

使用Python和OCR進行文件解析的完整程式碼演示(附程式碼)


文件解析涉及檢查文件中的資料並提取有用的信息。它可以透過自動化減少了大量的手動工作。一種流行的解析策略是將文件轉換為圖像並使用電腦視覺進行識別。而文件影像分析(Document Image Analysis)是指從文件的影像的像素資料中獲取資訊的技術,在某些情況下,預期結果應該是什麼樣的沒有明確的答案(文字、影像、圖表、數字、表格、公式…)。

OCR (Optical Character Recognition,光學字元辨識)是透過電腦視覺對影像中的文字進行偵測和擷取的過程。它是在第一次世界大戰期間發明的,當時以色列科學家伊曼紐爾·戈德堡(Emanuel Goldberg)發明了一台可以讀取字元並將其轉換為電報代碼的機器。到了現在該領域已經達到了一個非常複雜的水平,混合圖像處理、文字定位、字元分割和字元辨識。基本上是一種針對文字的物件偵測技術。
在本文中我將展示如何使用OCR進行文件解析。我將展示一些有用的Python程式碼,這些程式碼可以很容易地用於其他類似的情況(只需複製、貼上、運行),並提供完整的原始碼下載。
這裡將以一家上市公司的PDF格式的財務報表為例(連結如下)。
https://s2.q4cdn.com/470004039/files/doc_financials/2021/q4/_10-K-2021-(As-Filed).pdf

##偵測並擷取該PDF中的文字、圖形和表格
環境設定
文件解析令人煩惱的部分是,有太多的工具用於不同類型的資料(文字、圖形、表格),但沒有一個能夠完美地工作。以下是一些最受歡迎方法和軟體包:
- 以文本方式處理文件:用PyPDF2提取文本,用Camelot或TabulaPy提取表,用PyMuPDF提取圖形。
- 將文件轉換為圖像(OCR):使用pdf2image進行轉換,使用PyTesseract以及許多其他的庫提取數據,或只使用LayoutParser。
也許你會問:「為什麼不直接處理PDF文件,而要把頁面轉換成圖像呢?」你可以這麼做。這種策略的主要缺點是編碼問題:文件可以採用多種編碼(即UTF-8、ASCII、Unicode),因此轉換為文字可能會導致資料遺失。因此為了避免產生該問題,我將使用OCR,並用pdf2image將頁面轉換為圖像,需要注意的是PDF渲染庫Poppler是必要的。
# with pip pip install python-poppler # with conda conda install -c conda-forge poppler
你可以很容易地讀取檔案:
# READ AS IMAGE
import pdf2imagedoc = pdf2image.convert_from_path("doc_apple.pdf")
len(doc) #<-- check num pages
doc[0] #<-- visualize a page跟我們的截圖一模一樣,如果想將頁面圖像保存在本地,可以使用以下程式碼:
# Save imgs import osfolder = "doc" if folder not in os.listdir(): os.makedirs(folder)p = 1 for page in doc: image_name = "page_"+str(p)+".jpg" page.save(os.path.join(folder, image_name), "JPEG") p = p+1
最後,我們需要設定將要使用的CV引擎。 LayoutParser似乎是第一個基於深度學習的OCR通用包。它使用了兩個著名的模型來完成任務:
Detection: Facebook最先進的目標檢測庫(這裡將使用第二個版本Detectron2)。
pip install layoutparser torchvision && pip install "git+https://github.com/facebookresearch/detectron2.git@v0.5#egg=detectron2"
Tesseract:最著名的OCR系統,由惠普公司在1985年創建,目前由Google開發。
pip install "layoutparser[ocr]"
現在已經準備好開始OCR程式進行資訊偵測和擷取了。
import layoutparser as lp import cv2 import numpy as np import io import pandas as pd import matplotlib.pyplot as plt
偵測
(目標)偵測是在圖片中找到資訊片段,然後用矩形邊框將其包圍的過程。對於文件解析,這些資訊是標題、文字、圖形、表格…
讓我們來看一個複雜的頁面,它包含了一些東西:
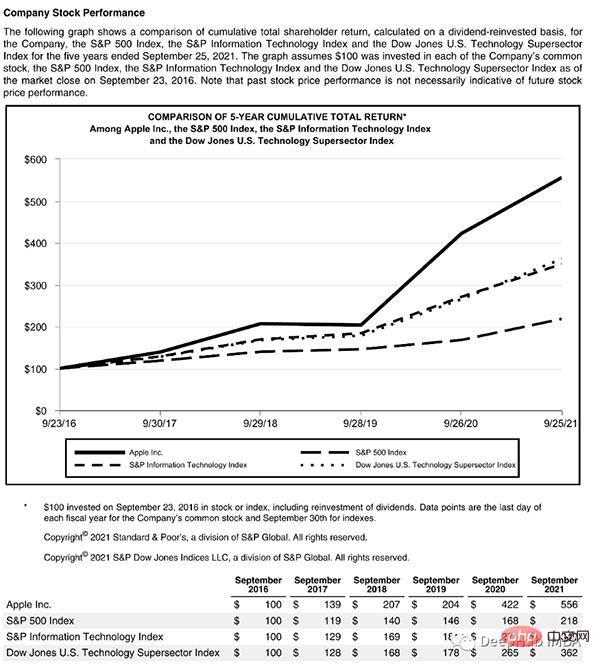
這個頁面以一個標題開始,有一個文字區塊,然後是一個圖表和一個表,因此我們需要一個經過訓練的模型來識別這些物件。幸運的是,Detectron能夠完成這項任務,我們只需從這裡選擇一個模型,並在程式碼中指定它的路徑。
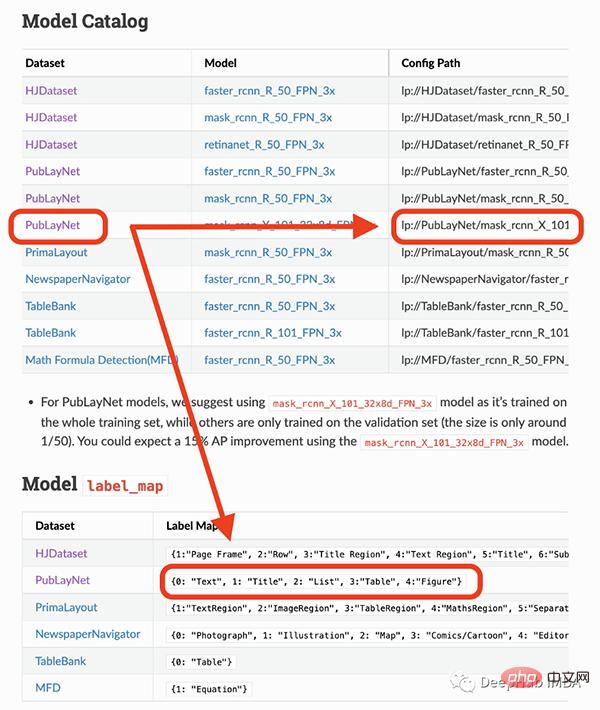
我將要使用的模型只能偵測4個物件(文字、標題、清單、表格、圖形)。因此,如果你需要辨識其他東西(如方程式),你就必須使用其他模型。
## load pre-trained model
model = lp.Detectron2LayoutModel(
"lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config",
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],
label_map={0:"Text", 1:"Title", 2:"List", 3:"Table", 4:"Figure"})
## turn img into array
i = 21
img = np.asarray(doc[i])
## predict
detected = model.detect(img)
## plot
lp.draw_box(img, detected, box_width=5, box_alpha=0.2,
show_element_type=True)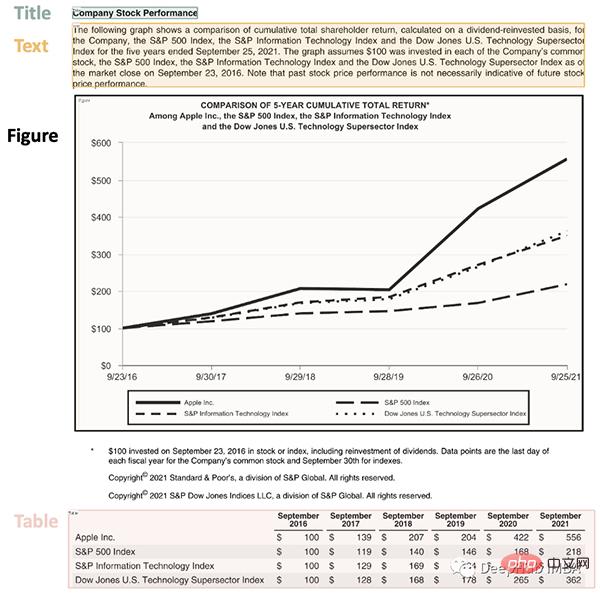
结果包含每个检测到的布局的细节,例如边界框的坐标。根据页面上显示的顺序对输出进行排序是很有用的:
## sort
new_detected = detected.sort(key=lambda x: x.coordinates[1])
## assign ids
detected = lp.Layout([block.set(id=idx) for idx,block in
enumerate(new_detected)])## check
for block in detected:
print("---", str(block.id)+":", block.type, "---")
print(block, end='nn')
完成OCR的下一步是正确提取检测到内容中的有用信息。
提取
我们已经对图像完成了分割,然后就需要使用另外一个模型处理分段的图像,并将提取的输出保存到字典中。
由于有不同类型的输出(文本,标题,图形,表格),所以这里准备了一个函数用来显示结果。
'''
{'0-Title': '...',
'1-Text': '...',
'2-Figure': array([[ [0,0,0], ...]]),
'3-Table': pd.DataFrame,
}
'''
def parse_doc(dic):
for k,v in dic.items():
if "Title" in k:
print('x1b[1;31m'+ v +'x1b[0m')
elif "Figure" in k:
plt.figure(figsize=(10,5))
plt.imshow(v)
plt.show()
else:
print(v)
print(" ")首先看看文字:
# load model
model = lp.TesseractAgent(languages='eng')
dic_predicted = {}
for block in [block for block in detected if block.type in ["Title","Text"]]:
## segmentation
segmented = block.pad(left=15, right=15, top=5,
bottom=5).crop_image(img)
## extraction
extracted = model.detect(segmented)
## save
dic_predicted[str(block.id)+"-"+block.type] =
extracted.replace('n',' ').strip()
# check
parse_doc(dic_predicted)
再看看图形报表
for block in [block for block in detected if block.type == "Figure"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## save dic_predicted[str(block.id)+"-"+block.type] = segmented # check parse_doc(dic_predicted)
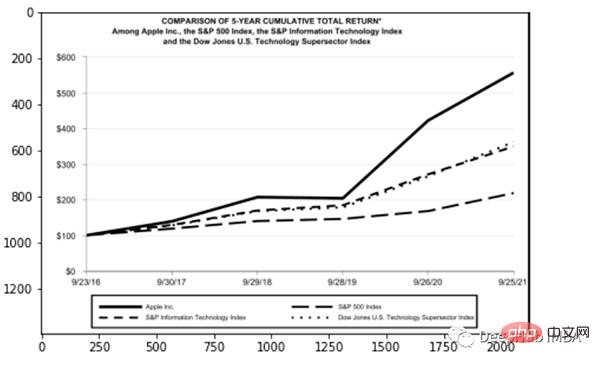
上面两个看着很不错,那是因为这两种类型相对简单,但是表格就要复杂得多。尤其是我们上看看到的的这个,因为它的行和列都是进行了合并后产生的。
for block in [block for block in detected if block.type == "Table"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## extraction extracted = model.detect(segmented) ## save dic_predicted[str(block.id)+"-"+block.type] = pd.read_csv( io.StringIO(extracted) ) # check parse_doc(dic_predicted)

正如我们的预料提取的表格不是很好。好在Python有专门处理表格的包,我们可以直接处理而不将其转换为图像。这里使用TabulaPy 包:
import tabula
tables = tabula.read_pdf("doc_apple.pdf", pages=i+1)
tables[0]
结果要好一些,但是名称仍然错了,但是效果要比直接OCR好的多。
总结
本文是一个简单教程,演示了如何使用OCR进行文档解析。使用Layoutpars软件包进行了整个检测和提取过程。并展示了如何处理PDF文档中的文本,数字和表格。
以上是使用Python和OCR進行文件解析的完整程式碼演示(附程式碼)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 mysql 是否要付費
Apr 08, 2025 pm 05:36 PM
mysql 是否要付費
Apr 08, 2025 pm 05:36 PM
MySQL 有免費的社區版和收費的企業版。社區版可免費使用和修改,但支持有限,適合穩定性要求不高、技術能力強的應用。企業版提供全面商業支持,適合需要穩定可靠、高性能數據庫且願意為支持買單的應用。選擇版本時考慮的因素包括應用關鍵性、預算和技術技能。沒有完美的選項,只有最合適的方案,需根據具體情況謹慎選擇。
 mysql安裝後怎麼使用
Apr 08, 2025 am 11:48 AM
mysql安裝後怎麼使用
Apr 08, 2025 am 11:48 AM
文章介紹了MySQL數據庫的上手操作。首先,需安裝MySQL客戶端,如MySQLWorkbench或命令行客戶端。 1.使用mysql-uroot-p命令連接服務器,並使用root賬戶密碼登錄;2.使用CREATEDATABASE創建數據庫,USE選擇數據庫;3.使用CREATETABLE創建表,定義字段及數據類型;4.使用INSERTINTO插入數據,SELECT查詢數據,UPDATE更新數據,DELETE刪除數據。熟練掌握這些步驟,並學習處理常見問題和優化數據庫性能,才能高效使用MySQL。
 如何針對高負載應用程序優化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何針對高負載應用程序優化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL數據庫性能優化指南在資源密集型應用中,MySQL數據庫扮演著至關重要的角色,負責管理海量事務。然而,隨著應用規模的擴大,數據庫性能瓶頸往往成為製約因素。本文將探討一系列行之有效的MySQL性能優化策略,確保您的應用在高負載下依然保持高效響應。我們將結合實際案例,深入講解索引、查詢優化、數據庫設計以及緩存等關鍵技術。 1.數據庫架構設計優化合理的數據庫架構是MySQL性能優化的基石。以下是一些核心原則:選擇合適的數據類型選擇最小的、符合需求的數據類型,既能節省存儲空間,又能提升數據處理速度
 HadiDB:Python 中的輕量級、可水平擴展的數據庫
Apr 08, 2025 pm 06:12 PM
HadiDB:Python 中的輕量級、可水平擴展的數據庫
Apr 08, 2025 pm 06:12 PM
HadiDB:輕量級、高水平可擴展的Python數據庫HadiDB(hadidb)是一個用Python編寫的輕量級數據庫,具備高度水平的可擴展性。安裝HadiDB使用pip安裝:pipinstallhadidb用戶管理創建用戶:createuser()方法創建一個新用戶。 authentication()方法驗證用戶身份。 fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 Navicat查看MongoDB數據庫密碼的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB數據庫密碼的方法
Apr 08, 2025 pm 09:39 PM
直接通過 Navicat 查看 MongoDB 密碼是不可能的,因為它以哈希值形式存儲。取回丟失密碼的方法:1. 重置密碼;2. 檢查配置文件(可能包含哈希值);3. 檢查代碼(可能硬編碼密碼)。
 mysql 需要互聯網嗎
Apr 08, 2025 pm 02:18 PM
mysql 需要互聯網嗎
Apr 08, 2025 pm 02:18 PM
MySQL 可在無需網絡連接的情況下運行,進行基本的數據存儲和管理。但是,對於與其他系統交互、遠程訪問或使用高級功能(如復制和集群)的情況,則需要網絡連接。此外,安全措施(如防火牆)、性能優化(選擇合適的網絡連接)和數據備份對於連接到互聯網的 MySQL 數據庫至關重要。
 mysql workbench 可以連接到 mariadb 嗎
Apr 08, 2025 pm 02:33 PM
mysql workbench 可以連接到 mariadb 嗎
Apr 08, 2025 pm 02:33 PM
MySQL Workbench 可以連接 MariaDB,前提是配置正確。首先選擇 "MariaDB" 作為連接器類型。在連接配置中,正確設置 HOST、PORT、USER、PASSWORD 和 DATABASE。測試連接時,檢查 MariaDB 服務是否啟動,用戶名和密碼是否正確,端口號是否正確,防火牆是否允許連接,以及數據庫是否存在。高級用法中,使用連接池技術優化性能。常見錯誤包括權限不足、網絡連接問題等,調試錯誤時仔細分析錯誤信息和使用調試工具。優化網絡配置可以提升性能
 mysql 需要服務器嗎
Apr 08, 2025 pm 02:12 PM
mysql 需要服務器嗎
Apr 08, 2025 pm 02:12 PM
對於生產環境,通常需要一台服務器來運行 MySQL,原因包括性能、可靠性、安全性和可擴展性。服務器通常擁有更強大的硬件、冗餘配置和更嚴格的安全措施。對於小型、低負載應用,可在本地機器運行 MySQL,但需謹慎考慮資源消耗、安全風險和維護成本。如需更高的可靠性和安全性,應將 MySQL 部署到雲服務器或其他服務器上。選擇合適的服務器配置需要根據應用負載和數據量進行評估。
