

Meta AI開放6億+宏基因體蛋白質結構圖譜,150億語言模型用兩週完成

今年,DeepMind 公佈了大約 2.2 億種蛋白質的預測結構,它幾乎涵蓋了 DNA 資料庫中已知生物體的所有蛋白質。現在,另一家科技巨頭 Meta 正在填補另一個空白,微生物領域。
簡單來說,Meta 使用 AI 技術預測了約 6 億種蛋白質結構,這些蛋白質來自細菌和其他尚未被表徵的微生物。團隊負責人Alexander Rives 表示:「這些蛋白質是我們所知最少的結構,它們是非常神秘的蛋白質。我認為這些發現為深入了解生物學提供了潛力。」
通常,語言模型是在大量文本上進行訓練的。 Meta 為了將語言模型應用於蛋白質,Rives 及其同事將已知的蛋白質序列作為輸入,這些蛋白質由 20 種氨基酸組成,並以不同的字母表示。然後,該網絡在遮蔽一定比例氨基酸的情況下學會了自動補全蛋白質。
Meta 將這個網路命名為 ESMFold。雖然 ESMFold 預測準確度不如 AlphaFold,但在預測結構方面,它比 AlphaFold 快約 60 倍。這一速度意味著可以將蛋白質結構預測擴展到更大的資料庫。

- 論文網址:https://www.biorxiv.org/content/10.1101/2022.07.20.500902v2
- 專案網址:https://github.com/facebookresearch/esm
如今,作為測試,Meta 決定將他們的模型應用於宏基因組DNA 資料庫,這些DNA 全部來自環境,包括土壤、海水、人類腸道、皮膚和其他微生物棲息地。 Meta AI 宣布推出包含 6 億多個蛋白質的 ESM 宏基因組圖譜(ESM Metagenomic Atlas),它是首個蛋白質宇宙「暗物質」的綜合視圖#。這還是最大的高解析度預測結構資料庫,比任何現有的蛋白質結構資料庫都要大 3 倍,並且是第一個全面、大規模地涵蓋宏基因組蛋白質的資料庫。
Meta 團隊總共預測了超過 6.17 億個蛋白質結構,只花了兩週的時間。 Rives 說,預測是免費的,任何人都可以使用,就像模型的底層程式碼一樣。
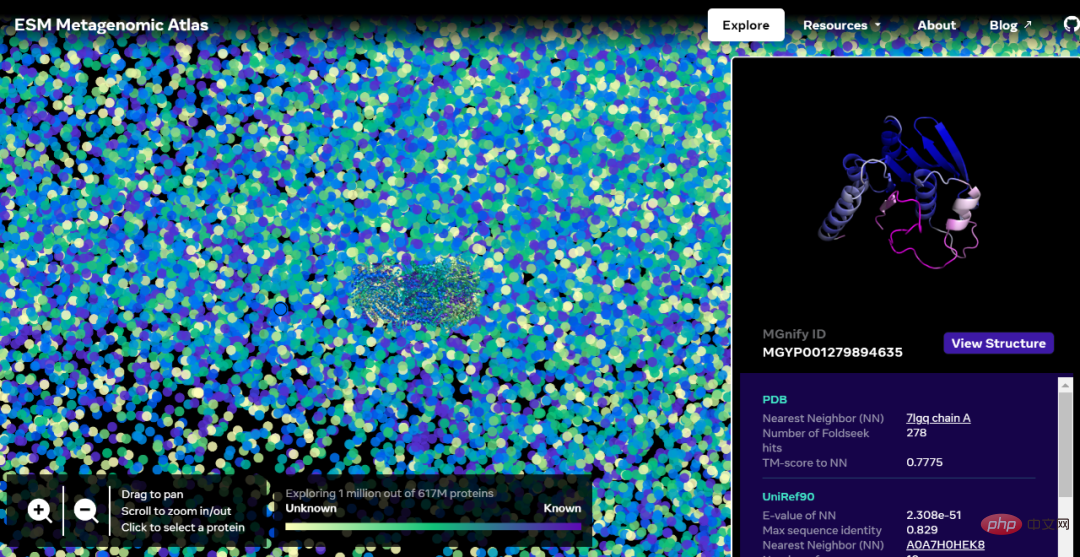
互動版本位址:https://esmatlas.com/explore?at=1,1,21.999999344348925
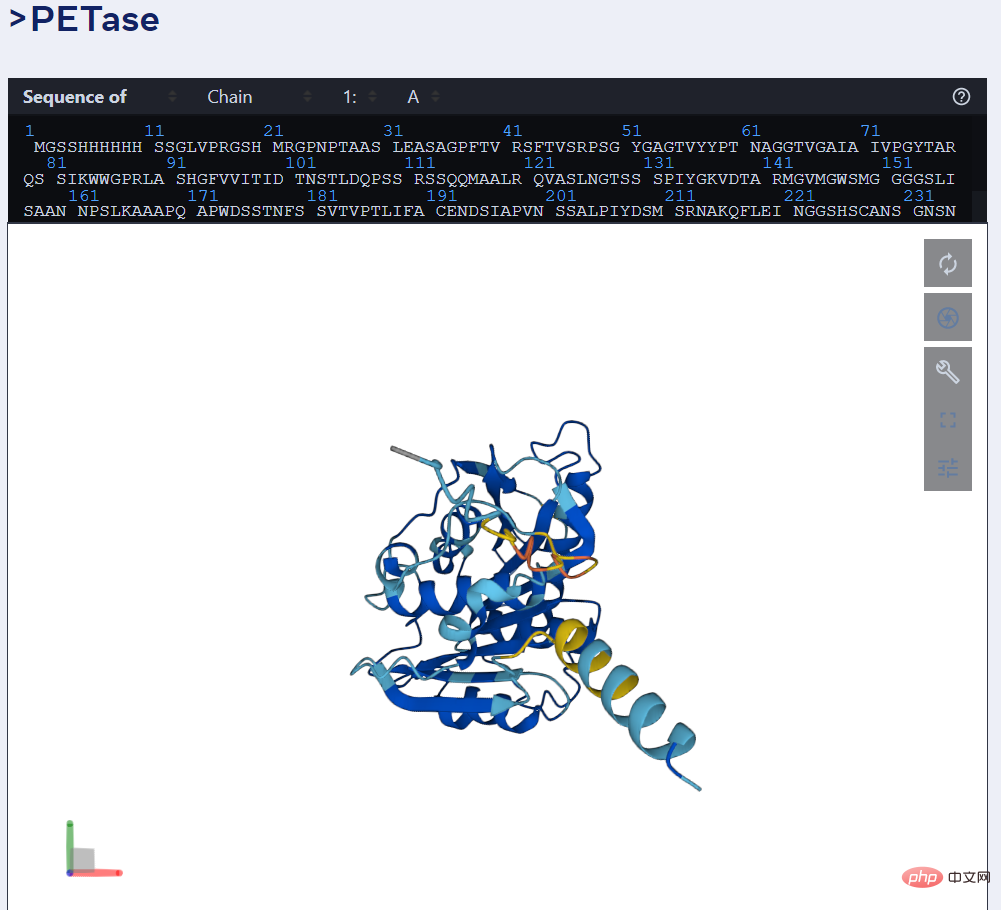
舉例而言,下圖為ESMFold 對PET 酵素的預測。
引言
眾所周知,蛋白質作為複雜且動態的分子,其由基因編碼,主要負責生命基本過程。蛋白質在生物學中有著驚人作用。例如,人類眼睛中的視桿和視錐細胞可以感知光線,因而我們能看到外面的世界;構成聽覺和觸覺基礎的分子感測器;植物中把光能轉化為化學能的複雜分子;驅動微生物和人類肌肉運動的「馬達」;分解塑膠的酵素;保護我們免受疾病的抗體,等等這些都是蛋白質。
1998 年,來自威斯康辛大學植物病理學部門的Jo Handelsman 首次提出宏基因組學(Metagenomics)這一概念,它是源於將來自環境中基因集可以在某種程度上當成單一基因組研究分析的想法,而宏的英文正是meta-,也翻譯為元。
宏基因體學揭示了數十億個對科學來說是新的蛋白質序列,並首次編入由NCBI、歐洲生物資訊研究所(European Bioinformatics Institute) 和聯合基因組研究所(Joint Genome Institute) 等公共計畫編製的大型資料庫中。
Meta AI 開發的新的蛋白質折疊方法,該方法利用大型語言模型,在宏基因組資料庫中(具有數億蛋白質)創建了首個全面的蛋白質結構視圖。 Meta 發現,相對於現有的 SOTA 蛋白質結構預測方法,語言模型可以將預測蛋白質原子級三維結構的速度提高 60 倍。這項進展將有助於加速蛋白質結構理解的新時代,這是首次人類有可能了解基因定序技術正在編目的數十億蛋白質的結構。
解鎖隱藏的自然世界:宏基因組結構空間的首個綜合視圖
我們知道,基因定序的進步使得對數十億個宏基因組蛋白序列進行編目成為可能。但是,透過實驗確定數以億計蛋白質的 3D 結構遠遠超出了時間密集型實驗室技術的範圍,例如 X 射線晶體學,它可能需要數週乃至數年的時間來檢測單個蛋白質。計算方式可以讓我們深入了解使用實驗技術無法實現的宏基因體學蛋白質。
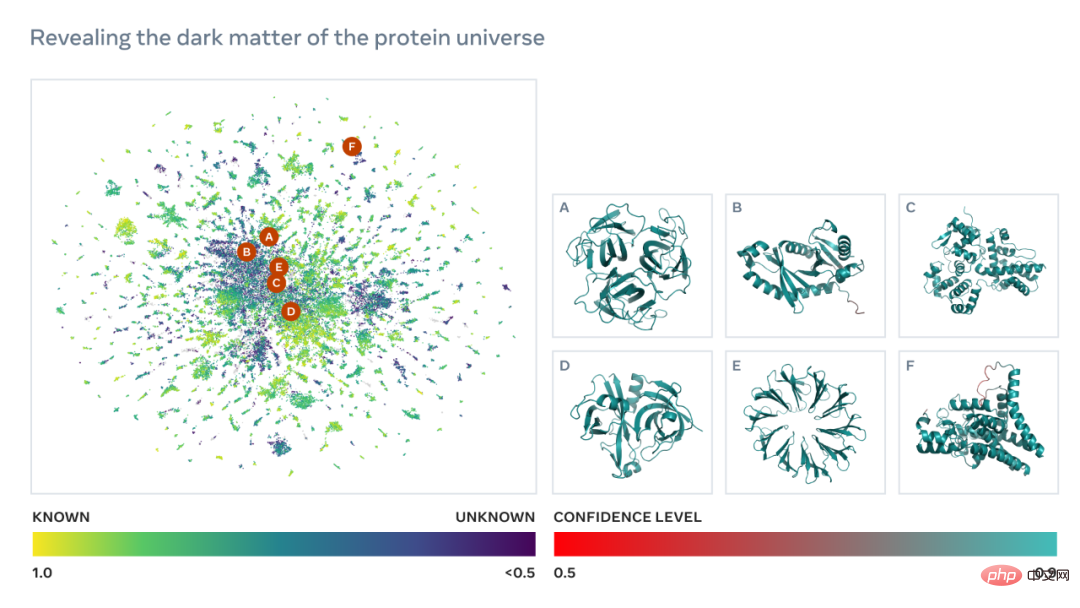
ESM 宏基因組圖譜將使科學家能夠在數億蛋白質的尺度上搜尋和分析宏基因組蛋白質的結構。這可以幫助識別以前未被表徵的結構,尋找遙遠的演化關係,並發現可用於醫學和其他應用的新蛋白質。
如下為一張包含數以萬計高置信度預測的圖譜,顯示了與目前已知結構的蛋白質的相似性。並且,該圖像首次顯示了完全未知的蛋白質結構空間的更大區域。
學習閱讀生物學語言
如下圖所示,ESM-2 語言模型經過訓練,可以預測演化過程中被序列掩蓋的胺基酸。 Meta AI 發現,作為訓練的結果,蛋白質結構的資訊出現在該模型的內部狀態中。這實在令人驚訝,因為該模型僅在序列上進行了訓練。
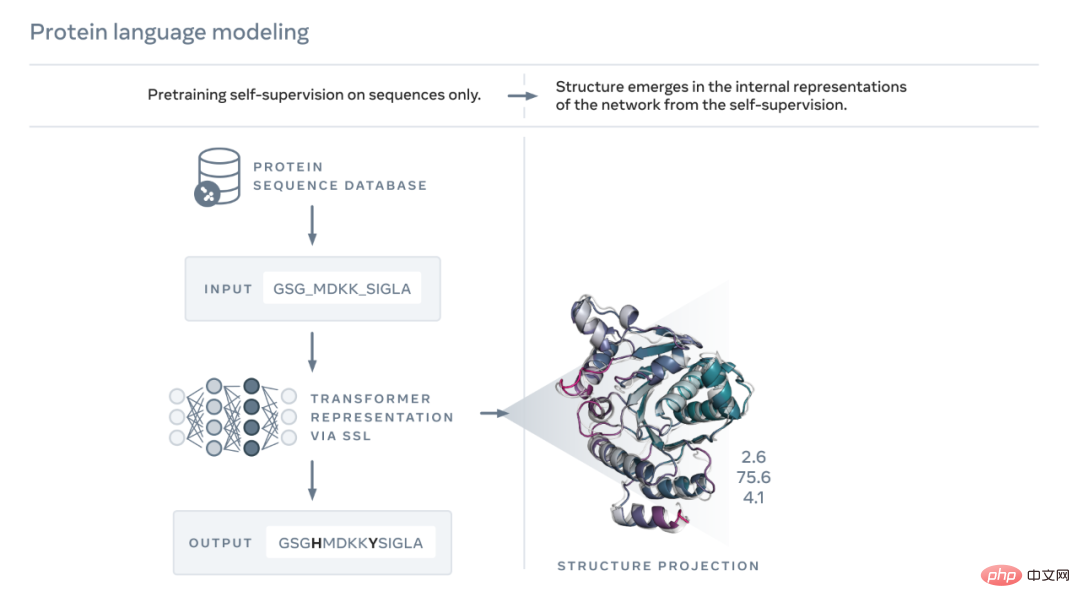
就像論文或信件的文字一樣,蛋白質可以寫成字元序列。其中,每個字元對應 20 種標準化學元素(胺基酸)中的一種,每種又具有不同的特性,它們是蛋白質的構建塊。這些構建塊能夠以天文數字的不同方式組合在一起,例如對於由 200 個氨基酸組成的蛋白質,存在 20^200 個可能的序列,這要比可見宇宙中的原子數量還要多。每個序列都折疊成 3D 形狀(但並非所有序列都會折疊成連貫的結構,許多序列折疊成無序形式),而正是這種形狀在很大程度上決定了蛋白質的生物學功能。
學習閱讀這種生物學語言帶來了巨大挑戰。雖然蛋白質序列和文本段落都可以寫成字符,但它們之間存在著深刻而根本性的差異。蛋白質序列描述了一個分子的化學結構,該分子根據物理定律折疊成複雜的 3D 形狀。
蛋白質序列包含了傳遞蛋白質摺疊結構訊息的統計模式。舉例而言,如果一個蛋白質中的兩個位置共同進化,或者換言之,如果其中一個位置出現某種氨基酸,通常與另一個位置的某種氨基酸配對,這可能意味著這兩個位置在折疊結構中相互作用。這類似於拼圖遊戲中的兩塊拼圖,進化必須選擇在折疊結構中拼合在一起的氨基酸。這又意味著我們通常可以透過觀察蛋白質序列中的模式來推斷蛋白質的結構。
ESM 使用 AI 來學習閱讀這些模式。 2019 年,Meta AI 提供證據證明語言模型學習了蛋白質的特性,例如它們的結構和功能。透過一種稱為掩碼語言建模的自我監督學習形式,Meta AI 在數百萬個天然蛋白質的序列上訓練了一個語言模型。使用此方法,模型必須正確填入文本段落中的空白,例如「To _ or not to , that is the _____」。
之後,Meta AI 訓練了一個語言模型來填補蛋白質序列中的空白。他們發現,蛋白質結構和功能的資訊在這項訓練中浮現了出來。 2020 年,Meta 發布了一個 SOTA 蛋白質語言模型 ESM1b,用於各種應用,包括幫助科學家預測 COVID-19 的演變以及發現疾病的遺傳原因。
現在,Meta AI 擴展了這種方法,用來創建下一代蛋白質語言模型 ESM-2,它的參數為 150 億,是迄今為止最大的蛋白質語言模型。他們發現,當模型參數從 800 萬放大到 150 億時,內部表示中會出現訊息,從而能夠以原子分辨率進行 3D 結構預測。
將蛋白質折疊實現數量級加速
在下圖中,隨著模型的擴大,高解析度的蛋白質結構出現。同時隨著模型的縮放,蛋白質結構的原子解析度影像中會出現新的細節。

使用目前SOTA 運算工具,在實際時間範圍內預測數億蛋白質序列結構可能花費數年時間,即便用上主要研究機構的資源也是如此。因此,想要在宏基因組尺度上進行預測,預測速度的突破至關重要。
Meta AI 發現使用蛋白質序列的語言模型大大加快了結構預測的速度,最高提升 60 倍。這足以在短短幾週內對整個宏基因組資料庫做出預測,並且可以擴展到比我們目前發布的資料庫大得多的資料庫。事實上,這種新的結構預測能力能夠在短短兩週內,在大約 2000 個 GPU 組成的集群上預測超過 6 億多個宏基因組蛋白的序列。
此外,目前 SOTA 結構預測方法需要搜尋大型蛋白質資料庫以識別相關序列。這些方法實際上需要一整組進化相關的序列作為輸入,以便它們可以提取與結構相關的模式。 Meta AI 的 ESM-2 語言模型在其對蛋白質序列的訓練過程中學習這些進化模式,進而能夠直接從蛋白質序列中對 3D 結構進行高解析度預測。
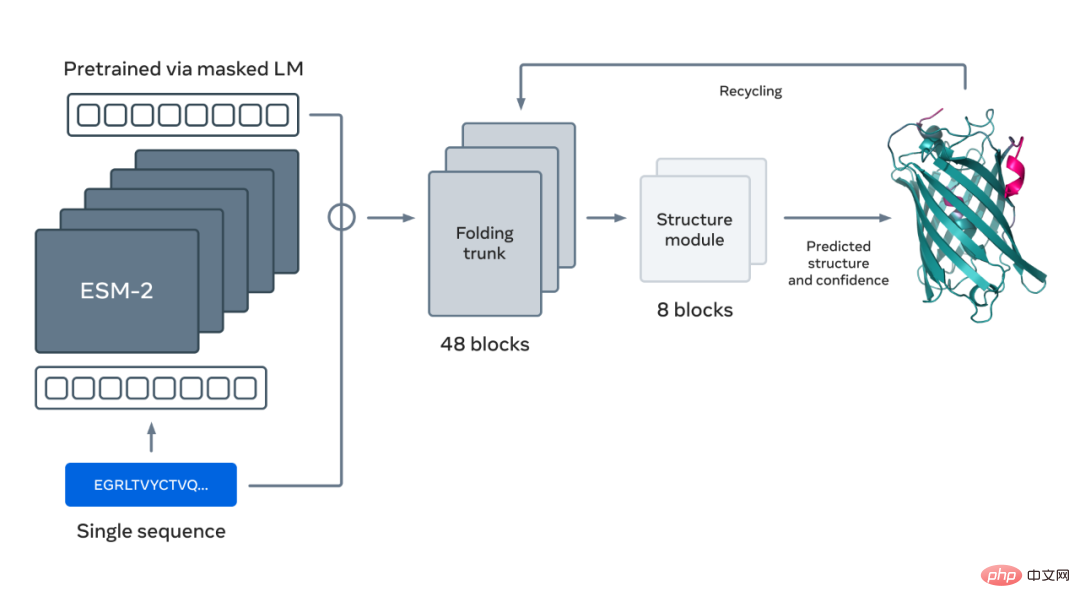
下圖展示了使用 ESM-2 語言模型進行蛋白質摺疊。箭頭從左到右顯示了網路中從語言模型到折疊 trunk 再到結構模組的資訊流,最後輸出 3D 座標和置信度。
更多詳細內容請參考原文。
#部落格連結:https://ai.facebook.com/blog/protein-folding-esmfold-metagenomics/
以上是Meta AI開放6億+宏基因體蛋白質結構圖譜,150億語言模型用兩週完成的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
本文介紹如何在Debian系統上自定義Apache的日誌格式。以下步驟將指導您完成配置過程:第一步:訪問Apache配置文件Debian系統的Apache主配置文件通常位於/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root權限打開配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定義自定義日誌格式找到或
 Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌是診斷內存洩漏問題的關鍵。通過分析Tomcat日誌,您可以深入了解內存使用情況和垃圾回收(GC)行為,從而有效定位和解決內存洩漏。以下是如何利用Tomcat日誌排查內存洩漏:1.GC日誌分析首先,啟用詳細的GC日誌記錄。在Tomcat啟動參數中添加以下JVM選項:-XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log這些參數會生成詳細的GC日誌(gc.log),包含GC類型、回收對像大小和時間等信息。分析gc.log
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
 Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
本文介紹如何在Debian系統中使用iptables或ufw配置防火牆規則,並利用Syslog記錄防火牆活動。方法一:使用iptablesiptables是Debian系統中功能強大的命令行防火牆工具。查看現有規則:使用以下命令查看當前的iptables規則:sudoiptables-L-n-v允許特定IP訪問:例如,允許IP地址192.168.1.100訪問80端口:sudoiptables-AINPUT-ptcp--dport80-s192.16
 Debian Nginx日誌路徑在哪裡
Apr 12, 2025 pm 11:33 PM
Debian Nginx日誌路徑在哪裡
Apr 12, 2025 pm 11:33 PM
Debian系統中,Nginx的訪問日誌和錯誤日誌默認存儲位置如下:訪問日誌(accesslog):/var/log/nginx/access.log錯誤日誌(errorlog):/var/log/nginx/error.log以上路徑是標準DebianNginx安裝的默認配置。如果您在安裝過程中修改過日誌文件存放位置,請檢查您的Nginx配置文件(通常位於/etc/nginx/nginx.conf或/etc/nginx/sites-available/目錄下)。在配置文件中
 Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
在Debian郵件服務器上安裝SSL證書的步驟如下:1.安裝OpenSSL工具包首先,確保你的系統上已經安裝了OpenSSL工具包。如果沒有安裝,可以使用以下命令進行安裝:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私鑰和證書請求接下來,使用OpenSSL生成一個2048位的RSA私鑰和一個證書請求(CSR):openss
 Debian郵件服務器防火牆配置技巧
Apr 13, 2025 am 11:42 AM
Debian郵件服務器防火牆配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian郵件服務器的防火牆是確保服務器安全性的重要步驟。以下是幾種常用的防火牆配置方法,包括iptables和firewalld的使用。使用iptables配置防火牆安裝iptables(如果尚未安裝):sudoapt-getupdatesudoapt-getinstalliptables查看當前iptables規則:sudoiptables-L配置
