
現在Google、OpenAI等大廠們的以文生圖模型,是趣味新聞報道者的衣食父母、梗圖愛好者的久旱甘霖。 輸行字就能產生各種或唯美或搞笑的圖片,不用很累很麻煩,就能很吸引人關注。 所以DALL·E系列和Imagen們,具有衣食父母和久旱甘霖的必備屬性:可獲取程度有限,不是隨時無限派發的福利。 2022年6月中,Hugging Face公司向全網所有用戶,免費完全公開了易用簡潔版的DALL·E接口:DALL·E Mini,不出意料地在各種社交媒體網站又掀起了一波大創作風潮。

現在各種社群媒體上紛紛有人表示:玩DALL·E Mini一時爽,一直玩一直爽,根本停不下來怎麼辦。 就像「踩滑板的便便」,摩擦摩擦,似魔鬼的步伐。
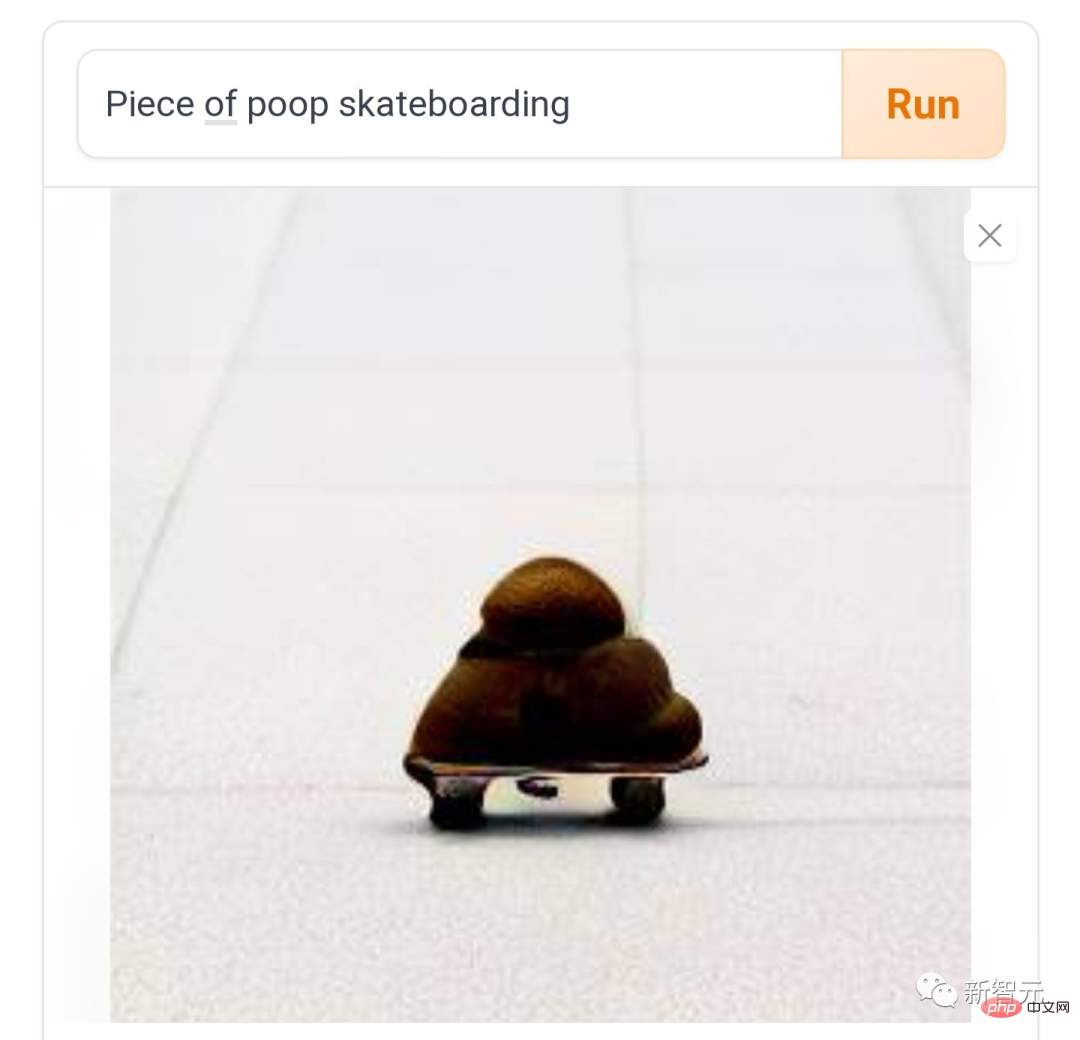
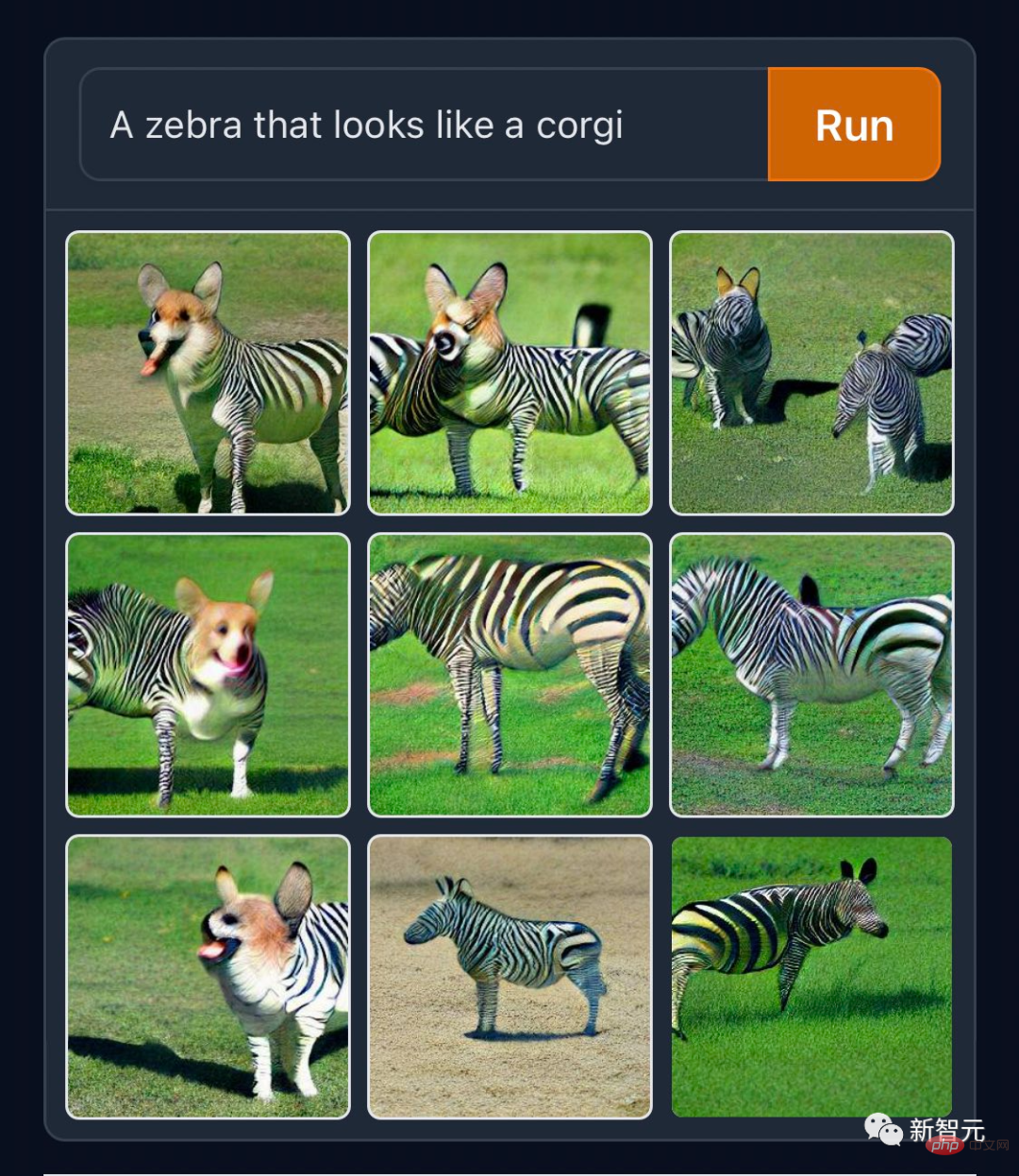
有人愛做「正常點的創作」,例如打破物種界線的「柯基版斑馬」。
古代公務員要是有這些素材,也不用辛苦地把非洲長頸鹿發明成神獸麒麟了。 GitHub的碼農們本色當行,在官推上發了一張「松鼠用電腦程式」的生成作品。

「哥吉拉的法庭場素描」,我不得不說,真的很像英語國家報紙上,不對外開放的案件審判報道素描風格。

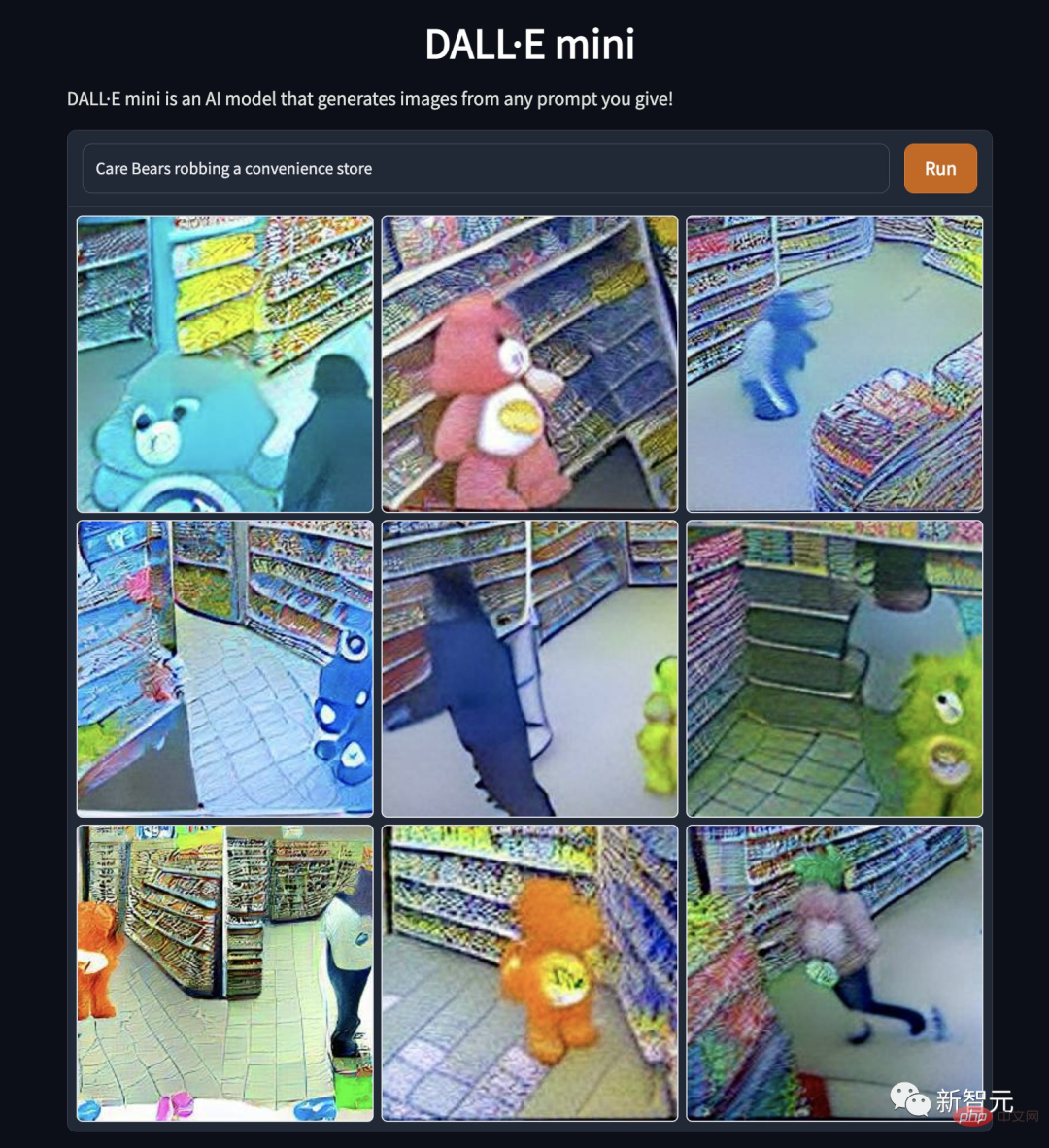
#「愛心熊搶劫便利商店」。卡通偶像折墮如此為哪般,究竟是熊性的扭曲,還是道德的淪喪…
##除此之外,DALL·E Mini生成「神獸在野地小徑上散步被抓拍」的圖像也有突出成就。 這是「小恐龍野地小徑上散步,被攝影機抓拍到」。

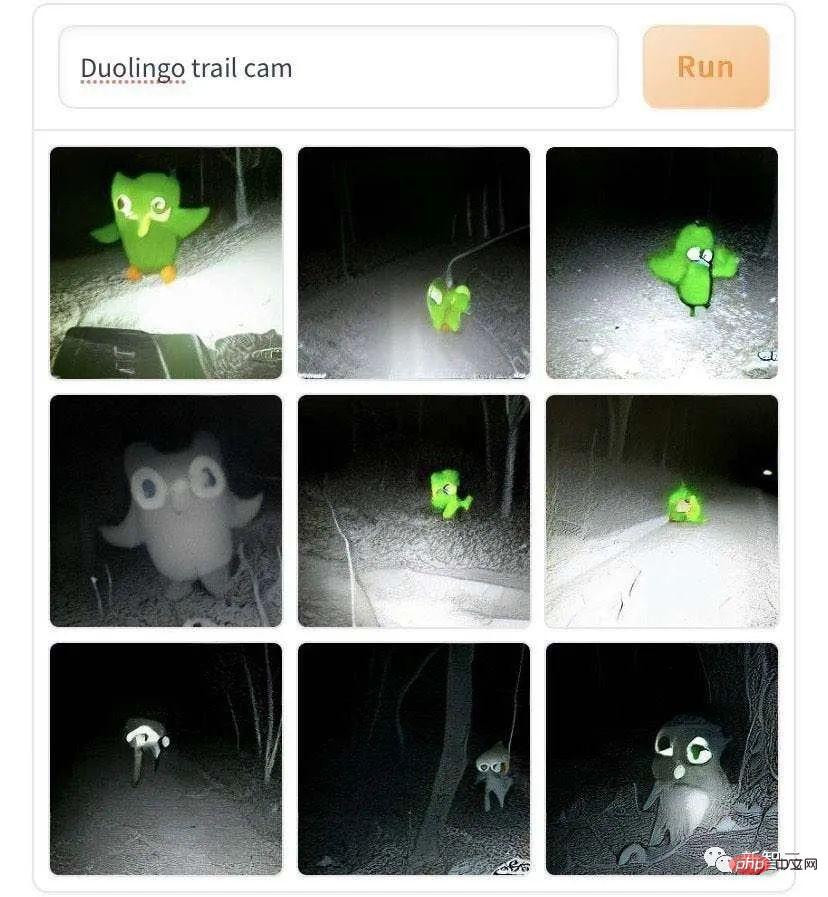
#這是「多鄰國鸚鵡商標野地小徑上散步,被攝影機抓拍到」。
#DALL·E Mini生成的這些神獸散步圖,背影都好孤獨和淒涼。不過這可能是AI模擬的微光攝影效果。 編輯部裡的大家也仿了一下:「草泥馬上路散步」,調性就陽光開朗了很多。
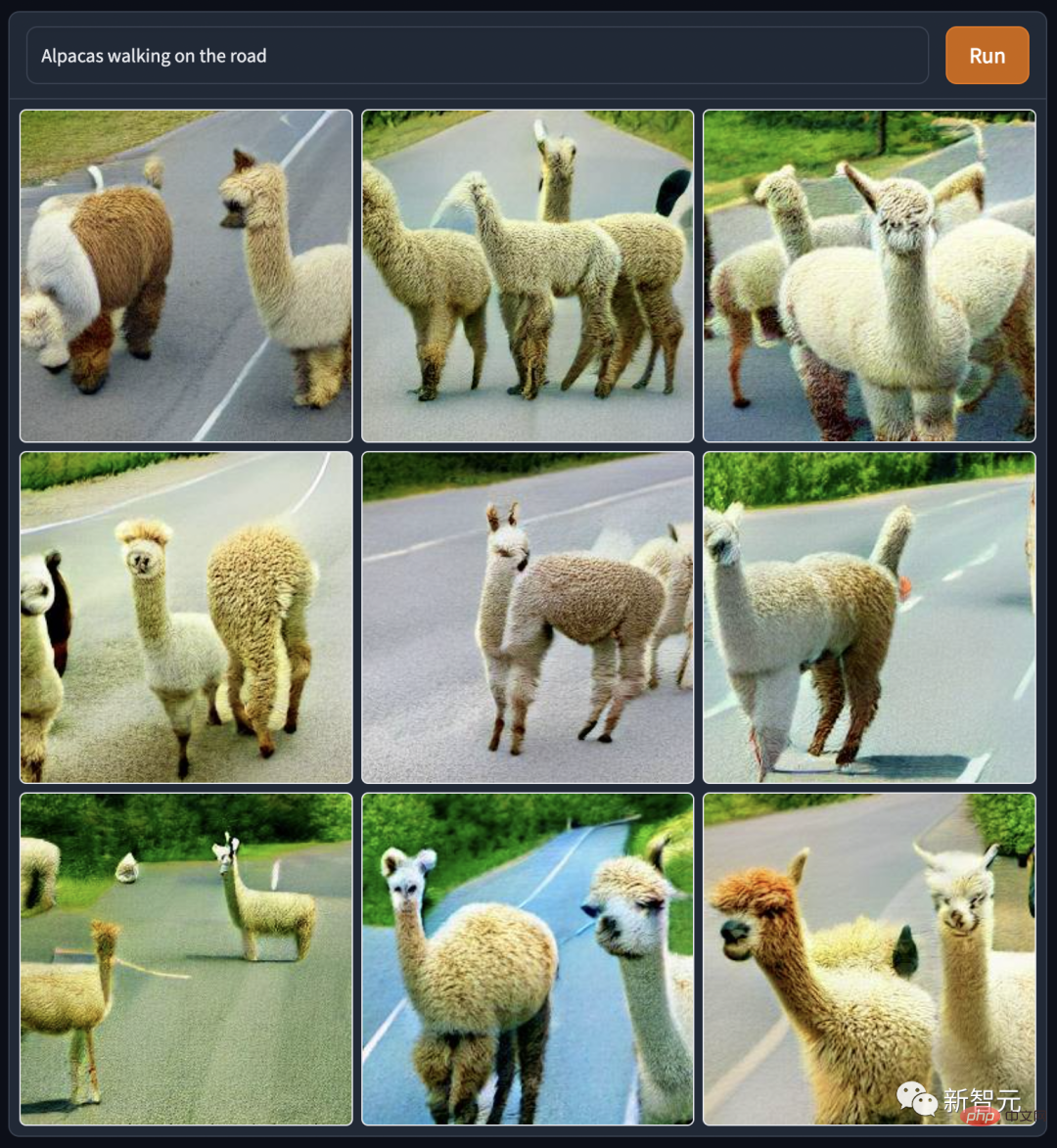
DALL·E Mini產生的神人圖,不比神獸圖效果差。 例如這張「耶穌火熱霹靂舞」,以前真的不知道祂老人家身體柔韌度這麼好來著,看來各種健身網站上的「和主一起做拉伸操」廣告是有所本的。
#還有這張「彩色玻璃上的饒舌歌手狗爺”,是不是真的兼具教堂聖像窗格和印象派畫作的風格。

#用DALL·E Mini來惡搞影視界角色,現在也蔚為風尚。 以下是來自星戰宇宙的「R2D2受洗」。可能星戰宇宙的物理和化學定律與現實世界有差異,機器人過水後既不漏電也不生鏽。

同樣來自星際大戰宇宙的「達斯維達鑿冰捕魚」 達斯維達老師真是好慘。被尊師砍到岩漿裡泡火山澡、成了殘疾人之後被親身兒子追斬,殘障人士帶著呼吸機熟練掌握原力後,淪落到地球跟愛斯基摩人搶生意……
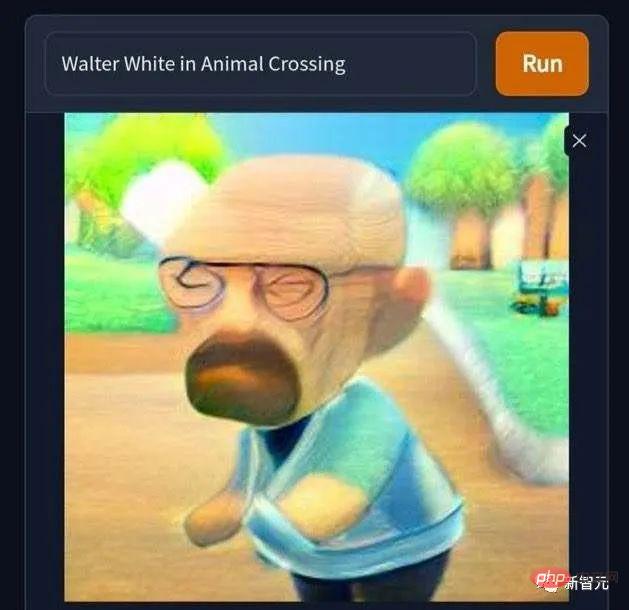
還有這張「沃特懷特誤入動物森友會世界」,禿頭孤寡末路毒梟突然就萌起來了。 可惜任天堂沒有在2000年代真的推出動森,不然老白會發現在動森裡搞虛擬交易賺錢,比辛苦苦搞藍色冰狀物實體商品養家省心省事得多。 讓我們高唱一句「拒絕黃~拒絕毒~拒絕黃賭毒~」。
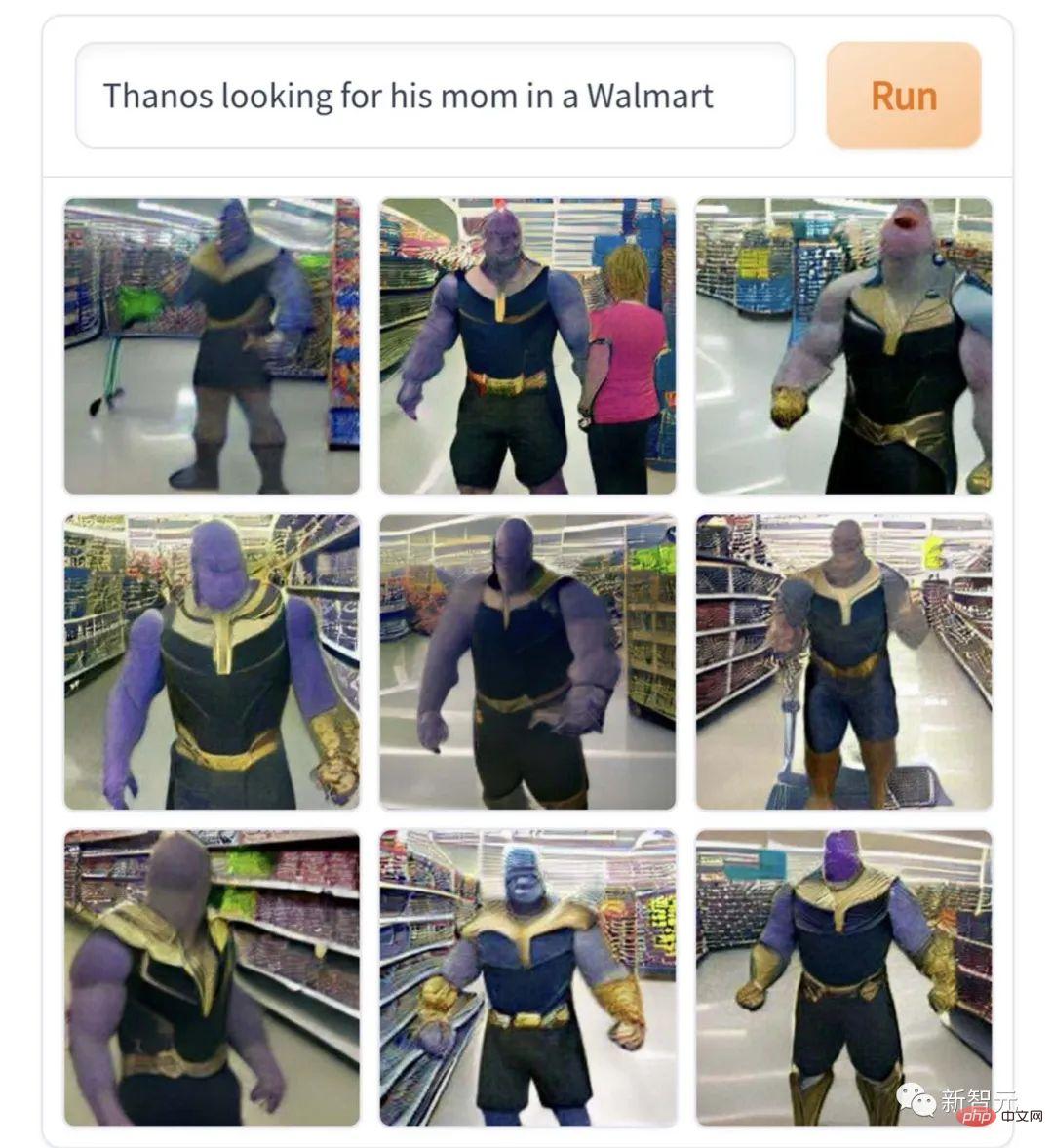
這張「薩諾斯在超市找媽媽」,真是很符合人物角色的內核,非常戲劇專業的本行解讀。 不爽了就要搞種族屠殺、一言不合就要毀滅宇宙,這就是找不到媽媽就撒潑痛哭的巨嬰性格嘛。
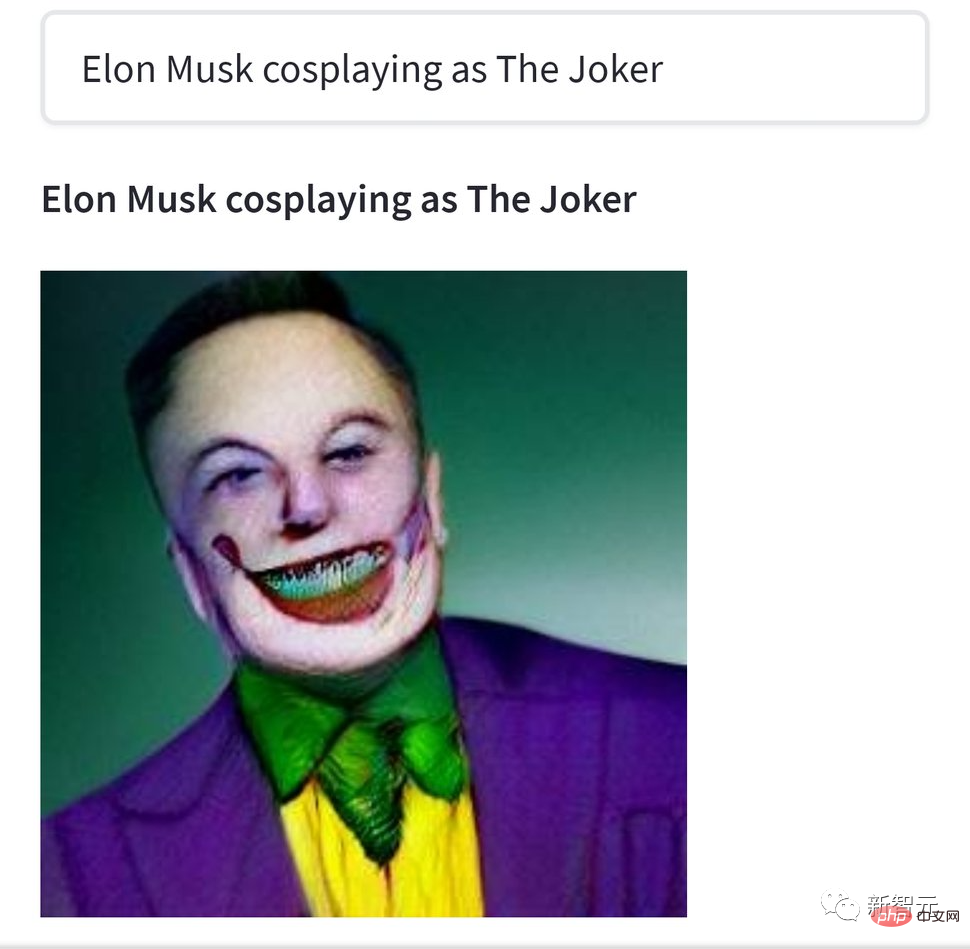
#然而這些創作都是輕口味的,比起重口味的克蘇魯愛好者們的作品,簡直清湯寡水。 例如這張「伊隆馬斯克扮演裂口小丑」,就有點嚇人。
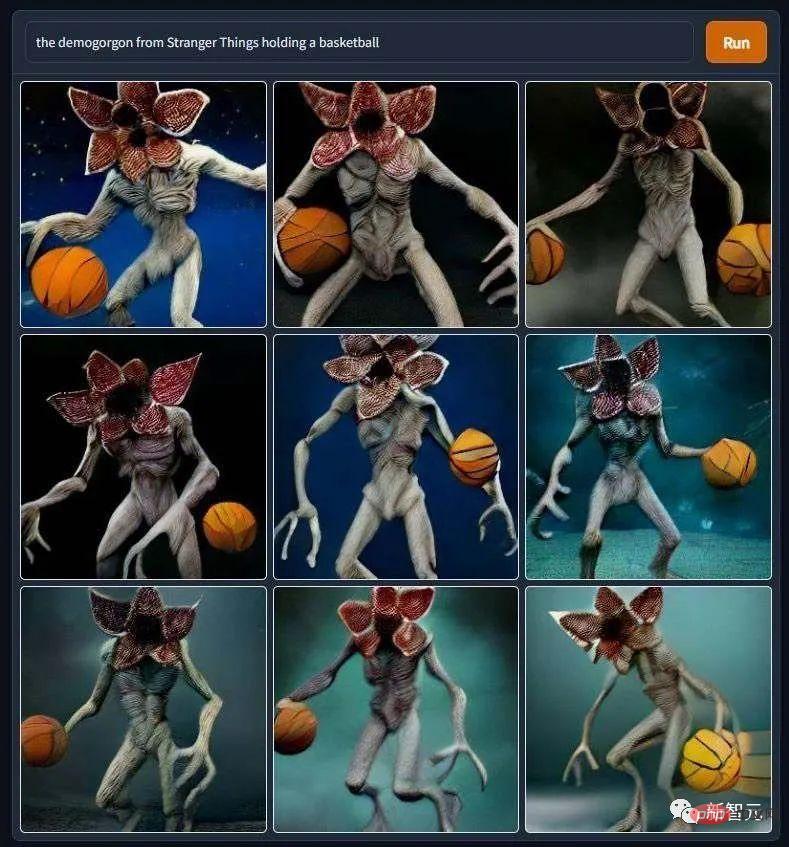
「魔王打籃球」,看了這張圖之後,編輯真的不敢繼續追《怪奇物語》這部劇了。
#各種系列恐怖片主角也出現在作品中,例如這張「面具傑森魔吃捲餅」

還有這張「猛鬼街殺人狂吃意麵」…圖案太嚇人了,讓編輯回想起DVD時代看這些恐怖片被嚇到前後俱急的青蔥歲月。

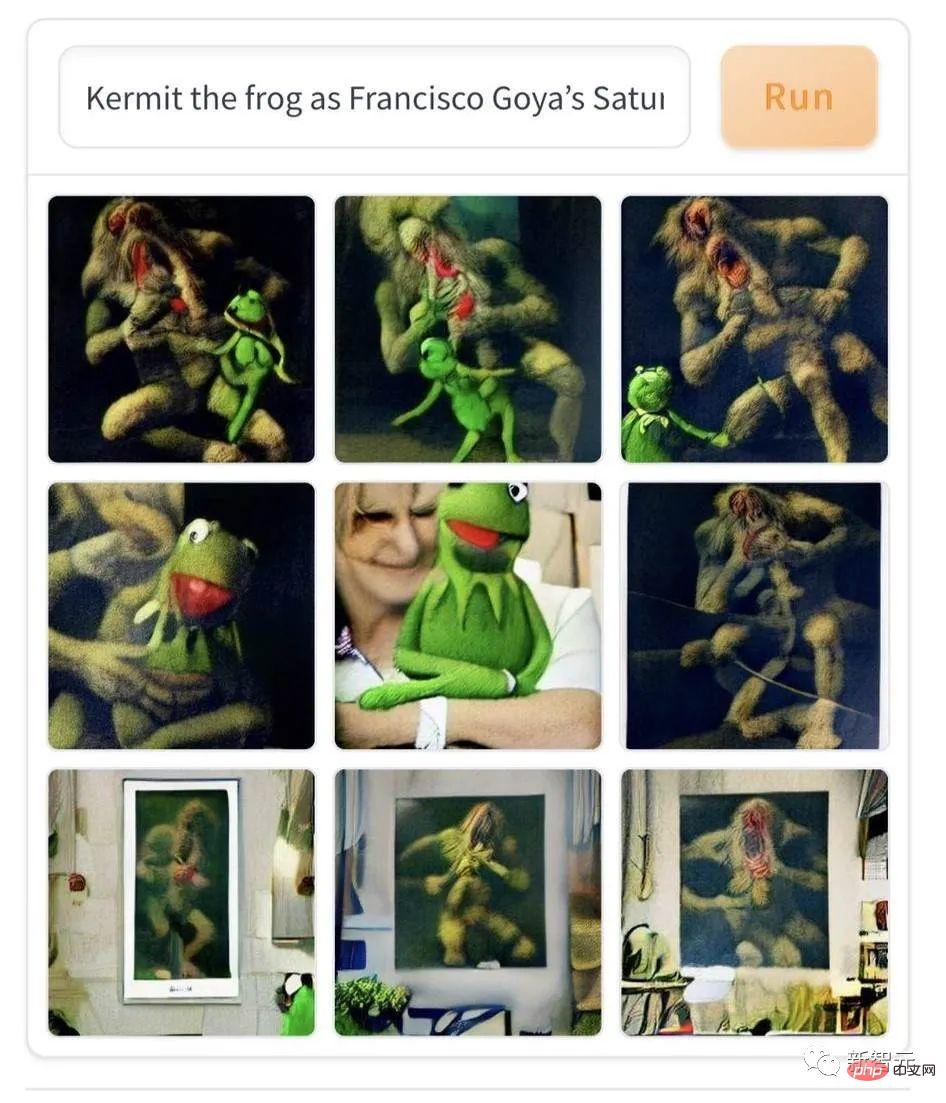
然而當代俗文藝在嚇人方面略遜古典藝術一籌,例如這幅「科米蛙在戈雅《農神食子》油畫中上鏡」。 AI用當代卡通搭配19世紀的表現主義油畫,能生生把初見者嚇到一脊背冷汗。
還有這張「死神在金拱門點卯」,看了這個,你以後上班上學還敢遲到嗎?

當然,細心且關注DALL·E系列動態的讀者們會發現,DALL·E Mini和之前的DALL·E大模型們,生成的圖片有個明顯的差異: DALL·E Mini生成的人像裡,臉都比DALL·E原本們生成的更模糊。 DALL·E Mini專案的主要開發者Boris Dayma在開發手記裡解釋了:我們這是親民減配版,Demo只有60行程式碼,功能弱少少很正常。
以下是Boris Dayma在手記中對項目的闡述。 先來看看項目特定的實作 它會根據文字產生對應的圖片:
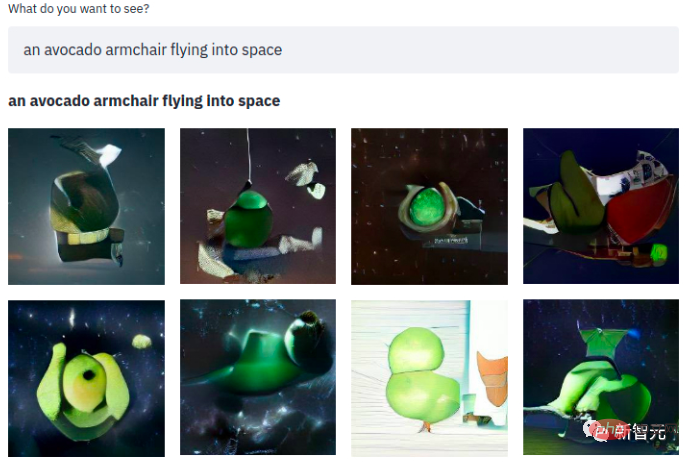
一句簡單的話,隨之而來的就是一個酪梨扶手椅閃現在太空中~ 該模型使用了三個資料集:
1、包含300萬張圖片和標題對的「Conceptual Captions Dataset」;
2、「YFCC100M」的Open AI子集,這包含了大約1500萬張圖像,不過出於對儲存空間的考慮,作者進一步對200萬張圖像進行了下採樣。同時使用標題和文字描述作為標籤,並刪除對應的html標記、換行和額外的空格;
#3、包含1200萬張圖片和標題對的「Conceptual 12M」。
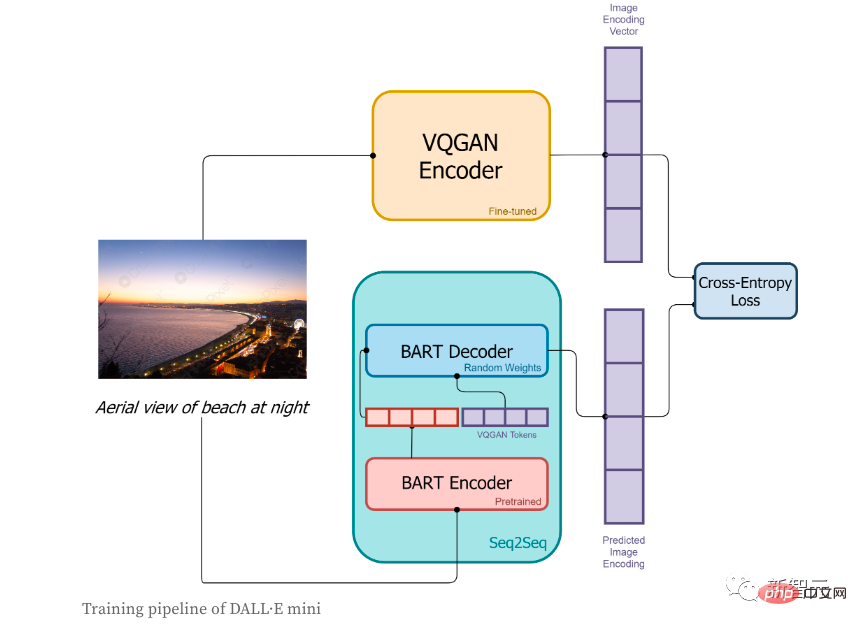
在訓練階段:
1、首先圖像會被VQGAN編碼器進行編碼,目的是將圖片轉換成一個token序列;
2、圖片對應的文本描述會透過BART編碼器進行編碼;
3、BART編碼器的輸出和VQGAN編碼器所編碼的序列token會一起被送入BART解碼器,該解碼器是一個自回歸模型,它的目的是去預測下一個token序列;
4、損失函數是交叉熵損失,用以計算模型預測的影像編碼結果和VQGAN真實影像編碼之間的損失值。
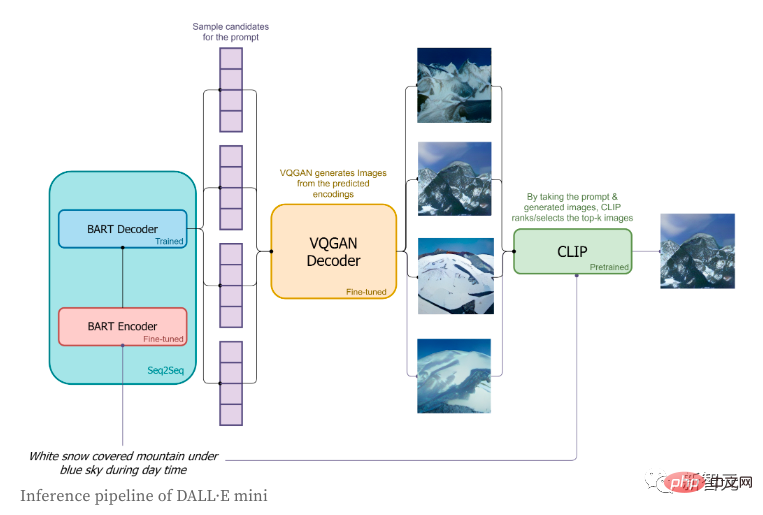
在推理階段,作者只使用了簡短的標籤,並且嘗試去產生其所對應圖片,具體流程如下:
1、標籤會透過BART編碼器進行編碼;
2、
3、基於BART解碼器在下一個token所預測的分佈,影像token會被依序的進行解碼;
#4、影像token的序列會被送入到VQGAN的解碼器進行解碼;
5.最後,「CLIP」會為我們選擇最好的生成結果。
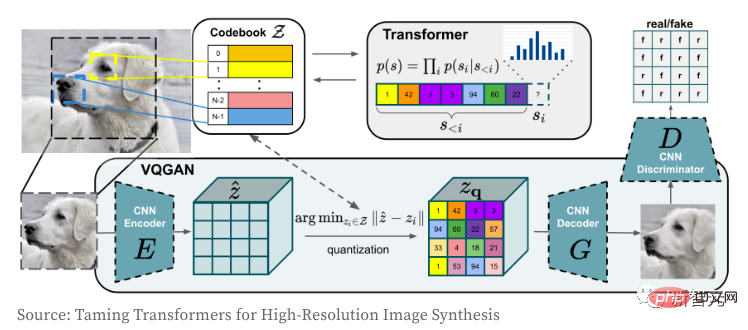
接下來我們再看一下VQGAN影像編碼器和解碼器是怎麼運作的。 Trannsformer模式想必大家都不陌生,從它誕生至今,不只是屠榜了NLP領域,CV領域的捲積CNN網路更是也被它掐住了喉嚨。 作者使用VQGAN的目的是將影像編碼到一個離散的token序列,該序列可以直接用在Transformer模型中。 由於使用像素值序列,會導致離散值的嵌入空間太大,最終使得訓練模型和滿足自註意力層的記憶體需要極為困難。
VQGAN透過結合感知損失和GAN的判別損失來學習像素的一個「密碼本」。編碼器輸出與「密碼本」對應的索引值。 隨著影像被編碼到token序列中,它就可以實現在任何Transformer模型中的使用。 在這個模型中,作者從大小為16,384的詞彙表中將影像編碼為「16x16=256」個的離散標記,使用壓縮係數f=16(4塊的寬度和高度各除以2)。解碼後的圖像是256x256(每邊16x16)。 關於VQGAN的更多細節的理解,請參閱《 Taming Transformers for High-Resolution Image Synthesis》。
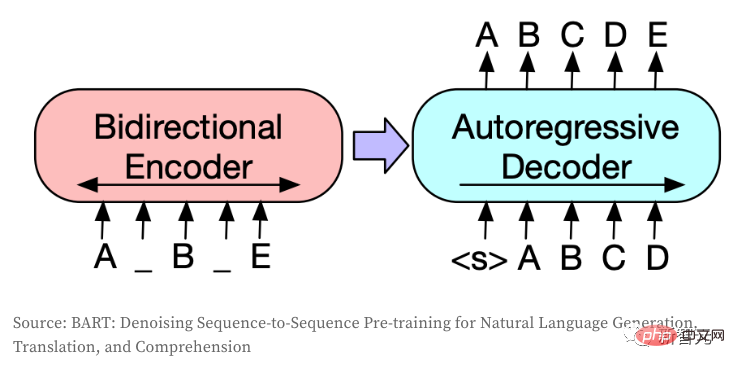
Seq2Seq模型是將一個token序列轉換為另一個token序列,通常在NLP中用於翻譯、摘要或對話建模等任務。 如果將影像編碼成離散的token,那麼同樣的想法也可以轉移到CV領域。模型使用了BART,作者只是對原始架構進行了微調:
1、為編碼器和解碼器創建了一個獨立的嵌入層(當有相同類型的輸入和輸出時,這二者通常可以共享);
2、調整解碼器輸入和輸出的shape,使其與VQGAN的大小保持一致(這一步不需要中間的嵌入層);
3、強制生成序列有256個token(此處並不包含作為序列開始和結束標誌的
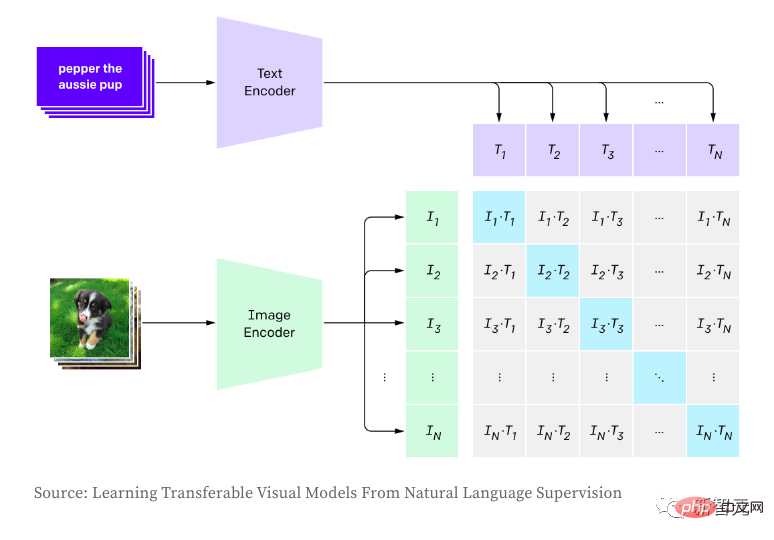
CLIP則用於建立圖像和文字之間的關係,並使用對比學習進行訓練,包括最大化圖像和文字對嵌入之間的積(餘弦相似度,就是正樣本)和最小化非關聯對(即負樣本)之間的乘積。 在產生影像時,作者根據模型的logits分佈對影像標記進行隨機抽樣,這會導致樣本不同且產生影像品質不一致。 CLIP允許根據輸入描述對產生的影像進行評分,從而選擇最佳產生的樣本。在推理階段,直接使用OpenAI的預訓練版本。
那麼,CLIP與OpenAI DALL·E相比,怎麼樣呢? 並不是所有關於DAL細節都是公眾所知的,但以下是作者認為的主要區別:
1、DALL·E使用120億參數版本的GPT-3。相較之下,作者的模型是原來的27倍,參數約4億個。
2、作者大量利用預先訓練的模型(VQGAN, BART編碼器和CLIP),而OpenAI必須從頭開始訓練所有的模型。模型架構考慮了可用的預訓練模型及其效率。
3、DALL·E從更小的詞彙表(8,192 VS 16,384)中使用更大數量的令牌(1,024 VS 256)編碼圖像。
4、DALL·E使用VQVAE,而作者使用VQGAN。當作者在Seq2Seq編碼器和解碼器之間分割時,DALL·E將文字和圖像作為單一資料流讀取。這也讓他們可以為文字和圖像使用獨立的詞彙。
5、DALL·E透過自回歸模型讀取文本,而作者使用雙向編碼器。
6、DALL·E訓練了2.5億對圖像和文本,而作者只使用了1500萬對。的。
7、DALL·E使用較少的標記(最多256 VS 1024)和較小的詞彙表(16384 VS 50264)來編碼文本。 在VQGAN的訓練上,作者先從ImageNet上預先訓練的checkpoint開始,壓縮係數f=16,詞彙表大小為16,384。雖然在編碼大範圍的圖像時非常高效,但預先訓練的checkpoint並不擅長編碼人和臉(因為二者在ImageNet中並不常見),所以作者決定在一個2 x RTX A6000的雲實例上對它進行大約20小時的微調。 很明顯,產生的影像在人臉上的品質並沒有提高很多,可能是「模型坍塌」。 一旦對模型進行了訓練,我們就將Pytorch模型轉換為JAX以備下一階段使用。
訓練DALL·E Mini: 此模型採用JAX編程,充分利用了TPU的優點。 作者用圖像編碼器預先編碼了所有的圖像,以便更快地載入資料。訓練期間,作者很快就確定了幾個近乎可行的參數:
1、每一步,每個TPU的batchsize大小為56,這是每個TPU可獲得的最大記憶體;
#2、梯度累加:有效的batchsize大小為56 × 8 TPU晶片× 8步=每次更新3,584張影像;
3、優化器Adafactor的記憶體效率可以讓我們使用更高的batchsize;
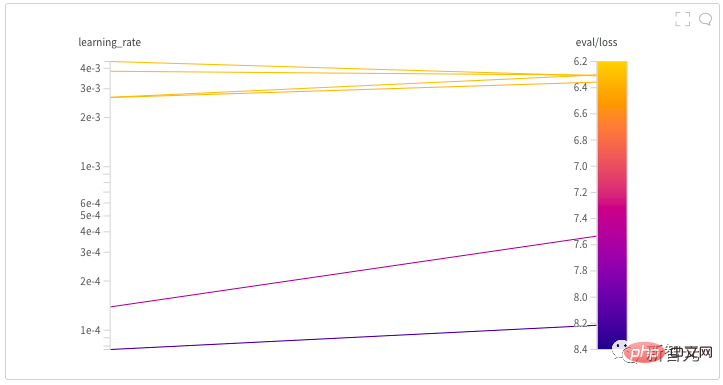
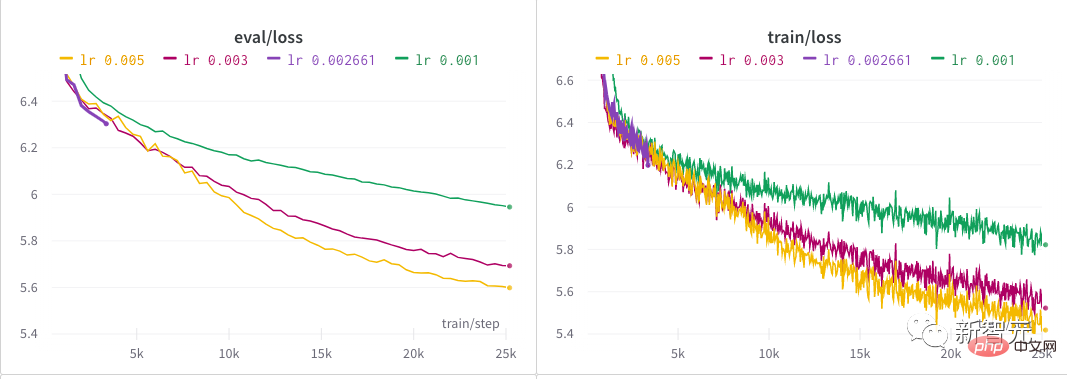
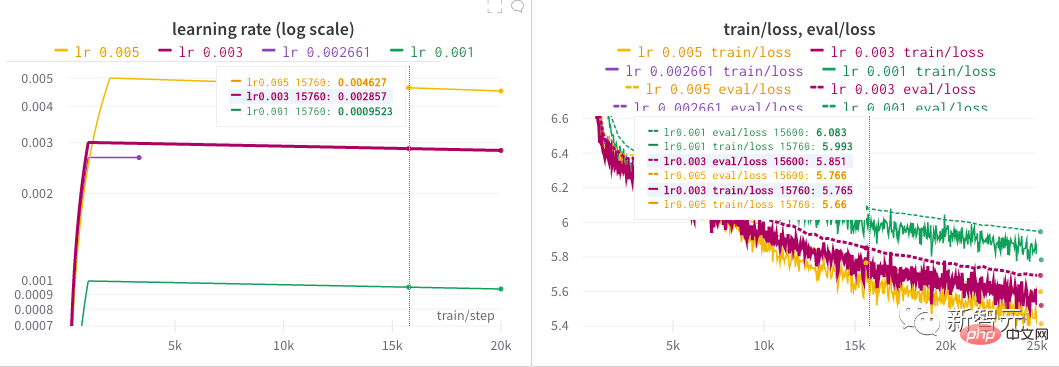
4、2000步驟「熱身」和以線性方式衰減的學習率。 作者花了幾近半天時間透過啟動超參數搜尋來為模型找到一個好的學習率。 每一個NB的模型背後,大抵都有那麼一段嘔心瀝血尋找超參數的歷程吧! 在作者初步探討之後,在較長一段時間內嘗試了幾種不同的學習率,直到最終確定為0.005。
以上是二代GAN網路崛起? DALL·E Mini畫面驚悚,老外玩瘋了!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















