

18張圖直觀理解神經網路、流形和拓樸

迄今,人們對神經網路的一大疑慮是,它是個難以解釋的黑盒子。本文則主要從理論上理解為什麼神經網路對模式辨識、分類效果這麼好,其本質是透過一層層仿射變換和非線性變換把原始輸入做扭曲和變形,直到可以非常容易被區分出不同的類別。實際上,反向傳播演算法(BP) 其實就是根據訓練資料不斷微調這個扭曲的效果。
大約十年前開 始, 深 度 神經 網路 在計算 機視覺等領域取得了突破性成果,引起了極大的興趣與關注。
然而,仍有一些人對此表示憂慮。原因之一是,神經網路是一個黑盒子:如果神經網路訓練得很好,可以獲得高品質的結果,但很難理解它的工作原理。如果神經網路故障,也很難找出問題所在。
雖然要整體理解深層神經網絡很難,但可以從低維深層神經網絡入手,也就是每層只有幾個神經元的網絡,它們理解起來要容易得多。我們可以透過視覺化方法來理解低維度深層神經網路的行為和訓練。視覺化方法能讓我們更直觀地了解神經網路的行為,並觀察到神經網路和 拓樸 學之間的連結。
接下來我會談及許多有趣的事情,包括能夠對特定資料集進行分類的神經網路的複雜性下限。
1、一個簡單的例子
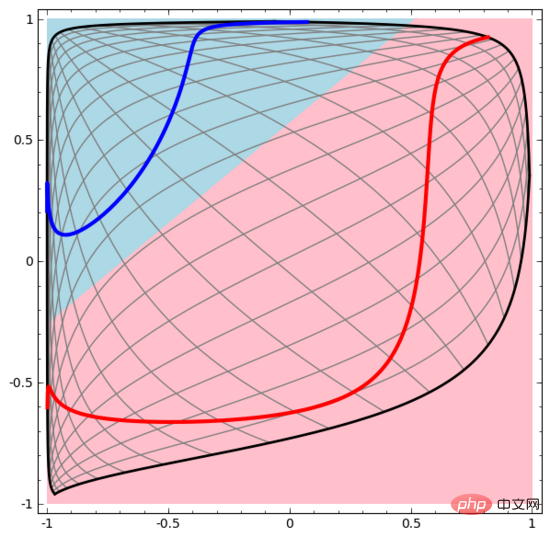
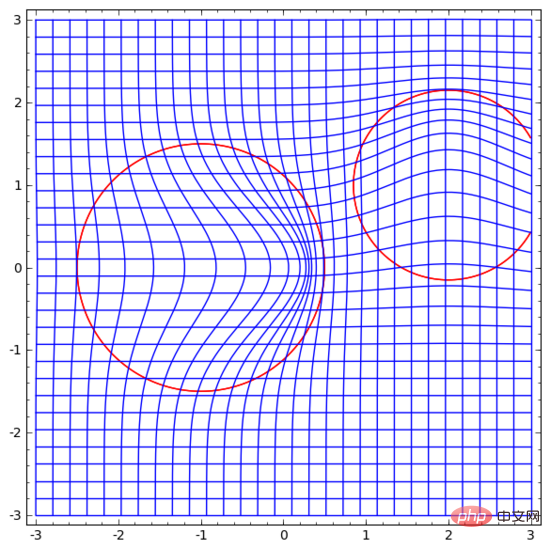
讓我們從一個非常簡單的資料集開始。下圖中,平面上的兩條曲線由無數的點組成。神經網路將試著區分這些點分別屬於哪一條線。
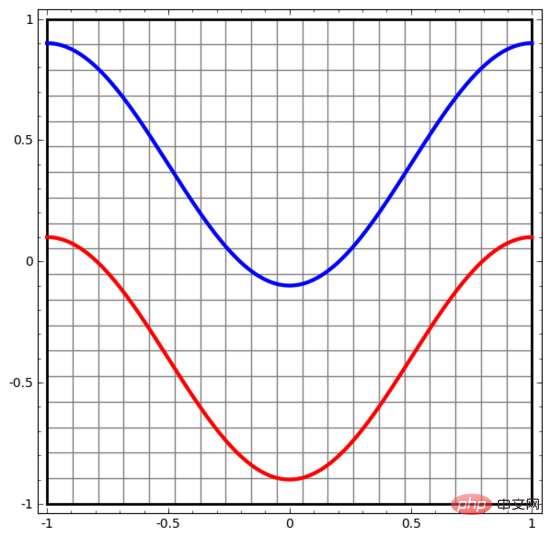
要觀察神經網路(或任何分類演算法)的行為,最直接的方法就是看看它是如何對每個資料點進行分類的。
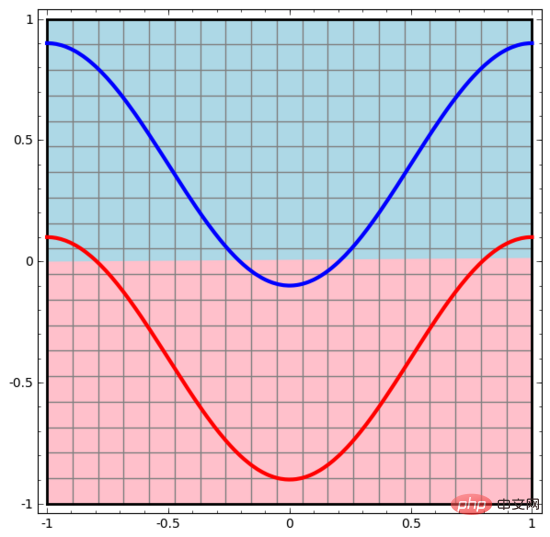
我們從最簡單的神經網路開始觀察,它只有一個輸入層和一個輸出層。這樣的神經網路只是用一條直線將兩類數據點分開。
這樣的神經網路太簡單粗暴了。現代神經網路通常在輸入層和輸出層之間有多個層,稱為隱藏層。再簡單的現代神經網路起碼有一個隱藏層。
一個簡單的神經網絡,圖源維基百科
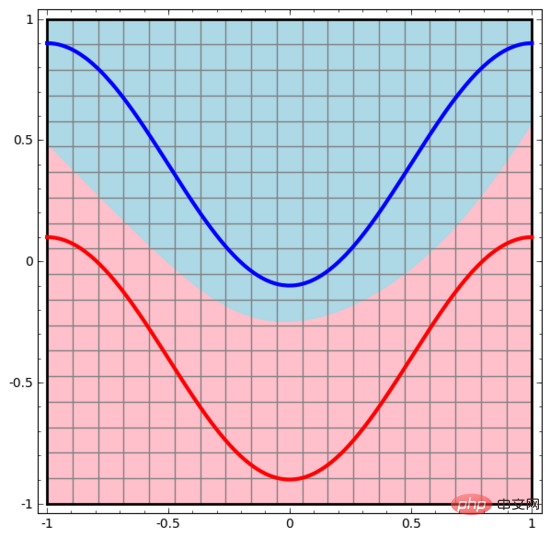
#同樣地,我們觀察神經網路對每個資料點所做的操作。可見,這個神經網路用一條曲線而不是直線來分離資料點。顯然,曲線比直線更複雜。
神經網路的每一層都會用一個新的表示形式來表示資料。我們可以觀察資料如何轉化成新的表示形式以及神經網路如何對它們進行分類。在最後一層的表示形式中,神經網路會在兩類資料之間畫一條線來區分(如果在更高的維度中,就會畫一個超平面)。
在前面的視覺化圖形中,我們看到了資料的原始表示形式。你可以把它視為資料在「輸入層」的樣子。現在我們來看看資料被轉換之後的樣子,你可以把它視為資料在「隱藏層」中的樣子。
資料的每一個維度都對應神經網路層中一個神經元的活化。
隱藏層用如上方法表示數據,使數據可以被一條直線分離 (即線性可分)
2、層的連續視覺化
在上一節的方法中,神經網路的每一層都以不同表示形式來表示資料。這樣一來,每層的表示形式之間是離散的,並不連續。
這就對我們的理解造成困難,從一種表示形式到另一種表示形式,中間是如何轉換的呢?好在,神經網路層的特性讓這方面的理解變得非常容易。
神經網路中有各種不同的層。下面我們將以tanh層作為具體例子來討論。一個tanh層 ,包括:
- 用「權重」矩陣W 作線性變換
- 用向量b 作平移
- 用tanh 逐點表示
我們可以將其視為一個連續的轉換,如下所示:
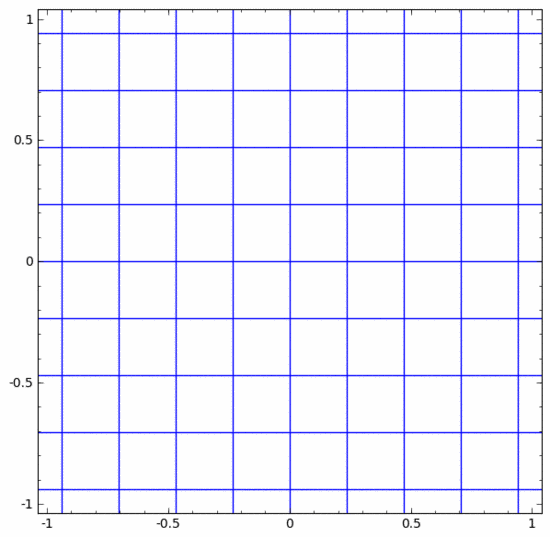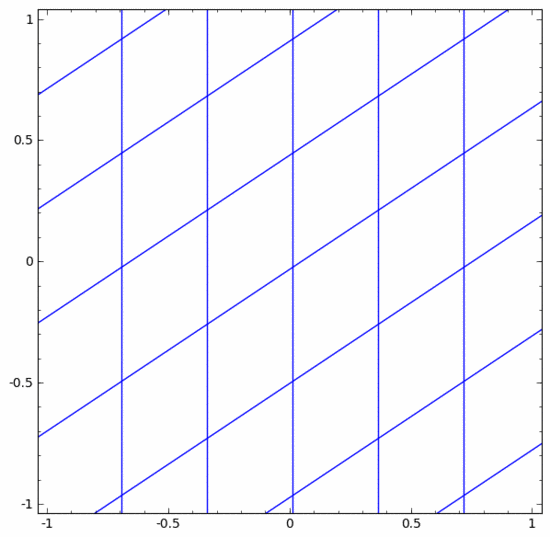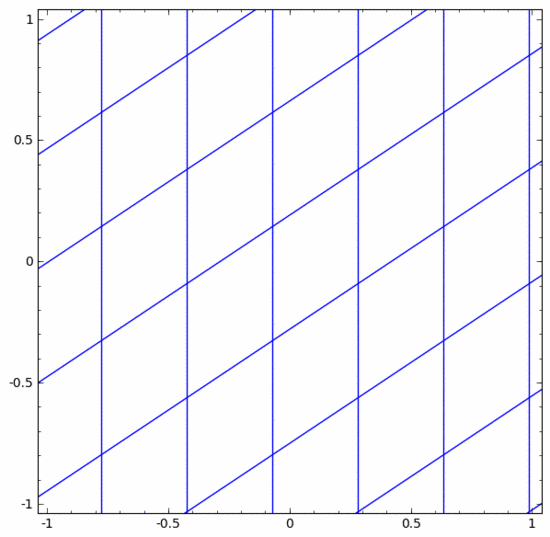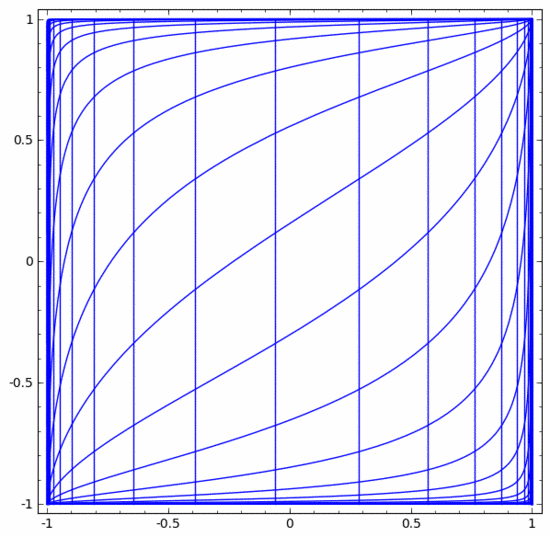
其他標準層的情況大致相同,由仿射變換和單調激活函數的逐點應用組成。
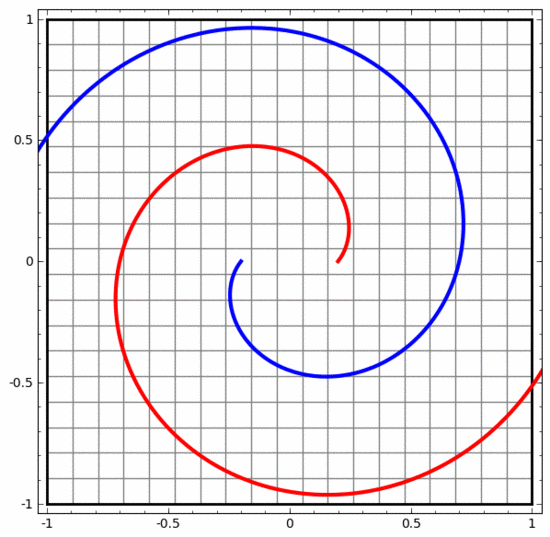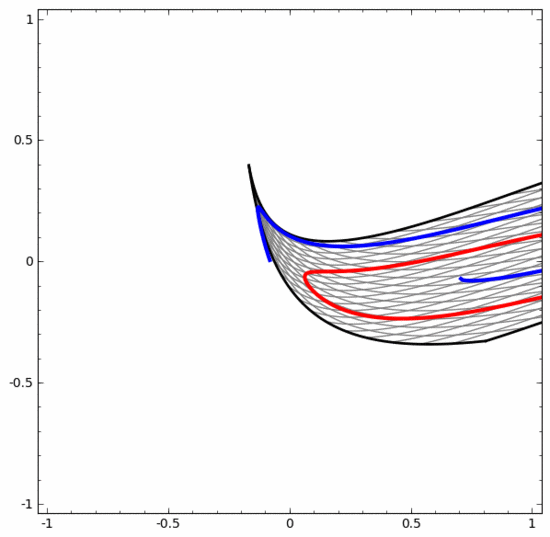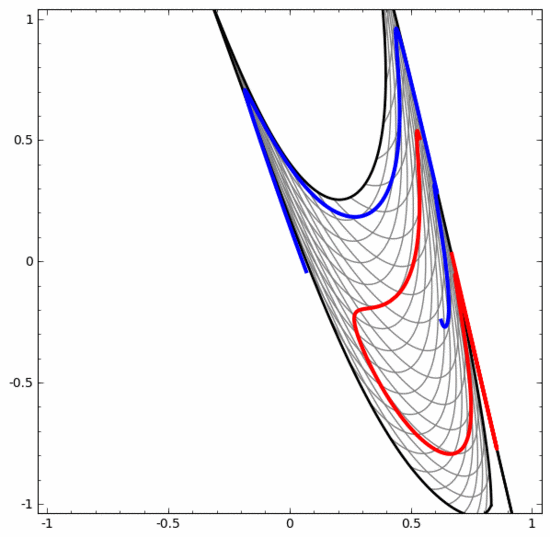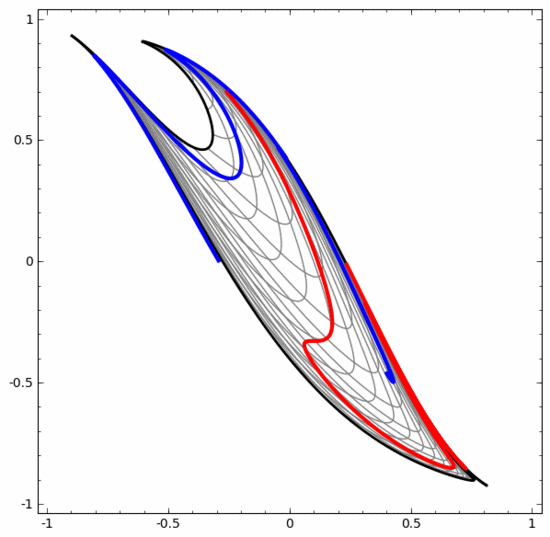
我們可以用這個方法來理解更複雜的神經網路。例如,下面的神經網路使用四個隱藏層對兩條略有互纏的螺旋線進行分類。可以看到,為了將資料分類,資料的表示方式被不斷轉換。兩條螺旋線最初是糾纏在一起的,但到最後它們可以被一條直線分離(線性可分)。
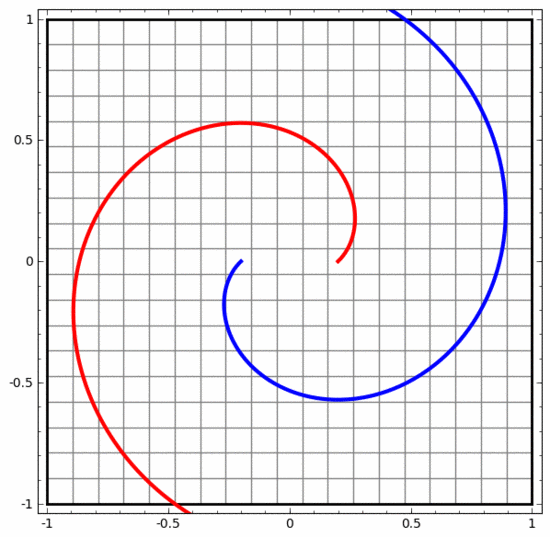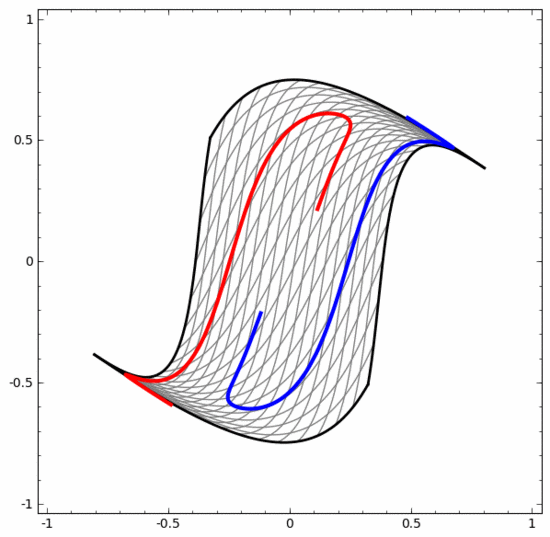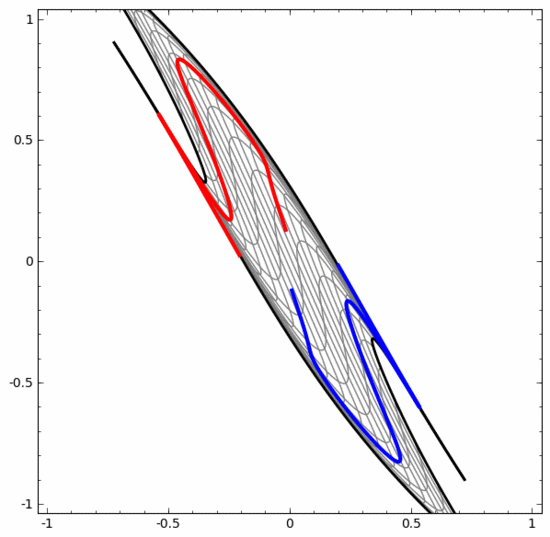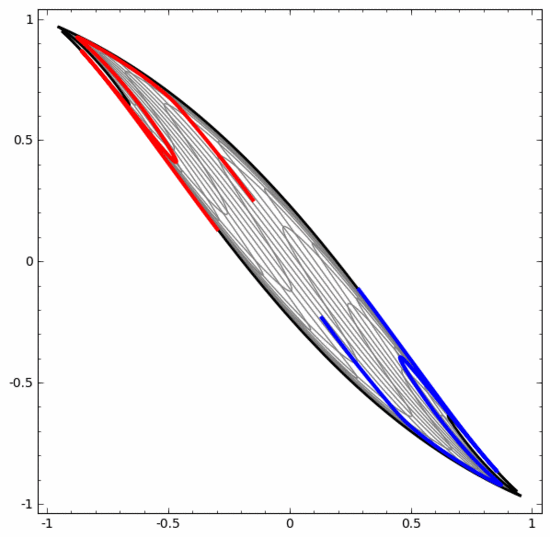
另一方面,下面的神經網絡,雖然也使用多個隱藏層,卻無法劃分兩條互纏程度更深的螺旋線。
要明確指出的是,以上兩個螺旋線分類任務有一些挑戰,因為我們現在使用的只是低維度神經網路。如果我們使用寬度更大的神經網絡,一切都會很容易很多。
(Andrej Karpathy基於ConvnetJS製作了一個很好的demo,讓人們可以透過這種可視化的訓練互動式地探索神經網路。)
3、tanh層的拓撲
神經網路的每一層都會拉伸和擠壓空間,但它不會剪切、割裂或折疊空間。直觀上看,神經網路不會破壞資料的拓撲性質。例如,如果一組資料是連續的,那麼它被轉換表示形式之後也是連續的(反之亦然)。
像這樣不影響拓樸性質的變換稱為同胚(homeomorphisms)。形式上,它們是雙向連續函數的雙射。
定理 :如果權重矩陣W 是非奇異的(non-singular),而神經網路的一層有N個輸入和N個輸出,那麼這層的映射是同胚(對於特定的定義域和值域而言)。
證明 :讓我們一步一步來:
1. 假設 W 存在非零行列式。那麼它就是一個具有線性逆的雙射線性函數。線性函數是連續的。那麼「乘以W 」這樣的變換就是同胚;
2. 「平移」變換是同胚;
3. tanh(還有s igmoid和softplus,但不包括ReLU )是具有連續逆(continuous inverses)的 連續函數。 (對於特定的定義域和值域而言),它們就是雙射,對它們的逐點應用就是同胚。
因此,如果 W 存在一個非零行列式,這一個神經網路層就是同胚。
如果我們將這樣的層隨意組合在一起,這個結果仍然成立。
4、拓樸與分類
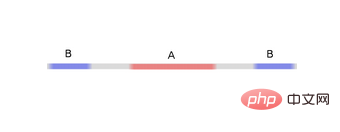
我們來看一個二維資料集,它包含兩類資料A和B:

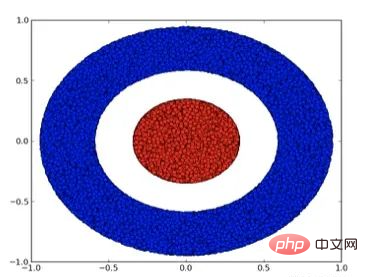
#A是紅色,B是藍色
說明 :要將這個資料集分類,神經網路(不管深度如何)必須有一個包含3個或更多隱藏單元的層。
如前所述,使用sigmoid單元或softmax層進行分類,相當於在最後一層的表示形式中找到一個超平面(在本例中則是直線)來分隔 A 和 B。如果只有兩個隱藏單元,神經網路在拓撲上就無法以這種方式分離數據,也就無法對上述數據集進行分類。
在下面的視覺化中,隱藏層轉換對資料的表示形式,直線為分割線。可見,分割線不斷旋轉、移動,卻始終無法很好地分隔A和B兩類資料。
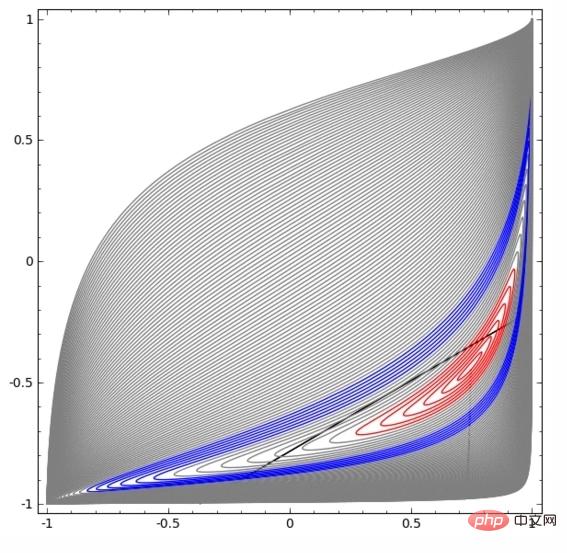
這樣的神經網路再怎麼訓練也無法很好地完成分類任務
最後它只能勉強實現一個局部最小值,達到80%的分類精度。
上述範例只有一個隱藏層,由於只有兩個隱藏單元,所以無論如何它都會分類失敗。
證明 :如果只有兩個隱藏單元,要嘛這層的轉換是同胚,要嘛層的權重矩陣有行列式0。如果是同胚的話,A還是被B包圍,不能用一條直線把A和B分開。如果有行列式0,那麼資料集將在某個軸上發生折疊。因為A被B包圍,所以A在任何軸上折疊都會導致部分A數據點與B混合,致使無法區分A和B。
但如果我們加入第三個隱藏單元,問題就迎刃而解了。此時,神經網路可以將資料轉換成如下表示形式:
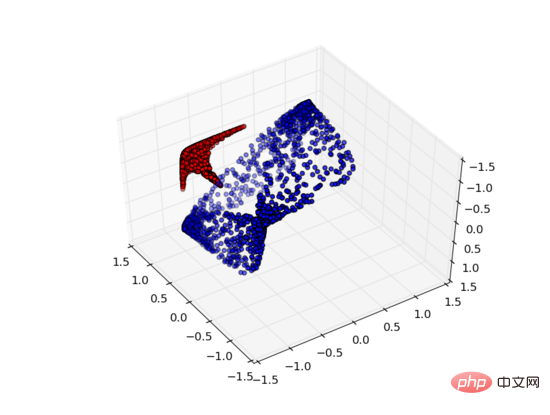
這時就可以用一個超平面來分隔A和B了。
為了更好地解釋其原理,這裡用一個更簡單的一維資料集舉例:
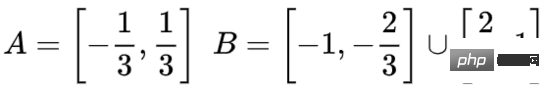
要對這個資料集進行分類,必須使用由兩個或更多隱藏單元組成的層。如果使用兩個隱藏單元,就可以用一條漂亮的曲線來表示數據,這樣就可以用一條直線來分隔A和B:
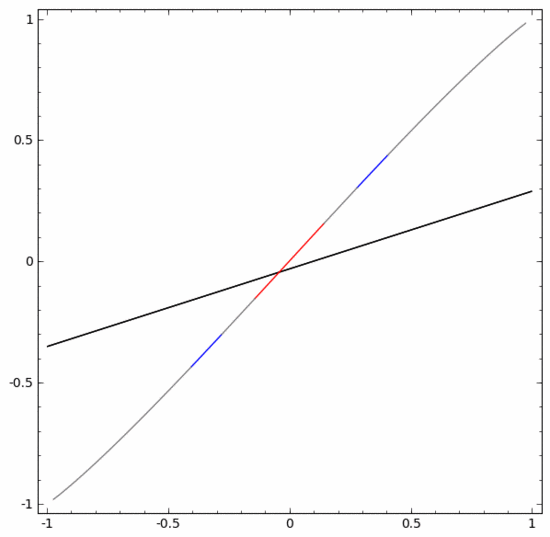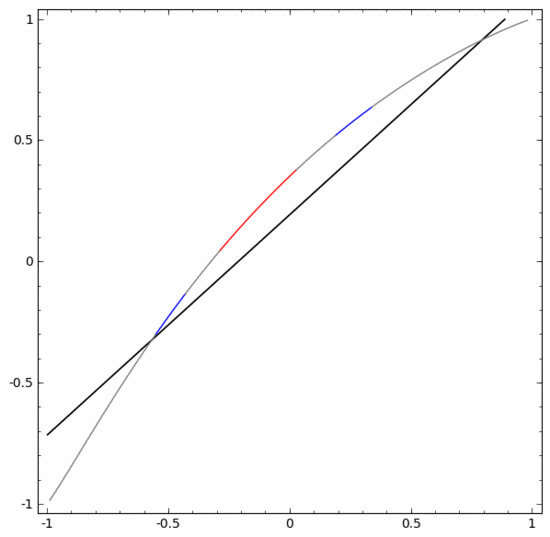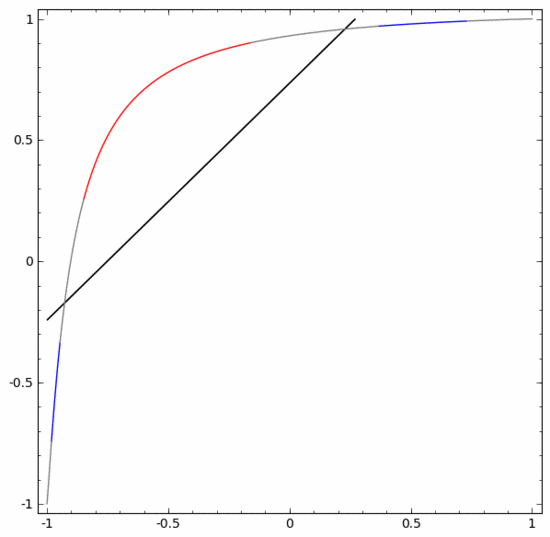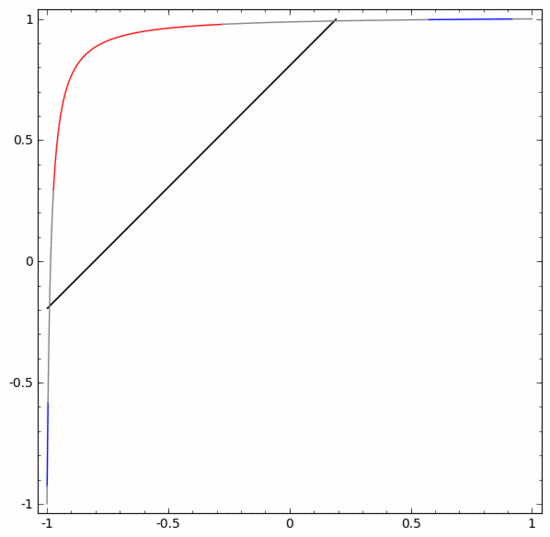
這是怎麼做的呢?當  時,其中一個隱藏單元被啟動;當
時,其中一個隱藏單元被啟動;當  時,另一個隱藏單元被啟動。當前一個隱藏單元被啟動而後一個隱藏單元未被啟動時,就可以判斷出這是屬於A的資料點。
時,另一個隱藏單元被啟動。當前一個隱藏單元被啟動而後一個隱藏單元未被啟動時,就可以判斷出這是屬於A的資料點。
5、流形假說
流形假說對處理真實世界的資料集(如影像資料)有意義嗎?我認為有意義。
流形假設是指自然資料在其嵌入空間中形成低維流形。這假設具備理論和實驗支撐。如果你相信流形假設,那麼分類演算法的任務就可以歸結為分離一組互相糾纏的流形。
在前面的範例中,一個類別完全包圍了另一個類別。然而,在真實世界的數據中,狗的圖像流形不太可能被貓的圖像流形完全包圍。但是,其他更合理的拓樸情況仍可能引發問題,下一節將會詳談。
6、連結與同倫
下面我將談談另一個有趣的資料集:兩個互相連結的圓環面(tori),A 和 B。

與我們之前談到的資料集情況類似,如果不使用n 1維度,就無法分離一個n維的資料集(n 1維度在本例中即為第4維度)。
連結問題屬於拓樸學中的紐結理論。有時候,我們看到一個鏈接,並不能立刻判斷它是否是一個斷鍊(unlink斷鍊的意思是,雖然它們互相糾纏,但可以通過連續變形將其分離)。
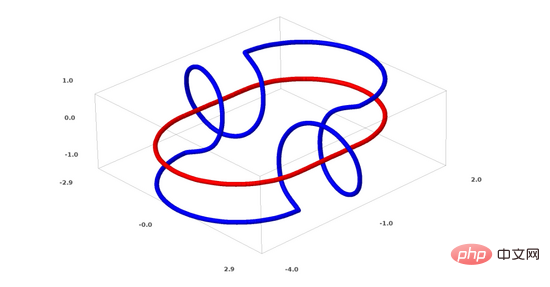
一個較簡單的斷鍊
如果隱藏層只有3個隱藏單元的神經網路可以對一個資料集進行分類,那麼這個資料集就是一個斷鍊(問題來了:從理論上講,所有斷鍊都可以被只有3個隱藏單元的神經網路分類嗎?)。
從紐結理論的角度來看,神經網路產生的資料表示形式的連續視覺化不僅僅是一個很好的動畫,也是一個解開連結的過程。在拓樸學中,我們稱之為原始連結和分離後的連結之間的環繞同痕(ambient isotopy)。
流形A和流形B之間的環繞同痕是一個連續函數:

#每個 是X的同胚。 是特徵函數, 將A映射到B。也就是說, 不斷從將A映射到自身過渡到將A映射到B。
定理 :如果同時滿足以下三個條件:(1)W為非奇異;(2)可以手動排列隱藏層中神經元的順序;(3)隱藏單元的數量大於1,那麼神經網路的輸入和神經網路層產生的表示形式之間有一個環繞同痕。
證明 :我們同樣一步一步來:
1. 最困難的部分是線性轉換。為了實現線性轉換,我們需要W有一個正行列式。我們的前提是行列式為非零,如果行列式為負,我們可以透過調換兩個隱藏神經元將其轉換為正。正行列式矩陣的空間是路徑連結的(path-connected),這就有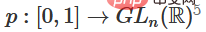 , 因此,
, 因此,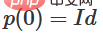 ,
,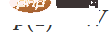 。透過函數
。透過函數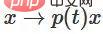 ,我們可以連續地將特徵函數過渡到W轉換,在時間t在每個點將x與連續過渡的矩陣 相乘。
,我們可以連續地將特徵函數過渡到W轉換,在時間t在每個點將x與連續過渡的矩陣 相乘。
2. 可以透過函數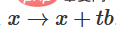 從特徵函數過渡到b平移。
從特徵函數過渡到b平移。
3. 可以透過函數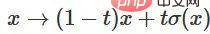 從特徵函數過渡到 的逐點應用。
從特徵函數過渡到 的逐點應用。
我猜可能有人會對下面這個問題感興趣:能不能研發出可自動發現這種環繞同痕 (ambient isotopy)的 程序,還能自動證明某些不同連結的等效性或某些連結的可分離性。我也想知道神經網路在這方面能不能打敗目前的SOTA技術。
雖然我們現在所談的連結形式很可能不會在現實世界的資料中出現,但現實的資料可能存在更高維度的泛化。
連結和紐結都是1維的流形,但需要4個維度才能將它們分開。同樣,要分離n維的流形,就需要更高維度的空間。所有的n維流形都可以用2n 2個維度分離。
7、一個簡單的方法
對於神經網路來說,最簡單的方法就是將互纏的流形直接拉開,而且將那些纏結在一起的部分拉得越細越好。雖然這不是我們追求的根本解決方案,但它可以實現相對較高的分類精度,達到相對理想的局部最小值。
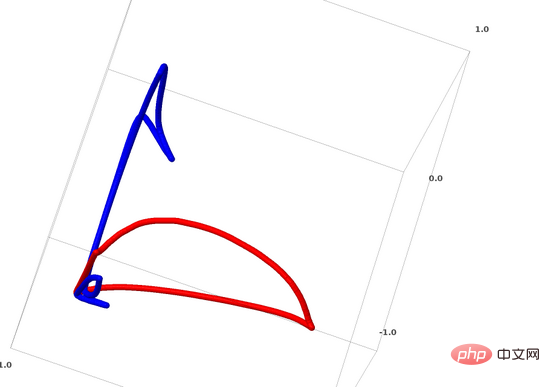
這種方法會導致試圖拉伸的區域出現非常高的導數。應對這一點需要採用收縮懲罰,也就是懲罰資料點的層的導數。
局部極小值對解決拓樸問題並無用處,不過拓樸問題或許可以為探索解決上述問題提供好的思路。
另一方面,如果我們只關心取得好的分類結果,那麼假如流形有一小部分與另一個流形互相纏繞,這對我們來說是個問題嗎?如果我們只在乎分類結果,那麼這似乎不成問題。
(我的直覺認為,像這樣走捷徑的方法並不好,容易走進死胡同。特別是,在最佳化問題中,尋求局部極小值並不能真正解決問題,而如果選擇一個無法真正解決問題的方案,就終將無法取得良好的效能。)
8、選取更適合操縱流形的神經網路層?
我認為標準的神經網路層不適合操縱流形,因為它們使用的是仿射變換和逐點激活函數。
或許我們可以使用一種完全不同的神經網路層?
我腦中浮現的一個想法是,首先,讓神經網路學習一個向量場,向量場的方向是我們想要移動流形的方向:
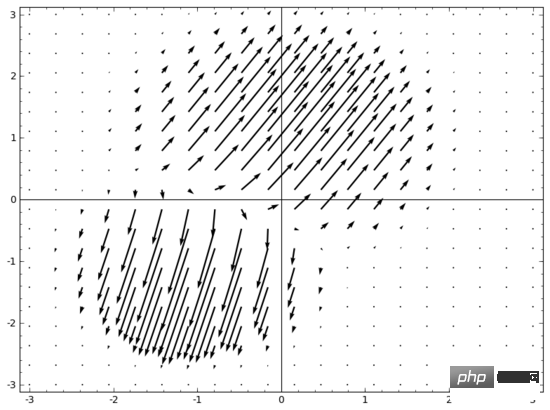
然後在此基礎上變形空間:
我們可以在固定點學習向量場(只需從訓練集中選取一些固定點作為錨),並以某種方式進行插值。上面的向量場的形式如下:
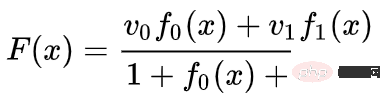
其中 和 是向量, 和 是n維高斯函數。這一想法受到徑向基底函數的啟發。
9、K-近鄰層
我的另一個觀點是,對神經網路而言,線性可分性可能是一個過高且不合理的要求,或許使用k近鄰(k-NN)會更好。然而,k-NN演算法很大程度上依賴數據的表示形式,因此,需要有良好的數據表示形式才能讓k-NN演算法取得好結果。
在第一個實驗中,我訓練了一些MNIST神經網路(兩層CNN,無dropout),錯誤率低於1%。然後,我丟棄了最後的softmax層,使用了k-NN演算法,多次結果顯示,錯誤率降低了0.1-0.2%。
不過,我覺得這種做法依然不對。神經網路仍在嘗試線性分類,只不過由於使用了k-NN演算法,所以能夠略微修正一些它所犯的錯誤,從而降低錯誤率。
由於(1/distance)的加權,k-NN對於它所作用的資料表示形式是可微的。因此,我們可以直接訓練神經網路進行k-NN分類。這可以視為一種「最近鄰」層,它的作用與softmax層類似。
我們不想為每個小批量回饋整個訓練集,因為這樣計算成本太高。我認為一個很好的方法是,根據小批量中其他元素的類別對小批量中的每個元素進行分類,給每個元素賦予(1/(與分類目標的距離))的權重。
遺憾的是,即使使用複雜的架構,使用k-NN演算法也只能把錯誤率降低到4-5%,而使用簡單的架構錯誤率則更高。不過,我並未在超參數方面下太多工夫。
但我還是很喜歡k-NN演算法,因為它比較適合神經網路。我們希望同一流形的點彼此更靠近,而不是執著於用超平面把流形分開。這相當於使單一流形收縮,同時使不同類別的流形之間的空間變大。這樣就把問題簡化了。
10、總結
資料的某些拓樸特性可能導致這些資料無法使用低維神經網路來進行線性分離(無論神經網路深度為何)。即使在技術可行的情況下,例如螺旋,使用低維神經網路也非常難以實現分離。
為了對資料進行精確分類,神經網路有時需要更寬的層。此外,傳統的神經網路層不適合操縱流形;即使人工設定權重,也很難得到理想的資料轉換表示形式。新的神經網路層或許能起到很好的輔助作用,特別是從流形角度理解機器學習啟發得出的新神經網路層。
以上是18張圖直觀理解神經網路、流形和拓樸的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 GNN的基礎、前沿和應用
Apr 11, 2023 pm 11:40 PM
GNN的基礎、前沿和應用
Apr 11, 2023 pm 11:40 PM
近年來,圖神經網路(GNN)取得了快速、令人難以置信的進展。圖神經網路又稱為圖深度學習、圖表徵學習(圖表示學習)或幾何深度學習,是機器學習特別是深度學習領域成長最快的研究主題。本次分享的題目為《GNN的基礎、前沿和應用》,主要介紹由吳凌飛、崔鵬、裴健、趙亮幾位學者牽頭編撰的綜合性書籍《圖神經網絡基礎、前沿與應用》中的大致內容。一、圖神經網路的介紹1、為什麼要研究圖?圖是一種描述和建模複雜系統的通用語言。圖本身並不複雜,它主要由邊和結點構成。我們可以用結點表示任何我們想要建模的物體,可以用邊表示兩
 YOLO不死! YOLOv9出爐:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
YOLO不死! YOLOv9出爐:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
如今的深度學習方法專注於設計最適合的目標函數,以使模型的預測結果與實際情況最接近。同時,必須設計一個合適的架構,以便為預測取得足夠的資訊。現有方法忽略了一個事實,當輸入資料經過逐層特徵提取和空間變換時,大量資訊將會遺失。本文將深入探討資料透過深度網路傳輸時的重要問題,即資訊瓶頸和可逆函數。基於此提出了可編程梯度資訊(PGI)的概念,以應對深度網路實現多目標所需的各種變化。 PGI可以為目標任務提供完整的輸入訊息,以計算目標函數,從而獲得可靠的梯度資訊以更新網路權重。此外設計了一種新的輕量級網路架
 一文通覽自動駕駛三大主流晶片架構
Apr 12, 2023 pm 12:07 PM
一文通覽自動駕駛三大主流晶片架構
Apr 12, 2023 pm 12:07 PM
目前主流的AI晶片主要分為三類,GPU、FPGA、ASIC。 GPU、FPGA皆是前期較成熟的晶片架構,屬於通用型晶片。 ASIC屬於為AI特定場景定制的晶片。業界已經確認CPU不適用於AI計算,但在AI應用領域也是不可或缺。 GPU方案GPU與CPU的架構比較CPU遵循的是馮諾依曼架構,其核心是儲存程式/資料、序列順序執行。因此CPU的架構中需要大量的空間去放置儲存單元(Cache)和控制單元(Control),相較之下運算單元(ALU)只佔據了很小的一部分,所以CPU在進行大規模平行運算
 'B站UP主成功打造全球首個基於紅石的神經網絡在社交媒體引起轟動,得到Yann LeCun的點贊讚賞'
May 07, 2023 pm 10:58 PM
'B站UP主成功打造全球首個基於紅石的神經網絡在社交媒體引起轟動,得到Yann LeCun的點贊讚賞'
May 07, 2023 pm 10:58 PM
在我的世界(Minecraft)中,紅石是一種非常重要的物品。它是遊戲中獨特的材料,開關、紅石火把和紅石塊等能對導線或物體提供類似電流的能量。紅石電路可以為你建造用於控製或激活其他機械的結構,其本身既可以被設計為用於響應玩家的手動激活,也可以反複輸出信號或者響應非玩家引發的變化,如生物移動、物品掉落、植物生長、日夜更替等等。因此,在我的世界中,紅石能夠控制的機械類別極其多,小到簡單機械如自動門、光開關和頻閃電源,大到佔地巨大的電梯、自動農場、小遊戲平台甚至遊戲內建的計算機。近日,B站UP主@
 扛住強風的無人機?加州理工用12分鐘飛行資料教會無人機禦風飛行
Apr 09, 2023 pm 11:51 PM
扛住強風的無人機?加州理工用12分鐘飛行資料教會無人機禦風飛行
Apr 09, 2023 pm 11:51 PM
當風大到可以把傘吹壞的程度,無人機卻穩穩噹噹,就像這樣:禦風飛行是空中飛行的一部分,從大的層面來講,當飛行員駕駛飛機著陸時,風速可能會給他們帶來挑戰;從小的層面來講,陣風也會影響無人機的飛行。目前來看,無人機要么在受控條件下飛行,無風;要么由人類使用遙控器操作。無人機被研究者控制在開闊的天空中編隊飛行,但這些飛行通常是在理想的條件和環境下進行的。然而,要讓無人機自主執行必要但日常的任務,例如運送包裹,無人機必須能夠即時適應風況。為了讓無人機在風中飛行時具有更好的機動性,來自加州理工學院的一組工
 多路徑多領域通吃! GoogleAI發布多領域學習通用模型MDL
May 28, 2023 pm 02:12 PM
多路徑多領域通吃! GoogleAI發布多領域學習通用模型MDL
May 28, 2023 pm 02:12 PM
面向視覺任務(如影像分類)的深度學習模型,通常使用單一視覺域(如自然影像或電腦生成的影像)的資料進行端到端的訓練。一般情況下,一個為多個領域完成視覺任務的應用程式需要為每個單獨的領域建立多個模型,分別獨立訓練,不同領域之間不共享數據,在推理時,每個模型將處理特定領域的輸入資料。即使是面向不同領域,這些模型之間的早期層的有些特徵都是相似的,所以,對這些模型進行聯合訓練的效率更高。這能減少延遲和功耗,降低儲存每個模型參數的記憶體成本,這種方法稱為多領域學習(MDL)。此外,MDL模型也可以優於單
 1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显著的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
 對比學習演算法在轉轉的實踐
Apr 11, 2023 pm 09:25 PM
對比學習演算法在轉轉的實踐
Apr 11, 2023 pm 09:25 PM
1 什麼是對比學習1.1 對比學習的定義1.2 對比學習的原理1.3 經典對比學習演算法系列2 對比學習的應用3 對比學習在轉轉的實踐3.1 CL在推薦召回的實踐3.2 CL在轉轉的未來規劃1什麼是對比學習1.1 對比學習的定義對比學習(Contrastive Learning, CL)是近年來AI 領域的熱門研究方向,吸引了眾多研究學者的關注,其所屬的自監督學習方式,更是在ICLR 2020 被Bengio和LeCun 等大佬點名稱為AI 的未來,後陸續登陸NIPS, ACL,
