

一行字實現3D換臉! UC伯克利提出'Chat-NeRF”,說句話完成大片級渲染

由於神經3D重建技術的發展,捕捉真實世界3D場景的特徵表示從未如此簡單。
然而,在此之上的3D場景編輯卻一直未能有一個簡單有效的方案。
最近,來自UC柏克萊的研究人員基於先前的工作InstructPix2Pix,提出了一種使用文字指令編輯NeRF場景的方法-Instruct-NeRF2NeRF。

論文網址:https://arxiv.org/abs/2303.12789
#利用Instruct-NeRF2NeRF,我們只需一句話,就能編輯大規模的現實世界場景,並且比以前的工作更真實、更有針對性。
例如,想要他有鬍子,臉上就會出現一簇鬍子!

或直接換頭,秒變成愛因斯坦。

此外,由於模型能持續使用新的編輯過的影像更新資料集,所以場景的重建效果也會逐步改善。
NeRF InstructPix2Pix = Instruct-NeRF2NeRF
具體來說,人類需要給定輸入圖像,以及告訴模型要做什麼的書面指令,隨後模型就會遵循這些指令來編輯圖像。
實作步驟如下:
- 在訓練視角下從場景中渲染出一張影像。
- 使用InstructPix2Pix模型根據全域文字指令對該圖像進行編輯。
- 以編輯後的影像取代訓練資料集中的原始影像。
- NeRF模型依照平常繼續進行訓練。

#實作方法
相較於傳統的三維編輯,NeRF2NeRF是一種新的三維場景編輯方法,其最大的亮點在於採用了「迭代資料集更新」技術。
雖然是在3D場景上進行編輯,但論文中使用2D而不是3D擴散模型來提取形式和外觀先驗,因為用於訓練3D生成模型的數據非常有限。
這個2D擴散模型,就是研究團隊不久前開發的InstructPix2Pix-一款基於指令文字的2D影像編輯模型,輸入影像與文字指令,它就能輸出編輯後的圖像。
然而,這種2D模型會導致場景不同角度的變化不均勻,因此,「迭代資料集更新」應運而生,該技術交替修改NeRF的「輸入圖片數據集」,並更新基礎3D表徵。
這意味著文字引導擴散模型(InstructPix2Pix)將根據指令產生新的圖像變化,並將這些新圖像用作NeRF模型訓練的輸入。因此,重建的三維場景將基於新的文字引導編輯。
在初始迭代中,InstructPix2Pix通常無法在不同視角下執行一致的編輯,然而,在NeRF重新渲染和更新的過程中,它們將會收斂於一個全局一致的場景。
總結而言,NeRF2NeRF方法透過迭代地更新影像內容,並將這些更新後的內容整合到三維場景中,從而提高了3D場景的編輯效率,也保持了場景的連貫性和真實性。

可以說,UC伯克利研究團隊的此項工作是先前InstructPix2Pix的延伸版,透過將NeRF與InstructPix2Pix結合,再配合「迭代資料集更新」,一鍵編輯照樣玩3D場景!
仍有局限,但瑕不掩瑜
不過,由於Instruct-NeRF2NeRF是基於先前的InstructPix2Pix,因此繼承了後者的諸多局限,例如無法進行大規模空間操作。
此外,與DreamFusion一樣,Instruct-NeRF2NeRF一次只能在一個視圖上使用擴散模型,所以也可能會遇到類似的偽影問題。
下圖展示了兩種類型的失敗案例:
#(1)Pix2Pix無法在2D中執行編輯,因此NeRF2NeRF在3D中也失敗了;
(2)Pix2Pix在2D中可以完成編輯,但在3D中存在很大的不一致性,因此NeRF2NeRF也沒能成功。

再例如下面這隻「熊貓」,不僅看起來非常凶悍(作為原型的雕像就很兇) ,而且毛色多少也有些詭異,眼睛在畫面移動時也有明顯的「穿模」。

自從ChatGPT,Diffusion, NeRFs被拉進聚光燈之下,這篇文章可謂充分發揮了三者的優勢,從「AI一句話作圖」進階到了「AI一句話編輯3D場景」。
儘管方法存在一些局限性,但仍瑕不掩瑜,為三維特徵編輯給出了一個簡單可行的方案,有望成為NeRF發展的里程碑之作。
一句話編輯3D場景
最後,再看一波作者放出的效果。
不難看出,這款一鍵PS的3D場景編輯神器,不論是指令理解能力,還是圖像真實程度,都比較符合預期,未來也許會成為學術界和網友們把玩的「新寵」,繼ChatGPT後打造出一個Chat-NeRFs。


#即便是隨意改變影像的環境背景、四季特徵、天氣,給出的新圖像也完全符合現實邏輯。
原圖:

#秋天:

雪天:

沙漠:

#########暴風雨:#######

參考資料:#https://www .php.cn/link/ebeb300882677f350ea818c8f333f5b9
#以上是一行字實現3D換臉! UC伯克利提出'Chat-NeRF”,說句話完成大片級渲染的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
寫在前面&筆者的個人理解三維Gaussiansplatting(3DGS)是近年來在顯式輻射場和電腦圖形學領域出現的一種變革性技術。這種創新方法的特點是使用了數百萬個3D高斯,這與神經輻射場(NeRF)方法有很大的不同,後者主要使用隱式的基於座標的模型將空間座標映射到像素值。 3DGS憑藉其明確的場景表示和可微分的渲染演算法,不僅保證了即時渲染能力,而且引入了前所未有的控制和場景編輯水平。這將3DGS定位為下一代3D重建和表示的潛在遊戲規則改變者。為此我們首次系統性地概述了3DGS領域的最新發展與關
 您的T-mobile智慧型手機上的5G UC與5G UW圖示的意思是什麼?
Feb 24, 2024 pm 06:10 PM
您的T-mobile智慧型手機上的5G UC與5G UW圖示的意思是什麼?
Feb 24, 2024 pm 06:10 PM
T-Mobile用戶已經開始注意到,他們的手機螢幕上的網路圖示有時顯示為5GUC,而其他業者則顯示為5GUW。這並不是拼字錯誤,而是代表不同類型的5G網路。事實上,營運商們正在不斷擴大他們的5G網路覆蓋範圍。在這個主題中,我們將探討T-Mobile智慧型手機上顯示的5GUC和5GUW圖示的意思。這兩種標誌代表著不同的5G技術,每種技術都有其獨特的特點和優點。透過了解這些標誌的含義,使用者可以更了解他們所連接的5G網路類型,以便選擇最適合自己需求的網路服務。 5GUCVS5GUW圖示在T
 了解 Microsoft Teams 中的 3D Fluent 表情符號
Apr 24, 2023 pm 10:28 PM
了解 Microsoft Teams 中的 3D Fluent 表情符號
Apr 24, 2023 pm 10:28 PM
您一定記得,尤其是如果您是Teams用戶,Microsoft在其以工作為重點的視訊會議應用程式中添加了一批新的3DFluent表情符號。在微軟去年宣佈為Teams和Windows提供3D表情符號之後,該過程實際上已經為該平台更新了1800多個現有表情符號。這個宏偉的想法和為Teams推出的3DFluent表情符號更新首先是透過官方部落格文章進行宣傳的。最新的Teams更新為應用程式帶來了FluentEmojis微軟表示,更新後的1800表情符號將為我們每天
 選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
0.寫在前面&&個人理解自動駕駛系統依賴先進的感知、決策和控制技術,透過使用各種感測器(如相機、光達、雷達等)來感知周圍環境,並利用演算法和模型進行即時分析和決策。這使得車輛能夠識別道路標誌、檢測和追蹤其他車輛、預測行人行為等,從而安全地操作和適應複雜的交通環境。這項技術目前引起了廣泛的關注,並認為是未來交通領域的重要發展領域之一。但是,讓自動駕駛變得困難的是弄清楚如何讓汽車了解周圍發生的事情。這需要自動駕駛系統中的三維物體偵測演算法可以準確地感知和描述周圍環境中的物體,包括它們的位置、
 CLIP-BEVFormer:明確監督BEVFormer結構,提升長尾偵測性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:明確監督BEVFormer結構,提升長尾偵測性能
Mar 26, 2024 pm 12:41 PM
寫在前面&筆者的個人理解目前,在整個自動駕駛系統當中,感知模組扮演了其中至關重要的角色,行駛在道路上的自動駕駛車輛只有通過感知模組獲得到準確的感知結果後,才能讓自動駕駛系統中的下游規控模組做出及時、正確的判斷和行為決策。目前,具備自動駕駛功能的汽車中通常會配備包括環視相機感測器、光達感測器以及毫米波雷達感測器在內的多種數據資訊感測器來收集不同模態的信息,用於實現準確的感知任務。基於純視覺的BEV感知演算法因其較低的硬體成本和易於部署的特點,以及其輸出結果能便捷地應用於各種下游任務,因此受到工業
 Windows 11中的Paint 3D:下載、安裝和使用指南
Apr 26, 2023 am 11:28 AM
Windows 11中的Paint 3D:下載、安裝和使用指南
Apr 26, 2023 am 11:28 AM
當八卦開始傳播新的Windows11正在開發中時,每個微軟用戶都對新作業系統的外觀以及它將帶來什麼感到好奇。經過猜測,Windows11就在這裡。作業系統帶有新的設計和功能變更。除了一些添加之外,它還附帶功能棄用和刪除。 Windows11中不存在的功能之一是Paint3D。雖然它仍然提供經典的Paint,它對抽屜,塗鴉者和塗鴉者有好處,但它放棄了Paint3D,它提供了額外的功能,非常適合3D創作者。如果您正在尋找一些額外的功能,我們建議AutodeskMaya作為最好的3D設計軟體。如
 單卡30秒跑出虛擬3D老婆! Text to 3D產生看清毛孔細節的高精度數字人,無縫銜接Maya、Unity等製作工具
May 23, 2023 pm 02:34 PM
單卡30秒跑出虛擬3D老婆! Text to 3D產生看清毛孔細節的高精度數字人,無縫銜接Maya、Unity等製作工具
May 23, 2023 pm 02:34 PM
ChatGPT為AI產業注入一劑雞血,一切曾經的不敢想,都成為現今的基操。正持續進擊的Text-to-3D,就被視為繼Diffusion(影像)和GPT(文字)後,AIGC領域的下一個前緣熱點,得到了前所未有的關注。這不,一款名為ChatAvatar的產品低調公測,火速收攬超70萬瀏覽與關注,並登上抱抱臉週熱門(Spacesoftheweek)。 △ChatAvatar也將支援從AI生成的單視角/多視角原畫生成3D風格化角色的Imageto3D技術,受到了廣泛關注現行beta版本生成的3D模型,
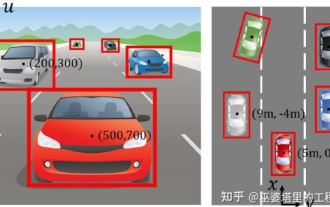 自動駕駛3D視覺感知演算法深度解讀
Jun 02, 2023 pm 03:42 PM
自動駕駛3D視覺感知演算法深度解讀
Jun 02, 2023 pm 03:42 PM
對於自動駕駛應用程式來說,最終還是需要對3D場景進行感知。道理很簡單,車輛不能靠著一張影像上得到感知結果來行駛,就算是人類駕駛也不能對著一張影像來開車。因為物體的距離和場景的和深度資訊在2D感知結果上是體現在現在的,而這些資訊才是自動駕駛系統對周圍環境做出正確判斷的關鍵。一般來說,自動駕駛車輛的視覺感應器(例如攝影機)安裝在車身上方或車內後視鏡上。無論哪個位置,攝影機所得到的都是真實世界在透視視圖(PerspectiveView)下的投影(世界座標係到影像座標系)。這種視圖與人類的視覺系統很類似,
