
通用智能需要解決多個領域的任務。人們認為強化學習演算法具有這種潛力,但它一直受到為新任務調整所需資源和知識的阻礙。在 DeepMind 的一項新研究中,研究人員展示了基於世界模型的通用可擴展的演算法 DreamerV3,它在具有固定超參數的廣泛領域中優於先前的方法。
DreamerV3 符合的領域包括連續和離散動作、視覺和低維輸入、2D 和 3D 世界、不同的資料量、獎勵頻率和獎勵等級。值得一提的是,DreamerV3 是第一個在沒有人類資料或主動教育的情況下從零開始在《我的世界》(Minecraft)中收集鑽石的演算法 。研究人員表示,這樣的通用演算法可以使強化學習廣泛應用,並有望擴展到硬決策問題。
鑽石是《我的世界》遊戲中最受歡迎的物品之一,它是遊戲中最稀有的物品之一,可被用來製作遊戲中絕大多數最強的工具、武器以及盔甲。因為只有在最深的岩層中才能找到鑽石,所以產量很低。
DreamerV3 是第一個在我的世界中收集鑽石的演算法,無需人工演示或手動製作課程。 該影片顯示了它收集的第一顆鑽石,發生在 30M 環境步數 / 17 天遊戲時間之內。
如果你對AI 玩我的世界沒有什麼概念,英偉達AI 科學家Jim Fan 表示,和AlphaGo 下圍棋比,我的世界任務數量是無限的,環境變化是無限的,知識也是有隱藏訊息的。
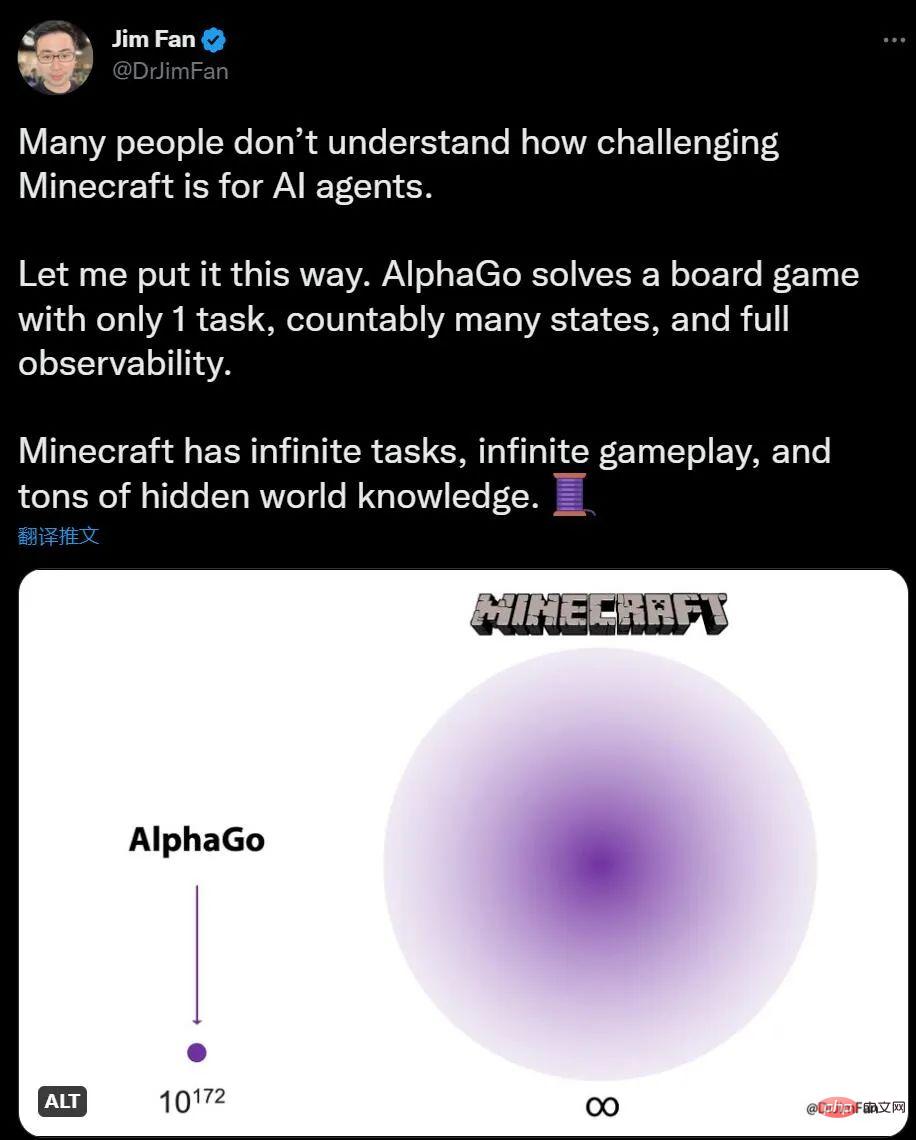
對人類來說,在我的世界裡探索和建構是有趣的事,圍棋則顯得有些複雜,對於AI 來說,情況剛好相反。 AlphaGo 在 6 年前擊敗了人類冠軍,但現在也沒有可以和我的世界人類高手媲美的演算法出現。
早在2019 年夏天,我的世界的開發公司就提出了「鑽石挑戰」,懸賞可以在遊戲裡找鑽石的AI 演算法,直到NeurIPS 2019 上,在提交的660 多件參賽作品中,沒有一個AI 能勝任這項任務。
但DreamerV3 的出現改變了這一現狀,鑽石是一項高度組合和長期的任務,需要復雜的探索和規劃,新演算法能在沒有任何人工數據輔助的情況下收集鑽石。或許效率還有很大改進空間,但 AI 智能體現在可以從頭開始學習收集鑽石這一事實本身,是一個重要的里程碑。
論文《Mastering Diverse Domains through World Models》:

論文連結:https://arxiv.org/abs/2301.04104v1
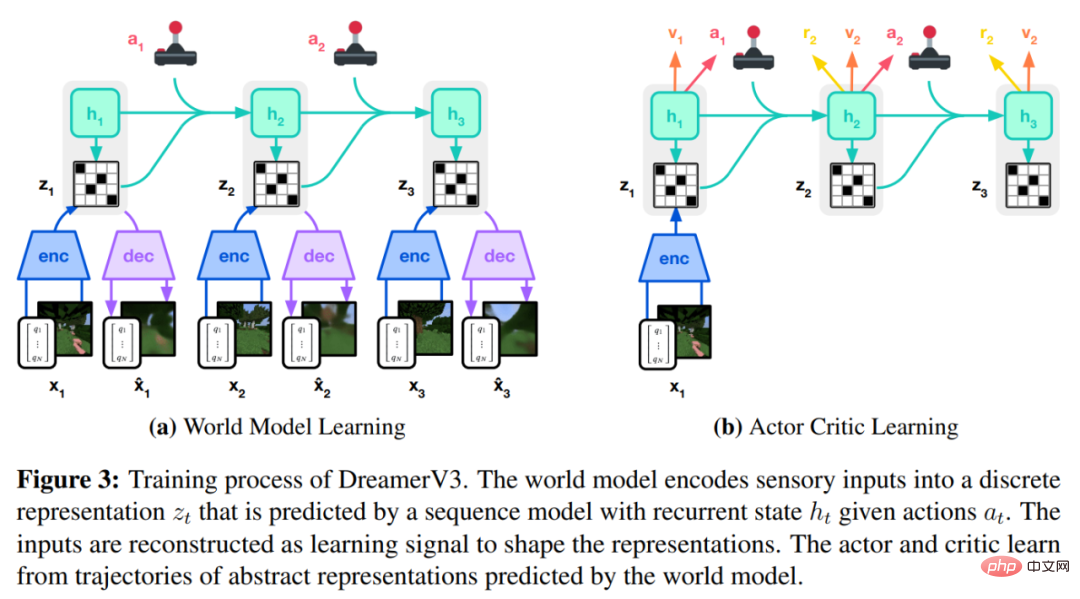
DreamerV3 演算法由三個神經網路組成,分別是世界模型(world model)、critic 和actor。這三個神經網路在不共享梯度的情況下根據回放經驗同時訓練,下圖 3(a)展示了世界模型學習,圖(b)展示了 Actor Critic 學習。
為了取得跨域成功,這些元件需要適應不同的訊號幅度,並在它們的目標中穩健地平衡項。這是具有挑戰性的,因為不僅針對同一領域內的相似任務,而且還要使用固定超參數跨不同領域進行學習。
DeepMind 首先解釋了用於預測未知數量級的簡單變換,然後介紹了世界模型、critic、actor 以及它們的穩健學習目標。結果發現,結合 KL 平衡和自由位可以使世界模型無需調整學習,並且在不誇大大小回報(small return)的情況下,縮小大回報實現了固定的策略熵正則化器。
Symlog 預測
重建輸入以及預測獎勵和價值具有挑戰性,因為它們的規模可能會因領域而異。使用平方損失預測大目標會導致發散,而絕對損失和 Huber 損失會使學習停滯。另一方面,基於運行統計資料的歸一化目標將非平穩性引入最佳化。因此,DeepMind 提出將 symlog 預測作為解決這個難題的簡單方法。
為此,具有輸入 x 和參數 θ 的神經網路 f (x, θ) 學習預測其目標 y 的變換版本。為了讀出該網路的預測 y^,DeepMind 使用了逆變換,如下公式(1)所示。
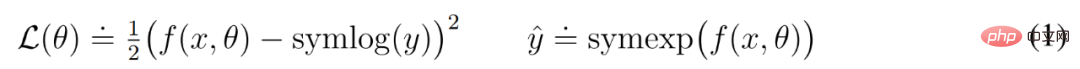
從下圖 4 可以看到,使用對數(logarithm)作為變換無法預測具有負值的目標。

因此,DeepMind 從雙對稱對數族中選擇一個函數,命名為 symlog 並作為變換,同時將 symexp 函數作為逆函數。
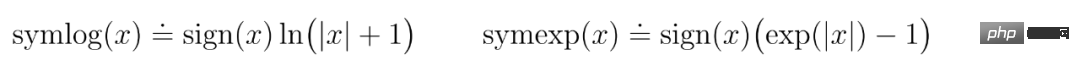
symlog 函數壓縮大的正值和負值的大小。 DreamerV3 在解碼器、獎勵預測器和 critic 中使用 symlog 預測,也使用 symlog 函數壓縮編碼器的輸入。
世界模型學習
世界模型透過自編碼學習感官輸入的緊湊表示,並透過預測未來的表示和潛在行為的獎勵來實現規劃。
如上圖 3 所示,DeepMind 將世界模型實作為循環狀態空間模型 (RSSM)。首先,編碼器將感官輸入 x_t 映射到隨機表示 z_t,然後具有循環狀態 h_t 的序列模型在給定過去動作 a_t−1 的情況下預測這些表示的序列。 h_t 和 z_t 的串聯形成模型狀態,從中預測獎勵 r_t 和 episode 連續標誌 c_t ∈ {0, 1} 並重建輸入以確保資訊表示,具體如下公式(3)所示。
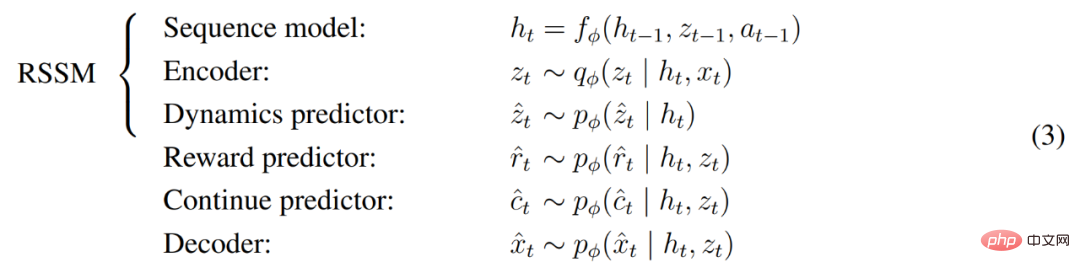
下圖 5 視覺化了 world world 的長期影片預測。編碼器和解碼器使用卷積神經網路 (CNN) 進行視覺輸入,使用多層感知器 (MLP) 進行低維輸入。動態、獎勵和持續預測器也是 MLPs,這些表示從 softmax 分佈的向量中取樣而來。 DeepMind 在取樣步驟中使用了直通梯度。
Actor Critic 學習
Actor Critic 神經網路完全從世界模型預測的抽象序列中學習行為。在環境互動期間,DeepMind 透過從 actor 網路中取樣來選擇動作,無需進行前瞻性規劃。
actor 和 critic 在模型狀態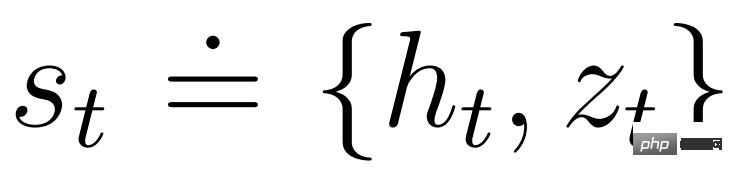 下運行,進而可以從世界模型學得的馬可夫表示中獲益。 actor 的目標是在每個模型狀態的折扣因子 γ = 0.997 時最大化預期回報
下運行,進而可以從世界模型學得的馬可夫表示中獲益。 actor 的目標是在每個模型狀態的折扣因子 γ = 0.997 時最大化預期回報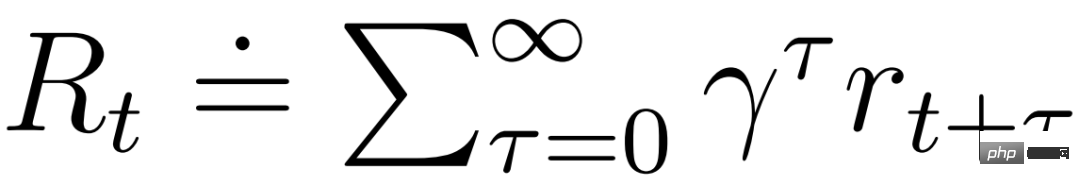 。為了考慮超出預測範圍 T = 16 的獎勵,critic 學習預測當前 actor 行為下每個狀態的報酬。
。為了考慮超出預測範圍 T = 16 的獎勵,critic 學習預測當前 actor 行為下每個狀態的報酬。
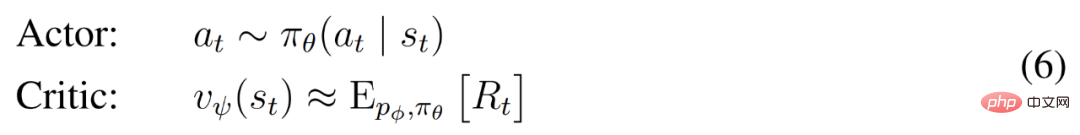
從重播輸入的表示開始,動態預測器和actor 產生一系列預期的模型狀態s_1:T 、動作a_1:T 、獎勵r_1:T 和連續標誌c_1:T 。為了估計超出預測範圍的獎勵的回報,DeepMind 計算了自舉的 λ 回報,它整合了預期回報和價值。
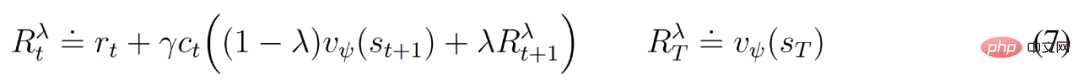
DeepMind 進行了廣泛的實證研究,以評估DreamerV3 在固定超參數下跨不同領域(超過150 個任務)的通用性和可擴展性,並與已有文獻中SOTA 方法進行比較。此外還將 DreamerV3 應用於具有挑戰性的電玩遊戲《我的世界》。
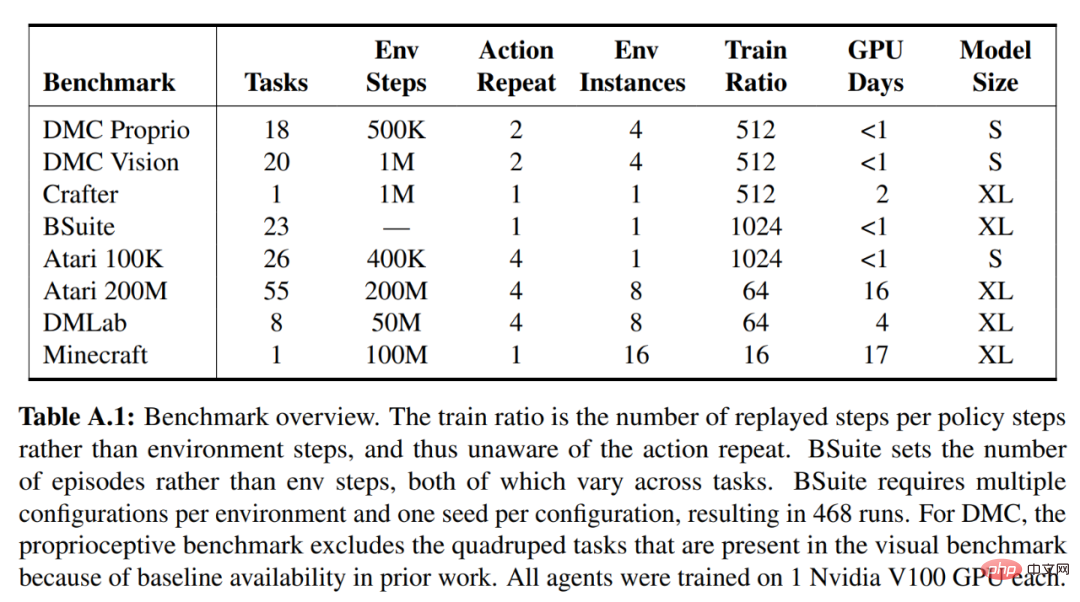
對於 DreamerV3,DeepMind 直接報告隨機訓練策略的效能,並避免使用確定性策略進行單獨評估運行,從而簡化了設定。所有的 DreamerV3 智能體均在一個 Nvidia V100 GPU 上進行訓練。下表 1 為基準概覽。
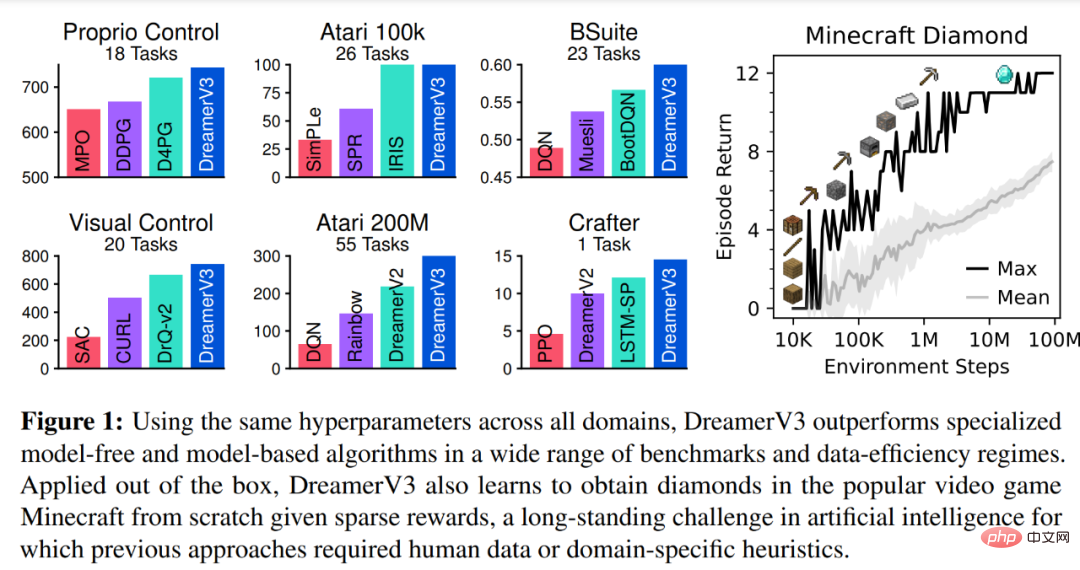
為了評估DreamerV3 的通用性,DeepMind 在七個領域進行了廣泛的實證評估,包括連續和離散動作、視覺和低維輸入、密集和稀疏獎勵、不同獎勵尺度、2D 和3D 世界以及程式生成。下圖 1 的結果發現,DreamerV3 在所有領域都實現了強大的效能,並在其中 4 個領域的表現優於所有先前的演算法,同時在所有基準測試中使用了固定超參數。
更多技術細節和實驗結果請參考原始論文。
以上是AI從零開始學會玩《我的世界》,DeepMind AI通用化取得突破的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















