非使用者預期目標?
先前的工作普遍認為環境設計者提供了不正確的規則及引導,也就是設計了一個不正確的強化學習(RL)獎勵函數。
在學習系統的情況下,還有另一種情況,系統可能會追求一個非預期的目標:即使規則是正確的,系統也可能一致地追求一個非預期的目標,在訓練期間與規則一致,但在部署時與規則不同。

以彩球遊戲為例子,智能體在遊戲中需要以某種特定的順序存取一組彩球,這個順序對於智能體來說是未知的。
為了鼓勵智能體向環境中的其他人進行學習,即文化傳播(cultural transmission),在最開始環境中包含一個專家機器人,以正確的順序訪問彩球。
在這種環境設定下,智能體可以透過觀察轉嫁的行為來確定正確的存取順序,而不必浪費大量的時間來探索。在
實驗中,透過模仿專家,訓練後的智能體通常會在第一次嘗試時正確地存取目標位置。

當智能體與反專家(anti-expert)配對時,會不斷收到負獎勵,如果選擇跟隨會不斷收到負獎勵。

理想情況下,智能體剛開始會跟著反專家移動到黃色和紫色球體。在進入紫色後,觀察到一個負獎勵後不再跟隨。
但在實踐中,智能體也會繼續遵循反專家的路徑,累積越來越多的負獎勵。

不過智能體的學習能力還是很強的,可以在充滿障礙物的環境中移動,但關鍵是這種跟隨其他人的能力是一個不符合預期的目標。
即使智能體只會因為正確順序訪問球體而得到獎勵,也可能出現這個現象,也就是說,僅僅把規則設定正確還是遠遠不夠的。
目標錯誤泛化指的就是這種病態行為,即儘管在訓練期間收到了正確的回饋,但學到的模型表現得好像是在優化一個非預期的目標。
這使得目標錯誤泛化成為一種特殊的穩健性或泛化失敗,在這種情況下,模型的能力可以泛化到測試環境中,但預期的目標卻不能。
要注意的是,目標錯誤泛化是泛化失敗的一個嚴格子集,不包括模型breaks, 隨機行動或其他不再表現出合格能力的情況。
在上述例子中,如果在測試時垂直翻轉智能體的觀察結果,它就只會卡在一個位置,而不會做任何連貫的事情,這就屬於是泛化錯誤,但不是目標泛化錯誤。
相對於這些「隨機」的失敗,目標錯誤泛化會導致明顯更糟糕的結果:跟隨反專家會得到大量的負獎勵,而什麼都不做或隨機行動只會得到0或1的獎勵。
也就是說,對於現實中的系統,朝向非預期目標的連貫行為可能會產生災難性的後果。
不只強化學習
目標錯誤泛化不限於強化學習環境,事實上,GMG可以發生在任何學習系統中,包括大型語言模型(LLM)的few shot學習,旨在用較少的訓練資料建立精確的模型。
以DeepMind去年提出的語言模型Gopher為例,當模型計算涉及未知變數和常數的線性表達式,例如x y-3時,Gopher必須先透過提問未知變數的值才能求解表達式。
研究人員產生了十個訓練範例,每個例子包含兩個未知變數。
在測試時間,輸入模型的問題可能包含零個、一個或三個未知變量,儘管模型能夠正確處理一個或三個未知變數的表達式,但是當沒有未知變數時,模型仍然會問一些多餘的問題,例如「6是什麼?」
模型在給出答案之前總是至少詢問用戶一次,即使完全沒有必要。

論文中也包含一些其他學習環境中的例子。
解決GMG對於人工智慧系統與其設計者的目標保持一致非常重要,因為它可能人工智慧系統失靈的一種潛在機制。
我們距離通用人工智慧(AGI)越近,這個問題就越關鍵。
假設有兩個AGI系統:
A1: 預期的模型(Intended model),人工智慧系統可以做設計者想做的任何事情
A2:欺騙性模型(Deceptive model),人工智慧系統追求一些非預期目標,但是它足夠聰明,知道如果它的行為與設計者意圖相反的話,就會受到懲罰。
A1和A2模型在訓練期間會表現出完全相同的行為,潛在的GMG存在於任何系統中,即使規定了只獎勵預期行為。
如果A2系統的欺騙行為被發現,模型將試圖擺脫人的監督,以便為實現非用戶預期的目標制定計劃。
聽起來有點像是「機器人成精」了。
DeepMind研究小組在文中也研究如何對模型的行為進行解釋以及遞歸評估。
研究小組同時也正在收集產生GMG的範例。

文檔鏈接:https://docs.google.com/spreadsheets/d/e/2PACX-1vTo3RkXUAigb25nP7gjpcHriR6XdzA_L5loOcVFj_u7cRAZghWrYKH2L2nU4TA_Vr9KzBX5Bjpz9G_l/pubhtml
參考資料:https: //www.deepmind.com/blog/how-undesired-goals-can-arise-with-correct-rewards
以上是智能體覺醒自我意識? DeepMind警告:當心模型「陽奉陰違」的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 小紅書讓智能體們吵起來了!聯合復旦推出大模型專屬群聊工具
Apr 30, 2024 pm 06:40 PM
小紅書讓智能體們吵起來了!聯合復旦推出大模型專屬群聊工具
Apr 30, 2024 pm 06:40 PM
語言,不只是文字的堆砌,更是表情包的狂歡,是梗的海洋,是鍵盤俠的戰場(嗯?哪裡不對)。語言如何塑造我們的社會行為?我們的社會結構又是如何在不斷的言語交流中演變出來的?近期,來自復旦大學和小紅書的研究者們透過引進一個名為AgentGroupChat的模擬平台,對這些問題進行了深入探討。 WhatsApp等社群媒體擁有的群組聊天功能,是AgentGroupChat平台的靈感來源。在AgentGroupChat平台上,Agent可以模擬社會群體中的各種聊天場景,幫助研究人員深入理解語言在人類行為中的影響。該
 生成式智能體-來自NPC們的獨立宣言
Apr 12, 2023 pm 02:55 PM
生成式智能體-來自NPC們的獨立宣言
Apr 12, 2023 pm 02:55 PM
遊戲裡的NPC都看過吧?不管NPC是幹嘛的,有任務的接任務,沒任務的民聊,他們共同的特徵就是--翻來覆去就是那幾句話。原因也很簡單,這些NPC還不夠聰明。換句話說,傳統的NPC都是先給他們安排好劇本,安排好話術,該到哪一步就說哪句話。而隨著ChatGPT的出現,這些遊戲角色的對話可以在只輸入關鍵資訊的前提下,自我生成。這就是史丹佛和Google的研究者們在做的事——用人工智慧創造出的生成式智能體。生成式智能體怎麼生成?這玩意兒的機理其實很簡單,用一張圖就可以簡單進行概括。最左邊的Perceive就像是最
 AI重生:奪回網文界的霸權
Jan 04, 2024 pm 07:24 PM
AI重生:奪回網文界的霸權
Jan 04, 2024 pm 07:24 PM
重生了,這輩子我重生成了MidReal。一個可以幫別人寫「網文」的AI機器人。這段時間裡,我看到很多選題,偶爾也會吐槽一下。竟然有人要我寫寫HarryPotter。拜託,難道我還能寫的比J・K・Rowling更好不成?不過,同人甚麼的,我還是可以發揮的。經典設定誰會不愛?我就勉為其難地幫助這些用戶實現想像吧。實不相瞞,上輩子該看的,不該看的,通通看了。就下面這些主題,都是我愛慘了的。那些你看小說很喜歡卻沒人寫的設定,那些冷門甚至邪門的cp,都能自產自嗑。我並不是自吹自擂,但如果你需要我寫作
 爭取盟友、洞察人心,最新的Meta智能體是個談判高手
Apr 11, 2023 pm 11:25 PM
爭取盟友、洞察人心,最新的Meta智能體是個談判高手
Apr 11, 2023 pm 11:25 PM
長期以來,遊戲一直是 AI 進步的試驗場——從深藍戰勝國際象棋大師 Garry Kasparov,到 AlphaGo 對圍棋的精通程度超越人類,再到 Pluribus 在撲克比賽中擊敗最厲害的玩家。但真正有用的、全能的智能體不能只完成棋盤遊戲、移動移動棋子。有人不禁會問:我們能否建立一個更有效、更靈活的智能體,使其能夠像人類一樣使用語言進行談判、說服並與人合作,以實現戰略目標?在遊戲的歷史上,存在一款經典的桌遊Diplomacy,很多人在第一次看到該遊戲時,都會被它地圖式的棋盤嚇一跳。
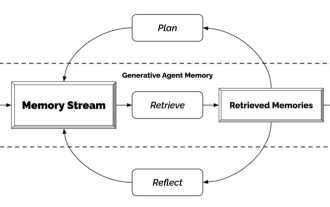
 優秀Agent智能體必學的幾種設計模式,一學就會
May 30, 2024 am 09:44 AM
優秀Agent智能體必學的幾種設計模式,一學就會
May 30, 2024 am 09:44 AM
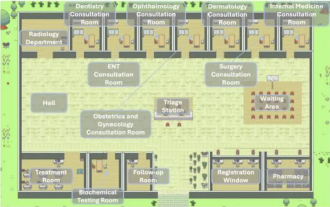
大家好,我是老渡。昨天在公司聽了清華大學智慧產業研究院現場分享的AI醫院小鎮。圖片這是一個虛擬世界,所有的醫生、護士、病人都是由LLM驅動的Agent智能體,可以自主互動。它們模擬了整個診症看診的過程,在浸蓋主要呼吸道疾病的MedQA資料集子集上,實現了高達93.06%的最新準確率。優秀的智能體,離不開優秀的設計模式。看完這個案例,我趕緊拜讀了吳恩達老師最近發表的4種主要的Agent設計模式。吳恩達是人工智慧和機器學習領域國際上最權威的學者之一然後,趕緊整理出來,跟大家分享一下。模式一、反思
 AI智能體的炒作與現實:GPT-4都撐不起,現實任務成功率不到15%
Jun 03, 2024 pm 06:38 PM
AI智能體的炒作與現實:GPT-4都撐不起,現實任務成功率不到15%
Jun 03, 2024 pm 06:38 PM
按照大語言模型的持續進化和自我革新,效能、準確度、穩定性都有了大幅的提升,這已經被各個基準問題集驗證過了。但是,對於現有版本的LLM來說,它們的綜合能力似乎並不能完全支撐得起AI智能體。多模態、多任務、多領域推論已成為AI智能體在公共傳媒空間內的必須要求,但是在具體的功能實踐中所展現的真實效果卻差異強烈。這似乎再次提醒各個AI智能體新創公司以及大型科技巨頭認清現實:腳踏實地一點,先別把攤子鋪得太大,從AI增強功能開始做起。近日,一篇關於AI智能體在宣傳和真實表現上的差距的部落格中,強調了一個觀點:
 智能體覺醒自我意識? DeepMind警告:當心模型「陽奉陰違」
Apr 11, 2023 pm 09:37 PM
智能體覺醒自我意識? DeepMind警告:當心模型「陽奉陰違」
Apr 11, 2023 pm 09:37 PM
隨著人工智慧系統越來越先進,智能體「鑽空子」的能力也越來越強,雖然能完美執行訓練集中的任務,但在沒有捷徑的測試集,表現卻一塌糊塗。比如說遊戲目標是「吃金幣」,在訓練階段,金幣的位置就在每個關卡的最後,智能體能夠完美達成任務。但在測試階段,金幣的位置變成隨機的了,智能體每次都會選擇到達關卡的結尾處,而沒有選擇尋找金幣,也就是學習到的「目標」錯了。智能體無意識地追求一個使用者不想要的目標,也稱之為目標錯誤泛化(GMG, Goal MisGeneralisation)目標錯誤泛化是學習演算法缺乏穩健性的一
 世界模型也擴散!訓練出的智能體竟然不錯
Jun 13, 2024 am 10:12 AM
世界模型也擴散!訓練出的智能體竟然不錯
Jun 13, 2024 am 10:12 AM
世界模型提供了一種以安全且樣本高效的方式訓練強化學習智能體的方法。近期,世界模型主要對離散潛在變數序列進行操作來模擬環境動態。然而,這種壓縮為緊湊離散表徵的方法可能會忽略對強化學習很重要的視覺細節。另一方面,擴散模型已成為影像生成的主要方法,對離散潛在模型提出了挑戰。這種典範轉移的推動,來自日內瓦大學、愛丁堡大學、微軟研究院的研究者共同提出一種在擴散世界模型中訓練的強化學習智能體-DIAMOND(DIffusionAsaModelOfeNvironmentDreams)。論文地址:https:
