

完爆GPT3、GooglePaLM!檢索增強模型Atlas刷新知識類小樣本任務SOTA

不知不覺間,大模型小樣本成為了小樣本學習領域的主流打法,在許多的任務背景下,一套通用的思路是先標註小數據樣本,再從預訓練大模型的基礎上使用小數據樣本進行訓練。儘管如我們所見,大模型在一眾小樣本學習的任務上都取得了驚人的效果,但是它也自然而然的將一些大模型固有的弊病放置在了小樣本學習的聚光燈下。
小樣本學習期望模型具有依據少量樣本完成自主推理的能力,也就是說理想中的模型應該透過做題而掌握解題思路,從而面對新出現的題可以舉一反三。然而大模型小樣本的理想且實用的學習能力,似乎卻是靠大模型訓練期間儲存的大量資訊來生生把一道題解設答的過程背誦下來,儘管在各個數據集上神勇無比,但總會給人帶來疑惑依照這個方法學習出來的學生真的是個有潛力的學生嗎?

而今天介紹的這篇由Meta AI 推出的論文,便另闢蹊徑的將檢索增強的方法應用於小樣本學習領域,不僅僅以64個範例便在自然問答資料集(Natural Questions)上取得了42%的正確率,同時也對標大模型PaLM 將參數量減少了50 倍(540B—>11B),並且在可解釋性、可控制性、可更新性等方面上都具有其餘大模型所不具備的顯著優勢。
論文主題:Few-shot Learning with Retrieval Augmented Language Models##論文連結:https://arxiv.org/pdf/2208.03299.pdf
#檢索增強溯源
##論文一開始,便向大家拋出了一個問題:“在小樣本學習領域,使用巨量的參數去存儲信息真的是必要的嗎?”,縱觀大模型的發展,前僕後繼的大模型可以樂此不疲的刷SOTA的原因之一,便是其龐大的參數儲存了問題所需的資訊。從Transformer 橫空出世以來,大模型一直是NLP 領域的主流範式,而隨著大模型的逐步發展,「大」的問題不斷暴露,追問所謂「大」的必要性便相當有意義,論文作者從這個問題出發,給了這個問題否定的答案,而其方法,便是檢索增強模型。

而在當時,其實還有另外一條路子,便是Cached LM,它的核心思想在於,既然RNN 一上考場就有可能記不住,那麼乾脆就讓RNN 開卷考試,透過引入Cache 機制,把訓練時預測的字詞存在Cache 中,預測時便可以結合query 與Cache 索引兩方面的資訊來完成任務,從而解決當時RNN 模型的硬傷。
由此,檢索增強技術便走上了一條與大模型依賴參數記憶資訊的迥然不同的道路。基於檢索增強的模型允許引入不同來源的外部知識,而這些檢索來源有訓練語料、外部資料、無監督資料等多種選擇。檢索增強模型一般由一個檢索器與一個生成器構成,透過檢索器根據 query 從外部檢索來源獲得相關知識,透過生成器結合 query 與檢索到的相關知識進行模型預測。
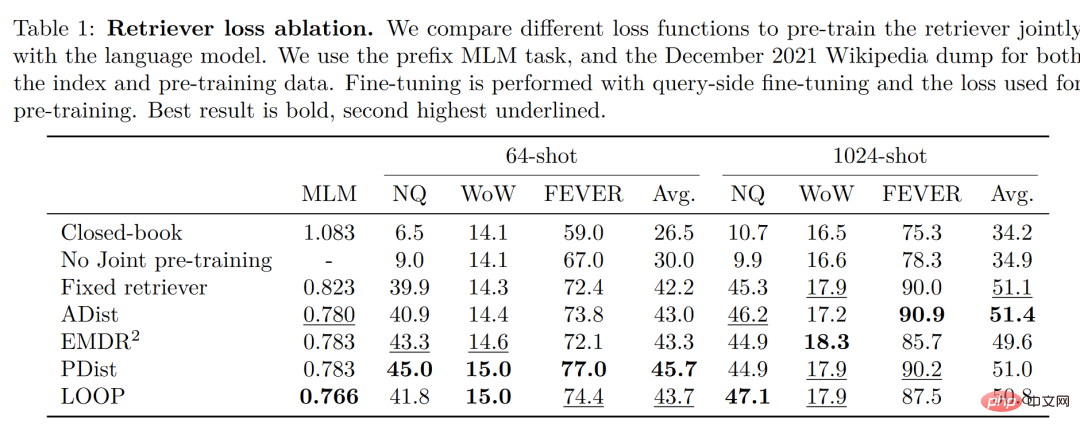
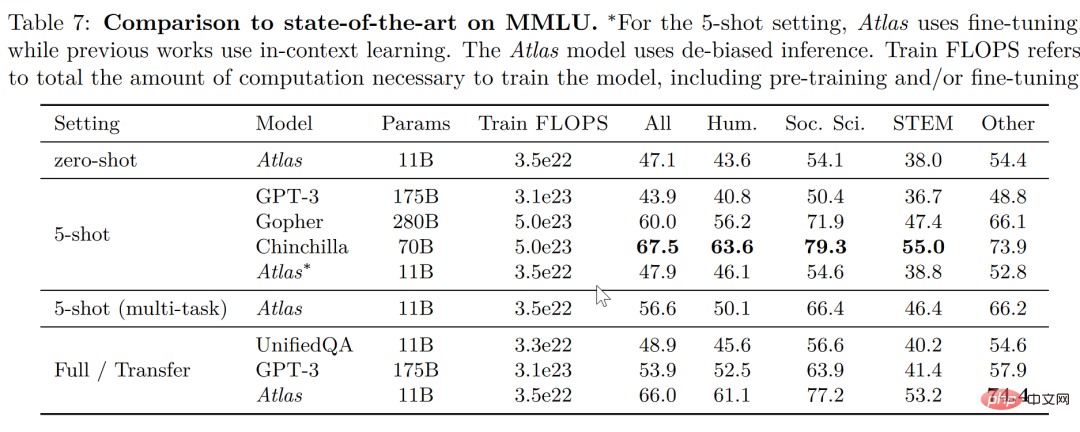
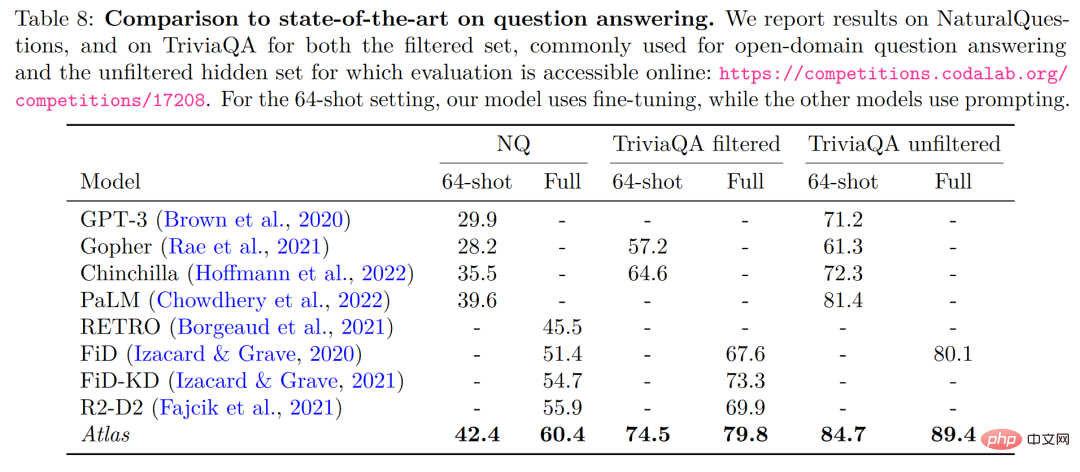
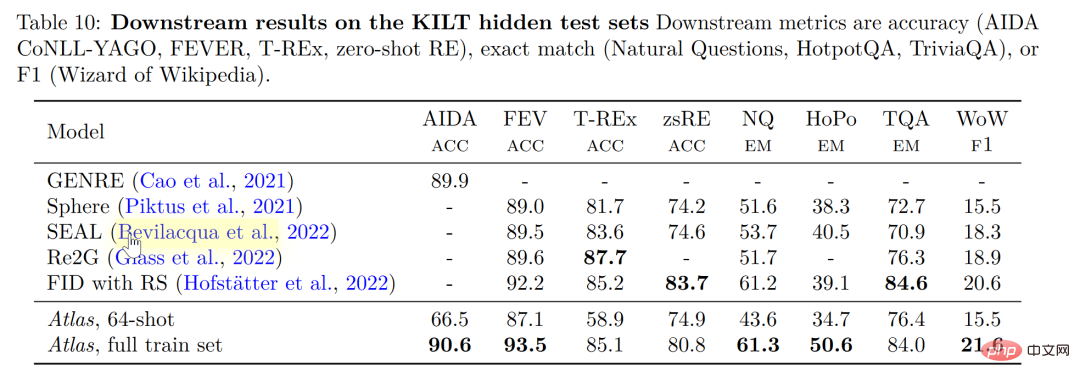
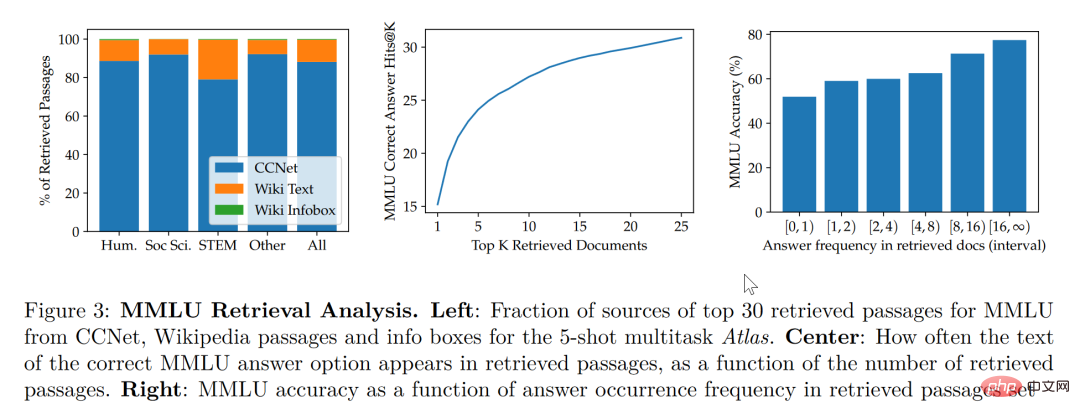
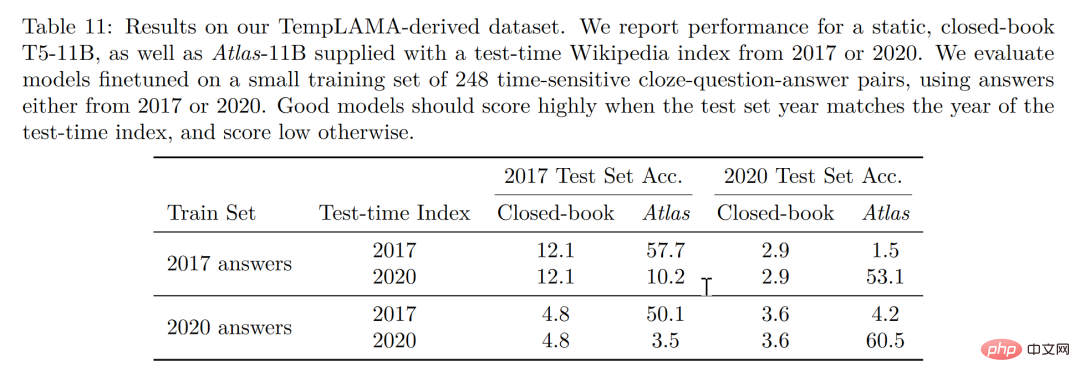
歸根結底,檢索增強模型的目標是期望模型不僅學會記憶數據,同時希望模型學會自己找到數據,這點特性在許多知識密集型的任務中具有極大的優勢並且檢索增強模型也在這些領域取得了巨大的成功,但是檢索增強是否適用於小樣本學習卻不得而知。回到 Meta AI 的這篇論文,便成功試驗了檢索增強在小樣本學習中的應用,Atlas 便應運而生。 #Atlas 有兩個子模型,一個檢索器與一個語言模型。當面對一個任務時,Atlas 依據輸入的問題使用檢索器從大量語料中生成出最相關的top-k 個文檔,之後將這些文檔與問題query 一同放入語言模型之中,進而產生出所需的輸出。 Atlas 模型的基本訓練策略在於,將檢索器與語言模型使用相同損失函數共同訓練。檢索器與語言模型都基於預先訓練的Transformer 網絡,其中: 值得注意的是,作者對比試驗了四種損失函數以及不做檢索器與語言模型聯合訓練的情況,結果如下圖: 可以看出,在小樣本環境下,使用聯合訓練的方法所得到的正確率顯著高於不使用聯合訓練的正確率,因此,作者得出結論,檢索器與語言模型的這種共同訓練是Atlas 獲得小樣本學習能力的關鍵。 在大規模多任務語言理解任務(MMLU) 中,對比其他模型,Atlas 在參數量只有11B 的情況下,具有比15 倍於Atlas 參數量的GPT-3 更好的正確率,在引入多任務訓練後,在5-shot 測試上正確率甚至逼近了25 倍於Atlas 參數量的Gopher。 在開放域問答的兩個測試資料-NaturalQuestions 以及TriviaQA 中,對比了Atlas 與其他模型在64 個例子上的表現以及全訓練集上的表現如下圖所示,Atlas 在64-shot 中取得了新的SOTA,在TrivuaQA 上僅用64 個數據便實現了84.7% 的準確率。 在事實查核任務(FEVER)中,Atlas 在小樣本的表現也顯著優於參數量十倍於Atlas 的Gopher 與ProoFVer,在15-shot 的任務中,超出了Gopher 5.1%。 在自家發布的知識密集型自然語言處理任務基準KILT 上,在某些任務裡使用64 個樣本訓練的Atlas 的正確率甚至接近了其他模型使用全樣本所獲得的正確率,在使用全樣本訓練Atlas 後,Atlas 在五個資料集上都刷新了SOTA。 根据这篇论文的研究,检索增强模型不仅兼顾了更小与更好,同时在可解释性方面也拥有其他大模型不具备的显著优势。大模型的黑箱属性,使得研究者很难以利用大模型对模型运行机理进行分析,而检索增强模型可以直接提取其检索到的文档,从而通过分析检索器所检索出的文章,可以获得对 Atlas 工作更好的理解。譬如,论文发现,在抽象代数领域,模型的语料有 73% 借助了维基百科,而在道德相关领域,检索器提取的文档只有3%来源于维基百科,这一点与人类的直觉相符合。如下图左边的统计图,尽管模型更偏好使用 CCNet 的数据,但是在更注重公式与推理的 STEM 领域,维基百科文章的使用率明显上升。 而根据上图右边的统计图作者发现,随着检索出的文章中包含正确答案的次数的升高,模型准确率也不断上升,在文章不包含答案时正确只有 55%,而在答案被提到超过 15 次时,正确率来到了 77%。除此之外,在人为检查了 50 个检索器检索出的文档时,发现其中有 44% 均包含有用的背景信息,显然,这些包含问题背景信息的资料可以为研究者扩展阅读提供很大的帮助。 一般而言,我们往往会认为大模型存在训练数据“泄露”的风险,即有时大模型针对测试问题的回答并非基于模型的学习能力而是基于大模型的记忆能力,也就是说在大模型学习的大量语料中泄露了测试问题的答案,而在这篇论文中,作者通过人为剔除可能会发生泄露的语料信息后,模型正确率从56.4%下降到了55.8%,仅仅下降0.6%,可以看出检索增强的方法可以有效的规避模型作弊的风险。 最后,可更新性也是检索增强模型的一大独特优势,检索增强模型可以无需重新训练而只需更新或替换其依托的语料库实现模型的时时更新。作者通过构造时序数据集,如下图所示,在不更新 Atlas 参数的情况下,仅仅通过使用 2020 年的语料库 Atlas 便实现了 53.1% 的正确率,而有趣的是即使是用2020年的数据微调 T5 ,T5 也没有很好的表现,作者认为,原因很大程度上是由于 T5 的预训练使用的数据是 2020 年以前的数据。 我们可以想象有三个学生,一个学生解题只靠死记硬背,一道数学题可以把答案分毫不差的背诵下来,一个学生就靠查书,遇到不会先去翻找资料找到最合适的再一一作答,而最后一个学生则天资聪明,简单的学习一些教科书上的知识便可以自信去考场挥毫泼墨指点江山。 显然,小样本学习的理想是成为第三个学生,而现实却很可能停留在了第一个学生之上。大模型很好用,但“大”绝不是模型最终的目的,回到小样本学习期望模型具有与人类相似的推理判断与举一反三能力的初心,那么我们可以看到,这篇论文是换个角度也好是前进一步也罢,至少是让那个学生可以轻松一点不往脑袋里装那么多可能大量冗余的知识,而可以拎起一本教科书轻装上阵,或许哪怕允许学生开卷考试带着教科书不断翻查,也会比学生生搬硬套死记硬背更接近智能吧!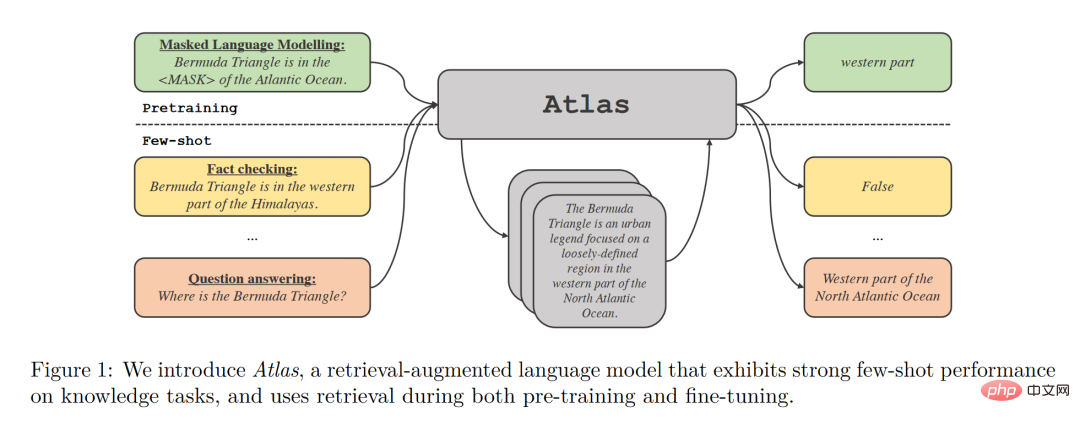
模型結構

實驗結果

可解释性、可控性、可更新性
结论

以上是完爆GPT3、GooglePaLM!檢索增強模型Atlas刷新知識類小樣本任務SOTA的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 排名前十的虛擬幣交易app有哪 最新數字貨幣交易所排行榜
Apr 28, 2025 pm 08:03 PM
排名前十的虛擬幣交易app有哪 最新數字貨幣交易所排行榜
Apr 28, 2025 pm 08:03 PM
Binance、OKX、gate.io等十大數字貨幣交易所完善系統、高效多元化交易和嚴密安全措施嚴重推崇。
 全球幣圈十大交易所有哪些 排名前十的貨幣交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球幣圈十大交易所有哪些 排名前十的貨幣交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球十大加密貨幣交易平台包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、KuCoin和Poloniex,均提供多種交易方式和強大的安全措施。
 靠譜的數字貨幣交易平台推薦 全球十大數字貨幣交易所排行榜2025
Apr 28, 2025 pm 04:30 PM
靠譜的數字貨幣交易平台推薦 全球十大數字貨幣交易所排行榜2025
Apr 28, 2025 pm 04:30 PM
靠谱的数字货币交易平台推荐:1. OKX,2. Binance,3. Coinbase,4. Kraken,5. Huobi,6. KuCoin,7. Bitfinex,8. Gemini,9. Bitstamp,10. Poloniex,这些平台均以其安全性、用户体验和多样化的功能著称,适合不同层次的用户进行数字货币交易
 排名靠前的貨幣交易平台有哪些 最新虛擬幣交易所排名榜前10
Apr 28, 2025 pm 08:06 PM
排名靠前的貨幣交易平台有哪些 最新虛擬幣交易所排名榜前10
Apr 28, 2025 pm 08:06 PM
目前排名前十的虛擬幣交易所:1.幣安,2. OKX,3. Gate.io,4。幣庫,5。海妖,6。火幣全球站,7.拜比特,8.庫幣,9.比特幣,10。比特戳。
 解密Gate.io戰略升級:MeMebox 2.0如何重新定義加密資產管理?
Apr 28, 2025 pm 03:33 PM
解密Gate.io戰略升級:MeMebox 2.0如何重新定義加密資產管理?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0通過創新架構和性能突破重新定義了加密資產管理。 1) 它解決了資產孤島、收益衰減和安全與便利悖論三大痛點。 2) 通過智能資產樞紐、動態風險管理和收益增強引擎,提升了跨鏈轉賬速度、平均收益率和安全事件響應速度。 3) 為用戶提供資產可視化、策略自動化和治理一體化,實現了用戶價值重構。 4) 通過生態協同和合規化創新,增強了平台的整體效能。 5) 未來將推出智能合約保險池、預測市場集成和AI驅動資產配置,繼續引領行業發展。
 比特幣值多少美金
Apr 28, 2025 pm 07:42 PM
比特幣值多少美金
Apr 28, 2025 pm 07:42 PM
比特幣的價格在20,000到30,000美元之間。 1. 比特幣自2009年以來價格波動劇烈,2017年達到近20,000美元,2021年達到近60,000美元。 2. 價格受市場需求、供應量、宏觀經濟環境等因素影響。 3. 通過交易所、移動應用和網站可獲取實時價格。 4. 比特幣價格波動性大,受市場情緒和外部因素驅動。 5. 與傳統金融市場有一定關係,受全球股市、美元強弱等影響。 6. 長期趨勢看漲,但需謹慎評估風險。
 全球幣圈十大交易所有哪些 排名前十的貨幣交易平台2025
Apr 28, 2025 pm 08:12 PM
全球幣圈十大交易所有哪些 排名前十的貨幣交易平台2025
Apr 28, 2025 pm 08:12 PM
2025年全球十大加密貨幣交易所包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi、Bitfinex、KuCoin、Bittrex和Poloniex,均以高交易量和安全性著稱。
 C 中的chrono庫如何使用?
Apr 28, 2025 pm 10:18 PM
C 中的chrono庫如何使用?
Apr 28, 2025 pm 10:18 PM
使用C 中的chrono庫可以讓你更加精確地控制時間和時間間隔,讓我們來探討一下這個庫的魅力所在吧。 C 的chrono庫是標準庫的一部分,它提供了一種現代化的方式來處理時間和時間間隔。對於那些曾經飽受time.h和ctime折磨的程序員來說,chrono無疑是一個福音。它不僅提高了代碼的可讀性和可維護性,還提供了更高的精度和靈活性。讓我們從基礎開始,chrono庫主要包括以下幾個關鍵組件:std::chrono::system_clock:表示系統時鐘,用於獲取當前時間。 std::chron
