

一塊GPU跑ChatGPT體量模型,AI繪圖又一神器ControlNet

目錄
- Transformer models: an introduction and catalog
- High-throughout Generative Inference of Large Language Models with a Single GPU
- Temporal Domain Generalization with Drift-Aware Dynamic Neural Networks
- Large-scale physically accurate modelling
- Large-scale physically accurate modelling Large-scale physically accurate modelling
- Large-scale physically accurate modelling
- Large-scale physically accurate modelling
- Large-scale physically accurate modelling of real proton exchange membrane fuel cell with deep learningA Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
Adding Conditional History from BERT to ChatGPT
Adding Conditional Control to Text-to-Image Diffusion Models- EVA3D: Compositional 3D Human Generation from 2D image Collections
- #ArXiv Weekly Radiostation: NLP、CV、ML 更多精選論文(附音訊)
#論文1:Transformer models: an introduction and catalog
作者:Xavier Amatriain
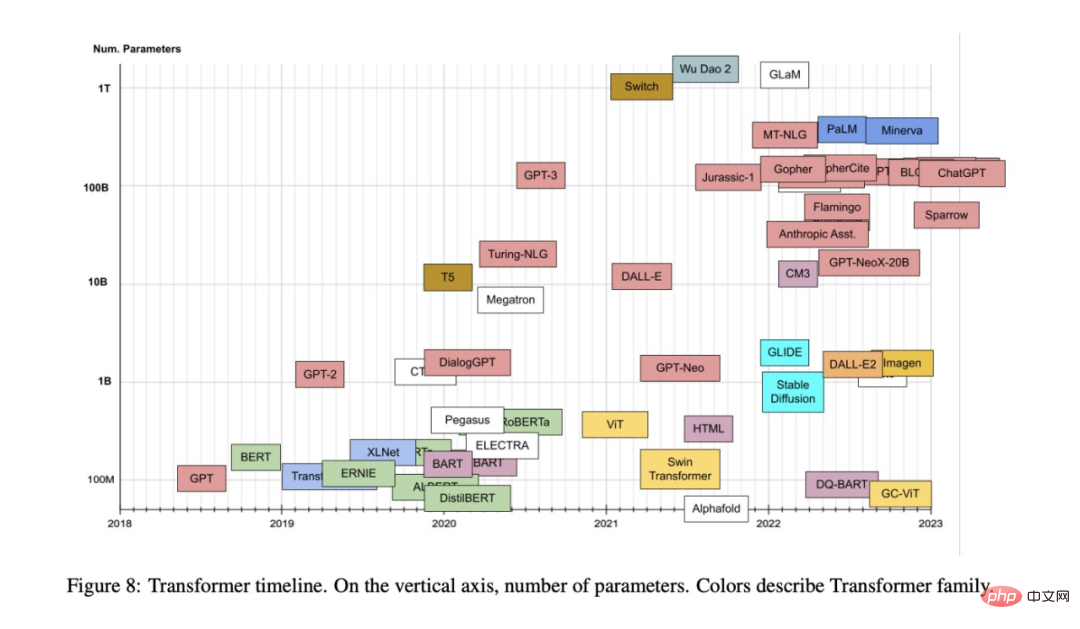
摘要:自2017 年提出至今,Transformer 模型已在自然語言處理、電腦視覺等其他領域展現了前所未有的實力,並引發了ChatGPT 這樣的技術突破,人們也提出了各種基於原始模型的變體。
由於學界和業界不斷提出基於 Transformer 注意力機制的新模型,我們有時很難對這個方向進行歸納總結。近日,領英 AI 產品策略負責人 Xavier Amatriain 的一篇綜述性文章或許可以幫助我們解決這個問題。- 推薦:本文的目標是為最受歡迎的Transformer 模型提供一個比較全面但簡單的目錄和分類,也介紹了Transformer 模型中最重要的面向和創新。
論文2:High-throughout Generative Inference of Large Language Models with a Single GPU
作者:Ying Sheng 等
論文網址:https://github.com/FMInference/FlexGen/blob/main/docs/paper.pdf
摘要:
- 傳統上,大語言模型(LLM)推理的高運算和記憶體需求使人們必須使用多個高階AI 加速器進行訓練。本研究探討如何將 LLM 推理的要求降低到一個消費級 GPU 並實現實用效能。 、
- 近日,來自史丹佛大學、UC Berkeley、蘇黎世聯邦理工學院、Yandex、莫斯科國立高等經濟學院、Meta、卡內基美隆大學等機構的新研究提出了FlexGen,這是一種用於運行有限GPU 記憶體的LLM 的高吞吐量生成引擎。下圖為FlexGen 的設計思路, 利用區塊調度來重複使用權重並將I/O 與計算重疊,如下圖(b) 所示,而其他基線系統使用低效的逐行調度,如下圖(a) 所示。
- 建議:跑 ChatGPT 體積模型,從此只需一塊 GPU:加速百倍的方法來了。
論文3:Temporal Domain Generalization with Drift-Aware Dynamic Neural Networks
#########作者:Guangji Bai 等##################論文網址:https://arxiv.org/pdf/2205.10664.pdf############# #########摘要:###在領域泛化(Domain Generalization, DG) 任務中,當領域的分佈隨環境連續變化時,如何準確地捕捉該變化以及其對模型的影響是非常重要但也極富挑戰的問題。 ######為此,來自Emory 大學的趙亮教授團隊,提出了一種基於貝葉斯理論的時間域泛化框架DRAIN,利用遞歸網絡學習時間維度領域分佈的漂移,同時通過動態神經網絡以及圖生成技術的結合最大化模型的表達能力,實現對未來未知領域上的模型泛化及預測。
本工作已入選 ICLR 2023 Oral (Top 5% among accepted papers)。如下為 DRAIN 總體框架示意圖。
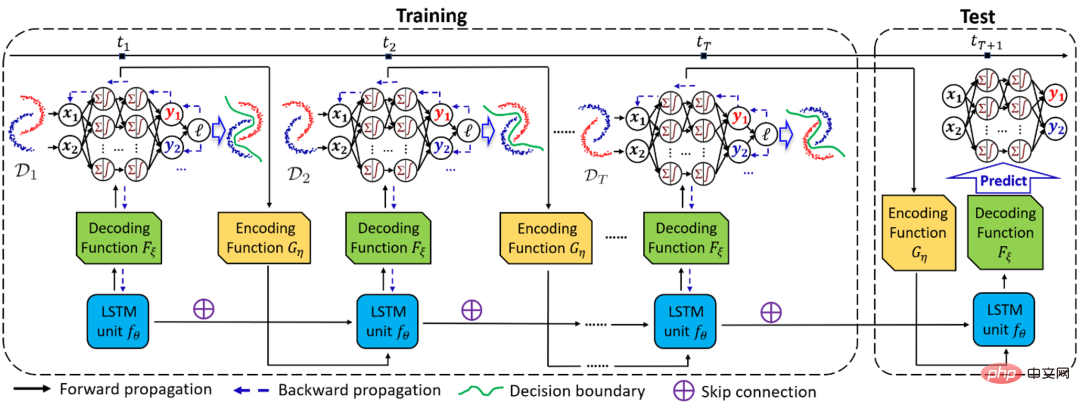
推薦:漂移感知動態神經網路加持,時間域泛化新框架遠超領域泛化& 適應方法。
論文4:Large-scale physically accurate modelling of real proton exchange membrane fuel cell with deep learning
作者:Ying Da Wang 等
- 論文網址:https://www.nature.com/articles/s41467-023-35973- 8
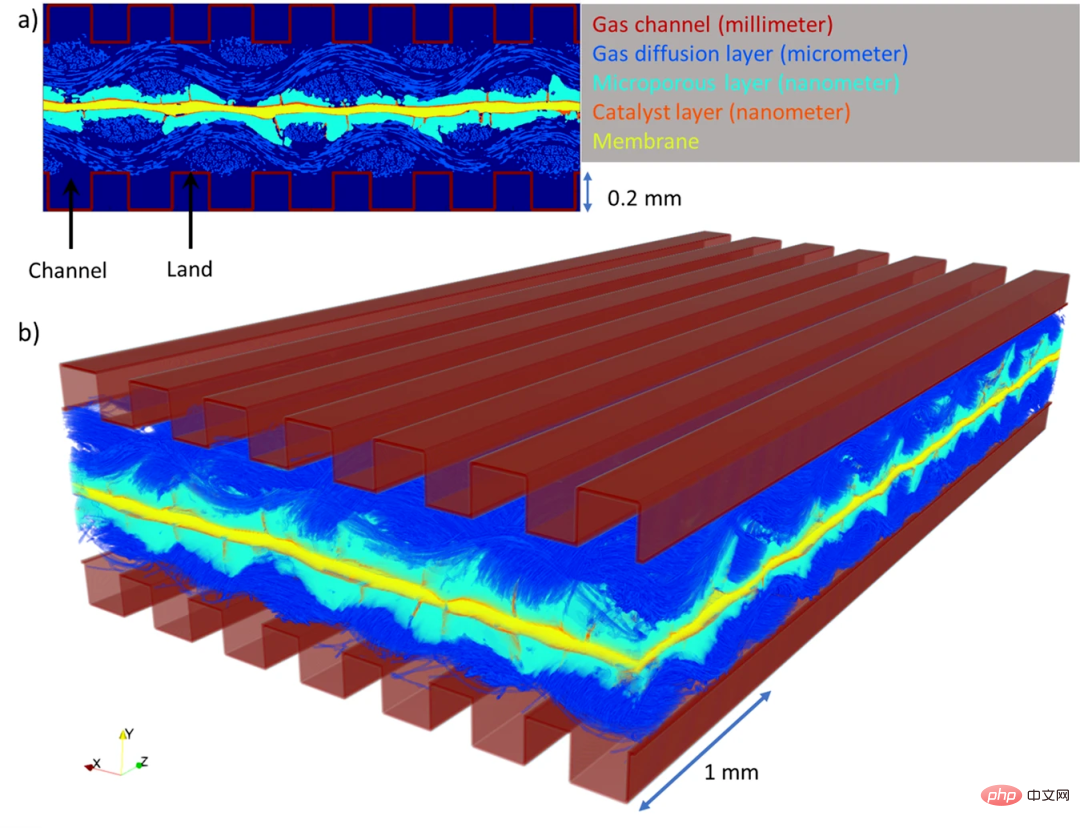
- #摘要:為了保障能源供應和應對氣候變化,人們的焦點從化石燃料轉向清潔和再生能源,氫以其高能量密度和清潔低碳的能源屬性可以在能源轉型變革中發揮重要作用。氫燃料電池,尤其是質子交換膜燃料電池 (PEMFC),由於高能量轉換效率和零排放操作,成為這場綠色革命的關鍵。 PEMFC 透過電化學過程將氫轉化為電能,反應的唯一副產品是純水。然而,如果水無法正常流出電池,隨後「淹沒」系統,PEMFC 可能會變得低效。到目前為止,由於燃料電池體積非常小且結構非常複雜,工程師很難理解燃料電池內部排水或積水的精確方法。
近日,雪梨新南威爾斯大學的研究團隊開發了一種深度學習演算法(DualEDSR),來提高對PEMFC 內部情況的理解,可以從較低解析度的X射線微電腦斷層掃描中產生高解析度的建模影像。該製程已經在單一氫燃料電池上進行了測試,可以對其內部進行精確建模,並有可能提高其效率。下圖展示了本研究中產生的 PEMFC 域。
建議:深度學習對燃料電池內部進行大規模物理精確建模,助力電池性能提升。
- 論文5:A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
- #作者:Ce Zhou 等
#摘要:
這篇近百頁的綜述梳理了預訓練基礎模型的演變史,讓我們看到ChatGPT 是怎麼一步一步走向成功的。 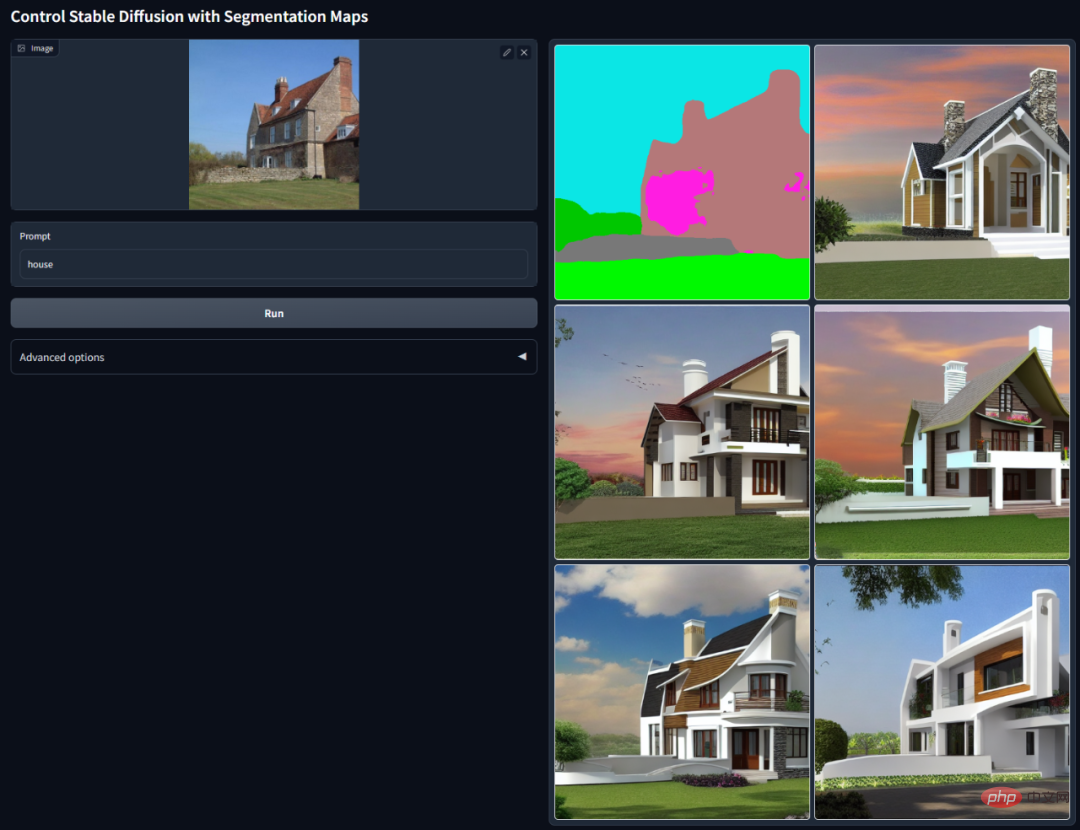
推薦:AI 降維打擊人類畫家,文生圖引入 ControlNet,深度、邊緣資訊全能復用。
論文7:EVA3D: Compositional 3D Human Generation from 2D image Collections
- 作者:Fangzhou Hong 等
- 論文網址:https://arxiv.org/abs/2210.04888
#摘要:在ICLR 2023 上,南洋理工大學- 商湯科技聯合研究中心S-Lab 團隊提出了首個從二維影像集合中學習高解析度三維人體生成的方法EVA3D。由於 NeRF 提供的可微渲染,近期的三維生成模型已經在靜止物體上達到了令人驚豔的效果。但是在人體這種更複雜且可形變的類別上,三維生成依舊有很大的挑戰。
本文提出了一個高效的組合的人體 NeRF 表達,實現了高分辨率(512x256)的三維人體生成,並且沒有使用超分模型。 EVA3D 在四個大型人體資料集上都大幅超越了現有方案,程式碼已開源。

推薦:ICLR 2023 Spotlight | 2D 影像腦補 3D 人體,衣服隨便搭,還能改動作。
ArXiv Weekly Radiostation
機器之心聯合由楚航、羅若天、梅洪源發起的ArXiv Weekly Radiostation,在7 Papers 的基礎上,精選本週更多重要論文,包括NLP、CV、ML領域各10篇精選,並提供音頻形式的論文摘要簡介,詳情如下:
7 NLP Papers
本週10 篇NLP 精選論文是:
1. Active Prompting with Chain- of-Thought for Large Language Models. (from Tong Zhang)
2. Prosodic features improve sentence segmentation and parsing. (from Mark Steedman)
3. ProsAudit, a prosodic benchmark for self-supervised speech models. (from Emmanuel Dupoux)
##4. Exploring Social Media for Early Detection of Depression in COVID-19 Patients. (來自 Jie Yang)
5. Federated Nearest Neighbor Machine Translation. (from Enhong Chen)
6. SPINDLE: Spinning Raw Text into Lambda Terms with Graph Attention. (from Michael Moortgat)
#7. A Neural Span-Based Continual Named Entity Recognition Model. (from Qingcai Chen)
################################### #####10 CV Papers######################本週10 篇CV 精選論文是:########### ##1. MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes. (from Richard Szeliski, Andreas Geiger)############2. Designing an Encoder for Fast Personalization of Text-to-Image Models. (from Daniel Cohen-Or)#############3. Teaching CLIP to Count to Ten. (from Michal Irani)########### ##4. Evaluating the Efficacy of Skincare Product: A Realistic Short-Term Facial Pore Simulation. (from Weisi Lin)############5. Real-Time Damage Detection in Fiber Lifting Ropes Using Convolution#####5. Real-Time Damage Detection in Fiber Lifting Ropes Using Convolutional Neural Networks. (from Moncef Gabbouj)############6. Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement. (from Chen Change Loy)#######
7。用於零樣本文字驅動影像編輯的區域感知擴散。 (出自徐長生)
8.用於開放詞彙語意分割的側邊適配器網路。 (白向)
9. VoxFormer:用於基於相機的 3D 語意場景完成的稀疏體素轉換器。 (取自 Sanja Fidler)
10。透過物件動力學和互動的解耦進行以物件為中心的視訊預測。 (取自 Sven Behnke)
##10 ML 論文
# #本週第10 篇ML 精選論文是:1. normflows:用於標準化流程的 PyTorch 套件。 (出自 Bernhard Schölkopf)
2。可解釋的多智能體強化學習的概念學習。 (來自卡蒂亞·西卡拉)
3。隨意的老師都是好老師。 (來自托馬斯·霍夫曼)
4。使用人類反饋對齊文字到圖像模型。 (取自 Craig Bouutilier、Pieter Abbeel)
5。改變是困難的:仔細觀察亞群轉變。 (來自迪娜·卡塔比)
6。 AlpaServe:用於深度學習服務的模型平行統計復用。 (來自陳志峰)
7.結構化行動空間的多元政策優化。 (摘自查宏遠)
8.混合性的幾何。 (來自羅伯特·C·威廉森)
#9。深度學習能學會抽象嗎?系統的探索框架。 (出自南寧鄭)
10.順序反事實風險最小化。 (朱利安·邁拉爾)
以上是一塊GPU跑ChatGPT體量模型,AI繪圖又一神器ControlNet的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 C 中的chrono庫如何使用?
Apr 28, 2025 pm 10:18 PM
C 中的chrono庫如何使用?
Apr 28, 2025 pm 10:18 PM
使用C 中的chrono庫可以讓你更加精確地控制時間和時間間隔,讓我們來探討一下這個庫的魅力所在吧。 C 的chrono庫是標準庫的一部分,它提供了一種現代化的方式來處理時間和時間間隔。對於那些曾經飽受time.h和ctime折磨的程序員來說,chrono無疑是一個福音。它不僅提高了代碼的可讀性和可維護性,還提供了更高的精度和靈活性。讓我們從基礎開始,chrono庫主要包括以下幾個關鍵組件:std::chrono::system_clock:表示系統時鐘,用於獲取當前時間。 std::chron
 怎樣在C 中測量線程性能?
Apr 28, 2025 pm 10:21 PM
怎樣在C 中測量線程性能?
Apr 28, 2025 pm 10:21 PM
在C 中測量線程性能可以使用標準庫中的計時工具、性能分析工具和自定義計時器。 1.使用庫測量執行時間。 2.使用gprof進行性能分析,步驟包括編譯時添加-pg選項、運行程序生成gmon.out文件、生成性能報告。 3.使用Valgrind的Callgrind模塊進行更詳細的分析,步驟包括運行程序生成callgrind.out文件、使用kcachegrind查看結果。 4.自定義計時器可靈活測量特定代碼段的執行時間。這些方法幫助全面了解線程性能,並優化代碼。
 解密Gate.io戰略升級:MeMebox 2.0如何重新定義加密資產管理?
Apr 28, 2025 pm 03:33 PM
解密Gate.io戰略升級:MeMebox 2.0如何重新定義加密資產管理?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0通過創新架構和性能突破重新定義了加密資產管理。 1) 它解決了資產孤島、收益衰減和安全與便利悖論三大痛點。 2) 通過智能資產樞紐、動態風險管理和收益增強引擎,提升了跨鏈轉賬速度、平均收益率和安全事件響應速度。 3) 為用戶提供資產可視化、策略自動化和治理一體化,實現了用戶價值重構。 4) 通過生態協同和合規化創新,增強了平台的整體效能。 5) 未來將推出智能合約保險池、預測市場集成和AI驅動資產配置,繼續引領行業發展。
 靠譜的數字貨幣交易平台推薦 全球十大數字貨幣交易所排行榜2025
Apr 28, 2025 pm 04:30 PM
靠譜的數字貨幣交易平台推薦 全球十大數字貨幣交易所排行榜2025
Apr 28, 2025 pm 04:30 PM
靠谱的数字货币交易平台推荐:1. OKX,2. Binance,3. Coinbase,4. Kraken,5. Huobi,6. KuCoin,7. Bitfinex,8. Gemini,9. Bitstamp,10. Poloniex,这些平台均以其安全性、用户体验和多样化的功能著称,适合不同层次的用户进行数字货币交易
 全球幣圈十大交易所有哪些 排名前十的貨幣交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球幣圈十大交易所有哪些 排名前十的貨幣交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球十大加密貨幣交易平台包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、KuCoin和Poloniex,均提供多種交易方式和強大的安全措施。
 排名前十的虛擬幣交易app有哪 最新數字貨幣交易所排行榜
Apr 28, 2025 pm 08:03 PM
排名前十的虛擬幣交易app有哪 最新數字貨幣交易所排行榜
Apr 28, 2025 pm 08:03 PM
Binance、OKX、gate.io等十大數字貨幣交易所完善系統、高效多元化交易和嚴密安全措施嚴重推崇。
 比特幣值多少美金
Apr 28, 2025 pm 07:42 PM
比特幣值多少美金
Apr 28, 2025 pm 07:42 PM
比特幣的價格在20,000到30,000美元之間。 1. 比特幣自2009年以來價格波動劇烈,2017年達到近20,000美元,2021年達到近60,000美元。 2. 價格受市場需求、供應量、宏觀經濟環境等因素影響。 3. 通過交易所、移動應用和網站可獲取實時價格。 4. 比特幣價格波動性大,受市場情緒和外部因素驅動。 5. 與傳統金融市場有一定關係,受全球股市、美元強弱等影響。 6. 長期趨勢看漲,但需謹慎評估風險。
 C 中的字符串流如何使用?
Apr 28, 2025 pm 09:12 PM
C 中的字符串流如何使用?
Apr 28, 2025 pm 09:12 PM
C 中使用字符串流的主要步驟和注意事項如下:1.創建輸出字符串流並轉換數據,如將整數轉換為字符串。 2.應用於復雜數據結構的序列化,如將vector轉換為字符串。 3.注意性能問題,避免在處理大量數據時頻繁使用字符串流,可考慮使用std::string的append方法。 4.注意內存管理,避免頻繁創建和銷毀字符串流對象,可以重用或使用std::stringstream。
