

微軟贏麻了!數十億文字-圖像對訓練,多模態Florence開啟免費體驗,登上Azure

2021年11月,微軟發布了一個多模態視覺基礎模型Florence(佛羅倫薩),橫掃超過40個基準任務,輕鬆適用於如分類、目標檢測、VQA、看圖說話、視頻檢索和動作識別等多個任務。
時隔一年半,Florence正式開啟商用階段!
Florence能幹嘛?
最近,微軟全球人工智慧首席技術長黃學東官宣布了微軟 Florence 基礎模型的公開預覽版。
Florence模型經過數十億文字-圖像對的訓練,目前已整合進Azure 認知視覺服務中,在「價格」和「表現」上都已到達「生產環境」的要求,目前處於免費試用階段。

改進後的視覺服務使開發人員能夠在不同行業創建前沿的、適應市場的、負責任的電腦視覺應用程式。客戶可以將他們的數據無縫地數位化、分析並連接到自然語言的交互中,從圖像和視頻內容中獲取更精確的信息,保護用戶遠離有害內容,增強安全性,並提升事件響應速度。
Florence的實際能力也很強大,使用者可以在Vision Studio中進行「開箱即用」的體驗。

體驗網址:https://portal.vision.cognitive.azure.com/gallery/featured
具體包括:
# Dense Captions(詳細的描述):可以自動提供內容豐富的描述資訊、設計建議、可存取的替代文字、搜尋引擎優化、智慧照片管理等以支援數位化內容。
圖像檢索:使用自然語言查詢,無縫地度量圖像和文字之間的相似性,從而改善搜尋推薦和廣告。
背景移除:可以方便地從原始背景中分割出人物和物體,並替換為其他背景場景,從而改變影像的外觀和感覺。
模型客製化:降低交付客製化模型的成本和時間,能夠以更高精度來匹配獨特的業務需求,即便只有少量的可用影像。
影片摘要:搜尋和互動影片內容,與人類同樣直觀的方式進行思考和寫作。可以協助找到相關內容,並且不需要額外的元資料。
Reddit消費品產品經理Tiffany Ong表示,透過微軟的Vision技術,可以使用戶更容易發現和理解Reddit上的內容。
新建立的圖片描述可以讓使用者更容易存取Reddit,使用圖像描述來幫助用戶提高文章的搜尋結果,讓Reddit用戶有更多機會來探索網站上的圖片,參與對話,並最終建立聯繫和社區感知。
Florence能夠為每張圖片產生多達10000個標籤,使得Reddit能夠更好地控制圖片中的物件數量,並幫助產生更好的影像描述。
Microsoft 365
除了微軟資料中心之外,微軟也正在提升Microsoft 365應用程式(包括Teams、 PowerPoint、 Outlook、 Word、 Designer、 OneDrive)中視覺服務的能力。
在影像分割能力的幫助下,Teams正在推動數位空間的創新型,把虛擬會議的體驗提升到新高度。
PowerPoint、 Outlook和Word利用自動替換文字的圖像描述來提高可訪問性。
Microsoft Designer和OneDrive正在使用改進的圖像描述、圖像搜尋和背景生成來簡化圖像的可發現性和編輯。
Microsoft資料中心正在利用Vision Services來增強安全性和基礎架構的可靠性。
LinkedIn的無障礙工程負責人Jennison Asuncon表示,LinkedIn上有超過40%的貼文包含至少一張圖片,對於盲人或低視力的使用者來說,視覺服務能夠讓所有使用者都有平等的閱讀機會,並使他們能夠參與線上對話。

透過Azure視覺認知服務,LinkedIn可以提供自動圖像描述來編輯和支援可選文本,這是一種全新的體驗。
不僅我對此感到興奮,我的同事剛剛分享了一個他們參加活動的照片,LinkedIn的執行長Ryan Roslansky也在照片裡。
負責任地創新
回顧負責任的人工智慧原則,可以了解到微軟是如何致力於開發人工智慧系統,以提升世界的可訪問性。

微軟致力於幫助各個組織充分利用人工智慧,並正在大力投資於提供技術、資源和專業知識的項目,以增強那些致力於創造一個更永續、更安全和更容易進入的世界的人的能力。
多模態是未來
包括微軟、Google在內的多個科技巨頭在人工智慧發展方向上出奇地一致,認為「多模態模型」是提高人工智慧系統能力的最佳途徑,也就是單一模型可以同時理解語言、圖像、視訊和音訊等,並且能夠完成單模態模型無法完成的任務,例如為視訊添加文字描述等。

為什麼不把幾個「單模態」模型串在一起,以達到同樣的目的,比如說用一個模型來理解圖像,而另一個模型用來理解語言?
第一個原因是,由其他模態提供的背景信息,多模態模型可以在某些情況下比單模態模型在同一任務中表現得更好。
比如說,一個能夠理解圖像、定價數據和購買歷史的人工智慧助理可以比一個「只理解定價數據」的AI能夠提供更好的個人化產品建議。
並且從計算的角度來看,多模態模型往往更有效率,可以提升資料處理的速度,降低後端的成本。
毫無疑問,所有商業公司都渴望降本增效。
Florence能夠理解圖像、視訊和語言以及這些模態之間的關係,從而可以做到一些單模態無法完成的任務,例如測量圖像和文字之間的相似度,分割照片中的對象,然後把它們貼到另一個背景上。
幾乎所有AI模型的訓練都面臨數據版權問題,Azure AI的企業副總裁(CVP)John Montgomery在回答有關“Florence的訓練數據”時沒有透露太多信息,只是說Florence使用的是「負責任地取得」的資料來源,包括來自合作夥伴的資料;此外,Montgomery表示,訓練資料中刪除了可能有問題的內容,也是公開訓練資料集的常見特點。

Montgomery認為,當使用大型基礎模型時,最重要的是要確保訓練資料集的質量,為每個視覺任務的適應模型創建基礎,微軟針對每個視覺任務的調整模型都經過了公平性、對抗性和挑戰性案例的測試,並實現了與Azure Open AI Service 和DALL-E 相同的內容審核服務。
在未來,消費者可以使用Florence做更多的事情,例如偵測製造過程中的缺陷,以及在零售店實現自助結帳。
不過Montgomery指出這些用例實際上並不需要多模態視覺模型,但他斷言,多模態在這個過程中可以增加一些有價值的東西。
Florence是一個經過「完全重新思考」的視覺模型,一旦在圖像和文字之間實現了簡單且高品質的翻譯過程,就會打開一個全新的、充滿未知可能性的世界。
客戶能夠體驗到顯著改進的圖像搜索,將圖像和視覺模型以及語言和語音等其它模型類型訓練成全新類型的應用,並輕鬆提高自定義模型的質量。
以上是微軟贏麻了!數十億文字-圖像對訓練,多模態Florence開啟免費體驗,登上Azure的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 微軟bing國際版入口地址(bing搜尋引擎入口)
Mar 14, 2024 pm 01:37 PM
微軟bing國際版入口地址(bing搜尋引擎入口)
Mar 14, 2024 pm 01:37 PM
必應(Bing)是微軟公司推出的網路搜尋引擎,搜尋功能非常強大,分了國內版和國際版兩個入口。這兩個版本入口在哪呢?怎麼訪問國際版呢?下面就來看看詳細內容。 必應中國版網址入口:https://cn.bing.com/ 必應國際版網址入口:https://global.bing.com/ 必應國際版怎麼存取? 1、先輸入開啟必應的網址入口:https://www.bing.com/ 2、可以看到有國內版跟國際版的選項,我們只需要選擇國際版,輸入關鍵字即可。
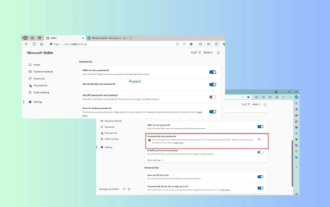 Microsoft Edge升級:自動儲存密碼功能遭禁? !用戶驚了!
Apr 19, 2024 am 08:13 AM
Microsoft Edge升級:自動儲存密碼功能遭禁? !用戶驚了!
Apr 19, 2024 am 08:13 AM
4月18日消息,近日,一些使用Canary頻道的MicrosoftEdge瀏覽器的用戶反映,在升級到最新版本後,他們發現自動保存密碼的選項被禁用了。經過調查,這是瀏覽器升級後的微調,而非功能被取消。在使用Edge瀏覽器造訪網站前,使用者回饋說瀏覽器會彈出一個視窗詢問是否希望儲存網站的登入密碼。選擇儲存後,下次登入時,Edge會自動填入已儲存的帳號和密碼,為使用者提供了極大的便利。但最近的更新類似於微調,修改了預設設定。使用者需要在選擇儲存密碼後,再手動在設定中開啟自動填入已儲存的帳號和密碼
 微軟發布 Win11 八月累積更新:提高安全性、優化鎖定螢幕等
Aug 14, 2024 am 10:39 AM
微軟發布 Win11 八月累積更新:提高安全性、優化鎖定螢幕等
Aug 14, 2024 am 10:39 AM
本站8月14日訊息,在今天的8月補丁星期二活動日中,微軟發布了適用於Windows11系統的累積更新,包括針對22H2和23H2的KB5041585更新,面向21H2的KB5041592更新。上述設備安裝8月累積更新之後,本站附上版本號變更如下:21H2設備安裝後版本號升至Build22000.314722H2設備安裝後版本號升至Build22621.403723H2設備安裝後版本號升至Build22631.4037面向Windows1121H2的KB5041585更新主要內容如下:改進:提高了
 微軟 Win11 壓縮為 7z、TAR 檔案的功能已從 24H2 下放到 23H2/22H2 版本
Apr 28, 2024 am 09:19 AM
微軟 Win11 壓縮為 7z、TAR 檔案的功能已從 24H2 下放到 23H2/22H2 版本
Apr 28, 2024 am 09:19 AM
本站4月27日消息,微軟本月初向Canary和Dev頻道發布了Windows11Build26100預覽版更新,預估會成為Windows1124H2更新的候選RTM版本。新版本中最主要的變化在於檔案總管、整合Copilot、編輯PNG檔案元資料、建立TAR和7z壓縮檔案等等。 @PhantomOfEarth發現,微軟已經將24H2版本(Germanium)部分功能下放到23H2/22H2(Nickel)版本中,例如創建TAR和7z壓縮檔。如示意圖所示,Windows11將支援原生建立TAR
 微軟全螢幕彈窗催促:Windows 10用戶抓緊時間升級到Windows 11
Jun 06, 2024 am 11:35 AM
微軟全螢幕彈窗催促:Windows 10用戶抓緊時間升級到Windows 11
Jun 06, 2024 am 11:35 AM
6月3日訊息,微軟正在積極向所有Windows10用戶發送全螢幕通知,鼓勵他們升級到Windows11作業系統。這項舉措涉及了那些硬體配置並不支援新系統的設備。自2015年起,Windows10已經佔了近70%的市場份額,穩坐Windows作業系統的霸主地位。然而,市佔率遠超過82%的市場份額,佔有率遠超過2021年問世的Windows11。儘管Windows11已經推出已近三年,但其市場滲透率仍顯緩慢。微軟已宣布,將於2025年10月14日後終止對Windows10的技術支持,以便更專注於
 微軟Edge瀏覽器更新:新增「放大影像」功能,提升使用者體驗
Mar 21, 2024 pm 01:40 PM
微軟Edge瀏覽器更新:新增「放大影像」功能,提升使用者體驗
Mar 21, 2024 pm 01:40 PM
3月21日消息,微軟近日對其MicrosoftEdge瀏覽器進行了更新,新增了一個實用的「放大影像」功能。現在,用戶在使用Edge瀏覽器時,只需右鍵點擊圖片,便可在彈出的選單中輕鬆找到這項新功能。更方便的是,使用者還可以將遊標停留在圖片上方,然後雙擊Ctrl鍵,即可快速呼出放大影像的功能。根據小編的了解,最新發布的MicrosoftEdge瀏覽器已經在Canary頻道進行了新功能測試。該瀏覽器的穩定版中也已經正式推出了實用的「放大影像」功能,為用戶提供了更便利的圖片瀏覽體驗。外國科技媒體也對此
 微軟 Z1000 固態硬碟現身網絡,搭載神秘 CNEXLabs 主控
Mar 11, 2024 pm 01:50 PM
微軟 Z1000 固態硬碟現身網絡,搭載神秘 CNEXLabs 主控
Mar 11, 2024 pm 01:50 PM
本站3月11日消息,消息人士結城安穗-YuuKi_AnS近日在X平台分享了一塊微軟Z1000固態硬碟樣品的系列圖片。從標籤資訊了解到,這塊Z1000為EngineeringSample(工程樣品),960GB容量,生產於2020年5月18日,DC3.3V供電,標稱功耗15W。根據消息來源透露,其支援NVMe1.2協議。 ▲微軟Z1000固態硬碟正面(有標籤面)照▲微軟Z1000固態硬碟正面照(無標籤)▲微軟Z1000固態硬碟反面照▲微軟Z1000固態硬碟反面照-主控特寫參考結城安穗-YuuKi_AnAn
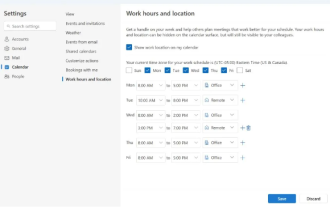 微軟推出新版Outlook for Windows:行事曆功能全面升級
Apr 27, 2024 pm 03:44 PM
微軟推出新版Outlook for Windows:行事曆功能全面升級
Apr 27, 2024 pm 03:44 PM
在4月27日的消息中,微軟公司宣布即將發布新版OutlookforWindows客戶端的測試。此次更新主要聚焦於優化行事曆功能,旨在提升使用者的工作效率,進一步簡化日常工作流程。新版OutlookforWindows客戶端的改進點在於其更強大的行事曆管理功能。現在,使用者能夠更方便地分享個人的工作時間與地點訊息,使得會議規劃更有效率。此外,Outlook還新增了人性化設置,讓用戶設定會議自動提前結束或推遲開始,為用戶提供了更多的靈活性,無論是換會議室、稍作休息還是享受一杯咖啡,都能輕鬆安排。根據
