
譯者| 朱先忠
審校| 孫淑娟

#紅葡萄園(作者:Vincent van Gogh)
#根據《紐約時報》報道,資料中心90%的能源被浪費,這是因為公司收集的大部分資料從未被分析或以任何形式使用。更具體地說,這被稱為「暗資料(Dark Data)」。
「暗數據」是指透過各種電腦網路操作所獲得的數據,但不以任何方式用於得出見解或進行決策。組織收集資料的能力可能超過其分析資料的吞吐量。在某些情況下,組織甚至可能不知道正在收集資料。 IBM估計,大約90%的感測器和類比數位轉換產生的資料從未被使用。 ——維基百科上的「暗資料」定義
從機器學習的角度來看,這些資料對於得出任何見解都沒有用處的關鍵原因之一是缺乏標籤。這使得無監督學習演算法對於挖掘這些數據的潛力非常有吸引力。
2014年,Ian Goodfello等人提出了一種透過對抗過程估計生成模型的新方法。它涉及同時訓練兩個獨立的模型:一個生成器模型試圖建模資料分佈,另一個鑑別器試圖透過生成器將輸入分類為訓練資料或假資料。
這篇論文在現代機器學習領域樹立了一個非常重要的里程碑,為無監督學習開闢了新的途徑。 2015年,深度卷積Radford等人發布的GAN論文透過應用卷積網路的原理成功地產生了2D圖像,從而繼續建構了論文中的這一想法。
透過本文,我試圖解釋上述論文中論述的關鍵組件,並使用PyTorch框架來實現它們。
為了理解GAN或DCGAN(深度卷積生成對抗網絡:Deep Convolutional Generative Adversarial Networks)的重要性,首先讓我們來了解一下是什麼使它們如此流行。
1. 由於大部分真實資料未標記,GAN的無監督學習特性使其非常適合此類用例。
2. 產生器和鑑別器對於具有有限標記資料的用例起到非常好的特徵提取器的作用,或者產生附加資料以改進二次模型訓練,因為它們可以產生假樣本而不是使用增強技術。
3. GANs提供了最大似然技術的替代方法。它們的對抗性學習過程和非啟發式成本函數使得它們對強化學習非常有吸引力。
4. 關於GAN的研究非常有吸引力,其結果引起了關於ML/DL影響的廣泛爭論。例如,Deepfake是GAN的一種應用,它可以將人的臉部覆蓋在目標人身上,這在本質上是非常有爭議的,因為它有可能被用於邪惡的目的。
5. 最後一點也是最重要的一點是,使用這個網路很酷,該領域的所有新研究都令人著迷。
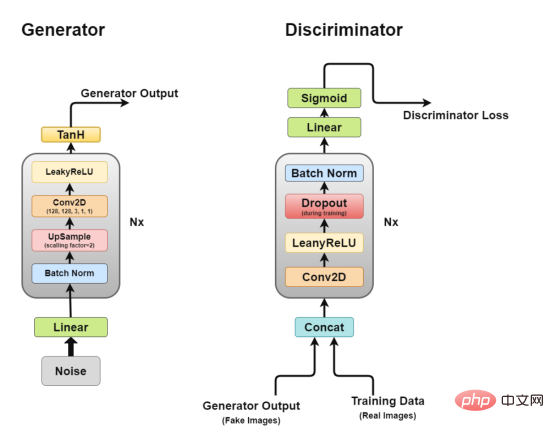
深度卷積GAN的架構
正如我們前面所討論的,我們將透過DCGAN進行工作,DCGAN試圖實現GAN的核心思想,用於生成逼真圖像的捲積網路。
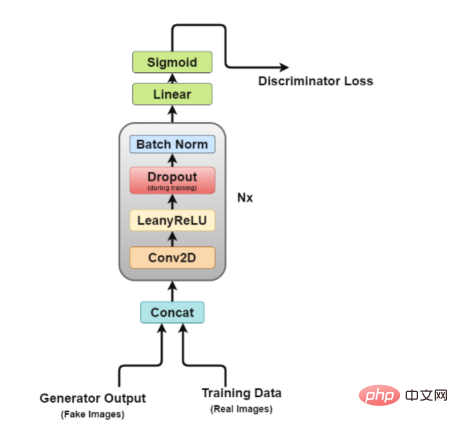
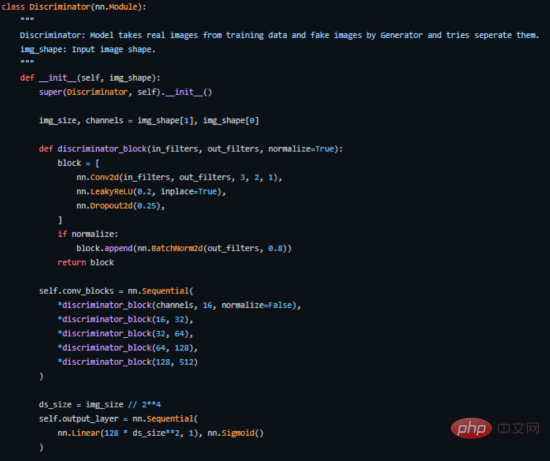
DCGAN由兩個獨立的模型組成:一個生成器(G)嘗試將隨機雜訊向量建模為輸入並嘗試學習資料分佈以產生假樣本,另一個鑑別器(D)獲取訓練數據(真實樣本)和產生的數據(假樣本),並嘗試對它們進行分類。這兩種模式之間的鬥爭就是我們所謂的對抗性訓練過程,一方的損失是另一方的利益。
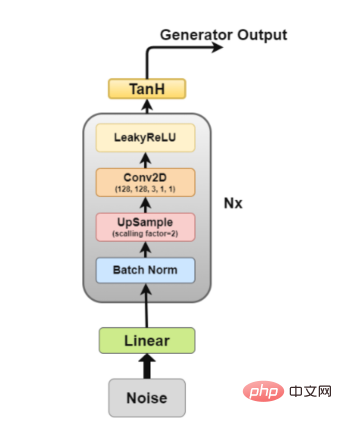
#生成器架構圖
#生成器是我們最感興趣的部分,因為它是一個生成假圖像以試圖欺騙鑑別器的生成器。
現在,讓我們更詳細地了解生成器的架構。
其中,層2至層5構成核心生成器區塊,可以重複N次以獲得所需的輸出影像形狀。
以下是我們如何在PyTorch中實現它的關鍵程式碼(完整原始碼請參閱位址https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py)。
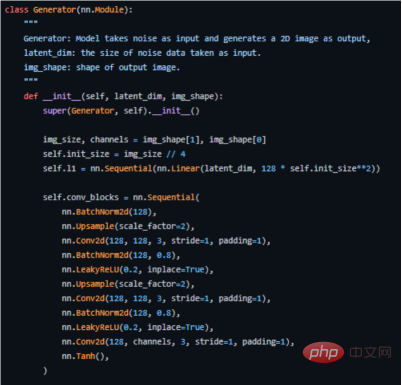
使用PyTorch框架的產生器實作關鍵程式碼
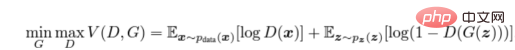
在實際應用環境中,上述方程式可能無法為G提供足夠的梯度來很好地學習。在學習的早期,當G較差時,D可以以高置信度拒絕樣本,因為它們與訓練資料明顯不同。在這種情況下,log(1 − D(G(z)))函數達到飽和。我們不是訓練G以最小化log(1 − D(G(z))),而是訓練G以最大化logD(G(z))。此目標函數能夠產生動態G和D的相同的固定點,但在學習早期卻提供了更強的梯度計算。 ——arxiv論文
由於我們同時訓練兩個模型,這可能會很棘手,而GAN是出了名的難以訓練,我們將在後面討論的已知問題之一稱為模式崩潰(mode collapse)。
論文建議使用學習率為0.0002的Adam最佳化器,如此低的學習率表示GAN傾向於非常快速地發散。它還使用值為0.5和0.999的一階和二階動量來進一步加速訓練。模型初始化為常態加權分佈,平均值為零,標準差為0.02。
下面展示的是我們如何為此實現一個訓練循環(完整原始碼請參閱https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py)。
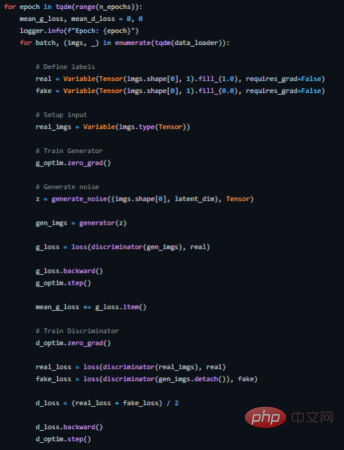
DCGAN的訓練循環
理想情況下,我們希望生成器產生各種輸出。例如,如果它產生人臉,它應該為每個隨機輸入產生一個新的人臉。但是,如果發生器產生足夠好的似是而非的輸出從而能夠欺騙鑑別器的話,它可能會一次又一次地產生相同的輸出。
最終,生成器會對單一鑑別器進行過度最佳化,並在一小組輸出結果之間旋轉(rotate),這種情況稱為「模式崩潰」。
以下方法可用來修正該情況。
總之,本文上面提到的有關GAN和DCGAN的論文簡直稱的上是一篇里程碑式的論文,因為它在無監督學習方面開闢了一條新的途徑。其中提出的對抗式訓練方法為訓練模型提供了一種新的方法,該模型緊密模擬真實世界的學習過程。因此,了解這個領域是如何發展的將是一件非常有趣的事情。
最後,您可以在我的GitHub原始碼倉庫上找到本文範例工程完整的實作原始碼。
朱先忠,51CTO社群編輯,濰坊一所大學電腦教師,自由程式設計界老兵一枚。
原文標題:Implementing Deep Convolutional GAN,作者:Akash Agnihotri
#以上是深度卷積生成對抗網路實戰的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















