

持續學習常用六種方法總結:使ML模型適應新資料的同時保持舊資料的效能

持續學習是指在不忘記從前面的任務中獲得的知識的情況下,按順序學習大量任務的模型。這是一個重要的概念,因為在監督學習的前提下,機器學習模型被訓練為針對給定資料集或資料分佈的最佳函數。而在現實環境中,資料很少是靜態的,可能會改變。當面對不可見的資料時,典型的ML模型可能會效能下降。這種現像被稱為災難性遺忘。

解決這類問題的常用方法是在包含新舊資料的新的更大資料集上對整個模型進行再訓練。但是這種做法往往代價高昂。所以有一個ML研究領域正在研究這個問題,基於該領域的研究,本文將討論6種方法,使模型可以在保持舊的性能的同時適應新數據,並避免需要在整個數據集(舊新)上進行重新訓練。
Prompt
Prompt 想法源自於GPT 3的提示(短序列的單字)可以幫助驅動模型更好地推理和回答。所以在本文中將Prompt 翻譯為提示。提示調優是指使用小型可學習的提示,並將其與實際輸入一起作為模型的輸入。這允許我們只在新資料上訓練提供提示的小模型,而無需再訓練模型權重。
具體來說,我選擇了使用提示進行基於文本的密集檢索的例子,這個例子改編自Wang的文章《Learning to Prompt for continuous Learning》。
論文的作者使用下圖描述了他們的想法:
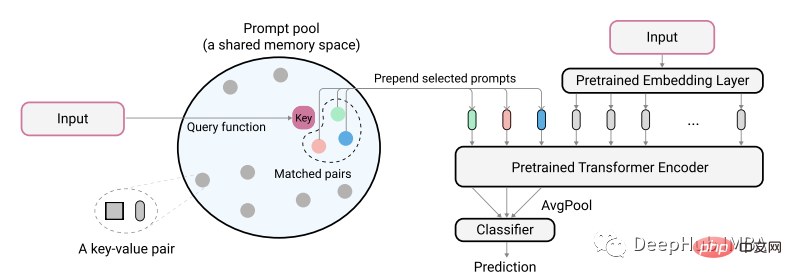
#實際編碼的文字輸入用作從提示池中識別最小匹配對的key。在將這些標識的提示輸入到模型之前,首先將它們新增至未編碼的文字嵌入。這樣做的目的是訓練這些提示來表示新的任務,同時保持舊的模型不變,這裡提示的很小,大概每個提示只有20個令牌。
class PromptPool(nn.Module):
def __init__(self, M = 100, hidden_size = 768, length = 20, N=5):
super().__init__()
self.pool = nn.Parameter(torch.rand(M, length, hidden_size), requires_grad=True).float()
self.keys = nn.Parameter(torch.rand(M, hidden_size), requires_grad=True).float()
self.length = length
self.hidden = hidden_size
self.n = N
nn.init.xavier_normal_(self.pool)
nn.init.xavier_normal_(self.keys)
def init_weights(self, embedding):
pass
# function to select from pool based on index
def concat(self, indices, input_embeds):
subset = self.pool[indices, :] # 2, 2, 20, 768
subset = subset.to("cuda:0").reshape(indices.size(0),
self.n*self.length,
self.hidden) # 2, 40, 768
return torch.cat((subset, input_embeds), 1)
# x is cls output
def query_fn(self, x):
# encode input x to same dim as key using cosine
x = x / x.norm(dim=1)[:, None]
k = self.keys / self.keys.norm(dim=1)[:, None]
scores = torch.mm(x, k.transpose(0,1).to("cuda:0"))
# get argmin
subsets = torch.topk(scores, self.n, 1, False).indices # k smallest
return subsets
pool = PromptPool()然後我們使用的經過訓練的舊數據模型,訓練新的數據,這裡只訓練提示部分的權重。
def train():
count = 0
print("*********** Started Training *************")
start = time.time()
for epoch in range(40):
model.eval()
pool.train()
optimizer.zero_grad(set_to_none=True)
lap = time.time()
for batch in iter(train_dataloader):
count += 1
q, p, train_labels = batch
queries_emb = model(input_ids=q['input_ids'].to("cuda:0"),
attention_mask=q['attention_mask'].to("cuda:0"))
passage_emb = model(input_ids=p['input_ids'].to("cuda:0"),
attention_mask=p['attention_mask'].to("cuda:0"))
# pool
q_idx = pool.query_fn(queries_emb)
raw_qembedding = model.model.embeddings(input_ids=q['input_ids'].to("cuda:0"))
q = pool.concat(indices=q_idx, input_embeds=raw_qembedding)
p_idx = pool.query_fn(passage_emb)
raw_pembedding = model.model.embeddings(input_ids=p['input_ids'].to("cuda:0"))
p = pool.concat(indices=p_idx, input_embeds=raw_pembedding)
qattention_mask = torch.ones(batch_size, q.size(1))
pattention_mask = torch.ones(batch_size, p.size(1))
queries_emb = model.model(inputs_embeds=q,
attention_mask=qattention_mask.to("cuda:0")).last_hidden_state
passage_emb = model.model(inputs_embeds=p,
attention_mask=pattention_mask.to("cuda:0")).last_hidden_state
q_cls = queries_emb[:, pool.n*pool.length+1, :]
p_cls = passage_emb[:, pool.n*pool.length+1, :]
loss, ql, pl = calc_loss(q_cls, p_cls)
loss.backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
if count % 10 == 0:
print("Model Loss:", round(loss.item(),4),
"| QL:", round(ql.item(),4), "| PL:", round(pl.item(),4),
"| Took:", round(time.time() - lap), "secondsn")
lap = time.time()
if count % 40 == 0 and count > 0:
print("model saved")
torch.save(model.state_dict(), model_PATH)
torch.save(pool.state_dict(), pool_PATH)
if count == 4600: return
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")訓練完成後,後續的推理過程需要將輸入與檢索到的提示結合。例如這個例子得到了效能—93%的新資料提示池,而完全(舊 新)訓練為—94%。這與原論文中提到的表現類似。但是需要說明的一點是結果可能會因任務而不同,你應該嘗試實驗來知道什麼是最好的。
要使此方法成為值得考慮的方法,它必須能夠在舊資料上保留舊模型> 80%的效能,同時提示也應該幫助模型在新資料上獲得良好的效能。
這種方法的缺點是需要使用提示池,這會增加額外的時間。這也不是一個永久的解決方案,但目前來說是可行的,或許以後還會有新的方法出現。
Data Distillation
你可能聽說過知識蒸餾一詞,這是一種使用來自教師模型的權重來指導和訓練較小規模模型的技術。資料蒸餾(Data Distillation)的工作原理也類似,它是使用來自真實資料的權重來訓練較小的資料子集。因為資料集的關鍵訊號被提煉並濃縮為較小的資料集,我們對新資料的訓練只需要提供一些提煉的資料以保持舊的效能。
在此範例中,我將資料蒸餾應用於密集檢索(文字)任務。目前看沒有其他人在這個領域使用這種方法,所以結果可能不是最好的,但如果你在文字分類上使用這種方法應該會得到不錯的結果。
本質上,文本資料蒸餾的想法源自於 Li 的一篇題為 Data Distillation for Text Classification 的論文,該論文的靈感來自 Wang 的 Dataset Distillation,他對圖像資料進行了蒸餾。 Li 用下圖描述了文本資料蒸餾的任務:
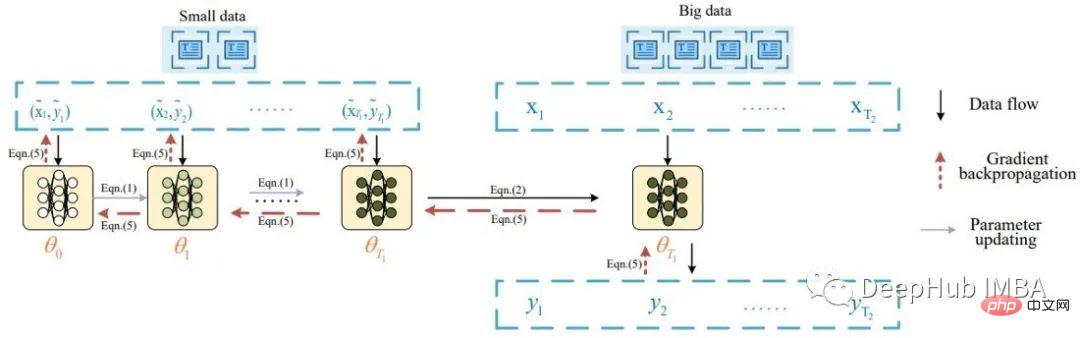
根據論文,首先將一批蒸餾資料輸入到模型以更新其權重。然後使用真實數據評估更新後的模型,並將訊號反向傳播到蒸餾數據集。該論文在 8 個公共基準資料集上報告了良好的分類結果(> 80% 準確率)。
依照提出的想法,我做了一些小的改動,使用了一批蒸餾數據和多個真實數據。以下是為密集檢索訓練創建蒸餾數據的代碼:
class DistilledData(nn.Module):
def __init__(self, num_labels, M, q_len=64, hidden_size=768):
super().__init__()
self.num_samples = M
self.q_len = q_len
self.num_labels = num_labels
self.data = nn.Parameter(torch.rand(num_labels, M, q_len, hidden_size), requires_grad=True) # i.e. shape: 1000, 4, 64, 768
# init using model embedding, xavier, or load from state dict
def init_weights(self, model, path=None):
if model:
self.data.requires_grad = False
print("Init weights using model embedding")
raw_embedding = model.model.get_input_embeddings()
soft_embeds = raw_embedding.weight[:, :].clone().detach()
nums = soft_embeds.size(0)
for i1 in range(self.num_labels):
for i2 in range(self.num_samples):
for i3 in range(self.q_len):
random_idx = random.randint(0, nums-1)
self.data[i1, i2, i3, :] = soft_embeds[random_idx, :]
print(self.data.shape)
self.data.requires_grad = True
if not path:
nn.init.xavier_normal_(self.data)
else:
distilled_data.load_state_dict(torch.load(path), strict=False)
# function to sample a passage and positive sample as in the article, i am doing dense retrieval
def get_sample(self, label):
q_idx = random.randint(0, self.num_samples-1)
sampled_dist_q = self.data[label, q_idx, :, :]
p_idx = random.randint(0, self.num_samples-1)
while q_idx == p_idx:
p_idx = random.randint(0, self.num_samples-1)
sampled_dist_p = self.data[label, p_idx, :, :]
return sampled_dist_q, sampled_dist_p, q_idx, p_idx這是將信號提取到蒸餾數據上的代碼
def distll_train(chunk_size=32):
count, times = 0, 0
print("*********** Started Training *************")
start = time.time()
lap = time.time()
for epoch in range(40):
distilled_data.train()
for batch in iter(train_dataloader):
count += 1
# get real query, pos, label, distilled data query, distilled data pos, ... from batch
q, p, train_labels, dq, dp, q_indexes, p_indexes = batch
for idx in range(0, dq['input_ids'].size(0), chunk_size):
model.train()
with torch.enable_grad():
# train on distiled data first
x1 = dq['input_ids'][idx:idx+chunk_size].clone().detach().requires_grad_(True)
x2 = dp['input_ids'][idx:idx+chunk_size].clone().detach().requires_grad_(True)
q_emb = model(inputs_embeds=x1.to("cuda:0"),
attention_mask=dq['attention_mask'][idx:idx+chunk_size].to("cuda:0")).cpu()
p_emb = model(inputs_embeds=x2.to("cuda:0"),
attention_mask=dp['attention_mask'][idx:idx+chunk_size].to("cuda:0"))
loss = default_loss(q_emb.to("cuda:0"), p_emb)
del q_emb, p_emb
loss.backward(retain_graph=True, create_graph=False)
state_dict = model.state_dict()
# update model weights
with torch.no_grad():
for idx, param in enumerate(model.parameters()):
if param.requires_grad and not param.grad is None:
param.data -= (param.grad*3e-5)
# real data
model.eval()
q_embs = []
p_embs = []
for k in range(0, len(q['input_ids']), chunk_size):
with torch.no_grad():
q_emb = model(input_ids=q['input_ids'][k:k+chunk_size].to("cuda:0"),).cpu()
p_emb = model(input_ids=p['input_ids'][k:k+chunk_size].to("cuda:0"),).cpu()
q_embs.append(q_emb)
p_embs.append(p_emb)
q_embs = torch.cat(q_embs, 0)
p_embs = torch.cat(p_embs, 0)
r_loss = default_loss(q_embs.to("cuda:0"), p_embs.to("cuda:0"))
del q_embs, p_embs
# distill backward
if count % 2 == 0:
d_grad = torch.autograd.grad(inputs=[x1.to("cuda:0")],#, x2.to("cuda:0")],
outputs=loss,
grad_outputs=r_loss)
indexes = q_indexes
else:
d_grad = torch.autograd.grad(inputs=[x2.to("cuda:0")],
outputs=loss,
grad_outputs=r_loss)
indexes = p_indexes
loss.detach()
r_loss.detach()
grads = torch.zeros(distilled_data.data.shape) # lbl, 10, 100, 768
for i, k in enumerate(indexes):
grads[train_labels[i], k, :, :] = grads[train_labels[i], k, :, :].to("cuda:0")
+ d_grad[0][i, :, :]
distilled_data.data.grad = grads
data_optimizer.step()
data_optimizer.zero_grad(set_to_none=True)
model.load_state_dict(state_dict)
model_optimizer.step()
model_optimizer.zero_grad(set_to_none=True)
if count % 10 == 0:
print("Count:", count ,"| Data:", round(loss.item(), 4), "| Model:",
round(r_loss.item(),4), "| Time:", round(time.time() - lap, 4))
# print()
lap = time.time()
if count % 100 == 0:
torch.save(model.state_dict(), model_PATH)
torch.save(distilled_data.state_dict(), distill_PATH)
if loss < 0.1 and r_loss < 1:
times += 1
if times > 100:
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")
return
del loss, r_loss, grads, q, p, train_labels, dq, dp, x1, x2, state_dict
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")這裡省略了數據加載等代碼,訓練完蒸餾的數據後,我們可以透過在其上訓練新模型來使用它,例如將其與新資料合併一起訓練。
根據我的實驗,一個在蒸餾資料上訓練的模型(每個標籤只包含4個樣本)獲得了66%的最佳性能,而一個完全在原始資料上訓練的模型也是得到了66%的最佳性能。而未經訓練的普通模型得到45%的表現。就像上面提到的這些數字對於密集檢索任務可能不太好,分類資料會好很多。
要使此方法成為在調整模型以適應新資料時值是一個有用的方法,需要能夠提取比原始資料小得多的資料集(即~ 1%)。經過提煉的數據也能夠給你一個略低於或等於主動學習方法的表現。
這個方法的優點是可以創建用於永久使用的蒸餾資料。缺點是提取的數據沒有可解釋性,並且需要額外的訓練時間。
Curriculum/Active training
Curriculum training是一種方法,訓練時向模型提供訓練樣本的難度逐漸變大。在對新資料進行訓練時,此方法需要人工的對任務進行標註,將任務分為簡單、中等或困難,然後對資料進行採樣。為了理解模型的簡單、中等或困難意味著什麼,我以這張圖片為例:
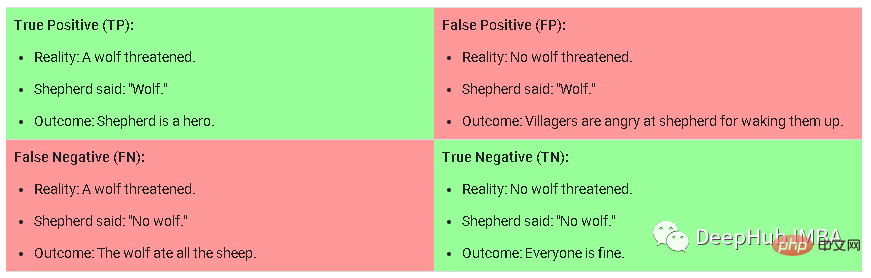
這是在分類任務中的混淆矩陣,困難樣本是假陽性(False Positive),是指模型預測為True的可能性很高,但實際上不是True的樣本。中等樣本是那些具有中到高的正確性可能性但低於預測閾值的True Negative。而簡單樣本則是那些可能性較低的True Positive/Negative。
Maximally Interfered Retrieval
這是 Rahaf 在題為“Online Continual Learning with Maximally Interfered Retrieval”的論文(1908.04742)中介紹的一種方法。主要想法是,對於正在訓練的每個新資料批次,如果針對較新資料更新模型權重,將需要識別在損失值方面受影響最大的舊樣本。保留由舊資料組成的有限大小的內存,並檢索最大干擾的樣本以及每個新資料批次以一起訓練。
這篇論文在持續學習領域是一篇成熟的論文,並且有很多引用,因此可能適用於您的案例。
Retrieval Augmentation
檢索增強(Retrieval Augmentation)是指透過從集合中檢索項目來擴充輸入、樣本等的技術。這是一個普遍的概念而不是一個特定的技術。我們到目前為止所討論的方法,大多數都在一定程度都是檢索相關的操作。 Izacard 的題為 Few-shot Learning with Retrieval Augmented Language Models 的論文使用更小的模型獲得了出色的少樣本 學習的性能。檢索增強也用於許多其他情況,例如單字產生或回答事實問題。
擴展模型在訓練時使用附加層是最常見也最簡單的方法,但是不一定有效,所以在這裡不進行詳細的討論,這裡的一個例子是Lewis 的Efficient Few-Shot Learning without Prompts。使用附加層通常是在新舊數據上獲得良好性能的最簡單但經過嘗試和測試的方法。主要想法是保持模型權重固定,並透過分類損失在新資料上訓練一層或幾層。
總結在本文中,我介紹了在新資料上訓練模型時可以使用的 6 種方法。像往常一樣應該進行實驗並決定哪種方法最適合,但是需要注意的是,除了我上面的方法外還有很多方法,例如數據蒸餾是計算機視覺中的一個活躍領域,你可以找到很多關於它的論文。最後說明的一點是:要使這些方法有價值,它們應該在舊數據和新數據上同時獲得良好的性能 。
以上是持續學習常用六種方法總結:使ML模型適應新資料的同時保持舊資料的效能的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 15個值得推薦的開源免費圖片標註工具
Mar 28, 2024 pm 01:21 PM
15個值得推薦的開源免費圖片標註工具
Mar 28, 2024 pm 01:21 PM
圖像標註是將標籤或描述性資訊與圖像相關聯的過程,以賦予圖像內容更深層的含義和解釋。這個過程對於機器學習至關重要,它有助於訓練視覺模型以更準確地識別圖像中的各個元素。透過為圖像添加標註,使得電腦能夠理解圖像背後的語義和上下文,從而提高對圖像內容的理解和分析能力。影像標註的應用範圍廣泛,涵蓋了許多領域,如電腦視覺、自然語言處理和圖視覺模型具有廣泛的應用領域,例如,輔助車輛識別道路上的障礙物,幫助疾病的檢測和診斷透過醫學影像識別。本文主要推薦一些較好的開源免費的圖片標註工具。 1.Makesens
 一文帶您了解SHAP:機器學習的模型解釋
Jun 01, 2024 am 10:58 AM
一文帶您了解SHAP:機器學習的模型解釋
Jun 01, 2024 am 10:58 AM
在機器學習和資料科學領域,模型的可解釋性一直是研究者和實踐者關注的焦點。隨著深度學習和整合方法等複雜模型的廣泛應用,理解模型的決策過程變得尤為重要。可解釋人工智慧(ExplainableAI|XAI)透過提高模型的透明度,幫助建立對機器學習模型的信任和信心。提高模型的透明度可以透過多種複雜模型的廣泛應用等方法來實現,以及用於解釋模型的決策過程。這些方法包括特徵重要性分析、模型預測區間估計、局部可解釋性演算法等。特徵重要性分析可以透過評估模型對輸入特徵的影響程度來解釋模型的決策過程。模型預測區間估計
 透過學習曲線辨識過擬合和欠擬合
Apr 29, 2024 pm 06:50 PM
透過學習曲線辨識過擬合和欠擬合
Apr 29, 2024 pm 06:50 PM
本文將介紹如何透過學習曲線來有效辨識機器學習模型中的過度擬合和欠擬合。欠擬合和過擬合1、過擬合如果一個模型對資料進行了過度訓練,以至於它從中學習了噪聲,那麼這個模型就被稱為過擬合。過度擬合模型非常完美地學習了每一個例子,所以它會錯誤地分類一個看不見的/新的例子。對於一個過度擬合的模型,我們會得到一個完美/接近完美的訓練集分數和一個糟糕的驗證集/測試分數。略有修改:"過擬合的原因:用一個複雜的模型來解決一個簡單的問題,從資料中提取雜訊。因為小資料集作為訓練集可能無法代表所有資料的正確表示。"2、欠擬合如
 人工智慧在太空探索和人居工程中的演變
Apr 29, 2024 pm 03:25 PM
人工智慧在太空探索和人居工程中的演變
Apr 29, 2024 pm 03:25 PM
1950年代,人工智慧(AI)誕生。當時研究人員發現機器可以執行類似人類的任務,例如思考。後來,在1960年代,美國國防部資助了人工智慧,並建立了實驗室進行進一步開發。研究人員發現人工智慧在許多領域都有用武之地,例如太空探索和極端環境中的生存。太空探索是對宇宙的研究,宇宙涵蓋了地球以外的整個宇宙空間。太空被歸類為極端環境,因為它的條件與地球不同。要在太空中生存,必須考慮許多因素,並採取預防措施。科學家和研究人員認為,探索太空並了解一切事物的現狀有助於理解宇宙的運作方式,並為潛在的環境危機
 通透!機器學習各大模型原理的深度剖析!
Apr 12, 2024 pm 05:55 PM
通透!機器學習各大模型原理的深度剖析!
Apr 12, 2024 pm 05:55 PM
通俗來說,機器學習模型是一種數學函數,它能夠將輸入資料映射到預測輸出。更具體地說,機器學習模型是一種透過學習訓練數據,來調整模型參數,以最小化預測輸出與真實標籤之間的誤差的數學函數。在機器學習中存在多種模型,例如邏輯迴歸模型、決策樹模型、支援向量機模型等,每種模型都有其適用的資料類型和問題類型。同時,不同模型之間存在著許多共通性,或者說有一條隱藏的模型演化的路徑。將聯結主義的感知機為例,透過增加感知機的隱藏層數量,我們可以將其轉化為深度神經網路。而對感知機加入核函數的話就可以轉換為SVM。這一
 使用C++實現機器學習演算法:常見挑戰及解決方案
Jun 03, 2024 pm 01:25 PM
使用C++實現機器學習演算法:常見挑戰及解決方案
Jun 03, 2024 pm 01:25 PM
C++中機器學習演算法面臨的常見挑戰包括記憶體管理、多執行緒、效能最佳化和可維護性。解決方案包括使用智慧指標、現代線程庫、SIMD指令和第三方庫,並遵循程式碼風格指南和使用自動化工具。實作案例展示如何利用Eigen函式庫實現線性迴歸演算法,有效地管理記憶體和使用高效能矩陣操作。
 你所不知道的機器學習五大學派
Jun 05, 2024 pm 08:51 PM
你所不知道的機器學習五大學派
Jun 05, 2024 pm 08:51 PM
機器學習是人工智慧的重要分支,它賦予電腦從數據中學習的能力,並能夠在無需明確編程的情況下改進自身能力。機器學習在各個領域都有廣泛的應用,從影像辨識和自然語言處理到推薦系統和詐欺偵測,它正在改變我們的生活方式。機器學習領域存在著多種不同的方法和理論,其中最具影響力的五種方法被稱為「機器學習五大派」。這五大派分別為符號派、聯結派、進化派、貝葉斯派和類推學派。 1.符號學派符號學(Symbolism),又稱符號主義,強調利用符號進行邏輯推理和表達知識。該學派認為學習是一種逆向演繹的過程,透過現有的
 Flash Attention穩定嗎? Meta、哈佛發現其模型權重偏差呈現數量級波動
May 30, 2024 pm 01:24 PM
Flash Attention穩定嗎? Meta、哈佛發現其模型權重偏差呈現數量級波動
May 30, 2024 pm 01:24 PM
MetaFAIR聯合哈佛優化大規模機器學習時所產生的資料偏差,提供了新的研究架構。據所周知,大語言模型的訓練常常需要數月的時間,使用數百甚至上千個GPU。以LLaMA270B模型為例,其訓練總共需要1,720,320個GPU小時。由於這些工作負載的規模和複雜性,導致訓練大模型存在著獨特的系統性挑戰。最近,許多機構在訓練SOTA生成式AI模型時報告了訓練過程中的不穩定情況,它們通常以損失尖峰的形式出現,例如Google的PaLM模型訓練過程中出現了多達20次的損失尖峰。數值偏差是造成這種訓練不準確性的根因,
