

使用OpenAI的Whisper 模型進行語音識別

語音辨識是人工智慧中的一個領域,它允許電腦理解人類語音並將其轉換為文字。該技術用於 Alexa 和各種聊天機器人應用程式等設備。而我們最常見的就是語音轉錄,語音轉錄可以語音轉換成文字記錄或字幕。

wav2vec2、Conformer 和 Hubert 等最先進模型的最新發展極大地推動了語音辨識領域的發展。這些模型採用無需人工標記資料即可從原始音訊中學習的技術,使它們能夠有效地使用未標記語音的大型資料集。它們也被擴展為使用多達1,000,000 小時的訓練數據,遠遠超過學術監督數據集中使用的傳統1,000 小時,但是以監督方式跨多個數據集和領域預訓練的模型已被發現表現出更好的穩健性和對持有資料集的泛化,所以執行語音辨識等任務仍然需要微調,這限制了它們的全部潛力。為了解決這個問題OpenAI 發展了 Whisper,一種利用弱監督方法的模型。
本文將說明用於訓練的資料集的種類以及模型的訓練方法,以及如何使用Whisper
Whisper 模型介紹
使用資料集:
Whisper模型是在68萬小時標記音訊資料的資料集上訓練的,其中包括11.7萬小時96種不同語言的演講和12.5萬小時從」任意語言「到英語的翻譯資料。該模型利用了互聯網生成的文本,這些文本是由其他自動語音識別系統(ASR)生成而不是人類創建的。該資料集還包括一個在VoxLingua107上訓練的語言偵測器,這是從YouTube影片中提取的短語音片段的集合,並根據影片標題和描述的語言進行標記,並帶有額外的步驟來去除誤報。
模型:
主要採用的結構是編碼器-解碼器結構。
重採樣:16000 Hz
特徵擷取方法:使用25毫秒的視窗和10毫秒的步幅計算80通道的log Mel譜圖表示。
特徵歸一化:輸入在全域內縮放到-1到1之間,並且在預訓練資料集上具有近似為零的平均值。
編碼器/解碼器:此模型的編碼器和解碼器採用Transformers。
編碼器的過程:
編碼器首先使用一個包含兩個卷積層(濾波器寬度為3)的詞幹處理輸入表示,並使用GELU啟動函數。
第二個卷積層的步幅為 2。
然後將正弦位置嵌入新增到詞幹的輸出中,然後套用編碼器 Transformer 區塊。
Transformers使用預先啟動殘差塊,編碼器的輸出使用歸一化層進行歸一化。
模型框圖:

解碼的過程:
在解碼器中,使用了學習位置嵌入和綁定輸入輸出標記表示。
編碼器和解碼器具有相同的寬度和數量的Transformers區塊。
訓練
為了改進模型的縮放屬性,它在不同的輸入大小上進行了訓練。
透過 FP16、動態損失縮放,並採用資料並行來訓練模型。
使用AdamW和梯度範數裁剪,在對前 2048 次更新進行預熱後,線性學習率衰減為零。
使用 256 個批次大小,並訓練模型進行 220次更新,這相當於對資料集進行兩到三次前向傳遞。
由於模型只訓練了幾個輪次,過度擬合不是一個重要問題,並且沒有使用資料增強或正規化技術。這反而可以依靠大型資料集內的多樣性來促進泛化和魯棒性。
Whisper 在先前使用過的資料集上展示了良好的準確性,並且已經針對其他最先進的模型進行了測試。
優點:
- Whisper 已經在真實資料以及其他模型上使用的資料以及弱監督下進行了訓練。
- 模型的準確性針對人類聽眾進行了測試並評估其表現。
- 它能夠偵測清音區域並應用 NLP 技術在轉錄本中正確進行標點符號的輸入。
- 模型是可擴展的,允許從音訊訊號中提取轉錄本,而無需將視訊分成區塊或批次,從而降低了漏音的風險。
- 模型在各種資料集上取得了更高的準確率。
Whisper在不同資料集上的比較結果,相較於wav2vec取得了目前最低的字錯誤率

模型沒有在timit資料集上進行測試,所以為了檢查它的單字錯誤率,我們將在這裡示範如何使用Whisper來自行驗證timit資料集,也就是說使用Whisper來建立我們自己的語音辨識應用。
使用Whisper 模型進行語音辨識
TIMIT 閱讀語音語料庫是語音資料的集合,它專門用於聲學語音研究以及自動語音辨識系統的開發和評估。它包括來自美國英語八種主要方言的 630 位演講者的錄音,每人朗讀十個語音豐富的句子。語料庫包括時間對齊的拼字、語音和單字轉錄以及每個語音的 16 位元、16kHz 語音波形檔案。該語料庫由麻省理工學院 (MIT)、SRI International (SRI) 和德州儀器 (TI) 共同開發。 TIMIT 語料庫轉錄已手動驗證,並指定了測試和訓練子集,以平衡語音和方言覆蓋範圍。
安裝:
!pip install git+https://github.com/openai/whisper.git !pip install jiwer !pip install datasets==1.18.3
第一條指令將安裝whisper模型所需的所有相依性。 jiwer是用來下載文字錯誤率包的datasets是hugface提供的資料集包,可以下載timit資料集。
導入庫
import whisper from pytube import YouTube from glob import glob import os import pandas as pd from tqdm.notebook import tqdm
載入timit資料集
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")計算不同模型尺寸下的Word錯誤率
考慮到過濾英文資料和非英文數據的需求,我們在這裡選擇使用多語言模型,而不是專門為英語設計的模型。
但是TIMIT資料集是純英文的,所以我們要應用相同的語言偵測和辨識過程。另外就是TIMIT資料集已經分割好訓練和驗證集,我們可以直接使用。
要使用Whisper,我們就要先了解不同模型的參數,大小和速度。

載入模型
model = whisper.load_model('tiny')tiny可以替換為上面提到的模型名稱。
定義語言偵測器的函數
def lan_detector(audio_file):
print('reading the audio file')
audio = whisper.load_audio(audio_file)
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
if max(probs, key=probs.get) == 'en':
return True
return False轉換語音到文字的函數
def speech2text(audio_file): text = model.transcribe(audio_file) return text["text"]
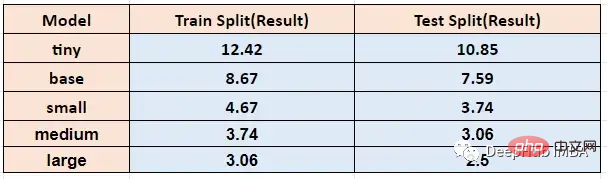
在不同模型大小下運行上面的函數,timit訓練和測試得到的單字錯誤率如下:
從u2b轉錄語音
#與其他語音辨識模型相比,Whisper 不僅能辨識語音,還能解讀一個人語音中的標點語調,並插入適當的標點符號,我們下面使用u2b的影片進行測試。
這裡就需要一個套件pytube,它可以輕鬆的幫助我們下載和提取音訊
def youtube_audio(link):
youtube_1 = YouTube(link)
videos = youtube_1.streams.filter(only_audio=True)
name = str(link.split('=')[-1])
out_file = videos[0].download(name)
link = name.split('=')[-1]
new_filename = link+".wav"
print(new_filename)
os.rename(out_file, new_filename)
print(name)
return new_filename,link獲得wav檔案後,我們就可以應用上面的函數從中提取文字。
總結
本文的程式碼在這裡
https://drive.google.com/file/d/1FejhGseX_S1Ig_Y5nIPn1OcHN8DLFGIO/view
還有許多操作可以用Whisper完成,你可以依照本文的程式碼自行嘗試。
以上是使用OpenAI的Whisper 模型進行語音識別的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 位元組跳動剪映推出 SVIP 超級會員:連續包年 499 元,提供多種 AI 功能
Jun 28, 2024 am 03:51 AM
位元組跳動剪映推出 SVIP 超級會員:連續包年 499 元,提供多種 AI 功能
Jun 28, 2024 am 03:51 AM
本站6月27日訊息,剪映是由位元組跳動旗下臉萌科技開發的一款影片剪輯軟體,依託於抖音平台且基本面向該平台用戶製作短影片內容,並相容於iOS、安卓、Windows 、MacOS等作業系統。剪映官方宣布會員體系升級,推出全新SVIP,包含多種AI黑科技,例如智慧翻譯、智慧劃重點、智慧包裝、數位人合成等。價格方面,剪映SVIP月費79元,年費599元(本站註:折合每月49.9元),連續包月則為59元每月,連續包年為499元每年(折合每月41.6元) 。此外,剪映官方也表示,為提升用戶體驗,向已訂閱了原版VIP
 使用Rag和Sem-Rag提供上下文增強AI編碼助手
Jun 10, 2024 am 11:08 AM
使用Rag和Sem-Rag提供上下文增強AI編碼助手
Jun 10, 2024 am 11:08 AM
透過將檢索增強生成和語意記憶納入AI編碼助手,提升開發人員的生產力、效率和準確性。譯自EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG,作者JanakiramMSV。雖然基本AI程式設計助理自然有幫助,但由於依賴對軟體語言和編寫軟體最常見模式的整體理解,因此常常無法提供最相關和正確的程式碼建議。這些編碼助手產生的代碼適合解決他們負責解決的問題,但通常不符合各個團隊的編碼標準、慣例和風格。這通常會導致需要修改或完善其建議,以便將程式碼接受到應
 微調真的能讓LLM學到新東西嗎:引入新知識可能讓模型產生更多的幻覺
Jun 11, 2024 pm 03:57 PM
微調真的能讓LLM學到新東西嗎:引入新知識可能讓模型產生更多的幻覺
Jun 11, 2024 pm 03:57 PM
大型語言模型(LLM)是在龐大的文字資料庫上訓練的,在那裡它們獲得了大量的實際知識。這些知識嵌入到它們的參數中,然後可以在需要時使用。這些模型的知識在訓練結束時被「具體化」。在預訓練結束時,模型實際上停止學習。對模型進行對齊或進行指令調優,讓模型學習如何充分利用這些知識,以及如何更自然地回應使用者的問題。但是有時模型知識是不夠的,儘管模型可以透過RAG存取外部內容,但透過微調使用模型適應新的領域被認為是有益的。這種微調是使用人工標註者或其他llm創建的輸入進行的,模型會遇到額外的實際知識並將其整合
 七個很酷的GenAI & LLM技術性面試問題
Jun 07, 2024 am 10:06 AM
七個很酷的GenAI & LLM技術性面試問題
Jun 07, 2024 am 10:06 AM
想了解更多AIGC的內容,請造訪:51CTOAI.x社群https://www.51cto.com/aigc/譯者|晶顏審校|重樓不同於網路上隨處可見的傳統問題庫,這些問題需要跳脫常規思維。大語言模型(LLM)在數據科學、生成式人工智慧(GenAI)和人工智慧領域越來越重要。這些複雜的演算法提升了人類的技能,並在許多產業中推動了效率和創新性的提升,成為企業保持競爭力的關鍵。 LLM的應用範圍非常廣泛,它可以用於自然語言處理、文字生成、語音辨識和推薦系統等領域。透過學習大量的數據,LLM能夠產生文本
 為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
編輯|ScienceAI問答(QA)資料集在推動自然語言處理(NLP)研究中發揮著至關重要的作用。高品質QA資料集不僅可以用於微調模型,也可以有效評估大語言模型(LLM)的能力,尤其是針對科學知識的理解和推理能力。儘管目前已有許多科學QA數據集,涵蓋了醫學、化學、生物等領域,但這些數據集仍有一些不足之處。其一,資料形式較為單一,大多數為多項選擇題(multiple-choicequestions),它們易於進行評估,但限制了模型的答案選擇範圍,無法充分測試模型的科學問題解答能力。相比之下,開放式問答
 你所不知道的機器學習五大學派
Jun 05, 2024 pm 08:51 PM
你所不知道的機器學習五大學派
Jun 05, 2024 pm 08:51 PM
機器學習是人工智慧的重要分支,它賦予電腦從數據中學習的能力,並能夠在無需明確編程的情況下改進自身能力。機器學習在各個領域都有廣泛的應用,從影像辨識和自然語言處理到推薦系統和詐欺偵測,它正在改變我們的生活方式。機器學習領域存在著多種不同的方法和理論,其中最具影響力的五種方法被稱為「機器學習五大派」。這五大派分別為符號派、聯結派、進化派、貝葉斯派和類推學派。 1.符號學派符號學(Symbolism),又稱符號主義,強調利用符號進行邏輯推理和表達知識。該學派認為學習是一種逆向演繹的過程,透過現有的
 SOTA性能,廈大多模態蛋白質-配體親和力預測AI方法,首次結合分子表面訊息
Jul 17, 2024 pm 06:37 PM
SOTA性能,廈大多模態蛋白質-配體親和力預測AI方法,首次結合分子表面訊息
Jul 17, 2024 pm 06:37 PM
編輯|KX在藥物研發領域,準確有效地預測蛋白質與配體的結合親和力對於藥物篩選和優化至關重要。然而,目前的研究並沒有考慮到分子表面訊息在蛋白質-配體相互作用中的重要作用。基於此,來自廈門大學的研究人員提出了一種新穎的多模態特徵提取(MFE)框架,該框架首次結合了蛋白質表面、3D結構和序列的信息,並使用交叉注意機制進行不同模態之間的特徵對齊。實驗結果表明,該方法在預測蛋白質-配體結合親和力方面取得了最先進的性能。此外,消融研究證明了該框架內蛋白質表面資訊和多模態特徵對齊的有效性和必要性。相關研究以「S
 佈局 AI 等市場,格芯收購泰戈爾科技氮化鎵技術和相關團隊
Jul 15, 2024 pm 12:21 PM
佈局 AI 等市場,格芯收購泰戈爾科技氮化鎵技術和相關團隊
Jul 15, 2024 pm 12:21 PM
本站7月5日消息,格芯(GlobalFoundries)於今年7月1日發布新聞稿,宣布收購泰戈爾科技(TagoreTechnology)的功率氮化鎵(GaN)技術及智慧財產權組合,希望在汽車、物聯網和人工智慧資料中心應用領域探索更高的效率和更好的效能。隨著生成式人工智慧(GenerativeAI)等技術在數位世界的不斷發展,氮化鎵(GaN)已成為永續高效電源管理(尤其是在資料中心)的關鍵解決方案。本站引述官方公告內容,在本次收購過程中,泰戈爾科技公司工程師團隊將加入格芯,進一步開發氮化鎵技術。 G
