
在日常資料探勘工作中,除了會涉及到使用Python處理分類或預測任務,有時還會涉及推薦系統相關任務。
推薦系統用於各個領域,常見的例子包括影片和音樂服務的播放清單產生器、線上商店的產品推薦器或社群媒體平台的內容推薦器。在這個專案中,我們創建一個電影推薦器。
協同過濾透過收集許多使用者的偏好或品味訊息,對使用者的興趣進行自動預測(過濾)。到目前為止,推薦系統已經發展很長一段時間了,它們的模型是基於各種技術,如加權平均、相關性、機器學習、深度學習等等。
自 1995 年以來,Movielens 20M dataset 擁有超過 2000 萬個電影評級和標記活動。在本文中,我們將從movie.csv & rating.csv檔案中擷取資訊。使用Python庫:Pandas, Seaborn, Scikit-learn和SciPy,使用k-近鄰演算法中的餘弦相似度訓練模型。
以下是該專案的核心步驟:
MovieLens 20M 資料集自1995 年以來超過2000 萬的電影評級和標記活動。
# usecols 允许选择自己选择的特征,并通过dtype设定对应类型
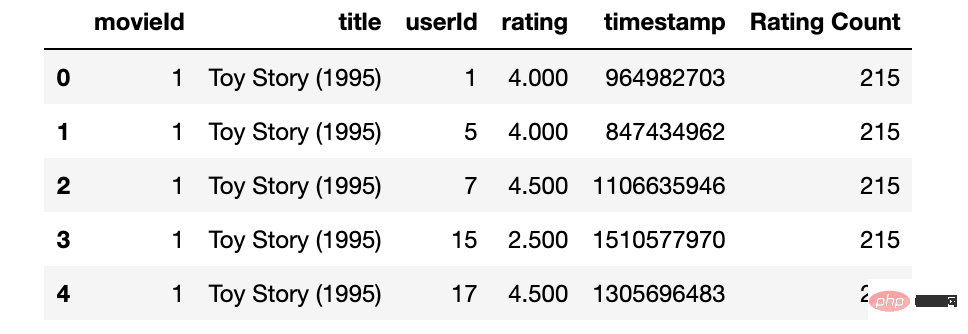
movies_df=pd.read_csv('movies.csv',
usecols=['movieId','title'],
dtype={'movieId':'int32','title':'str'})
movies_df.head()
ratings_df=pd.read_csv('ratings.csv',
usecols=['userId', 'movieId', 'rating','timestamp'],
dtype={'userId': 'int32', 'movieId': 'int32', 'rating': 'float32'})
ratings_df.head()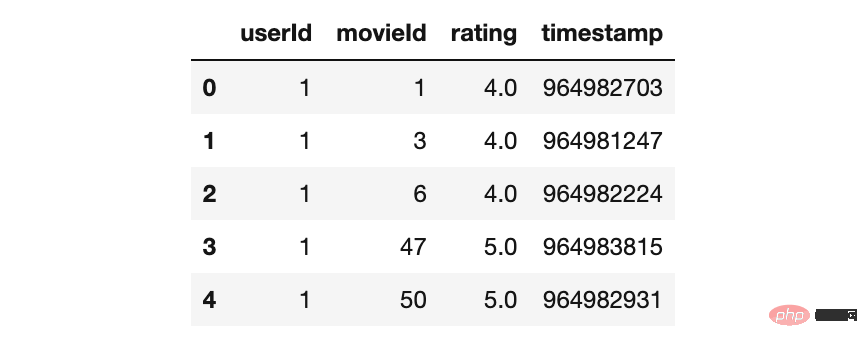
檢查是否存在任何空值以及兩個資料中的條目數。
# 检查缺失值 movies_df.isnull().sum()
movieId 0
title 0
dtype: int64
ratings_df.isnull().sum()
print("Movies:",movies_df.shape)
print("Ratings:",ratings_df.shape)# movies_df.info() # ratings_df.info() movies_merged_df=movies_df.merge(ratings_df, on='movieId') movies_merged_df.head()
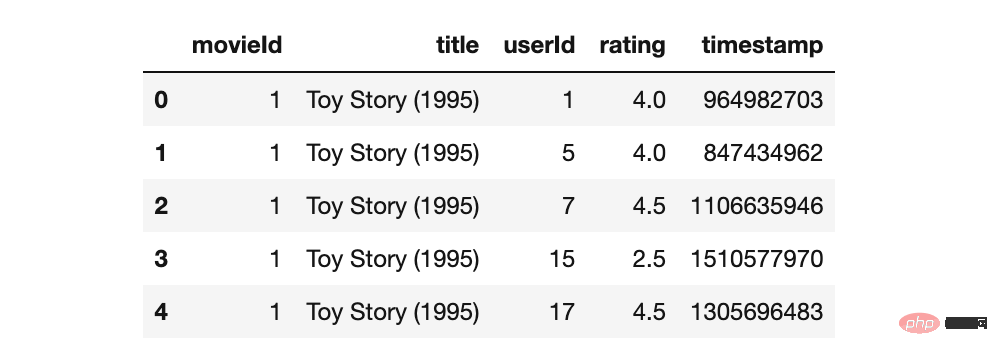
movies_average_rating=movies_merged_df.groupby('title')['rating']
.mean().sort_values(ascending=False)
.reset_index().rename(columns={'rating':'Average Rating'})
movies_average_rating.head()
movies_rating_count=movies_merged_df.groupby('title')['rating']
.count().sort_values(ascending=True)
.reset_index().rename(columns={'rating':'Rating Count'}) #ascending=False
movies_rating_count_avg=movies_rating_count.merge(movies_average_rating, on='title')
movies_rating_count_avg.head()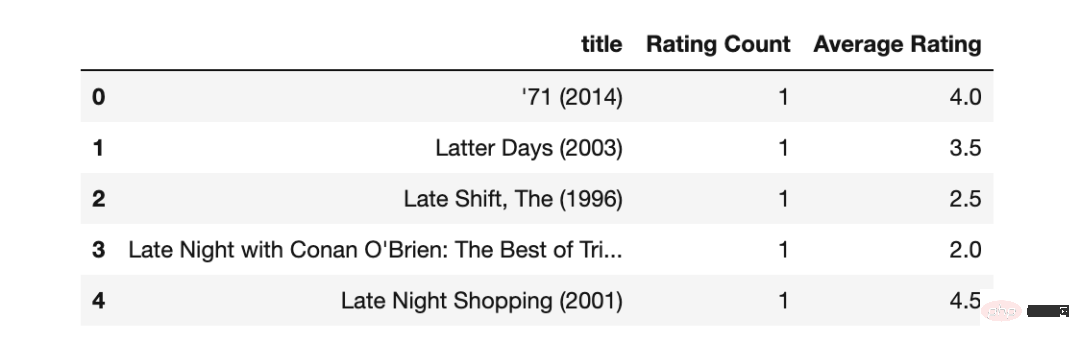
# 导入可视化库
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(font_scale = 1)
plt.rcParams["axes.grid"] = False
plt.style.use('dark_background')
%matplotlib inline
# 绘制图形
plt.figure(figsize=(12,4))
plt.hist(movies_rating_count_avg['Rating Count'],bins=80,color='tab:purple')
plt.ylabel('Ratings Count(Scaled)', fontsize=16)
plt.savefig('ratingcounthist.jpg')
plt.figure(figsize=(12,4))
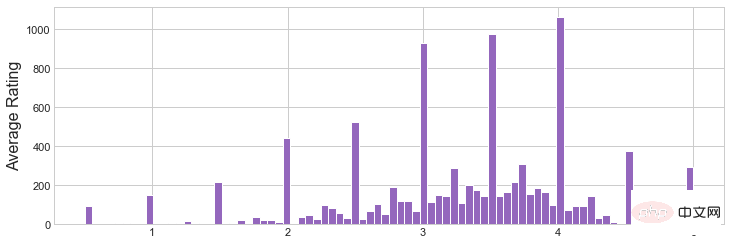
plt.hist(movies_rating_count_avg['Average Rating'],bins=80,color='tab:purple')
plt.ylabel('Average Rating',fontsize=16)
plt.savefig('avgratinghist.jpg')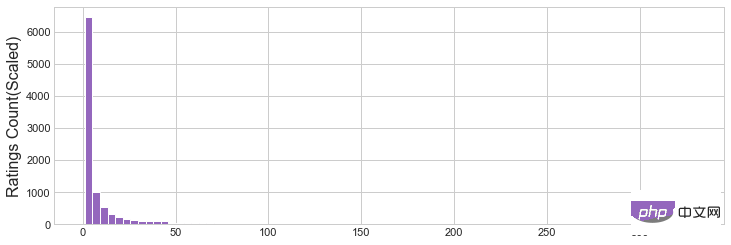
圖1 Average Rating直方圖
現在建立一個joinplot二維圖表,將這兩個特徵一起視覺化。
plot=sns.jointplot(x='Average Rating',
y='Rating Count',
data=movies_rating_count_avg,
alpha=0.5,
color='tab:pink')
plot.savefig('joinplot.jpg')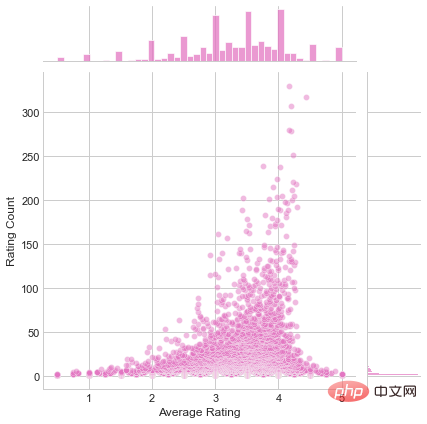
# 运用describe()函数得到数据集的描述统计值,如分位数和标准差等。 设置阈值并筛选出高于阈值的数据。 至此已经通过过滤掉了评论低于阈值的电影来清洗数据。 创建一个以用户为索引、以电影为列的数据透视表 为了稍后将数据加载到模型中,需要创建一个数据透视表。并设置'title'作为索引,'userId'为列,'rating'为值。 接下来将创建的数据透视表加载到模型。 建立 kNN 模型并输出与每部电影相似的 5 个推荐 使用scipy.sparse模块中的csr_matrix方法,将数据透视表转换为用于拟合模型的数组矩阵。 最后,使用之前生成的矩阵数据,来训练来自sklearn中的NearestNeighbors算法。并设置参数:metric = 'cosine', algorithm = 'brute'分析
数据清洗
pd.set_option('display.float_format', lambda x: '%.3f' % x)
print(rating_with_RatingCount['Rating Count'].describe())count 100836.000
mean58.759
std 61.965
min1.000
25% 13.000
50% 39.000
75% 84.000
max329.000
Name: Rating Count, dtype: float64
popularity_threshold = 50
popular_movies= rating_with_RatingCount[
rating_with_RatingCount['Rating Count']>=popularity_threshold]
popular_movies.head()
# popular_movies.shape
创建数据透视表
import os
movie_features_df=popular_movies.pivot_table(
index='title',columns='userId',values='rating').fillna(0)
movie_features_df.head()
movie_features_df.to_excel('output.xlsx')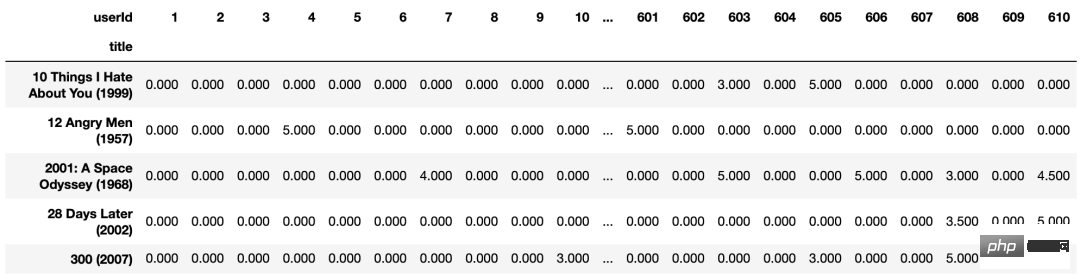
建立 kNN 模型
from scipy.sparse import csr_matrix
movie_features_df_matrix = csr_matrix(movie_features_df.values)
from sklearn.neighbors import NearestNeighbors model_knn = NearestNeighbors(metric = 'cosine', algorithm = 'brute') model_knn.fit(movie_features_df_matrix)
现在向模型传递一个索引,根据'kneighbors'算法要求,需要将数据转换为单行数组,并设置n_neighbors的值。
query_index = np.random.choice(movie_features_df.shape[0]) distances, indices = model_knn.kneighbors(movie_features_df.iloc[query_index,:].values.reshape(1, -1), n_neighbors = 6)
最后在 query_index 中输出出电影推荐。
for i in range(0, len(distances.flatten())):
if i == 0:
print('Recommendations for {0}:n'
.format(movie_features_df.index[query_index]))
else:
print('{0}: {1}, with distance of {2}:'
.format(i, movie_features_df.index[indices.flatten()[i]],
distances.flatten()[i]))Recommendations for Harry Potter and the Order of the Phoenix (2007): 1: Harry Potter and the Half-Blood Prince (2009), with distance of 0.2346513867378235: 2: Harry Potter and the Order of the Phoenix (2007), with distance of 0.3396233320236206: 3: Harry Potter and the Goblet of Fire (2005), with distance of 0.4170845150947571: 4: Harry Potter and the Prisoner of Azkaban (2004), with distance of 0.4499547481536865: 5: Harry Potter and the Chamber of Secrets (2002), with distance of 0.4506162405014038:
至此我们已经能够成功构建了一个仅基于用户评分的推荐引擎。
以下是我们构建电影推荐系统的步骤摘要:
以下是可以扩展项目的一些方法:
以上是使用Python建構電影推薦系統的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















