

1 月9 日訊息,2020 年6 月,在訓練約2000 億個單字、燒掉幾千萬美元後,史上最強大AI 模型「生成型已訓練變換模型3」(GPT-3)一炮而紅。
這個 OpenAI 打造的語言 AI 模型宛如萬能選手,只有你想不到的畫風,沒有它輸不出的文案,既能創作文學,能當翻譯,還能編寫自己的電腦程式碼。任何外行人都可以使用這個模型,幾分鐘內提供範例,就能獲得想要的文本產出。
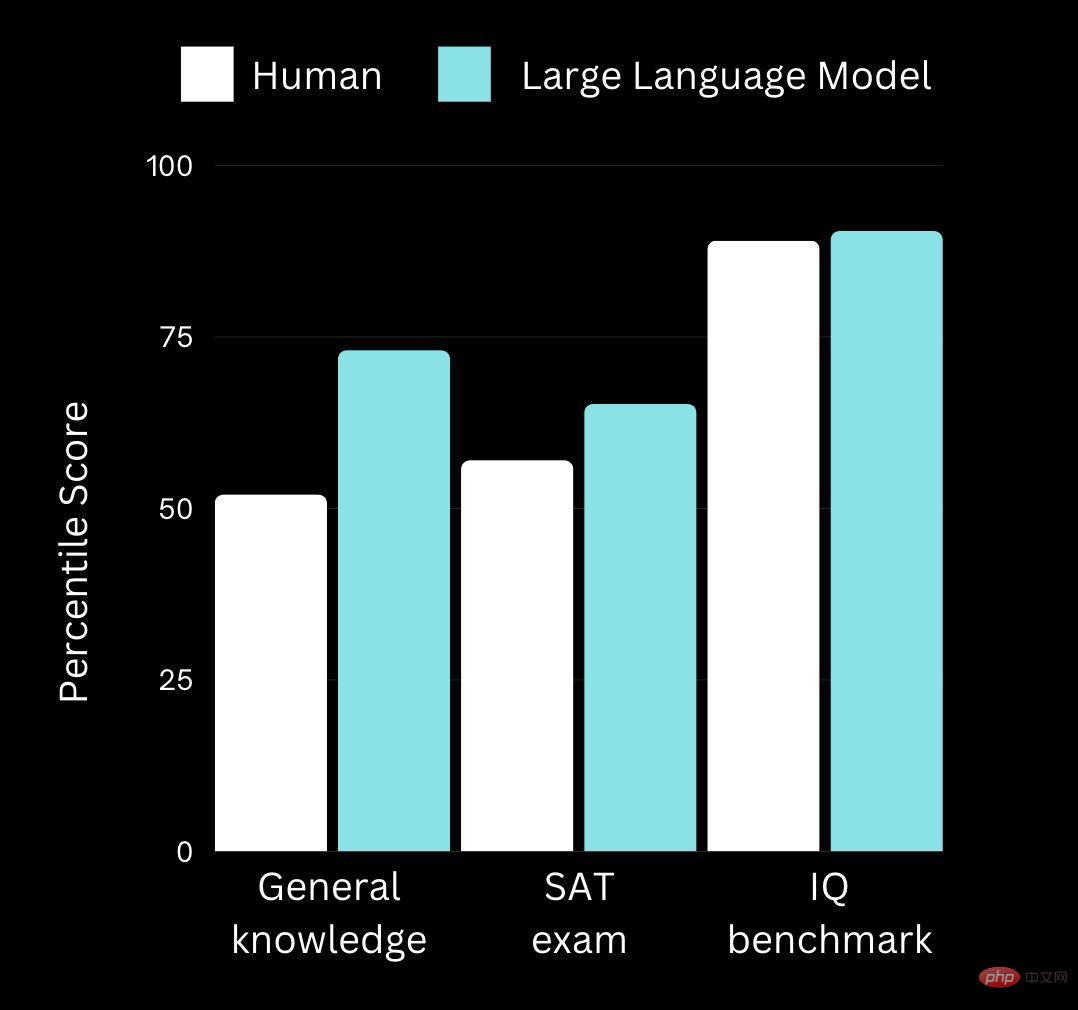
根據新華社,美國加州大學洛杉磯分校的研究人員發現,在一系列測量智力的推理測驗中,自回歸語言模式 GPT-3 的成績明顯優於一般大學生。
該程式利用深度學習產生類似人類語言的文字。 GPT-3 有許多用途,包括語言翻譯和為聊天機器人生成文字等,其有 1750 億個參數,是目前規模最大、功能最強的語言處理人工智慧模型之一。
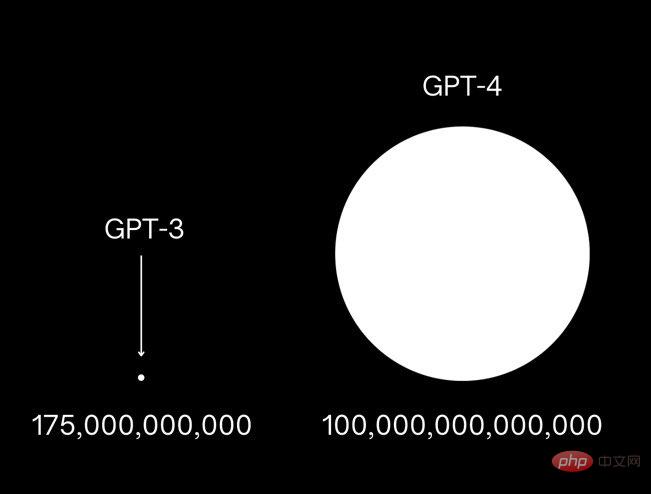
IT之家這裡突然想到,OpenAI 的ChatGPT 似乎也實現了類似效果,雖然它依然基於GGPT-3,但這個模型被業界稱為「GPT-4」 ,這也是矽谷研究實驗室推出的第四代語言模型,對全世界的搜尋引擎、作家、編碼人員、教授以及Nickelback 構成了生存威脅。
當然,根據大多數專家的意見,與即將發布的 GPT-4 主版本相比,ChatGPT 現版本只能說是一個開胃小菜。
加州大學研究者認為,這類大型語言模型重新引發了在提供足夠訓練資料的情況下人類認知能力是否更強的爭論。特別令人感興趣的是這些模型能夠零樣本地推理新問題,而無需對這些問題進行任何直接訓練。
研究人員指出,在人類認知中,這種能力與類比推理能力密切相關,而他們在一系列類比任務上對GPT-3 進行了直接比較,包括與Raven 的漸進矩陣密切相關的新型基於文本的矩陣推理任務,最終發現GPT-3 表現出了驚人的抽像模式歸納能力,在大多數情況下匹配甚至超越人類的能力。
最終結果表明,諸如 GPT-3 這樣的大型語言模型已經獲得了一種“新興能力”,可以為廣泛的類比問題找到零樣本解決方案。
https://doi.org/10.48550/arXiv.2212.09196
以上是研究發現,人工智慧語言模型 GPT-3 在智商測驗中明顯勝過人類大學生的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















