

用Python做一個房價預測小工具!


哈嘍,大家好。
這是一個房價預測的案例,來自 Kaggle 網站,是許多演算法初學者的第一道競賽題目。
此案例有著解機器學習問題的完整流程,包含EDA、特徵工程、模型訓練、模型融合等。
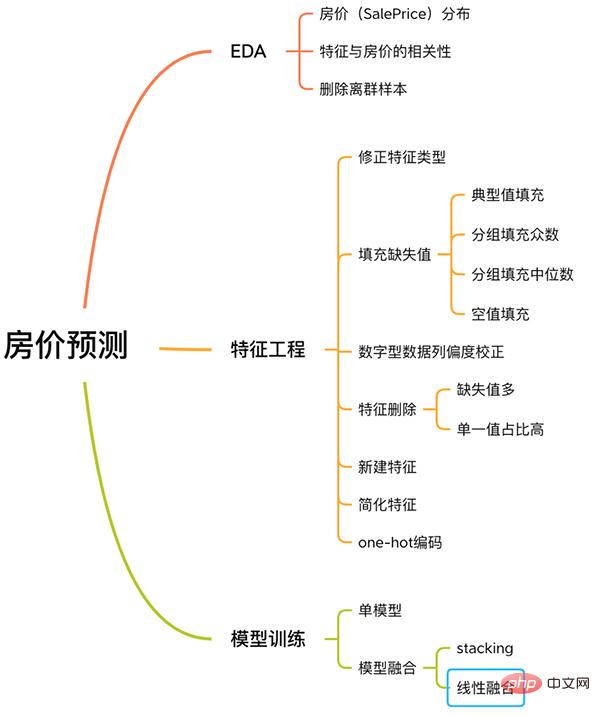
房價預測流程
下面跟著我,來學習該案例。
沒有囉嗦的文字,沒有多餘的程式碼,只有通俗的講解。
一. EDA
探索性資料分析(Exploratory Data Analysis,簡稱EDA) 的目的在於讓我們對資料集有充分的了解。在這一步驟,我們探索的內容如下:

EDA內容
1.1 輸入資料集
train = pd.read_csv('./data/train.csv')
test = pd.read_csv('./data/test.csv')

訓練樣本
train和test分別是訓練集和測試集,分別有1460 個樣本,80 個特徵。
SalePrice欄位代表房價,是我們要預測的。
1.2 房價分佈
因為我們任務是預測房價,所以在資料集中核心要關注的就是房價(SalePrice) 一列的值分佈。
sns.distplot(train['SalePrice']);
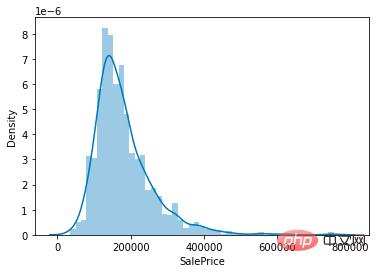
房價取值分佈
從圖上可以看出,SalePrice列峰值比較陡,且峰值向左偏。
也可以直接呼叫skew()和kurt()函數計算SalePrice具體的偏度和峰度值。
對於偏度和峰度都比較大的情況,建議對SalePrice列取log()進行平滑。
1.3 與房價相關的特徵
了解完SalePrice的分佈後,我們可以計算 80 個特徵與SalePrice的相關關係。
聚焦在與SalePrice相關性最強的 10 個特徵。
# 计算列之间相关性
corrmat = train.corr()
# 取 top10
k = 10
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
# 绘图
cm = np.corrcoef(train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
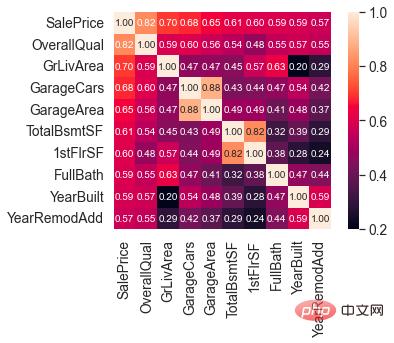
與SalePrice高度相關的特徵
OverallQual(房子材料和裝飾)、GrLivArea(地上居住面積)、GarageCars(車庫容量)和TotalBsmtSF (地下室面積)跟SalePrice有很強的相關性。
這些特徵在後面做特徵工程時也會重點關注。
1.4 剔除離群樣本
由於資料集樣本量很少,離群點不利於我們後面訓練模型。
所以要計算每個數值特性的離群點,剔除離群次數最多的樣本。
# 获取数值型特征 numeric_features = train.dtypes[train.dtypes != 'object'].index # 计算每个特征的离群样本 for feature in numeric_features: outs = detect_outliers(train[feature], train['SalePrice'],top=5, plot=False) all_outliers.extend(outs) # 输出离群次数最多的样本 print(Counter(all_outliers).most_common()) # 剔除离群样本 train = train.drop(train.index[outliers])
detect_outliers()是自訂函數,用sklearn函式庫的LocalOutlierFactor演算法計算離群點。
到這裡, EDA 就完成了。最後,將訓練集和測試集合併,進行下面的特徵工程。
y = train.SalePrice.reset_index(drop=True) train_features = train.drop(['SalePrice'], axis=1) test_features = test features = pd.concat([train_features, test_features]).reset_index(drop=True)
features合併了訓練集和測試集的特徵,是我們下面要處理的資料。
二. 特徵工程
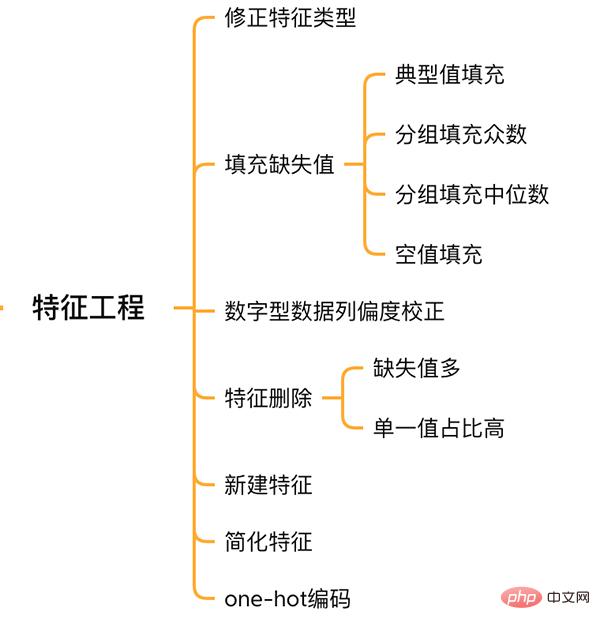
特徵工程
2.1 校正特徵類型
MSSubClass(房屋類型)、YrSold (銷售年份)和MoSold(銷售月份)是類別型特徵,只不過用數字來表示,需要將它們轉換成文字特徵。
features['MSSubClass'] = features['MSSubClass'].apply(str) features['YrSold'] = features['YrSold'].astype(str) features['MoSold'] = features['MoSold'].astype(str)
2.2 填滿特徵缺失值
填入缺失值沒有統一的標準,需要根據不同的特徵來決定以什麼樣的方式來填入。
# Functional:文档提供了典型值 Typ
features['Functional'] = features['Functional'].fillna('Typ') #Typ 是典型值
# 分组填充需要按照相似的特征分组,取众数或中位数
# MSZoning(房屋区域)按照 MSSubClass(房屋)类型分组填充众数
features['MSZoning'] = features.groupby('MSSubClass')['MSZoning'].transform(lambda x: x.fillna(x.mode()[0]))
#LotFrontage(到接到举例)按Neighborhood分组填充中位数
features['LotFrontage'] = features.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.median()))
# 车库相关的数值型特征,空代表无,使用0填充空值。
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
features[col] = features[col].fillna(0)
2.3 偏度校正
跟探索SalePrice列類似,對偏度高的特徵進行平滑。
# skew()方法,计算特征的偏度(skewness)。 skew_features = features[numeric_features].apply(lambda x: skew(x)).sort_values(ascending=False) # 取偏度大于 0.15 的特征 high_skew = skew_features[skew_features > 0.15] skew_index = high_skew.index # 处理高偏度特征,将其转化为正态分布,也可以使用简单的log变换 for i in skew_index: features[i] = boxcox1p(features[i], boxcox_normmax(features[i] + 1))
2.4 特徵刪除和新增
對於幾乎都是缺失值,或單一取值佔比高(99.94%)的特徵可以直接刪除。
features = features.drop(['Utilities', 'Street', 'PoolQC',], axis=1)
同時,可以融合多個特徵,產生新特徵。
有時候模型很難學習到特徵之間的關係,手動融合特徵可以降低模型學習難度,提升效果。
# 将原施工日期和改造日期融合 features['YrBltAndRemod']=features['YearBuilt']+features['YearRemodAdd'] # 将地下室面积、1楼、2楼面积融合 features['TotalSF']=features['TotalBsmtSF'] + features['1stFlrSF'] + features['2ndFlrSF']
可以發現,我們融合的特徵都是與SalePrice強相關的特徵。
最後簡化特徵,對分佈單調的特徵(如:100個資料中有99個的數值是0.9,另1個是0.1),進行01處理。
features['haspool'] = features['PoolArea'].apply(lambda x: 1 if x > 0 else 0) features['has2ndfloor'] = features['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
2.6 生成最终训练数据
到这里特征工程就做完了, 我们需要从features中将训练集和测试集重新分离出来,构造最终的训练数据。
X = features.iloc[:len(y), :] X_sub = features.iloc[len(y):, :] X = np.array(X.copy()) y = np.array(y) X_sub = np.array(X_sub.copy())
三. 模型训练
因为SalePrice是数值型且是连续的,所以需要训练一个回归模型。
3.1 单一模型
首先以岭回归(Ridge) 为例,构造一个k折交叉验证模型。
from sklearn.linear_model import RidgeCV from sklearn.pipeline import make_pipeline from sklearn.model_selection import KFold kfolds = KFold(n_splits=10, shuffle=True, random_state=42) alphas_alt = [14.5, 14.6, 14.7, 14.8, 14.9, 15, 15.1, 15.2, 15.3, 15.4, 15.5] ridge = make_pipeline(RobustScaler(), RidgeCV(alphas=alphas_alt, cv=kfolds))
岭回归模型有一个超参数alpha,而RidgeCV的参数名是alphas,代表输入一个超参数alpha数组。在拟合模型时,会从alpha数组中选择表现较好某个取值。
由于现在只有一个模型,无法确定岭回归是不是最佳模型。所以我们可以找一些出场率高的模型多试试。
# lasso lasso = make_pipeline( RobustScaler(), LassoCV(max_iter=1e7, alphas=alphas2, random_state=42, cv=kfolds)) #elastic net elasticnet = make_pipeline( RobustScaler(), ElasticNetCV(max_iter=1e7, alphas=e_alphas, cv=kfolds, l1_ratio=e_l1ratio)) #svm svr = make_pipeline(RobustScaler(), SVR( C=20, epsilon=0.008, gamma=0.0003, )) #GradientBoosting(展开到一阶导数) gbr = GradientBoostingRegressor(...) #lightgbm lightgbm = LGBMRegressor(...) #xgboost(展开到二阶导数) xgboost = XGBRegressor(...)
有了多个模型,我们可以再定义一个得分函数,对模型评分。
#模型评分函数 def cv_rmse(model, X=X): rmse = np.sqrt(-cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=kfolds)) return (rmse)
以岭回归为例,计算模型得分。
score = cv_rmse(ridge)
print("Ridge score: {:.4f} ({:.4f})n".format(score.mean(), score.std()), datetime.now(), ) #0.1024
运行其他模型发现得分都差不多。
这时候我们可以任选一个模型,拟合,预测,提交训练结果。还是以岭回归为例
# 训练模型
ridge.fit(X, y)
# 模型预测
submission.iloc[:,1] = np.floor(np.expm1(ridge.predict(X_sub)))
# 输出测试结果
submission = pd.read_csv("./data/sample_submission.csv")
submission.to_csv("submission_single.csv", index=False)
submission_single.csv是岭回归预测的房价,我们可以把这个结果上传到 Kaggle 网站查看结果的得分和排名。
3.2 模型融合-stacking
有时候为了发挥多个模型的作用,我们会将多个模型融合,这种方式又被称为集成学习。
stacking 是一种常见的集成学习方法。简单来说,它会定义个元模型,其他模型的输出作为元模型的输入特征,元模型的输出将作为最终的预测结果。
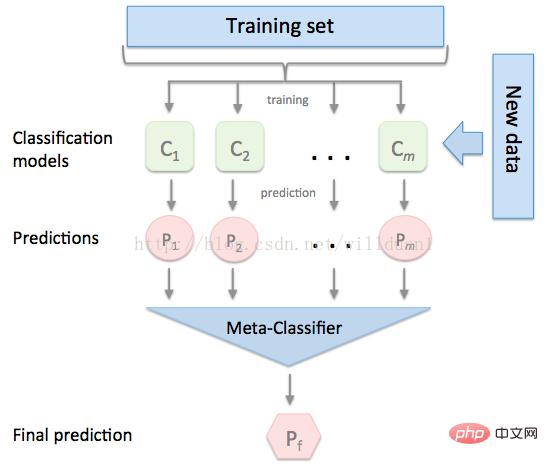
stacking
这里,我们用mlextend库中的StackingCVRegressor模块,对模型做stacking。
stack_gen = StackingCVRegressor( regressors=(ridge, lasso, elasticnet, gbr, xgboost, lightgbm), meta_regressor=xgboost, use_features_in_secondary=True)
训练、预测的过程与上面一样,这里不再赘述。
3.3 模型融合-线性融合
多模型线性融合的思想很简单,给每个模型分配一个权重(权重加和=1),最终的预测结果取各模型的加权平均值。
# 训练单个模型 ridge_model_full_data = ridge.fit(X, y) lasso_model_full_data = lasso.fit(X, y) elastic_model_full_data = elasticnet.fit(X, y) gbr_model_full_data = gbr.fit(X, y) xgb_model_full_data = xgboost.fit(X, y) lgb_model_full_data = lightgbm.fit(X, y) svr_model_full_data = svr.fit(X, y) models = [ ridge_model_full_data, lasso_model_full_data, elastic_model_full_data, gbr_model_full_data, xgb_model_full_data, lgb_model_full_data, svr_model_full_data, stack_gen_model ] # 分配模型权重 public_coefs = [0.1, 0.1, 0.1, 0.1, 0.15, 0.1, 0.1, 0.25] # 线性融合,取加权平均 def linear_blend_models_predict(data_x,models,coefs, bias): tmp=[model.predict(data_x) for model in models] tmp = [c*d for c,d in zip(coefs,tmp)] pres=np.array(tmp).swapaxes(0,1) pres=np.sum(pres,axis=1) return pres
到这里,房价预测的案例我们就讲解完了,大家可以自己运行一下,看看不同方式训练出来的模型效果。
回顾整个案例会发现,我们在数据预处理和特征工程上花费了很大心思,虽然机器学习问题模型原理比较难学,但实际过程中往往特征工程花费的心思最多。
以上是用Python做一個房價預測小工具!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 十大數字貨幣交易所app推薦 幣圈虛擬幣交易所排名前十
Apr 22, 2025 pm 03:03 PM
十大數字貨幣交易所app推薦 幣圈虛擬幣交易所排名前十
Apr 22, 2025 pm 03:03 PM
十大數字貨幣交易所app推薦:1. OKX,2. Binance,3. gate.io,4. Huobi,5. Coinbase,6. KuCoin,7. Kraken,8. Bitfinex,9. Bybit,10. Bitstamp,這些app均提供實時行情、技術分析和價格提醒功能,幫助用戶實時監控市場動態並做出明智的投資決策。
 靠譜好用的虛擬幣交易所app推薦 幣圈十大交易所排行榜最新
Apr 22, 2025 pm 01:21 PM
靠譜好用的虛擬幣交易所app推薦 幣圈十大交易所排行榜最新
Apr 22, 2025 pm 01:21 PM
靠譜好用的虛擬幣交易所app是:1. Binance,2. OKX,3. Gate.io,4. Coinbase,5. Kraken,6. Huobi Global,7. Bitfinex,8. KuCoin,9. Bittrex,10. Poloniex。這些平台因其交易量、用戶體驗和安全性等因素被評選為最佳,均提供註冊、驗證、存款、提款和交易操作功能。
 十大數字虛擬貨幣app排行榜 幣圈交易數字貨幣交易所排名前十
Apr 22, 2025 pm 03:00 PM
十大數字虛擬貨幣app排行榜 幣圈交易數字貨幣交易所排名前十
Apr 22, 2025 pm 03:00 PM
十大數字虛擬貨幣app排行榜分別是:1. OKX,2. Binance,3. gate.io,4. Coinbase,5. Kraken,6. Huobi,7. KuCoin,8. Bitfinex,9. Bitstamp,10. Poloniex。這些交易所根據交易量、用戶體驗和安全性等因素評選,均提供多種數字貨幣交易服務和高效的交易體驗。
 meme幣交易所排行榜 meme幣主流交易所top10盤點
Apr 22, 2025 am 09:57 AM
meme幣交易所排行榜 meme幣主流交易所top10盤點
Apr 22, 2025 am 09:57 AM
最適合交易Meme幣的平台包括:1. 幣安(Binance),全球最大,流動性高,低手續費;2. 歐意(OKX),高效交易引擎,支持多種Meme幣;3. XBIT,去中心化,支持跨鏈交易;4. 雷迪姆(Solana DEX),低成本,結合Serum訂單簿;5. PancakeSwap(BSC DEX),交易費用低,速度快;6. Orca(Solana DEX),用戶體驗優化;7. Coinbase,安全性高,適合新手;8. 火幣(Huobi),亞洲知名,交易對豐富;9. DEXRabbit,智能
 2025數字貨幣交易平台有哪些 十大數字貨幣app最新排行榜
Apr 22, 2025 pm 03:09 PM
2025數字貨幣交易平台有哪些 十大數字貨幣app最新排行榜
Apr 22, 2025 pm 03:09 PM
十大虛擬幣看盤平台app推薦:1. OKX,2. Binance,3. Gate.io,4. Huobi,5. Coinbase,6. Kraken,7. Bitfinex,8. KuCoin,9. Bybit,10. Bitstamp,這些平台提供實時行情、技術分析工具和用戶友好的界面,幫助投資者進行有效的市場分析和交易決策。
 適合新手的數字貨幣交易App有哪些?一文了解幣圈
Apr 22, 2025 am 08:45 AM
適合新手的數字貨幣交易App有哪些?一文了解幣圈
Apr 22, 2025 am 08:45 AM
選擇適合新手的數字貨幣交易平台需考慮安全性、易用性、教育資源和費用透明度:1. 優先選擇提供冷存儲、雙重驗證和資產保險的平台;2. 界面簡潔、操作清晰的App更適合新手;3. 平台應提供教程和市場分析等學習工具;4. 注意交易手續費和提現費等隱性成本。
 免費的看盤軟件網站有哪些 幣圈十大免費看行情軟件排名
Apr 22, 2025 am 10:57 AM
免費的看盤軟件網站有哪些 幣圈十大免費看行情軟件排名
Apr 22, 2025 am 10:57 AM
币圈十大免费看行情软件排名前三分别是OKX、Binance和gate.io。1. OKX提供简洁界面和实时数据,支持多种图表和市场分析。2. Binance功能强大,数据准确,适合各种交易者。3. gate.io以稳定性和全面性著称,适合长期和短线投资者。
 幣圈行情實時數據免費平台推薦前十名發布
Apr 22, 2025 am 08:12 AM
幣圈行情實時數據免費平台推薦前十名發布
Apr 22, 2025 am 08:12 AM
適合新手的加密貨幣數據平台有CoinMarketCap和非小號。 1. CoinMarketCap提供全球加密貨幣實時價格、市值、交易量排名,適合新手與基礎分析需求。 2. 非小號提供中文友好界面,適合中文用戶快速篩選低風險潛力項目。
