

正規表示式可用於搜尋、編輯和操作文字。 Python RegEx 被幾乎所有的公司廣泛使用,並且對他們的應用程式具有良好的行業吸引力,這使得正規表示式越來越受重視。
今天我們就一起來學習下 Python 正規表示式。
為什麼要使用正規表示式。
為了回答這個問題,我們先來看看我們面臨的各種問題,而這些問題又可以透過使用正規表示式來解決。
考慮以下場景:
文末有一個包含大量資料的日誌文件,從這個日誌檔案中,希望只取得日期和時間。乍一看,日誌檔案的可讀性是很低的。

在這種情況下,可以使用正規表示式來識別模式並輕鬆提取所需資訊。
考慮下一個場景:你是一名銷售人員,有很多電子郵件地址,其中許多地址都是假的/無效的,看看下面的圖片:

我們可以做的是使用正規表示式,可以驗證電子郵件地址的格式並從真實ID 中過濾掉虛假ID。
下一個場景與銷售員範例的場景非常相似,考慮下圖:

#我們如何驗證電話號碼,然後根據原產國對其進行分類?
每個正確的數字都會有一個特定的模式,可以透過使用正規表示式來追蹤和追蹤。
接下來是另一個簡單的場景:
我們有一個學生資料庫,其中包含姓名、年齡和地址等詳細資訊。考慮一下地區代碼最初是 59006 但現在已更改為 59076 的情況,這種情況為每個學生手動更新此代碼將非常耗時且過程非常漫長。
基本上,為了使用正規表示式解決這些問題,我們首先從包含 pin 碼的學生資料中找到一個特定的字串,然後將它們全部替換為新字串。
正規表示式用於識別文字字串中的搜尋模式,它還有助於找出資料的正確性,甚至可以使用正規表示式進行尋找、取代和格式化資料等操作。
考慮以下範例:

在給定字串的所有資料中,假設我們只需要城市,這可以以格式化的方式轉換為僅包含名稱和城市的字典。現在的問題是,我們能否確定一種模式來猜測名稱和城市?此外我們也可以找出年齡,隨著年齡的增長,這很容易,對吧?它只是一個整數。
我們要如何處理這個名字?如果你看一下這個模式,所有的名字都以大寫字母開頭。借助正規表示式,我們可以使用此方法識別姓名和年齡。
我們可以使用下面的程式碼
import re
Nameage = '''
Janice is 22 and Theon is 33
Gabriel is 44 and Joey is 21
'''
ages = re.findall(r'd{1,3}', Nameage)
names = re.findall(r'[A-Z][a-z]*',Nameage)
ageDict = {}
x = 0
for eachname in names
ageDict[eachname] = ages[x]
x+=1
print(ageDict)Output:
{'Janice': '22', 'Theon': '33', 'Gabriel': '44', 'Joey': '21'}可以使用正規則表達式執行許多操作。在這裡,我列出了一些幫助更好地理解正規表示式的用法非常重要的內容。
讓我們先檢查如何在字串中找到特定單字
import re
if re.search("inform","we need to inform him with the latest information"):
print("There is inform")我們在這裡所做的一切都是為了搜尋單字inform 是否存在於我們的搜尋字串中。
當然我們也可以優化以下程式碼
import re
allinform = re.findall("inform","We need to inform him with the latest information!")
for i in allinform:
print(i)在這裡,在這種特殊情況下,將找到兩次infor。一個來自inform,一個來自information。
如上所示,在正規表示式中找出單字就這麼簡單。
接下來我們將了解如何使用正規表示式產生迭代器。
產生迭代器是找出並目標字串的開始和結束索引的簡單過程。考慮以下範例:
import re
Str = "we need to inform him with the latest information"
for i in re.finditer("inform.", Str
locTuple = i.span()
print(locTuple)對於找到的每個符合項,都會列印開始和結束索引。當我們執行上述程式時,輸出如下:
(11, 18) (38, 45)
接下來我們將檢查如何使用正規表示式將單字與模式配對。
考虑一个输入字符串,我们必须将某些单词与该字符串匹配。要详细说明,请查看以下示例代码:
import re
Str = "Sat, hat, mat, pat"
allStr = re.findall("[shmp]at", Str)
for i in allStr:
print(i)字符串中有什么共同点?可以看到字母“a”和“t”在所有输入字符串中都很常见。代码中的 [shmp] 表示要查找的单词的首字母,因此,任何以字母 s、h、m 或 p 开头的子字符串都将被视为匹配,其中任何一个,并且最后必须跟在“at”后面。
Output:
hat mat pat
接下来我们将检查如何使用正则表达式一次匹配一系列字符。
我们希望输出第一个字母应该在 h 和 m 之间并且必须紧跟 at 的所有单词。看看下面的例子,我们应该得到的输出是 hat 和 mat
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[h-m]at", Str)
for i in someStr:
print(i)Output:
hat mat
现在让我们稍微改变一下上面的程序以获得一个不同的结果
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[^h-m]at", Str)
for i in someStr:
print(i)发现细微差别了吗,我们在正则表达式中添加了插入符号 (^),它的作用否定了它所遵循的任何效果。我们不会给出从 h 到 m 开始的所有内容的输出,而是会向我们展示除此之外的所有内容的输出。
我们可以预期的输出是不以 h 和 m 之间的字母开头但最后仍然紧随其后的单词。Output:
sat pat
接下来,我们可以使用正则表达式检查另一个操作,其中我们将字符串中的一项替换为其他内容:
import re
Food = "hat rat mat pat"
regex = re.compile("[r]at")
Food = regex.sub("food", Food)
print(Food)在上面的示例中,单词 rat 被替换为单词 food。正则表达式的替代方法就是利用这种情况,它也有各种各样的实际用例。Output:
hat food mat pat
import re randstr = "Here is Edureka" print(randstr)
Output:
Here is Edureka
这就是反斜杠问题,其中一个斜线从输出中消失了,这个特殊问题可以使用正则表达式来解决。
import re randstr = "Here is Edureka" print(re.search(r"Edureka", randstr))
Output:
<re.Match object; span=(8, 16), match='Edureka'>
这就是使用正则表达式解决反斜杠问题的简单方法。
使用正则表达式可以轻松地单独匹配字符串中的单个字符
import re
randstr = "12345"
print("Matches: ", len(re.findall("d{5}", randstr)))Output:
Matches: 1
我们可以在 Python 中使用正则表达式轻松删除换行符
import re
randstr = '''
You Never
Walk Alone
Liverpool FC
'''
print(randstr)
regex = re.compile("
")
randstr = regex.sub(" ", randstr)
print(randstr)Output:
You Never Walk Alone Liverpool FC You Never Walk Alone Liverpool FC
可以从上面的输出中看到,新行已被空格替换,并且输出打印在一行上。
还可以使用许多其他东西,具体取决于要替换字符串的内容
: Backspace : Formfeed : Carriage Return : Tab : Vertical Tab
可以使用如下代码
import re
randstr = "12345"
print("Matches:", len(re.findall("d", randstr)))Output:
Matches: 5
从上面的输出可以看出,d 匹配字符串中存在的整数。但是,如果我们用 D 替换它,它将匹配除整数之外的所有内容,与 d 完全相反。
接下来我们了解一些在 Python 中使用正则表达式的重要实际例子。
我们将检查使用最为广泛的 3 个主要用例
需要在任何相关场景中轻松验证电话号码
考虑以下电话号码:
电话号码的一般格式如下:
我们将在下面的示例中使用 w,请注意 w = [a-zA-Z0-9_]
import re
phn = "412-555-1212"
if re.search("w{3}-w{3}-w{4}", phn):
print("Valid phone number")Output:
Valid phone number
在任何情况下验证电子邮件地址的有效性。
考虑以下电子邮件地址示例:
我们只需一眼就可以从无效的邮件 ID 中识别出有效的邮件 ID,但是当我们的程序为我们做这件事时,却并没有那么容易,但是使用正则,就非常简单了。
指导思路,所有电子邮件地址应包括:
import re
email = "ac@aol.com md@.com @seo.com dc@.com"
print("Email Matches: ", len(re.findall("[w._%+-]{1,20}@[w.-]{2,20}.[A-Za-z]{2,3}", email)))Output:
Email Matches: 1
从上面的输出可以看出,我们输入的 4 封电子邮件中有一封有效的邮件。
这基本上证明了使用正则表达式并实际使用它们是多么简单和高效。
从网站上删除所有电话号码以满足需求。
要了解网络抓取,请查看下图:
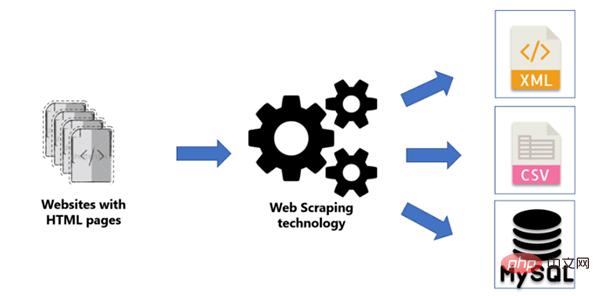
我们已经知道,一个网站将由多个网页组成,我们需要从这些页面中抓取一些信息。
网页抓取主要用于从网站中提取信息,可以将提取的信息以 XML、CSV 甚至 MySQL 数据库的形式保存,这可以通过使用 Python 正则表达式轻松实现。
import urllib.request
from re import findall
url = "http://www.summet.com/dmsi/html/codesamples/addresses.html"
response = urllib.request.urlopen(url)
html = response.read()
htmlStr = html.decode()
pdata = findall("(d{3}) d{3}-d{4}", htmlStr)
for item in pdata:
print(item)Output:
(257) 563-7401 (372) 587-2335 (786) 713-8616 (793) 151-6230 (492) 709-6392 (654) 393-5734 (404) 960-3807 (314) 244-6306 (947) 278-5929 (684) 579-1879 (389) 737-2852 ...
我们首先是通过导入执行网络抓取所需的包,最终结果包括作为使用正则表达式完成网络抓取的结果而提取的电话号码。
以上是整理了幾個Python正規表達式,拿走就能用!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















