
图像抠图是指提取图像中准确的前景。当前的自动方法倾向于不加区别地提取图像中的所有显著对象。在本文中,作者提出了一个新的任务称为 参考图像抠图 (Referring Image Matting,RIM),指的是提取特定对象的细致的alpha抠图,它可以最好地匹配给定的自然语言描述。 然而,流行的visual grounding方法都局限于分割水平,可能是由于缺乏高质量的RIM数据集。为了填补这一空白, 作者通过设计一个全面的图像合成和表达生成引擎,建立了第一个大规模挑战性数据集RefMatte ,以在当前公共高质量抠图前景的基础上生成合成图像,具有灵活的逻辑和重新标记的多样化属性。
RefMatte由230个对象类别、47,500个图像、118,749个表达式区域实体和474,996个表达式组成,将来可以很容易地进一步扩展。除此之外,作者还构建了一个真实世界测试集,该测试集由100幅自然图像组成,使用人工生成的短语标注来进一步评估RIM模型的泛化能力。首先定义了基于提示和基于表达两种背景下的RIM任务,然后测试了几种典型的图像抠图方法以及具体的模型设计。这些结果为现有方法的局限性以及可能的解决方案提供了经验性的见解。相信新任务RIM和新数据集RefMatte将在该领域开辟新的研究方向,并促进未来的研究。

论文标题:Referring Image Matting
论文地址: https:// arxiv.org/abs/2206.0514 9
代码地址: https:// github.com/JizhiziLi/RI M
图像抠图是指提取自然图像中前景的软ahpha抠图,这有利于各种下游应用,如视频会议、广告制作和电子商务推广。典型的抠图方法可以分为两组:1)基于辅助输入的方法,例如trimap,以及2)无需任何人工干预即可提取前景的自动抠图方法。但前者不适用于自动应用场景,后者一般局限于特定的对象类别,如人、动物或所有显著的物体。如何对任意对象进行可控的图像抠图,即提取与给定的自然语言描述最匹配的特定对象的alpha抠图,仍是一个有待探索的问题。
语言驱动的任务,例如referring expression segmentation(RES)、referring image segmentation(RIS)、视觉问答 (VQA) 和 referring expression comprehension (REC) 已被广泛探索。基于ReferIt、Google RefExp、RefCOCO、VGPhraseCut和Cops-Ref等许多数据集,这些领域已经取得了很大进展。例如,RES 方法旨在分割由自然语言描述指示的任意对象。然而,获得的mask仅限于没有精细细节的分割级别,由于数据集中的低分辨率图像和粗略的mask标注。因此,它们不可能用于需要对前景对象进行细致 Alpha 抠图的场景。

为了填补这一空白,作者在本文中提出了一项名为“Referring Image Matting (RIM)”的新任务。 RIM 是指在图像中提取与给定自然语言描述最匹配的特定前景对象以及细致的高质量 alpha 抠图。与上述两种抠图方法解决的任务不同,RIM 旨在对语言描述指示的图像中的任意对象进行可控的图像抠图。在工业应用领域具有现实意义,为学术界开辟了新的研究方向。
为了促进 RIM 的研究,作者建立了第一个名为 RefMatte 的数据集,该数据集由 230 个对象类别、47,500 个图像和 118,749 个表达式区域实体以及相应的高质量 alpha matte 和 474,996 个表达式组成。
具体来说,为了构建这个数据集,作者首先重新访问了许多流行的公共抠图数据集,如 AM-2k、P3M-10k、AIM-500、SIM,并手动标记仔细检查每个对象。作者还采用了多种基于深度学习的预训练模型为每个实体生成各种属性,例如人类的性别、年龄和衣服类型。然后,作者设计了一个综合的构图和表达生成引擎,以生成具有合理绝对和相对位置的合成图像,并考虑其他前景对象。最后,作者提出了几种表达逻辑形式,利用丰富的视觉属性生成不同的语言描述。此外,作者提出了一个真实世界的测试集 RefMatte-RW100,其中包含 100 张包含不同对象和人类注释表达的图像,用于评估 RIM 方法的泛化能力。上图显示了一些示例。
為了對相關任務中的最新方法進行公平和全面的評估,作者在RefMatte 上根據語言描述的形式在兩種不同的設置下對它們進行基準測試,即基於提示的設置和基於表達的設置。由於代表性方法是專門為分割任務設計的,直接將它們應用於 RIM 任務時仍然存在差距。
為了解決這個問題,作者提出了兩種為RIM 定制它們的策略,即1)在CLIPSeg 之上精心設計了一個名為CLIPmat 的輕量級摳圖頭,以產生高品質的alpha 摳圖結果,同時保持其端到端可訓練的管道; 2)提供了幾種單獨的基於粗圖的摳圖方法作為後期精煉器,以進一步改善分割/摳圖結果。廣泛的實驗結果 1) 展示了所提出的 RefMatte 資料集對於 RIM 任務研究的價值,2) 確定語言描述形式的重要作用; 3) 驗證提議的客製化策略的有效性。
本研究的主要貢獻有三個面向。 1)定義了一個名為RIM 的新任務,旨在識別和提取與給定自然語言描述最匹配的特定前景對象的alpha摳圖;2)建立了第一個大規模數據集RefMatte,由47,500張圖像和118,749個表達區域實體組成,具有高品質的alpha摳圖和豐富的表達;3) 在兩種不同的設定下使用兩種針對RefMatte 的RIM 定制策略對具有代表性的最先進方法進行了基準測試,並獲得了一些有用的見解。

在本節中,將介紹建構RefMatte(第3.1 節和第3.2 節)的pipeline以及任務設定(第3.3節)和資料集的統計資訊(第3.5 節)。上圖展示RefMatte 的一些範例。此外,作者還建立了一個真實世界的測試集,由 100 張自然圖像組成,並帶有手動標記的豐富語言描述註釋(第 3.4 節)。
為了準備足夠多的高品質摳圖實體來幫助建立RefMatte 資料集,作者重新存取目前可用的摳圖資料集以過濾出滿足要求的前景。然後手動標記所有候選實體的類別並利用多個基於深度學習的預訓練模型來註釋它們的屬性。
Pre-processing and filtering
由於圖像摳圖任務的性質,所有候選實體都應該是高解析度的,並且在alpha 摳圖中具有清晰和精細的細節。此外,數據應該透過開放許可公開取得,並且沒有隱私問題,以促進未來的研究。針對這些要求,作者採用了來自 AM-2k 、P3M-10k 和 AIM-500的所有前景影像。具體來說,對於 P3M-10k,作者過濾掉具有兩個以上黏性前景實例的圖像,以確保每個實體僅與一個前景實例相關。對於其他可用的資料集,如 SIM、DIM和 HATT,作者過濾掉那些在人類實例中具有可辨識臉孔的前景影像。作者也過濾掉那些低解析度或具有低品質 alpha 摳圖的前景影像。最終實體總數為 13,187 個。對於後續合成步驟中使用的背景影像,作者選擇 BG-20k 中的所有影像。
Annotate the category names of entities
#由於先前的自動摳圖方法傾向於從圖像中提取所有顯著的前景對象,因此它們沒有為每個實體提供特定的(類別)名稱。但是,對於 RIM 任務,需要實體名稱來描述它。作者為每個實體標記了入門級類別名稱,它代表人們對特定實體最常用的名稱。在這裡,採用半自動策略。具體來說,作者使用具有 ResNet-50-FPN主幹的 Mask RCNN 偵測器來自動偵測和標記每個前景實例的類別名稱,然後手動檢查和修正它們。 RefMatte 共有 230 個類別。此外,作者採用 WordNet為每個類別名稱產生同義詞以增強多樣性。作者手動檢查同義詞並將其中一些替換為更合理的同義詞。
Annotate the attributes of entities
為了確保所有實體具有豐富的視覺屬性以支援形成豐富的表達式,作者為所有實體標註了顏色、人類實體的性別、年齡和衣服類型等多種屬性。作者也採用半自動策略來產生此類屬性。為了產生顏色,作者將前景影像的所有像素值聚類,找出最常見的值,並將其與 webcolors 中的特定顏色進行匹配。對於性別和年齡,作者採用預訓練模型。依照常識根據預測的年齡來定義年齡組。對於衣服類型,作者採用 預訓練模型。此外,受前景分類的啟發,作者為所有實體添加了顯著或不顯著以及透明或不透明的屬性,因為這些屬性在圖像摳圖任務中也很重要。最終,每個實體至少有 3 個屬性,人類實體至少有 6 個屬性。
基於上一節收集的摳圖實體,作者提出了一個影像合成引擎和表達式產生引擎來建構RefMatte 資料集。如何將不同的實體排列形成合理的合成影像,同時產生語義清晰、語法正確、豐富、花俏的表達方式來描述這些合成影像中的實體,是建構RefMatte的關鍵,也是具有挑戰性的。為此,作者定義了六種位置關係,用於在合成影像中排列不同的實體,並利用不同的邏輯形式來產生適當的表達。
Image composition engine
為了保持實體的高分辨率,同時以合理的位置關係排列它們,作者為每個合成圖像採用兩個或三個實體。作者定義了六種位置關係:左、右、上、下、前、後。對於每個關係,首先產生前景圖像,並透過 alpha 混合將它們與來自 BG-20k的背景圖像合成。具體來說,對於左、右、上、下的關係,作者確保前景實例中沒有遮蔽以保留它們的細節。對於前後關係,透過調整它們的相對位置來模擬前景實例之間的遮蔽。作者準備了一袋候選詞來表示每個關係。
Expression generation engine
為了給合成影像中的實體提供豐富的表達方式,作者從定義的不同邏輯形式的角度為每個實體定義了三種表達方式,其中 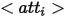 代表屬性,
代表屬性, 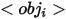 代表類別名稱,
代表類別名稱, 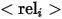 代表參考實體和相關實體之間的關係,具體三種表達的例子如上圖(a),(b)和(c )所示。
代表參考實體和相關實體之間的關係,具體三種表達的例子如上圖(a),(b)和(c )所示。
Dataset split
資料集總共有13,187 個摳圖實體,其中11,799 個用於建立訓練集,1,388 個用於測試集。然而,訓練集和測試集的類別並不平衡,因為大多數實體屬於人類或動物類別。具體來說,在訓練集中的 11799 個實體中,有 9186 個人類、1800 個動物和 813 個物體。在包含 1,388 個實體的測試集中,有 977 個人類、200 個動物和 211 個物件。為了平衡類別,作者複製實體以實現人類:動物:物件的 5:1:1 比率。因此,在訓練集中有 10,550 個人類、2,110 個動物和 2,110 個對象,在測試集中有 1,055 個人類、211 個動物和 211 個對象。
為了為 RefMatte 產生影像,作者從訓練或測試split中挑選 5 個人類、1 個動物和 1 個物件作為一組,並將它們輸入影像合成引擎。對於訓練或測試split中的每一組,作者產生 20 張圖像來形成訓練集,並產生 10 張圖像來形成測試集。左/右:上/下:前/後關係的比例設定為 7:2:1。每個影像中的實體數量設定為 2 或 3。對於前後關係,作者總是選擇 2 個實體來保持每個實體的高解析度。在這個過程之後,就有 42,200 個訓練圖像和 2,110 個測試圖像。為了進一步增強實體組合的多樣性,我作者所有候選人中隨機選擇 實體和關係,形成另外 2800 個訓練圖像和 390 個測試圖像。最後,在訓練集中有 45,000 張合成影像,在測試集中有 2,500 張圖像。
Task setting
為了在給定不同形式的語言描述的情況下對RIM 方法進行基準測試,作者在RefMatte 中設定了兩個設定:
基於提示的設定(Prompt-based settin):此設定中的文字描述為提示,即實體的入門級類別名稱,例如上圖中的提示分別為花、人、羊駝;
基於表達式的設定(Expression-based setting):此設定中的文字描述是上一節中產生的表達式,從基本表達式、絕對位置表達式和相對位置表達式中選擇。從上圖中也可以看到一些範例。

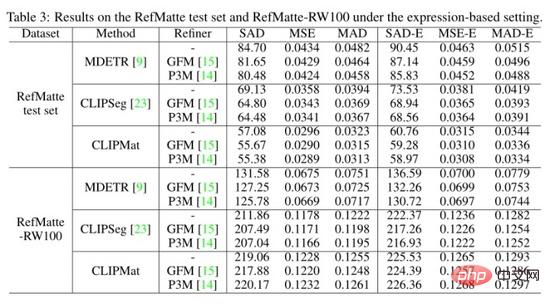
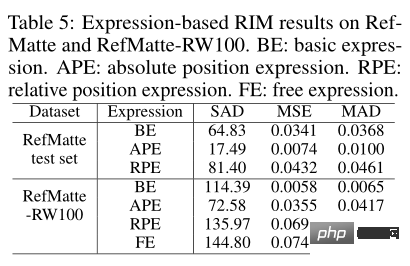
由於 RefMatte 是基於合成圖像構建的,因此它們與真實世界圖像之間可能存在域差距。為了研究在其上訓練的RIM 模型對真實世界圖像的泛化能力,作者進一步建立了一個名為RefMatte-RW100 的真實世界測試集,它由100 張真實世界的高分辨率圖像組成,每張圖像中有2 到3 個實體。然後,作者按照3.2節中相同的三個設定來註解它們的表達式。此外,作者在註釋中加入了一個自由表達式。對於高品質的 alpha 摳圖標籤,作者使用影像編輯軟體產生它們,例如 Adobe Photoshop 和 GIMP。 RefMatte-RW100 的一些例子如上圖所示。
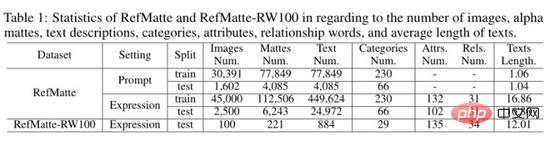

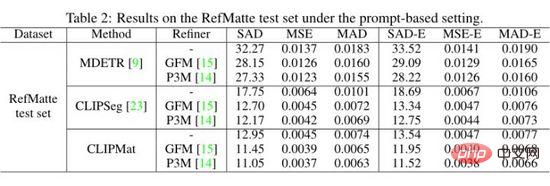
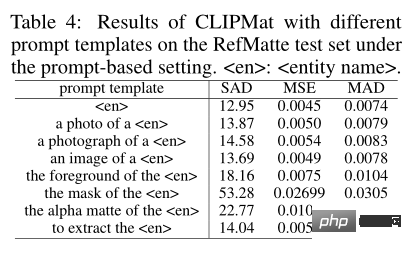
。結果如上表所示。可以看到 CLIPmat 在不同提示下的效能差異很大。
以上是深度學習又有新坑了!雪梨大學提出全新跨模態任務,以文字指導圖像進行摳圖的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















