

十個Pandas的另類資料處理技巧

本文所整理的技巧與以前整理過10個Pandas的常用技巧不同,你可能不會經常的使用它,但是有時當你遇到一些非常棘手的問題時,這些技巧可以幫你快速解決一些不常見的問題。

1、Categorical類型
預設情況下,具有有限數量選項的欄位都會被指派object 類型。但是就記憶體來說並不是一個有效的選擇。我們可以這些列建立索引,並僅使用對物件的參考而實際值。 Pandas 提供了一種稱為 Categorical的Dtype來解決這個問題。
例如一個具有圖片路徑的大型資料集組成。每行有三列:anchor, positive, and negative.。
如果類別列使用 Categorical 可以顯著減少記憶體使用量。
# raw data +----------+------------------------+ |class |filename| +----------+------------------------+ | Bathroom | Bathroombath_1.jpg| | Bathroom | Bathroombath_100.jpg| | Bathroom | Bathroombath_1003.jpg | | Bathroom | Bathroombath_1004.jpg | | Bathroom | Bathroombath_1005.jpg | +----------+------------------------+ # target +------------------------+------------------------+----------------------------+ | anchor |positive|negative| +------------------------+------------------------+----------------------------+ | Bathroombath_1.jpg| Bathroombath_100.jpg| Dinningdin_540.jpg| | Bathroombath_100.jpg| Bathroombath_1003.jpg | Dinningdin_1593.jpg | | Bathroombath_1003.jpg | Bathroombath_1004.jpg | Bedroombed_329.jpg| | Bathroombath_1004.jpg | Bathroombath_1005.jpg | Livingroomliving_1030.jpg | | Bathroombath_1005.jpg | Bathroombath_1007.jpg | Bedroombed_1240.jpg | +------------------------+------------------------+----------------------------+
filename欄的值會經常被複製重複。因此,所以透過使用Categorical可以極大的減少記憶體使用量。
讓我們讀取目標資料集,看看記憶體的差異:
triplets.info(memory_usage="deep") # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 anchor 525000 non-null category # 1 positive 525000 non-null category # 2 negative 525000 non-null category # dtypes: category(3) # memory usage: 4.6 MB # without categories triplets_raw.info(memory_usage="deep") # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 anchor 525000 non-null object # 1 positive 525000 non-null object # 2 negative 525000 non-null object # dtypes: object(3) # memory usage: 118.1 MB
差異非常大,並且隨著重複次數的增加,差異呈現非線性成長。
2、行列轉換
sql中常會遇到行列轉換的問題,Pandas有時候也需要,讓我們看看來自Kaggle比賽的資料集。 census_start .csv檔:
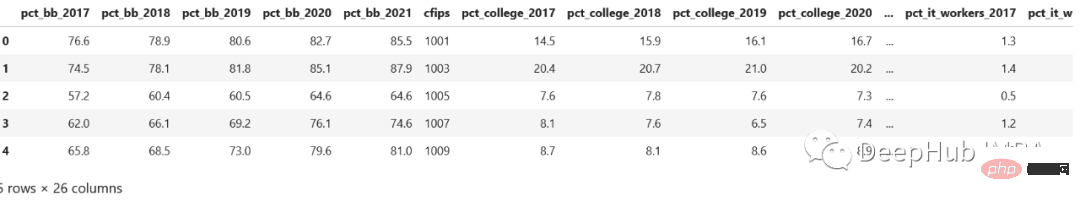
可以看到,這些按年來保存的,如果有一個列year和pct_bb,並且每一行有相應的值,則會好得多,對吧。
cols = sorted([col for col in original_df.columns
if col.startswith("pct_bb")])
df = original_df[(["cfips"] + cols)]
df = df.melt(id_vars="cfips",
value_vars=cols,
var_name="year",
value_name="feature").sort_values(by=["cfips", "year"])看看結果,這樣是不是就好很多了:

#3、apply()很慢
我們上次已經介紹過,最好不要使用這個方法,因為它遍歷每行並呼叫指定的方法。但是要是我們沒有別的選擇,那還有沒有辦法提高速度呢?
可以使用swifter或pandarallew這樣的包,使過程並行化。
Swifter
import pandas as pd import swifter def target_function(row): return row * 10 def traditional_way(data): data['out'] = data['in'].apply(target_function) def swifter_way(data): data['out'] = data['in'].swifter.apply(target_function)
Pandarallel
import pandas as pd from pandarallel import pandarallel def target_function(row): return row * 10 def traditional_way(data): data['out'] = data['in'].apply(target_function) def pandarallel_way(data): pandarallel.initialize() data['out'] = data['in'].parallel_apply(target_function)
透過多線程,可以提高計算的速度,當然當然,如果有集群,那麼最好使用dask或pyspark
4、空值,int, Int64
標準整數資料型別不支援空值,所以會自動轉換為浮點數。所以如果資料要求在整數欄位中使用空值,請考慮使用Int64資料類型,因為它會使用pandas.NA來表示空值。
5、Csv, 壓縮還是parquet?
#盡可能選擇parquet。 parquet會保留資料類型,讀取資料時就不需要指定dtypes。 parquet檔案預設已經使用了snappy進行壓縮,所以佔用的磁碟空間小。下面可以看看幾個的對比
|file|size | +------------------------+---------+ | triplets_525k.csv| 38.4 MB | | triplets_525k.csv.gzip |4.3 MB | | triplets_525k.csv.zip|4.5 MB | | triplets_525k.parquet|1.9 MB | +------------------------+---------+
讀取parquet需要額外的包,例如pyarrow或fastparquet。 chatgpt說pyarrow比fastparquet要快,但是我在小資料集上測試時fastparquet比pyarrow要快,但是這裡建議使用pyarrow,因為pandas 2.0也是預設的使用這個。
6、value_counts ()
計算相對頻率,包括獲得絕對值、計數和除以總數是很複雜的,但是使用value_counts,可以更容易地完成這項任務,並且此方法提供了包含或排除空值的選項。
df = pd.DataFrame({"a": [1, 2, None], "b": [4., 5.1, 14.02]})
df["a"] = df["a"].astype("Int64")
print(df.info())
print(df["a"].value_counts(normalize=True, dropna=False),
df["a"].value_counts(normalize=True, dropna=True), sep="nn")
這樣是不是就簡單很多了
7、Modin
注意:Modin現在還在測試階段。
pandas是單線程的,但Modin可以透過縮放pandas來加快工作流程,它在較大的資料集上工作得特別好,因為在這些資料集上,pandas會變得非常緩慢或記憶體佔用過大導致OOM。
!pip install modin[all]
import modin.pandas as pd
df = pd.read_csv("my_dataset.csv")以下是modin官網的架構圖,有興趣的研究把:

#8、extract()
如果經常遇到複雜的半結構化的數據,並且需要從中分離出單獨的列,那麼可以使用這個方法:
import pandas as pd
regex = (r'(?P<title>[A-Za-z's]+),'
r'(?P<author>[A-Za-zs']+),'
r'(?P<isbn>[d-]+),'
r'(?P<year>d{4}),'
r'(?P<publisher>.+)')
addr = pd.Series([
"The Lost City of Amara,Olivia Garcia,978-1-234567-89-0,2023,HarperCollins",
"The Alchemist's Daughter,Maxwell Greene,978-0-987654-32-1,2022,Penguin Random House",
"The Last Voyage of the HMS Endeavour,Jessica Kim,978-5-432109-87-6,2021,Simon & Schuster",
"The Ghosts of Summer House,Isabella Lee,978-3-456789-12-3,2000,Macmillan Publishers",
"The Secret of the Blackthorn Manor,Emma Chen,978-9-876543-21-0,2023,Random House Children's Books"
])
addr.str.extract(regex)
9、读写剪贴板
这个技巧有人一次也用不到,但是有人可能就是需要,比如:在分析中包含PDF文件中的表格时。通常的方法是复制数据,粘贴到Excel中,导出到csv文件中,然后导入Pandas。但是,这里有一个更简单的解决方案:pd.read_clipboard()。我们所需要做的就是复制所需的数据并执行一个方法。
有读就可以写,所以还可以使用to_clipboard()方法导出到剪贴板。
但是要记住,这里的剪贴板是你运行python/jupyter主机的剪切板,并不可能跨主机粘贴,一定不要搞混了。
10、数组列分成多列
假设我们有这样一个数据集,这是一个相当典型的情况:
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3],
"b": [4, 5, 6],
"category": [["foo", "bar"], ["foo"], ["qux"]]})
# let's increase the number of rows in a dataframe
df = pd.concat([df]*10000, ignore_index=True)
我们想将category分成多列显示,例如下面的

先看看最慢的apply:
def dummies_series_apply(df):
return df.join(df['category'].apply(pd.Series)
.stack()
.str.get_dummies()
.groupby(level=0)
.sum())
.drop("category", axis=1)
%timeit dummies_series_apply(df.copy())
#5.96 s ± 66.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)sklearn的MultiLabelBinarizer
from sklearn.preprocessing import MultiLabelBinarizer
def sklearn_mlb(df):
mlb = MultiLabelBinarizer()
return df.join(pd.DataFrame(mlb.fit_transform(df['category']), columns=mlb.classes_))
.drop("category", axis=1)
%timeit sklearn_mlb(df.copy())
#35.1 ms ± 1.31 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)是不是快了很多,我们还可以使用一般的向量化操作对其求和:
def dummies_vectorized(df):
return pd.get_dummies(df.explode("category"), prefix="cat")
.groupby(["a", "b"])
.sum()
.reset_index()
%timeit dummies_vectorized(df.copy())
#29.3 ms ± 1.22 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
使用第一个方法(在StackOverflow上的回答中非常常见)会给出一个非常慢的结果。而其他两个优化的方法的时间是非常快速的。
总结
我希望每个人都能从这些技巧中学到一些新的东西。重要的是要记住尽可能使用向量化操作而不是apply()。此外,除了csv之外,还有其他有趣的存储数据集的方法。不要忘记使用分类数据类型,它可以节省大量内存。感谢阅读!
以上是十個Pandas的另類資料處理技巧的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Win11小技巧分享:一招跳過微軟帳號登入
Mar 27, 2024 pm 02:57 PM
Win11小技巧分享:一招跳過微軟帳號登入
Mar 27, 2024 pm 02:57 PM
Win11小技巧分享:一招跳過微軟帳號登入Windows11是微軟最新推出的作業系統,具有全新的設計風格和許多實用的功能。然而,對於某些用戶來說,在每次啟動系統時都要登入微軟帳戶可能會感到有些煩擾。如果你是其中一員,不妨試試以下的技巧,讓你能夠跳過微軟帳號登錄,直接進入桌面介面。首先,我們需要在系統中建立一個本機帳戶,來取代微軟帳戶登入。這樣做的好處是
 老手必備:C語言中*與&的技巧與注意事項
Apr 04, 2024 am 08:21 AM
老手必備:C語言中*與&的技巧與注意事項
Apr 04, 2024 am 08:21 AM
C語言中,表示指針,儲存其他變數的位址;&表示位址運算符,傳回變數的記憶體位址。指針的使用技巧包括定義指針、解引用指針,需確保指針指向有效地址;地址運算符&的使用技巧包括取得變數地址,取得數組元素地址時返回數組第一元素地址。實戰案例說明了使用指標和位址運算子反轉字串。
 新手製作表格有哪些技巧
Mar 21, 2024 am 09:11 AM
新手製作表格有哪些技巧
Mar 21, 2024 am 09:11 AM
我們經常在excel中製作和編輯表格,但是作為一個剛剛接觸軟體的新手來講,如何使用excel製作表格,並沒有我們使用起來那麼輕鬆。下邊,我們針對新手,也就是初學者需要掌握的表格製作的一些步驟進行一些演練,希望對需要的人有些幫助。新手錶格範例樣板如下圖:我們看看如何完成! 1,新建excel文檔,有兩種方法。可以在【桌面】空白位置,點選滑鼠右鍵-【新建】-【xls】檔。也可以【開始】-【所有程式】-【MicrosoftOffice】-【MicrosoftExcel20**】2,雙擊我們新建的ex
 Golang如何提升資料處理效率?
May 08, 2024 pm 06:03 PM
Golang如何提升資料處理效率?
May 08, 2024 pm 06:03 PM
Golang透過並發性、高效能記憶體管理、原生資料結構和豐富的第三方函式庫,提升資料處理效率。具體優勢包括:並行處理:協程支援同時執行多個任務。高效率記憶體管理:垃圾回收機制自動管理記憶體。高效資料結構:切片、映射和通道等資料結構快速存取和處理資料。第三方函式庫:涵蓋fasthttp和x/text等各種資料處理庫。
 VSCode入門指南:初學者必讀,快速掌握使用技巧!
Mar 26, 2024 am 08:21 AM
VSCode入門指南:初學者必讀,快速掌握使用技巧!
Mar 26, 2024 am 08:21 AM
VSCode(VisualStudioCode)是一款由微軟開發的開源程式碼編輯器,具有強大的功能和豐富的插件支持,成為開發者的首選工具之一。本文將為初學者提供一個入門指南,幫助他們快速掌握VSCode的使用技巧。在本文中,將介紹如何安裝VSCode、基本的編輯操作、快捷鍵、插件安裝等內容,並為讀者提供具體的程式碼範例。 1.安裝VSCode首先,我們需
 PHP程式設計技巧:如何實現3秒內跳轉網頁
Mar 24, 2024 am 09:18 AM
PHP程式設計技巧:如何實現3秒內跳轉網頁
Mar 24, 2024 am 09:18 AM
標題:PHP程式設計技巧:如何實現3秒內跳轉網頁在Web開發中,經常會遇到需要在一定時間內自動跳到另一個頁面的情況。本文將介紹如何使用PHP實作在3秒內實現頁面跳轉的程式設計技巧,並提供具體的程式碼範例。首先,實現頁面跳轉的基本原理是透過HTTP的回應頭中的Location欄位來實現。透過設定該欄位可以讓瀏覽器自動跳到指定的頁面。下面是一個簡單的例子,示範如何在P
 Laravel 和 CodeIgniter 中資料處理能力的比較如何?
Jun 01, 2024 pm 01:34 PM
Laravel 和 CodeIgniter 中資料處理能力的比較如何?
Jun 01, 2024 pm 01:34 PM
比較Laravel和CodeIgniter的資料處理能力:ORM:Laravel使用EloquentORM,提供類別物件關係映射,而CodeIgniter使用ActiveRecord,將資料庫模型表示為PHP類別的子類別。查詢建構器:Laravel具有靈活的鍊式查詢API,而CodeIgniter的查詢建構器更簡單,基於陣列。資料驗證:Laravel提供了一個Validator類,支援自訂驗證規則,而CodeIgniter的驗證功能內建較少,需要手動編碼自訂規則。實戰案例:用戶註冊範例展示了Lar
 Win11技巧大揭密:如何繞過微軟帳號登入
Mar 27, 2024 pm 07:57 PM
Win11技巧大揭密:如何繞過微軟帳號登入
Mar 27, 2024 pm 07:57 PM
Win11技巧大揭密:如何繞過微軟帳號登入近期,微軟公司推出了全新的作業系統Windows11,引起了廣泛關注。相較於之前的版本,Windows11在介面設計、功能改進等方面做出了許多新的調整,但也引發了一些爭議,其中最引人注目的一點就是強制要求用戶使用微軟帳戶登入系統。對於某些用戶來說,他們可能更習慣於使用本地帳戶登錄,而不願意將個人資訊與微軟帳戶綁定。
